The Expert Strikes Back: Interpreting Mixture-of-Experts Language Models at Expert Level
Pith reviewed 2026-05-21 09:32 UTC · model grok-4.3
The pith
Mixture-of-Experts models have less polysemantic neurons than dense networks, enabling expert-level interpretation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
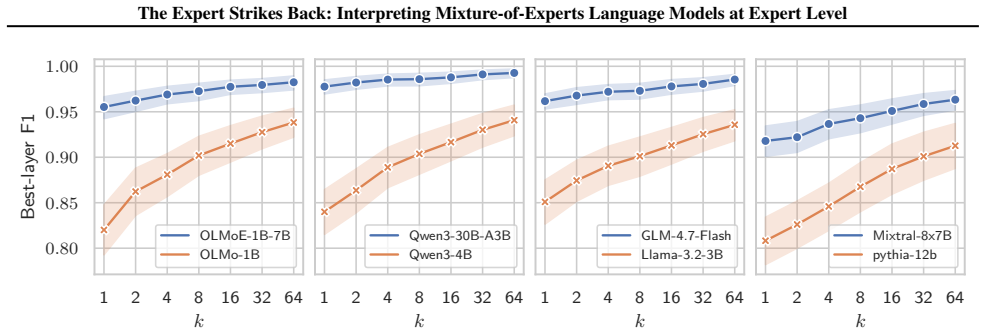
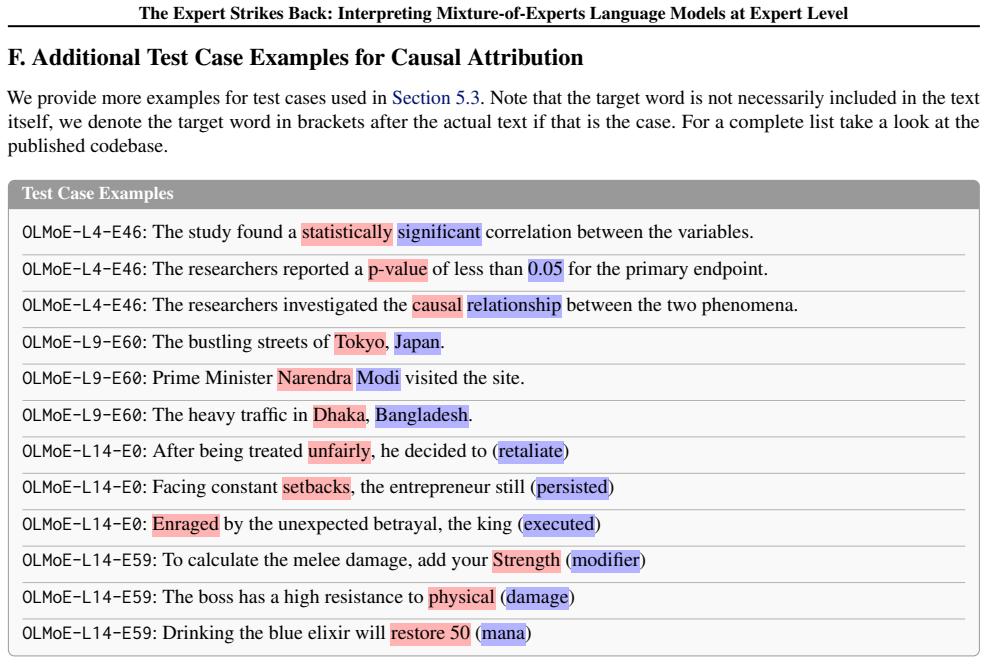
The central discovery is that expert neurons in Mixture-of-Experts language models are consistently less polysemantic than neurons in dense feed-forward networks when measured by k-sparse probing, with the gap increasing as the routing becomes sparser. This supports the idea that sparsity encourages monosemantic representations. At the expert level, these components function as fine-grained task experts that handle specific linguistic operations or semantic tasks, such as closing brackets in LaTeX, rather than serving as broad domain specialists or simple token processors.
What carries the argument
k-sparse probing for comparing polysemanticity between expert and dense neurons, together with automated expert interpretation to classify their specializations.
If this is right
- Experts become a practical scale for analyzing and editing model behavior.
- Greater sparsity in routing may further reduce polysemanticity and improve interpretability.
- Large-scale interpretability efforts can target hundreds of experts instead of millions of neurons.
- Model capabilities can be attributed to specific task operations performed by individual experts.
Where Pith is reading between the lines
- Designers of future MoE models might deliberately increase routing sparsity to enhance interpretability.
- Techniques for editing or steering models could focus on activating or suppressing particular experts for targeted outputs.
- Similar analysis might reveal whether dense models contain hidden substructures that mimic expert-like specialization.
Load-bearing premise
That the k-sparse probing method reliably captures the true degree of polysemanticity independent of the specific datasets used for probing and the chosen sparsity parameter k.
What would settle it
Finding a probe dataset or sparsity level k where dense network neurons appear less polysemantic than MoE expert neurons would challenge the main result.
Figures













read the original abstract
Mixture-of-Experts (MoE) architectures have become the dominant choice for scaling Large Language Models (LLMs), activating only a subset of parameters per token. While MoE architectures are primarily adopted for computational efficiency, it remains an open question whether their sparsity makes them inherently easier to interpret than dense feed-forward networks (FFNs). We compare MoE experts and dense FFNs using $k$-sparse probing and find that expert neurons are consistently less polysemantic, with the gap widening as routing becomes sparser. This suggests that sparsity pressures both individual neurons and entire experts toward monosemanticity. Leveraging this finding, we zoom out from the neuron to the expert level as a more effective unit of analysis. We validate this approach by automatically interpreting hundreds of experts. This analysis allows us to resolve the debate on specialization: experts are neither broad domain specialists (e.g., biology) nor simple token-level processors. Instead, they function as fine-grained task experts, specializing in linguistic operations or semantic tasks (e.g., closing brackets in $\LaTeX{}$). Our findings suggest that MoEs are inherently interpretable at the expert level, providing a clearer path toward large-scale model interpretability. Code is available at: https://github.com/jerryy33/MoE_analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Mixture-of-Experts (MoE) language models are inherently more interpretable than dense feed-forward networks because expert neurons exhibit lower polysemanticity (as measured by k-sparse probing), with this gap widening under sparser routing. It further claims that experts function as fine-grained task specialists (e.g., linguistic operations such as bracket closing in LaTeX) rather than broad domain or token-level processors, validated through automatic interpretation of hundreds of experts, and concludes that MoEs provide a clearer path to large-scale interpretability.
Significance. If the empirical results hold after addressing methodological controls, the work would offer a practical shift in interpretability analysis from individual neurons to the expert level in MoE models, along with evidence that sparsity induces monosemanticity. The public availability of code at https://github.com/jerryy33/MoE_analysis is a strength that supports reproducibility of the probing and interpretation pipelines.
major comments (2)
- [Abstract] Abstract: the central claim that expert neurons are consistently less polysemantic than those in dense FFNs, with the gap widening as routing becomes sparser, rests on k-sparse probing without reported ablations on probe dataset composition, cross-model normalization of the sparsity level k, or sensitivity tests. This leaves open the possibility that the measured gap arises from interactions between native MoE routing and the fixed probe distribution rather than intrinsic monosemanticity.
- [Abstract] Abstract (validation step): the automatic interpretation of hundreds of experts to resolve the specialization debate lacks detail on the probe construction, clustering or labeling procedure, and controls for selection bias or inter-expert consistency, making it difficult to assess whether the fine-grained task specialization (e.g., LaTeX bracket closing) is robust or an artifact of the chosen examples.
minor comments (1)
- [Abstract] The abstract refers to 'linguistic operations or semantic tasks' without providing concrete quantitative metrics (e.g., activation frequencies or task-specific accuracy) that would allow readers to gauge the granularity of specialization.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and robustness of our work. We address each major comment in detail below, providing additional methodological details and ablations where necessary.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that expert neurons are consistently less polysemantic than those in dense FFNs, with the gap widening as routing becomes sparser, rests on k-sparse probing without reported ablations on probe dataset composition, cross-model normalization of the sparsity level k, or sensitivity tests. This leaves open the possibility that the measured gap arises from interactions between native MoE routing and the fixed probe distribution rather than intrinsic monosemanticity.
Authors: We acknowledge the importance of these controls to rule out confounds. In the revised manuscript, we include new experiments ablating the probe dataset composition using both in-distribution and out-of-distribution probes. We also normalize k by the average activation sparsity per model and perform sensitivity analysis for k values around the chosen level. These additional results confirm that the polysemanticity gap is robust and not an artifact of the probe distribution or routing interaction. We have added a dedicated paragraph in the methods and results sections describing these ablations. revision: yes
-
Referee: [Abstract] Abstract (validation step): the automatic interpretation of hundreds of experts to resolve the specialization debate lacks detail on the probe construction, clustering or labeling procedure, and controls for selection bias or inter-expert consistency, making it difficult to assess whether the fine-grained task specialization (e.g., LaTeX bracket closing) is robust or an artifact of the chosen examples.
Authors: We agree that additional details on the interpretation pipeline are warranted. We have revised the manuscript to provide a comprehensive description of the automatic interpretation method, including: the construction of activation probes from a diverse set of inputs, the use of hierarchical clustering followed by automated labeling with a language model and human verification, and controls such as shuffling expert labels to test for bias and measuring consistency across different data subsets. These additions demonstrate that the observed fine-grained specializations are consistent and not due to selection bias or specific examples. A new appendix details the full procedure and reports quantitative consistency metrics. revision: yes
Circularity Check
No circularity: empirical comparison via external k-sparse probing
full rationale
The paper reports direct empirical measurements of polysemanticity using k-sparse probing on MoE experts versus dense FFNs, followed by automated interpretation of expert activations. No equations, fitted parameters, or self-citations are shown to reduce the reported specialization gap or task-expert findings to quantities defined by the authors' own inputs. The central claims rest on observed activation patterns over probe data rather than any self-definitional or tautological construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparsity level k
axioms (1)
- domain assumption k-sparse probing measures the number of distinct concepts a unit participates in
Reference graph
Works this paper leans on
-
[1]
https://transformer-circuits.pub/2025/ attribution-graphs/methods.html. Bills, S., Cammarata, N., Mossing, D., Tillman, H., Gao, L., Goh, G., Sutskever, I., Leike, J., Wu, J., and Saunders, W. Language models can explain neurons in language models. https://openaipublic.blob.core.windows. net/neuron-explainer/paper/index.html, 2023. Bricken, T., Templeton,...
work page 2025
-
[2]
Chaudhari, M., Nuer, J., and Thorstenson, R
https://transformer-circuits.pub/2023/ monosemantic-features/index.html. Chaudhari, M., Nuer, J., and Thorstenson, R. Superposition in mixture of experts. InMechanistic Interpretability Workshop at NeurIPS 2025, 2025. Chughtai, B., Cooney, A., and Nanda, N. Summing up the facts: Additive mechanisms behind factual recall in llms. arXiv preprint arXiv:2402....
-
[3]
https://transformer-circuits.pub/2021/ framework/index.html. Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., Grosse, R., McCandlish, S., Kaplan, J., Amodei, D., Wattenberg, M., and Olah, C. Toy mod- els of superposition.Transformer Circuits Thread, 10 The Expert Strikes Back: ...
work page 2021
-
[4]
arXiv preprint arXiv:2511.13653 , year =
https://transformer-circuits.pub/2022/ toy_model/index.html. Gao, L., Rajaram, A., Coxon, J., Govande, S. V ., Baker, B., and Mossing, D. Weight-sparse transformers have in- terpretable circuits.arXiv preprint arXiv:2511.13653, 2025. Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. InProceed- ings of...
-
[5]
Tokens routed to this expert are wrapped in double asterisks (e.g., **token**)
<snippet>: The raw text. Tokens routed to this expert are wrapped in double asterisks (e.g., **token**)
-
[6]
-'score': The obtained score for that token
<top_activations>: A list of the top active tokens in that snippet (up to 5), sorted by an importance score (Router Weight * Output L2 Norm). -'score': The obtained score for that token. -'token_str': The string representation. -'promoted_tokens': The top 3 tokens the expert predicted next (Logit Lens). </data_structure> <guidelines>
-
[7]
**Analyze Density:** Does the expert activate sporadically (specific entities) or continuously (syntactic blocks)?
-
[8]
**Consult Logit Lens:** Use the'promoted_tokens'to understand the *effect* of the expert. If an expert activates on'New', and promotes'York','Zealand','Jersey', it is a named-entity completer
-
[9]
Find the common thread across all examples
**Generalize:** Do not overfit to a single example. Find the common thread across all examples
-
[10]
**Formatting:** Ignore the`**`markers when analyzing the natural flow of text; they are only for highlighting. </guidelines> EXPLAINER USER PROMPT <context> Here are the maximal activating examples for Expert 17. </context> <data> <example id="1"> <snippet> and whistles” you need to create more complex** quizzes** and** surveys**. These** are** the** feat...
-
[11]
A **Hypothesis** describing the function of a specific MoE Expert
-
[12]
text": "A short text snippet where you would expect the MoE expert to be active
A list of **Test Examples**. Each example contains a text snippet, where active tokens are highlighted with double asterisks (e.g., **token**). Your job is to determine: **Does the highlighted token pattern in the example match the Hypothesis?** - If the highlighted tokens fit the hypothesis description: Output 1. - If the highlighted tokens clearly viola...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.