Recognition: 2 theorem links
· Lean TheoremBBC: Improving Large-k Approximate Nearest Neighbor Search with a Bucket-based Result Collector
Pith reviewed 2026-05-13 20:43 UTC · model grok-4.3
The pith
A bucket-based collector organizes ANN candidates by distance to speed up large-k queries in quantization indexes by up to 3.8 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BBC improves quantization-based ANN indexes for large-k queries by replacing conventional top-k collectors with a bucket-based result buffer that organizes candidates into distance buckets, reducing ranking costs and cache misses while enabling lightweight final selection, together with two re-ranking algorithms that cut either candidate volume or cache misses depending on the underlying quantizer.
What carries the argument
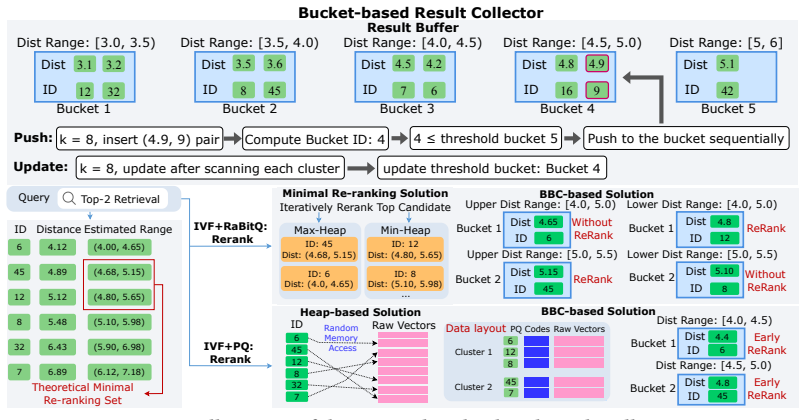
Bucket-based result buffer that organizes candidates into buckets by distance to the query for efficient superset maintenance and top-k selection.
If this is right
- Existing quantization-based ANN indexes gain substantial speed for large-k queries without altering their core structure.
- Re-ranking overhead drops by limiting candidates examined or by improving memory access patterns.
- Cache efficiency rises during candidate ranking and selection phases.
- The same collector works across multiple quantization methods while preserving recall.
- Final top-k extraction becomes a lightweight step after bucket organization.
Where Pith is reading between the lines
- The same bucket organization could be tested on non-quantization ANN indexes that also produce large candidate sets.
- Applications that vary k at runtime might benefit from adaptive bucket sizing tuned to expected result cardinality.
- Index designers facing high-k workloads may need to treat result collection as a first-class optimization target rather than an afterthought.
- Direct measurement of cache miss rates before and after BBC on new hardware would confirm the memory-efficiency mechanism.
Load-bearing premise
Grouping candidates by distance reduces ranking costs and cache misses enough to offset the overhead of maintaining the buckets.
What would settle it
Running BBC-augmented indexes against standard large-k ANN benchmarks and measuring no reduction in query time or cache misses would disprove the acceleration claim.
Figures






read the original abstract
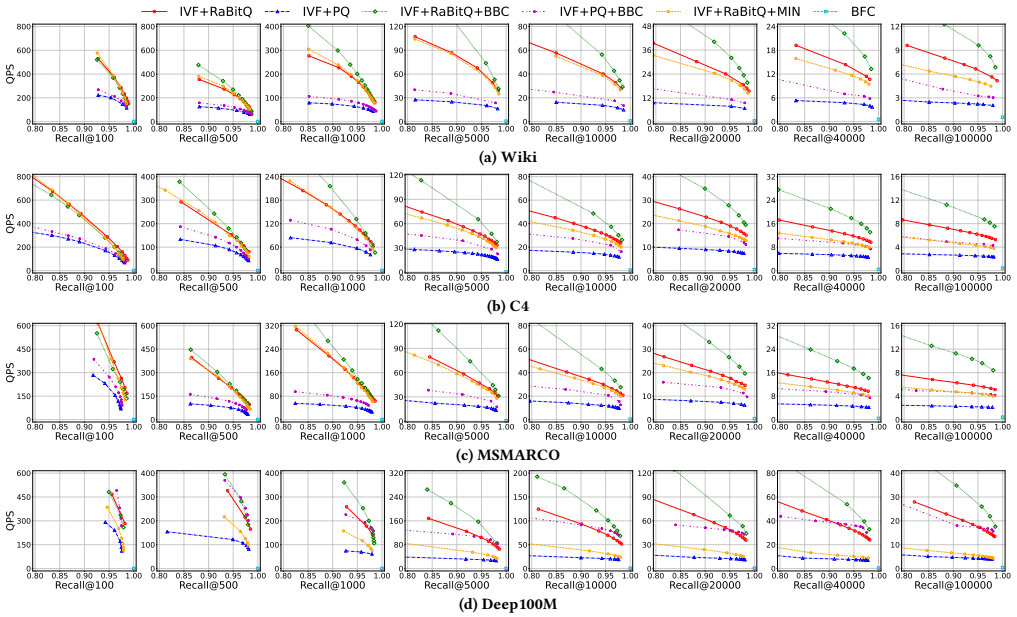
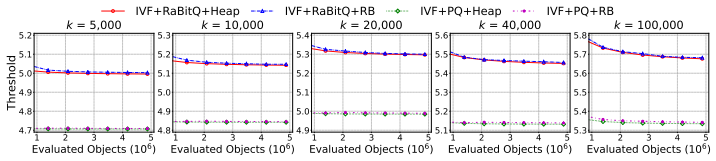
Although Approximate Nearest Neighbor (ANN) search has been extensively studied, large-k ANN queries that aim to retrieve a large number of nearest neighbors remain underexplored, despite their numerous real-world applications. Existing ANN methods face significant performance degradation for such queries. In this work, we first investigate the reasons for the performance degradation of quantization-based ANN indexes: (1) the inefficiency of existing top-k collectors, which incurs significant overhead in candidate maintenance, and (2) the reduced pruning effectiveness of quantization methods, which leads to a costly re-ranking process. To address this, we propose a novel bucket-based result collector (BBC) to enhance the efficiency of existing quantization-based ANN indexes for large-k ANN queries. BBC introduces two key components: (1) a bucket-based result buffer that organizes candidates into buckets by their distances to the query. This design reduces ranking costs and improves cache efficiency, enabling high performance maintenance of a candidate superset and a lightweight final selection of top-k results. (2) two re-ranking algorithms tailored for different types of quantization methods, which accelerate their re-ranking process by reducing either the number of candidate objects to be re-ranked or cache misses. Extensive experiments on real-world datasets demonstrate that BBC accelerates existing quantization-based ANN methods by up to 3.8x at recall@k = 0.95 for large-k ANN queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BBC, a bucket-based result collector, to address performance degradation in quantization-based ANN indexes for large-k queries. It identifies two issues—inefficient top-k candidate maintenance and reduced pruning effectiveness leading to costly re-ranking—and introduces a distance-bucketed buffer for candidate organization plus two tailored re-ranking algorithms. Experiments on real-world datasets are reported to yield speedups of up to 3.8× at recall@k = 0.95.
Significance. If the claimed speedups are robustly verified with full experimental controls, the work would offer a practical, low-overhead enhancement to existing quantization indexes without altering their core structure. This could benefit database applications involving large-k retrieval (e.g., recommendation or analytics workloads) by improving cache behavior and reducing ranking costs in the high-candidate regime.
major comments (2)
- [Abstract] Abstract: the central performance claim of up to 3.8× speedup at recall@k=0.95 is presented without any description of datasets, quantization methods, baselines, number of trials, or variance; this leaves the offset between bucket-maintenance overhead and saved ranking/cache work unverifiable, especially for the large-superset regime the method targets.
- [Abstract] The design rationale (bucket insertion and re-ranking) assumes that organizing candidates by distance reduces ranking costs enough to offset linear bucket-maintenance overhead; no analytic bound or worst-case analysis is supplied for the case when quantization pruning returns a very large candidate superset, which is precisely the operating point emphasized in the paper.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the range of k values tested and the specific recall@k target used for the 3.8× figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the request for stronger analytical support. We address each major comment below and will revise the manuscript to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of up to 3.8× speedup at recall@k=0.95 is presented without any description of datasets, quantization methods, baselines, number of trials, or variance; this leaves the offset between bucket-maintenance overhead and saved ranking/cache work unverifiable, especially for the large-superset regime the method targets.
Authors: We agree that the abstract would benefit from additional context to make the speedup claim more self-contained. In the revision we will expand the abstract with a brief clause noting that the results are obtained on standard real-world datasets using common quantization-based indexes (with full details on baselines, number of trials, and variance reported in the experimental section). Due to strict length limits we cannot embed every experimental parameter in the abstract itself, but the added sentence will allow readers to immediately locate the supporting evidence and verify the net benefit of bucket maintenance versus ranking savings. revision: partial
-
Referee: [Abstract] The design rationale (bucket insertion and re-ranking) assumes that organizing candidates by distance reduces ranking costs enough to offset linear bucket-maintenance overhead; no analytic bound or worst-case analysis is supplied for the case when quantization pruning returns a very large candidate superset, which is precisely the operating point emphasized in the paper.
Authors: We acknowledge that a formal analytic bound would strengthen the design rationale. The current manuscript supplies extensive empirical measurements (Section 5) across increasing candidate-superset sizes that demonstrate the bucket-maintenance cost is more than offset by reduced ranking and cache-miss overhead. In the revision we will add a short cost-model paragraph in the design section that contrasts the amortized O(1) bucket insertion with the O(n log n) cost of full sorting or the full re-ranking scan, and we will explicitly discuss the regime where the superset size greatly exceeds k. While a complete worst-case proof is not provided, the added model together with the existing empirical data will address the concern for the targeted operating point. revision: yes
Circularity Check
No circularity: structural proposal with empirical validation
full rationale
The paper identifies performance bottlenecks in quantization-based ANN for large-k queries via investigation, then introduces BBC as a bucket-organized buffer plus two re-ranking algorithms. No equations, parameter fits, or derivations are present that reduce to inputs by construction. No self-citations serve as load-bearing uniqueness theorems or ansatzes. The speedup claims rest on experimental measurements rather than self-referential logic, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BBC introduces a bucket-based result buffer that organizes candidates into buckets by their distances to the query... reduces ranking costs and improves cache efficiency
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two re-ranking algorithms tailored for different types of quantization methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Charu C Aggarwal, Alexander Hinneburg, and Daniel A Keim. 2001. On the surprising behavior of distance metrics in high dimensional space. InInternational conference on database theory. 420–434
work page 2001
-
[2]
Cecilia Aguerrebere, Ishwar Singh Bhati, Mark Hildebrand, Mariano Tepper, and Theodore L. Willke. 2023. Similarity search in the blink of an eye with compressed indices.Proc. VLDB Endow.16, 11 (2023), 3433–3446
work page 2023
-
[3]
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2015. Cache locality is not enough: High-Performance Nearest Neighbor Search with Product Quantization Fast Scan.Proc. VLDB Endow.9, 4 (2015), 288–299
work page 2015
-
[4]
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2017. Accel- erated Nearest Neighbor Search with Quick ADC. InProceedings of the 2017 ACM on International Conference on Multimedia Retrieval, ICMR 2017, Bucharest, Romania, June 6-9, 2017. 159–166
work page 2017
-
[5]
Akhil Arora, Sakshi Sinha, Piyush Kumar, and Arnab Bhattacharya. 2018. HD- Index: Pushing the Scalability-Accuracy Boundary for Approximate kNN Search in High-Dimensional Spaces.Proceedings of the VLDB Endowment11, 8 (2018), 906–919
work page 2018
-
[6]
Martin Aumüller, Erik Bernhardsson, and Alexander John Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Inf. Syst.87 (2020)
work page 2020
-
[7]
Martin Aumüller and Matteo Ceccarello. 2023. Recent Approaches and Trends in Approximate Nearest Neighbor Search, with Remarks on Benchmarking.IEEE Data Eng. Bull.47, 3 (2023), 89–105
work page 2023
-
[8]
Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2025. Graph-based vector search: An experimental evaluation of the state-of-the-art.Proceedings of the ACM on Management of Data3, 1 (2025), 1–31
work page 2025
- [9]
-
[10]
Alina Beygelzimer, Sham M. Kakade, and John Langford. 2006. Cover Trees for Nearest Neighbor. InMachine Learning, Proceedings of the Twenty-Third International Conference (ICML 2006), Pittsburgh, Pennsylvania, USA, June 25-29, 2006 (ACM International Conference Proceeding Series), Vol. 148. 97–104
work page 2006
-
[11]
Paolo Ciaccia, Marco Patella, and Pavel Zezula. 1997. M-tree: An E cient access method for similarity search in metric spaces. InProceedings of the 23rd VLDB conference, Athens, Greece. 426–435
work page 1997
- [12]
-
[13]
Blelloch, Laxman Dhulipala, Yan Gu, Harsha Vardhan Simhadri, and Yihan Sun
Magdalen Dobson, Zheqi Shen, Guy E. Blelloch, Laxman Dhulipala, Yan Gu, Harsha Vardhan Simhadri, and Yihan Sun. 2023. Scaling Graph-Based ANNS Al- gorithms to Billion-Size Datasets: A Comparative Analysis.CoRRabs/2305.04359 (2023)
-
[14]
Karima Echihabi, Themis Palpanas, and Kostas Zoumpatianos. 2021. New Trends in High-d Vector Similarity Search: AI-Driven, Progressive, and Distributed.Proc. VLDB Endow.14, 12 (2021), 3198–3201
work page 2021
-
[15]
Hakan Ferhatosmanoglu, Ertem Tuncel, Divyakant Agrawal, and Amr El Abbadi
-
[16]
InProceedings of the ninth international conference on Information and knowledge management
Vector approximation based indexing for non-uniform high dimensional data sets. InProceedings of the ninth international conference on Information and knowledge management. 202–209
-
[17]
Michael L Fredman and Robert Endre Tarjan. 1987. Fibonacci heaps and their uses in improved network optimization algorithms.Journal of the ACM (JACM) 34, 3 (1987), 596–615
work page 1987
-
[18]
Cong Fu, Changxu Wang, and Deng Cai. 2022. High Dimensional Similarity Search with Satellite System Graph: Efficiency, Scalability, and Unindexed Query Compatibility.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 8 (2022), 4139–4150
work page 2022
-
[19]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast Approximate Nearest Neighbor Search with the Navigating Spreading-out Graph.Proceedings of the VLDB Endowment12, 5 (2019), 461–474
work page 2019
-
[20]
Junhao Gan, Jianlin Feng, Qiong Fang, and Wilfred Ng. 2012. Locality-Sensitive Hashing Scheme Based on Dynamic Collision Counting. InProceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2012, Scottsdale, AZ, USA, May 20-24, 2012. 541–552
work page 2012
-
[21]
Jianyang Gao, Yutong Gou, Yuexuan Xu, Yongyi Yang, Cheng Long, and Raymond Chi-Wing Wong. 2025. Practical and asymptotically optimal quantization of high-dimensional vectors in euclidean space for approximate nearest neighbor search.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
work page 2025
-
[22]
Jianyang Gao and Cheng Long. 2024. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search.Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
work page 2024
-
[23]
Weihao Gao, Xiangjun Fan, Chong Wang, Jiankai Sun, Kai Jia, Wenzi Xiao, Ruofan Ding, Xingyan Bin, Hui Yang, and Xiaobing Liu. 2021. Learning an end-to-end structure for retrieval in large-scale recommendations. InProceedings of the 30th ACM international conference on information & knowledge management. 524–533. 13
work page 2021
-
[24]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2014. Optimized Product Quantization.IEEE Trans. Pattern Anal. Mach. Intell.36, 4 (2014), 744–755
work page 2014
-
[25]
Yunchao Gong, Svetlana Lazebnik, Albert Gordo, and Florent Perronnin. 2013. Iterative Quantization: A Procrustean Approach to Learning Binary Codes for Large-Scale Image Retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence35, 12 (2013), 2916–2929
work page 2013
-
[26]
Yutong Gou, Jianyang Gao, Yuexuan Xu, and Cheng Long. 2025. SymphonyQG: Towards Symphonious Integration of Quantization and Graph for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 1 (2025), 80:1–80:26
work page 2025
-
[27]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Vol. 119. 3887–3896
work page 2020
-
[28]
Ben Harwood and Tom Drummond. 2016. Fanng: Fast approximate nearest neighbour graphs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5713–5722
work page 2016
-
[29]
Jae-Pil Heo, Youngwoon Lee, Junfeng He, Shih-Fu Chang, and Sung-Eui Yoon
-
[30]
Spherical Hashing: Binary Code Embedding with Hyperspheres.IEEE Trans. Pattern Anal. Mach. Intell.37, 11 (2015), 2304–2316
work page 2015
-
[31]
Qiang Huang, Jianlin Feng, Yikai Zhang, Qiong Fang, and Wilfred Ng. 2015. Query-Aware Locality-Sensitive Hashing for Approximate Nearest Neighbor Search.Proc. VLDB Endow.9, 1 (2015), 1–12
work page 2015
-
[32]
Piotr Indyk and Rajeev Motwani. 1998. Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. InProceedings of the Thirtieth Annual ACM Symposium on the Theory of Computing, Dallas, Texas, USA, May 23-26,
work page 1998
-
[33]
Yahoo Japan. 2018. Neighborhood Graph and Tree for Indexing High-dimensional Data. https://github.com/yahoojapan/NGT. Accessed: 2024-04-17
work page 2018
-
[34]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information pro- cessing Systems32 (2019)
work page 2019
-
[35]
H Jégou, M Douze, and C Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Transactions on Pattern Analysis and Machine Intelligence 33, 1 (2011), 117–128
work page 2011
-
[36]
Wenqi Jiang, Shigang Li, Yu Zhu, Johannes de Fine Licht, Zhenhao He, Runbin Shi, Cédric Renggli, Shuai Zhang, Theodoros Rekatsinas, Torsten Hoefler, and Gustavo Alonso. 2023. Co-design Hardware and Algorithm for Vector Search. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC 2023, Denver, C...
work page 2023
-
[37]
Donald B Johnson. 1975. Priority queues with update and finding minimum spanning trees.Inform. Process. Lett.4, 3 (1975), 53–57
work page 1975
-
[38]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
work page 2019
-
[39]
Sujay Khandagale, Bhawna Juneja, Prabhat Agarwal, Aditya Subramanian, Jae- won Yang, and Yuting Wang. 2025. InteractRank: Personalized Web-Scale Search Pre-Ranking with Cross Interaction Features. InCompanion Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025 - 2 May 2025. 287–295
work page 2025
-
[40]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
work page 2020
-
[41]
Daniel H Larkin, Siddhartha Sen, and Robert E Tarjan. 2014. A back-to-basics empirical study of priority queues. In2014 Proceedings of the Sixteenth Workshop on Algorithm Engineering and Experiments (ALENEX). SIAM, 61–72
work page 2014
-
[42]
Jinhyuk Lee, Zhuyun Dai, Sai Meher Karthik Duddu, Tao Lei, Iftekhar Naim, Ming-Wei Chang, and Vincent Zhao. 2023. Rethinking the role of token retrieval in multi-vector retrieval.Advances in Neural Information Processing Systems36 (2023), 15384–15405
work page 2023
-
[43]
Yifan Lei, Qiang Huang, Mohan S. Kankanhalli, and Anthony K. H. Tung. 2020. Locality-Sensitive Hashing Scheme Based on Longest Circular Co-Substring. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, Online Conference [Portland, or, USA], June 14-19, 2020. 2589– 2599
work page 2020
-
[44]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
work page 2020
-
[45]
Conglong Li, Minjia Zhang, David G. Andersen, and Yuxiong He. 2020. Im- proving Approximate Nearest Neighbor Search through Learned Adaptive Early Termination. InProceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020. 2539–2554
work page 2020
-
[46]
Jinfeng Li, Xiao Yan, Jie Zhang, An Xu, James Cheng, Jie Liu, Kelvin Kai Wing Ng, and Ti-Chung Cheng. 2018. A General and Efficient Querying Method for Learning to Hash. InProceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15,
work page 2018
-
[47]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data — Experiments, Analyses, and Improvement.IEEE Transactions on Knowl- edge and Data Engineering32, 8 (2020), 1475–1488
work page 2020
-
[48]
Kejing Lu, Hongya Wang, Wei Wang, and Mineichi Kudo. 2020. VHP: Approxi- mate Nearest Neighbor Search via Virtual Hypersphere Partitioning.Proc. VLDB Endow.13, 9 (2020), 1443–1455
work page 2020
-
[49]
Varun Malhotra and Christos Kozyrakis. 2006. Library-based prefetching for pointer-intensive applications. InTechnical report. Computer Systems Laboratory, Stanford University
work page 2006
-
[50]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[51]
Approximate Nearest Neighbor Algorithm Based on Navigable Small World Graphs. 45 (2014), 61–68
work page 2014
-
[52]
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence42, 4 (2020), 824– 836
work page 2020
-
[53]
Yu A Malkov and Dmitry A Yashunin. 2020. hnswlib: Hierarchical Navigable Small World graphs. https://github.com/nmslib/hnswlib. Accessed: 2025-09-09
work page 2020
-
[54]
Julieta Martinez, Shobhit Zakhmi, Holger H. Hoos, and James J. Little. 2018. LSQ++: Lower Running Time and Higher Recall in Multi-codebook Quantization. InComputer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XVI (Lecture Notes in Computer Science), Vol. 11220. 508–523
work page 2018
-
[55]
Yusuke Matsui, Ryota Hinami, and Shin’ichi Satoh. 2018. Reconfigurable inverted index. InProceedings of the 26th ACM international conference on Multimedia. 1715–1723
work page 2018
-
[56]
Yusuke Matsui, Yusuke Uchida, Hervé Jégou, and Shin’ichi Satoh. 2018. A Survey of Product Quantization.ITE Transactions on Media Technology and Applications 6, 1 (2018), 2–10
work page 2018
-
[57]
Yusuke Matsui, Toshihiko Yamasaki, and Kiyoharu Aizawa. 2015. Pqtable: Fast exact asymmetric distance neighbor search for product quantization using hash tables. InProceedings of the IEEE International Conference on Computer Vision. 1940–1948
work page 2015
- [58]
-
[59]
Jason Mohoney, Anil Pacaci, Shihabur Rahman Chowdhury, Ali Mousavi, Ihab F Ilyas, Umar Farooq Minhas, Jeffrey Pound, and Theodoros Rekatsinas. 2023. High-throughput vector similarity search in knowledge graphs.Proceedings of the ACM on Management of Data1, 2 (2023), 1–25
work page 2023
-
[60]
Hamid Mousavi and Carlo Zaniolo. 2011. Fast and accurate computation of equi-depth histograms over data streams. InProceedings of the 14th international conference on extending database technology. 69–80
work page 2011
-
[61]
M Muralikrishna and David J DeWitt. 1988. Equi-depth multidimensional his- tograms. InProceedings of the 1988 ACM SIGMOD international conference on Management of data. 28–36
work page 1988
-
[62]
Parth Nagarkar and K Selçuk Candan. 2018. Pslsh: An index structure for efficient execution of set queries in high-dimensional spaces. InProceedings of the 27th ACM International Conference on Information and Knowledge Management. 477– 486
work page 2018
-
[63]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Survey of vector database management systems.VLDB J.33, 5 (2024), 1591–1615
work page 2024
-
[64]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Vector Database Manage- ment Techniques and Systems. InCompanion of the 2024 International Conference on Management of Data. Santiago AA Chile, 597–604
work page 2024
-
[65]
John Paparrizos, Ikraduya Edian, Chunwei Liu, Aaron J. Elmore, and Michael J. Franklin. 2022. Fast Adaptive Similarity Search through Variance-Aware Quan- tization. In38th IEEE International Conference on Data Engineering, ICDE 2022, Kuala Lumpur, Malaysia, May 9-12, 2022. 2969–2983
work page 2022
-
[66]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS. Proceedings of the VLDB Endowment18, 11 (2025), 4171–4184
work page 2025
-
[67]
Marco Patella and Paolo Ciaccia. 2009. Approximate similarity search: A multi- faceted problem.Journal of Discrete Algorithms7, 1 (2009), 36–48
work page 2009
-
[68]
Ninh Pham and Tao Liu. 2022. Falconn++: A locality-sensitive filtering ap- proach for approximate nearest neighbor search.Advances in Neural Information Processing Systems35 (2022), 31186–31198
work page 2022
-
[69]
Gregory Piatetsky-Shapiro and Charles Connell. 1984. Accurate estimation of the number of tuples satisfying a condition.ACM Sigmod Record14, 2 (1984), 256–276
work page 1984
-
[70]
Jeffrey Pound, Floris Chabert, Arjun Bhushan, Ankur Goswami, Anil Pacaci, and Shihabur Rahman Chowdhury. 2025. MicroNN: An On-device Disk-resident Updatable Vector Database. InCompanion of the 2025 International Conference on Management of Data. 608–621. 14
work page 2025
-
[71]
William Pugh. 1990. Skip lists: a probabilistic alternative to balanced trees. Commun. ACM33, 6 (1990), 668–676
work page 1990
-
[72]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
work page 2020
-
[73]
Parikshit Ram and Kaushik Sinha. 2019. Revisiting Kd-Tree for Nearest Neighbor Search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8,
work page 2019
-
[74]
Patrick Schäfer, Jakob Brand, Ulf Leser, Botao Peng, and Themis Palpanas
- [75]
-
[76]
Harsha Vardhan Simhadri, George Williams, Martin Aumüller, Matthijs Douze, Artem Babenko, Dmitry Baranchuk, Qi Chen, Lucas Hosseini, Ravishankar Krish- naswamny, Gopal Srinivasa, et al. 2022. Results of the NeurIPS’21 challenge on billion-scale approximate nearest neighbor search. InNeurIPS 2021 Competitions and Demonstrations Track. 177–189
work page 2022
-
[77]
Nikos Sismanis, Nikos Pitsianis, and Xiaobai Sun. 2012. Parallel search of k- nearest neighbors with synchronous operations. In2012 IEEE Conference on High Performance Extreme Computing. IEEE, 1–6
work page 2012
-
[78]
Yifang Sun, Wei Wang, Jianbin Qin, Ying Zhang, and Xuemin Lin. 2014. SRS: solving c-approximate nearest neighbor queries in high dimensional euclidean space with a tiny index.Proceedings of the VLDB Endowment(2014)
work page 2014
-
[79]
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Going deeper with convolutions. InProceedings of the IEEE conference on computer vision and pattern recognition. 1–9
work page 2015
-
[80]
Xiaoxin Tang, Zhiyi Huang, David Eyers, Steven Mills, and Minyi Guo. 2015. Effi- cient selection algorithm for fast k-nn search on gpus. In2015 IEEE International Parallel and Distributed Processing Symposium. IEEE, 397–406
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.