Recognition: no theorem link
Adam's Law: Textual Frequency Law on Large Language Models
Pith reviewed 2026-05-13 21:50 UTC · model grok-4.3
The pith
Frequent textual expressions improve LLM performance when used in prompts and for fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Textual Frequency Law states that frequent textual data should be preferred for LLMs for both prompting and fine-tuning. The authors estimate sentence-level frequency from online resources, apply an input paraphraser to produce more frequent expressions, use Textual Frequency Distillation by querying models for story completions to refine frequency estimates, and introduce Curriculum Textual Frequency Training that fine-tunes models in order of increasing sentence frequency. Results on the Textual Frequency Paired Dataset demonstrate effectiveness across math reasoning, machine translation, commonsense reasoning, and agentic tool calling.
What carries the argument
Textual Frequency Law (TFL), which ranks sentence-level frequency estimated from public online text and orders both prompting paraphrases and fine-tuning curriculum by that ranking.
Load-bearing premise
Sentence-level frequency counts taken from current online sources accurately match the distribution of text the target LLMs originally saw during training, and paraphrasing keeps task meaning intact while raising frequency.
What would settle it
The same tasks and models show no improvement or clear degradation when prompts and fine-tuning data are replaced by higher-frequency paraphrases and curriculum ordering compared with the original lower-frequency versions.
Figures

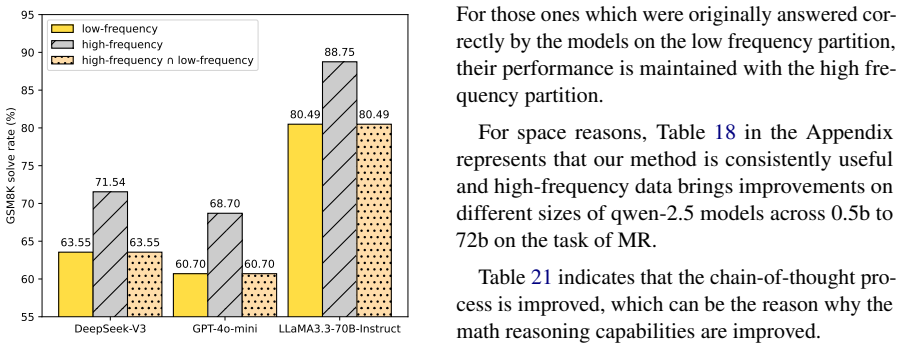



read the original abstract
While textual frequency has been validated as relevant to human cognition in reading speed, its relatedness to Large Language Models (LLMs) is seldom studied. We propose a novel research direction in terms of textual data frequency, which is an understudied topic, to the best of our knowledge. Our framework is composed of three units. First, this paper proposes Textual Frequency Law (TFL), which indicates that frequent textual data should be preferred for LLMs for both prompting and fine-tuning. Since many LLMs are closed-source in their training data, we propose using online resources to estimate the sentence-level frequency. We then utilize an input paraphraser to paraphrase the input into a more frequent textual expression. Next, we propose Textual Frequency Distillation (TFD) by querying LLMs to conduct story completion by further extending the sentences in the datasets, and the resulting corpora are used to adjust the initial estimation. Finally, we propose Curriculum Textual Frequency Training (CTFT) that fine-tunes LLMs in an increasing order of sentence-level frequency. Experiments are conducted on our curated dataset Textual Frequency Paired Dataset (TFPD) on math reasoning, machine translation, commonsense reasoning and agentic tool calling. Results show the effectiveness of our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Textual Frequency Law (TFL), which states that textual data with higher sentence-level frequency should be preferred for both prompting and fine-tuning of LLMs. Frequency is estimated exclusively from online resources (as training corpora are closed), refined via an input paraphraser and Textual Frequency Distillation (TFD) that queries LLMs for story completions to extend sentences and adjust estimates, and applied through Curriculum Textual Frequency Training (CTFT) that orders fine-tuning by increasing frequency. Effectiveness is asserted via experiments on the curated Textual Frequency Paired Dataset (TFPD) across math reasoning, machine translation, commonsense reasoning, and agentic tool calling tasks.
Significance. If the frequency estimates can be shown to correlate with the models' actual training distributions and the circularity issues are resolved, the framework could provide a practical, proxy-based method for data selection and augmentation in LLMs without access to proprietary corpora. It would extend frequency effects from human cognition studies to LLM training and introduce a curriculum strategy grounded in textual frequency, potentially improving efficiency on reasoning and generation tasks.
major comments (3)
- [TFD method] TFD description: Querying the same class of LLMs to generate story completions that directly adjust the frequency estimates used for subsequent training creates a circular loop; model outputs shape the training signal, so any gains on TFPD tasks cannot be unambiguously attributed to a general textual frequency law rather than model-specific artifacts or surface properties.
- [Experiments on TFPD] Experiments section: No quantitative results, baselines, statistical tests, ablation studies, or validation details (e.g., how online frequency estimates were correlated with model likelihoods or how paraphrases were checked for semantic equivalence) are supplied, leaving the data-to-claim link unassessable and undermining support for TFL.
- [Introduction and frequency estimation] Frequency estimation assumption (Introduction and §3): The central claim requires that sentence-level frequency from current online resources positively correlates with the original training distribution of the target LLMs. No correlation analysis, proxy validation, or sensitivity test is presented; if the proxy is misaligned, observed improvements cannot be read as evidence for TFL.
minor comments (2)
- [Abstract] Abstract: The statement that 'results show the effectiveness of our framework' is unsupported by any metrics or comparisons; this should be revised to reflect the actual content of the experimental section.
- [Methods] Notation: 'Sentence-level frequency' is used without a precise definition or formula (e.g., whether it is raw count, normalized probability, or n-gram based); add an explicit equation in the methods section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, acknowledging limitations in the current draft and outlining specific revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [TFD method] TFD description: Querying the same class of LLMs to generate story completions that directly adjust the frequency estimates used for subsequent training creates a circular loop; model outputs shape the training signal, so any gains on TFPD tasks cannot be unambiguously attributed to a general textual frequency law rather than model-specific artifacts or surface properties.
Authors: We appreciate the concern regarding potential circularity. The initial sentence-level frequency estimates are derived exclusively from independent online resources, separate from any LLM used in our experiments. The TFD step employs story completion solely to extend sentences and refine those external estimates by capturing broader contextual usage patterns; the generated text is not used as training data. Training and evaluation remain on the original TFPD tasks, with frequency serving only as an ordering signal for CTFT. To further address model-specific artifacts, we will add an ablation comparing performance with and without the TFD refinement step. revision: partial
-
Referee: [Experiments on TFPD] Experiments section: No quantitative results, baselines, statistical tests, ablation studies, or validation details (e.g., how online frequency estimates were correlated with model likelihoods or how paraphrases were checked for semantic equivalence) are supplied, leaving the data-to-claim link unassessable and undermining support for TFL.
Authors: We acknowledge that the current manuscript draft omits the required quantitative details, baselines, statistical tests, and validation procedures. This is a clear gap. In the revision we will include complete experimental tables with performance metrics across all tasks, comparisons to baselines such as random ordering and reverse-frequency curriculum, statistical significance tests, full ablations for the paraphraser, TFD, and CTFT components, and validation of paraphrases via semantic equivalence metrics such as BERTScore. revision: yes
-
Referee: [Introduction and frequency estimation] Frequency estimation assumption (Introduction and §3): The central claim requires that sentence-level frequency from current online resources positively correlates with the original training distribution of the target LLMs. No correlation analysis, proxy validation, or sensitivity test is presented; if the proxy is misaligned, observed improvements cannot be read as evidence for TFL.
Authors: We agree that explicit validation of the online proxy is essential. Because training corpora are closed, we adopted online resources as the most practical proxy. In the revised manuscript we will add a dedicated subsection reporting correlation analysis between our online frequency estimates and likelihoods obtained from open-source models on held-out data, together with sensitivity tests across different online sources and time windows. revision: yes
Circularity Check
TFD uses LLM outputs to adjust frequency estimates later applied to train the same LLMs
specific steps
-
fitted input called prediction
[Abstract]
"we propose Textual Frequency Distillation (TFD) by querying LLMs to conduct story completion by further extending the sentences in the datasets, and the resulting corpora are used to adjust the initial estimation."
Initial sentence-level frequency (from online resources) is updated using completions generated by the target LLMs; the adjusted frequencies are then fed into CTFT to order fine-tuning of those same LLMs. The training signal therefore contains a component statistically derived from the model's own generations rather than remaining an independent external measure.
full rationale
The derivation chain is mostly self-contained: TFL is stated as a hypothesis, online frequency is an external proxy, paraphraser and CTFT are downstream applications. The single load-bearing circular step occurs in TFD, where LLM-generated story completions directly modify the frequency values that CTFT then uses to order fine-tuning of those LLMs. This creates a partial self-referential loop (fitted frequency parameter incorporates model output), but does not render the entire TFL claim or experimental results equivalent to the inputs by construction. No self-citation chains, uniqueness theorems, or ansatz smuggling are present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frequent textual data is preferred by LLMs for prompting and fine-tuning
Reference graph
Works this paper leans on
-
[1]
Amirhossein Abaskohi, Sascha Rothe, and Yadollah Yaghoobzadeh. 2023. https://doi.org/10.18653/v1/2023.acl-short.59 LM - CPPF : Paraphrasing-guided data augmentation for contrastive prompt-based few-shot fine-tuning . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 670--681, Toronto...
-
[2]
A. Alexandrov, D. Boricheva, F. Pulverm \"u ller, and Y Shtyrov. 2011. Strength of word-specific neural memory traces assessed electrophysiologically. PLoS ONE, 6(8):e22999
work page 2011
-
[3]
Marta Ba \ n \'o n, Pinzhen Chen, Barry Haddow, Kenneth Heafield, Hieu Hoang, Miquel Espl \`a -Gomis, Mikel L. Forcada, Amir Kamran, Faheem Kirefu, Philipp Koehn, Sergio Ortiz Rojas, Leopoldo Pla Sempere, Gema Ram \'i rez-S \'a nchez, Elsa Sarr \'i as, Marek Strelec, Brian Thompson, William Waites, Dion Wiggins, and Jaume Zaragoza. 2020. https://doi.org/1...
-
[4]
Bowen Cao, Deng Cai, Zhisong Zhang, Yuexian Zou, and Wai Lam. 2024. https://openreview.net/forum?id=Mi853QaJx6 On the worst prompt performance of large language models . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
work page 2024
-
[5]
Karl Cobbe , Vineet Kosaraju , Mohammad Bavarian , Mark Chen , Heewoo Jun , Lukasz Kaiser , Matthias Plappert , Jerry Tworek , Jacob Hilton , Reiichiro Nakano , Christopher Hesse , and John Schulman . 2021. https://doi.org/10.48550/arXiv.2110.14168 Training Verifiers to Solve Math Word Problems . arXiv e-prints, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168 2021
-
[6]
DeepSeek-AI , Daya Guo , Dejian Yang , Haowei Zhang , Junxiao Song , Ruoyu Zhang , Runxin Xu , Qihao Zhu , Shirong Ma , Peiyi Wang , Xiao Bi , Xiaokang Zhang , Xingkai Yu , Yu Wu , Z. F. Wu , Zhibin Gou , Zhihong Shao , Zhuoshu Li , Ziyi Gao , Aixin Liu , Bing Xue , Bingxuan Wang , Bochao Wu , Bei Feng , Chengda Lu , Chenggang Zhao , Chengqi Deng , Chenyu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[7]
DeepSeek-AI , Aixin Liu , Bei Feng , Bing Xue , Bingxuan Wang , Bochao Wu , Chengda Lu , Chenggang Zhao , Chengqi Deng , Chenyu Zhang , Chong Ruan , Damai Dai , Daya Guo , Dejian Yang , Deli Chen , Dongjie Ji , Erhang Li , Fangyun Lin , Fucong Dai , Fuli Luo , Guangbo Hao , Guanting Chen , Guowei Li , H. Zhang , Han Bao , Hanwei Xu , Haocheng Wang , Haowe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[8]
Rutvik H Desai, Wonil Choi, and John M Henderson. 2020. https://doi.org/10.1080/23273798.2018.1527376 Word frequency effects in naturalistic reading . Language, cognition and neuroscience, 35(5):583—594
-
[9]
David Freedman, Robert Pisani, and Roger Purves. 2007. Statistics (international student edition). Pisani, R. Purves, 4th edn. WW Norton & Company, New York
work page 2007
-
[10]
Silin Gao, Yichi Zhang, Zhijian Ou, and Zhou Yu. 2020. https://doi.org/10.18653/v1/2020.acl-main.60 Paraphrase augmented task-oriented dialog generation . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 639--649, Online. Association for Computational Linguistics
-
[11]
Tanya Goyal and Greg Durrett. 2020. https://doi.org/10.18653/v1/2020.acl-main.22 Neural syntactic preordering for controlled paraphrase generation . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 238--252, Online. Association for Computational Linguistics
-
[12]
Aaron Grattafiori , Abhimanyu Dubey , Abhinav Jauhri , Abhinav Pandey , Abhishek Kadian , Ahmad Al-Dahle , Aiesha Letman , Akhil Mathur , Alan Schelten , Alex Vaughan , Amy Yang , Angela Fan , Anirudh Goyal , Anthony Hartshorn , Aobo Yang , Archi Mitra , Archie Sravankumar , Artem Korenev , Arthur Hinsvark , Arun Rao , Aston Zhang , Aurelien Rodriguez , A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[13]
Zhen Guo, Peiqi Wang, Yanwei Wang, and Shangdi Yu. 2023. https://github.com/zguo0525/Dr.llama Dr. llama: Improving small language models in domain-specific qa via generative data augmentation
work page 2023
-
[14]
Yanjin He, Qingkai Zeng, and Meng Jiang. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1421 Pre-trained models perform the best when token distributions follow Z ipf ' s law . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28009--28021, Suzhou, China. Association for Computational Linguistics
-
[15]
Kris Heylen, Yves Peirsman, Dirk Geeraerts, and Dirk Speelman. 2008. https://aclanthology.org/L08-1204/ Modelling word similarity: an evaluation of automatic synonymy extraction algorithms. In Proceedings of the Sixth International Conference on Language Resources and Evaluation ( LREC `08) , Marrakech, Morocco. European Language Resources Association (ELRA)
work page 2008
-
[16]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
work page 2022
-
[17]
Hanxu Hu, Hongyuan Lu, Huajian Zhang, Yun-Ze Song, Wai Lam, and Yue Zhang. 2024. https://openreview.net/forum?id=Hvq9RtSoHG Chain-of-symbol prompting for spatial reasoning in large language models . In First Conference on Language Modeling
work page 2024
-
[18]
Shadi Iskander, Sofia Tolmach, Ori Shapira, Nachshon Cohen, and Zohar Karnin. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.285 Quality matters: Evaluating synthetic data for tool-using LLM s . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4958--4976, Miami, Florida, USA. Association for Computational...
-
[19]
Lu Jiang, Deyu Meng, Shoou-I Yu, Zhenzhong Lan, Shiguang Shan, and Alexander G. Hauptmann. 2014. Self-paced learning with diversity. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, NIPS'14, page 2078–2086, Cambridge, MA, USA. MIT Press
work page 2014
-
[20]
Jing Jin and Houfeng Wang. 2024. https://aclanthology.org/2024.lrec-main.1267/ Select high-quality synthetic QA pairs to augment training data in MRC under the reward guidance of generative language models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 1...
work page 2024
-
[21]
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. https://doi.org/10.18653/v1/2020.acl-main.560 The state and fate of linguistic diversity and inclusion in the NLP world . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6282--6293, Online. Association for Computational...
-
[22]
Goro Kobayashi, Tatsuki Kuribayashi, Sho Yokoi, and Kentaro Inui. 2023. https://doi.org/10.18653/v1/2023.findings-acl.276 Transformer language models handle word frequency in prediction head . In Findings of the Association for Computational Linguistics: ACL 2023, pages 4523--4535, Toronto, Canada. Association for Computational Linguistics
-
[23]
Hongyuan Lu and Wai Lam. 2023. https://doi.org/10.18653/v1/2023.eacl-main.5 PCC : Paraphrasing with bottom-k sampling and cyclic learning for curriculum data augmentation . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 68--82, Dubrovnik, Croatia. Association for Computational Linguistics
-
[24]
Hongyuan Lu , Haoran Yang , Haoyang Huang , Dongdong Zhang , Wai Lam , and Furu Wei . 2023. https://doi.org/10.48550/arXiv.2305.06575 Chain-of-Dictionary Prompting Elicits Translation in Large Language Models . arXiv e-prints, arXiv:2305.06575
-
[25]
Nikolay Mikhaylovskiy. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.837 Z ipf ' s and heaps' laws for tokens and LLM -generated texts . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 15469--15481, Suzhou, China. Association for Computational Linguistics
-
[26]
Ranjini Mohan and Christine Weber. 2019. https://doi.org/10.1080/13825585.2018.1519105 Neural activity reveals effects of aging on inhibitory processes during word retrieval . Aging, Neuropsychology, and Cognition, 26(5):660--687. PMID: 30223706
-
[27]
Niklas Muennighoff , Zitong Yang , Weijia Shi , Xiang Lisa Li , Li Fei-Fei , Hannaneh Hajishirzi , Luke Zettlemoyer , Percy Liang , Emmanuel Cand \`e s , and Tatsunori Hashimoto . 2025. https://doi.org/10.48550/arXiv.2501.19393 s1: Simple test-time scaling . arXiv e-prints, arXiv:2501.19393
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.19393 2025
-
[28]
NLLB-Team. 2022. No language left behind: Scaling human-centered machine translation
work page 2022
-
[29]
Byung-Doh Oh, Shisen Yue, and William Schuler. 2024. https://aclanthology.org/2024.eacl-long.162/ Frequency explains the inverse correlation of large language models' size, training data amount, and surprisal`s fit to reading times . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: L...
work page 2024
-
[30]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://doi.org/10.3115/1073083.1073135 B leu: a method for automatic evaluation of machine translation . In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311--318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics
-
[31]
Maja Popovi \'c . 2015. https://doi.org/10.18653/v1/W15-3049 chr F : character n-gram F -score for automatic MT evaluation . In Proceedings of the Tenth Workshop on Statistical Machine Translation, pages 392--395, Lisbon, Portugal. Association for Computational Linguistics
-
[32]
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.213 COMET : A neural framework for MT evaluation . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685--2702, Online. Association for Computational Linguistics
-
[33]
Robyn Speer. 2022. https://doi.org/10.5281/zenodo.7199437 rspeer/wordfreq: v3.0
-
[34]
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS'14, page 3104–3112, Cambridge, MA, USA. MIT Press
work page 2014
-
[35]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. https://doi.org/10.18653/v1/N19-1421 C ommonsense QA : A question answering challenge targeting commonsense knowledge . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[36]
Tianyi Tang, Hongyuan Lu, Yuchen Jiang, Haoyang Huang, Dongdong Zhang, Xin Zhao, Tom Kocmi, and Furu Wei. 2024. https://doi.org/10.18653/v1/2024.naacl-long.367 Not all metrics are guilty: Improving NLG evaluation by diversifying references . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistic...
-
[37]
Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. 2023. https://doi.org/10.18653/v1/2023.acl-long.153 Towards understanding chain-of-thought prompting: An empirical study of what matters . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2717--2...
-
[38]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2024. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA. Curran Associates Inc
work page 2024
-
[39]
Sam Witteveen and Martin Andrews. 2019. https://doi.org/10.18653/v1/D19-5623 Paraphrasing with large language models . In Proceedings of the 3rd Workshop on Neural Generation and Translation, pages 215--220, Hong Kong. Association for Computational Linguistics
-
[40]
Wenhao Zhu , Pinzhen Chen , Hanxu Hu , Shujian Huang , Fei Yuan , Jiajun Chen , and Alexandra Birch . 2025. https://doi.org/10.48550/arXiv.2502.15592 Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning . arXiv e-prints, arXiv:2502.15592
-
[41]
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. 2024 a . https://doi.org/10.18653/v1/2024.findings-naacl.176 Multilingual machine translation with large language models: Empirical results and analysis . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 2765--2781, Mexi...
-
[42]
Wenhong Zhu, Hongkun Hao, Zhiwei He, Yun-Ze Song, Jiao Yueyang, Yumeng Zhang, Hanxu Hu, Yiran Wei, Rui Wang, and Hongyuan Lu. 2024 b . https://doi.org/10.18653/v1/2024.findings-naacl.53 CLEAN -- EVAL : Clean evaluation on contaminated large language models . In Findings of the Association for Computational Linguistics: NAACL 2024, pages 835--847, Mexico C...
-
[43]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[44]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.