Recognition: 2 theorem links
· Lean TheoremUAV-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models
Pith reviewed 2026-05-13 21:37 UTC · model grok-4.3
The pith
UAV-Track VLA adds temporal compression and a dual-branch decoder to vision-language-action models for better aerial tracking in simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
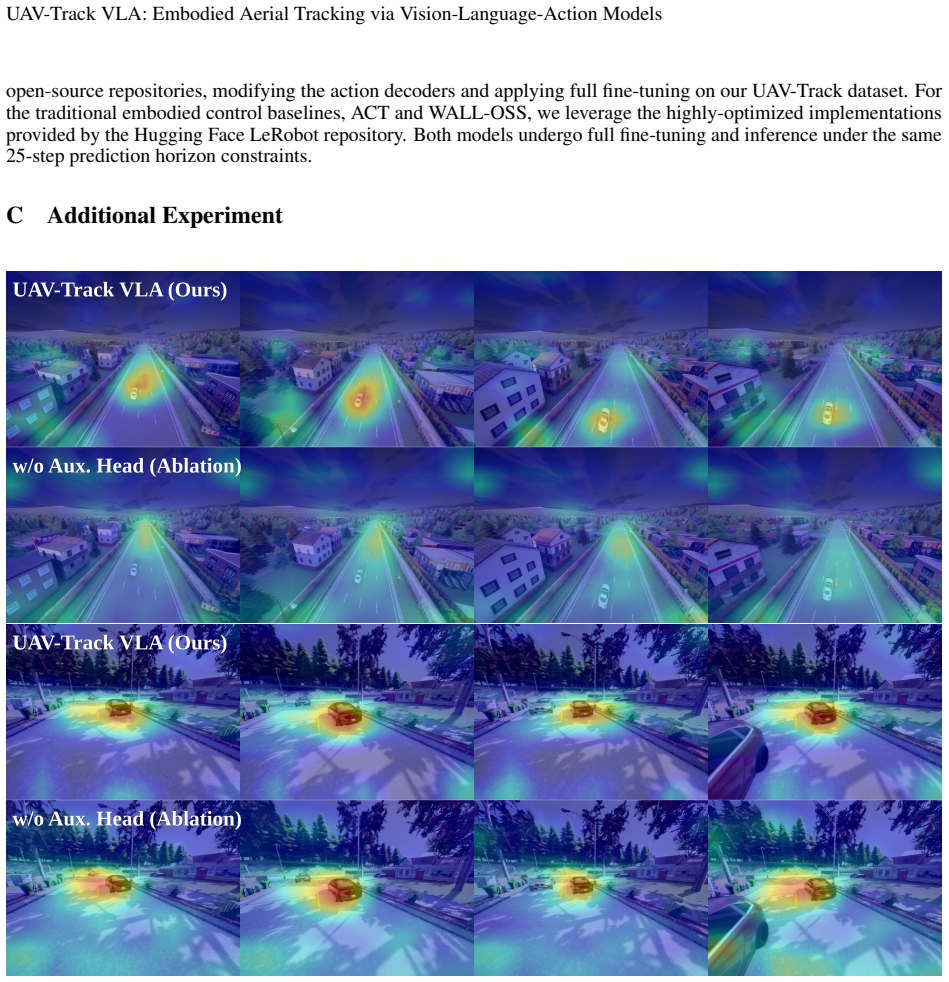
UAV-Track VLA, built on the π0.5 base, introduces a temporal compression net to capture inter-frame dynamics and a parallel dual-branch decoder that separates cross-modal features into a spatial-aware auxiliary grounding head and a flow-matching action expert; this yields end-to-end superior performance over baselines, including 61.76 percent success rate and 269.65 average tracking frames on challenging long-distance pedestrian tasks together with 33.4 percent lower inference latency at 0.0571 seconds per step.
What carries the argument
The UAV-Track VLA model, which uses a temporal compression net for inter-frame dynamics and a parallel dual-branch decoder to decouple features for continuous action output.
If this is right
- Higher success rates and longer continuous tracking in long-distance pedestrian tasks within simulated urban environments.
- Lower single-step inference time that supports real-time UAV control loops.
- Zero-shot generalization to previously unseen simulated environments.
- A new public benchmark and 890K-frame dataset for evaluating multimodal aerial tracking.
Where Pith is reading between the lines
- Hardware-in-the-loop testing on actual UAVs would be needed to check whether sensor noise or wind affects the reported latency and success gains.
- The same temporal-compression and dual-branch pattern could be tested on ground-based robots to see if the efficiency benefits transfer beyond aerial platforms.
- Integration with existing flight controllers might allow the model to replace separate perception and planning modules in current UAV stacks.
Load-bearing premise
Strong results inside the CARLA simulator will carry over to real UAV hardware without further adaptation.
What would settle it
Running the trained UAV-Track VLA controller on physical drone hardware and measuring success rate plus average tracking duration in actual long-distance pedestrian scenarios.
Figures




read the original abstract
Embodied visual tracking is crucial for Unmanned Aerial Vehicles (UAVs) executing complex real-world tasks. In dynamic urban scenarios with complex semantic requirements, Vision-Language-Action (VLA) models show great promise due to their cross-modal fusion and continuous action generation capabilities. To benchmark multimodal tracking in such environments, we construct a dedicated evaluation benchmark and a large-scale dataset encompassing over 890K frames, 176 tasks, and 85 diverse objects. Furthermore, to address temporal feature redundancy and the lack of spatial geometric priors in existing VLA models, we propose an improved VLA tracking model, UAV-Track VLA. Built upon the $\pi_{0.5}$ architecture, our model introduces a temporal compression net to efficiently capture inter-frame dynamics. Additionally, a parallel dual-branch decoder comprising a spatial-aware auxiliary grounding head and a flow matching action expert is designed to decouple cross-modal features and generate fine-grained continuous actions. Systematic experiments in the CARLA simulator validate the superior end-to-end performance of our method. Notably, in challenging long-distance pedestrian tracking tasks, UAV-Track VLA achieves a 61.76\% success rate and 269.65 average tracking frames, significantly outperforming existing baselines. Furthermore, it demonstrates robust zero-shot generalization in unseen environments and reduces single-step inference latency by 33.4\% (to 0.0571s) compared to the original $\pi_{0.5}$, enabling highly efficient, real-time UAV control. Data samples and demonstration videos are available at: https://github.com/Hub-Tian/UAV-Track_VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UAV-Track VLA, a Vision-Language-Action model for embodied aerial tracking on UAVs in dynamic urban scenes. It constructs a new benchmark and dataset (>890K frames, 176 tasks, 85 objects) and proposes architectural extensions to the π_{0.5} base model: a temporal compression net for inter-frame dynamics and a parallel dual-branch decoder (spatial-aware grounding head + flow-matching action expert). All quantitative results are obtained in the CARLA simulator, where the method reports a 61.76% success rate and 269.65 average tracking frames on long-distance pedestrian tasks, plus a 33.4% latency reduction to 0.0571 s per step, outperforming baselines and showing zero-shot generalization in unseen simulated environments.
Significance. If the simulation results hold under real conditions, the work would provide a valuable new large-scale multimodal dataset and benchmark for UAV tracking with semantic requirements, together with concrete architectural improvements that demonstrably raise success rates and lower latency inside CARLA. These elements could accelerate research on embodied VLA systems for aerial platforms.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The headline claims of enabling 'highly efficient, real-time UAV control' in dynamic urban scenes rest entirely on CARLA simulation results (61.76% success rate, 269.65 frames, 0.0571 s latency). No physical UAV hardware trials, sensor-noise injection, or sim-to-real transfer analysis are provided, which is load-bearing for the embodied-tracking contribution.
- [§4] §4 and associated tables: No error bars, standard deviations, or statistical significance tests accompany the reported success rates, average tracking frames, or latency figures. This makes it impossible to judge whether the claimed outperformance over baselines is robust.
- [§3] §3 (Method): The temporal compression net and dual-branch decoder are introduced without sufficient implementation details (exact layer counts, compression ratios, loss weights, or integration points with π_{0.5}), hindering reproducibility of the reported latency and accuracy gains.
minor comments (2)
- The manuscript states that data samples and videos are available at the cited GitHub repository but does not indicate whether the full 890K-frame dataset and benchmark code will be released under an open license.
- [§3] Notation for the base model (π_{0.5}) should be clarified on first use, including a brief reference to its original publication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The headline claims of enabling 'highly efficient, real-time UAV control' in dynamic urban scenes rest entirely on CARLA simulation results (61.76% success rate, 269.65 frames, 0.0571 s latency). No physical UAV hardware trials, sensor-noise injection, or sim-to-real transfer analysis are provided, which is load-bearing for the embodied-tracking contribution.
Authors: We acknowledge that all reported results are obtained in the CARLA simulator and that no real-world UAV hardware experiments or dedicated sim-to-real transfer studies are included. This is a substantive limitation for claims about embodied aerial tracking. In the revised manuscript we will add a new Limitations subsection in §4 that explicitly discusses the sim-to-real gap, including sensor noise, dynamics mismatch, and the need for future hardware validation. We will also run and report a preliminary robustness experiment that injects realistic Gaussian noise on RGB and depth observations and quantifies the resulting drop in success rate and tracking duration. Physical UAV trials lie beyond the scope of the current revision but are planned for follow-up work. revision: partial
-
Referee: [§4] §4 and associated tables: No error bars, standard deviations, or statistical significance tests accompany the reported success rates, average tracking frames, or latency figures. This makes it impossible to judge whether the claimed outperformance over baselines is robust.
Authors: We agree that statistical measures are necessary to substantiate the reported gains. For the revised version we will re-run all experiments with five independent random seeds and report mean ± standard deviation for every metric (success rate, average tracking frames, and latency). We will additionally include paired t-test p-values comparing our method against each baseline to demonstrate statistical significance. These updates will appear in the tables and text of §4. revision: yes
-
Referee: [§3] §3 (Method): The temporal compression net and dual-branch decoder are introduced without sufficient implementation details (exact layer counts, compression ratios, loss weights, or integration points with π_{0.5}), hindering reproducibility of the reported latency and accuracy gains.
Authors: We appreciate the referee’s request for greater reproducibility. In the revised §3 we will supply the missing details: the temporal compression net consists of three convolutional layers achieving a 4:1 temporal compression ratio; the dual-branch decoder comprises a six-layer spatial-aware grounding head and an eight-layer flow-matching action expert; loss weights are set to λ_grounding = 0.3, λ_action = 1.0, λ_flow = 0.5; and both branches attach directly after the vision-language encoder of π_{0.5}. We will also release the complete training configuration files and updated code to allow exact reproduction of the latency and accuracy results. revision: yes
Circularity Check
No circularity: empirical benchmark on new simulator dataset with no self-referential derivations
full rationale
The paper constructs a new dataset (890K frames, 176 tasks) and benchmark, then evaluates an improved VLA model (temporal compression net + dual-branch decoder built on π0.5) exclusively via CARLA simulation experiments. Reported metrics (61.76% success, 269.65 frames, 33.4% latency reduction) are direct empirical outcomes on held-out and zero-shot simulator scenarios. No equations, parameter fits, or derivations are shown that reduce by construction to the same inputs; the architecture changes are independent design choices whose performance is measured externally to the training data. Self-citations, if present, are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CARLA simulator provides sufficiently realistic visual, temporal, and control dynamics for UAV tracking evaluation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Built upon the π0.5 architecture, our model introduces a temporal compression net... parallel dual-branch decoder comprising a spatial-aware auxiliary grounding head and a flow matching action expert
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Systematic experiments in the CARLA simulator... 61.76% success rate and 269.65 average tracking frames
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
The Unified Autonomy Stack: Toward a Blueprint for Generalizable Robot Autonomy
An open-sourced Unified Autonomy Stack fuses LiDAR, radar, vision and inertial data with sampling-based planning and control barrier functions to deliver resilient autonomy on aerial and ground robots in challenging r...
Reference graph
Works this paper leans on
-
[1]
Uavs meet llms: Overviews and perspectives towards agentic low-altitude mobility
Yonglin Tian, Fei Lin, Yiduo Li, Tengchao Zhang, Qiyao Zhang, Xuan Fu, Jun Huang, Xingyuan Dai, Yutong Wang, Chunwei Tian, et al. Uavs meet llms: Overviews and perspectives towards agentic low-altitude mobility. Information Fusion, 122:103158, 2025
work page 2025
-
[2]
Nianyi Sun, Jin Zhao, Qing Shi, Chang Liu, and Peng Liu. Moving target tracking by unmanned aerial vehicle: A survey and taxonomy.IEEE Transactions on Industrial Informatics, 20(5):7056–7068, 2024
work page 2024
-
[3]
Wahab Khawaja, Martins Ezuma, Vasilii Semkin, Fatih Erden, Ozgur Ozdemir, and Ismail Guvenc. A survey on detection, classification, and tracking of uavs using radar and communications systems.IEEE Communications Surveys & Tutorials, 2025
work page 2025
-
[4]
Yiming Li, Changhong Fu, Fangqiang Ding, Ziyuan Huang, and Geng Lu. Autotrack: Towards high-performance visual tracking for uav with automatic spatio-temporal regularization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
work page 2020
-
[5]
Adaptive and background-aware vision transformer for real-time uav tracking
Shuiwang Li, Yangxiang Yang, Dan Zeng, and Xucheng Wang. Adaptive and background-aware vision transformer for real-time uav tracking. InProceedings of the IEEE/CVF international conference on computer vision, pages 13989–14000, 2023
work page 2023
-
[6]
Yuanliang Xue, Tao Shen, Guodong Jin, Lining Tan, Nian Wang, Lianfeng Wang, and Jing Gao. Handling occlusion in uav visual tracking with query-guided redetection.IEEE Transactions on Instrumentation and Measurement, 73:1–17, 2024
work page 2024
-
[7]
Mao Xi, Yun Zhou, Zheng Chen, Wengang Zhou, and Houqiang Li. Anti-distractor active object tracking in 3d environments.IEEE Transactions on Circuits and Systems for Video Technology, 32(6):3697–3707, 2022
work page 2022
-
[8]
Open-world drone active tracking with goal-centered rewards
Haowei Sun, Jinwu Hu, Zhirui Zhang, Haoyuan Tian, Xinze Xie, Yufeng Wang, Xiaohua Xie, Yun Lin, Zhuliang Yu, and Mingkui Tan. Open-world drone active tracking with goal-centered rewards. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[9]
Alberto Dionigi, Simone Felicioni, Mirko Leomanni, and Gabriele Costante. D-vat: End-to-end visual active tracking for micro aerial vehicles.IEEE Robotics and Automation Letters, 9(6):5046–5053, 2024
work page 2024
-
[10]
Rt-1: Robotics transformer for real-world control at scale, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang- Huei Lee, Sergey Levine, Yao Lu, Utsav Malla,...
work page 2023
-
[11]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024
work page 2024
-
[12]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian 10 UA V-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James...
work page 2026
-
[13]
A survey on vision-language-action models for autonomous driving
Sicong Jiang, Zilin Huang, Kangan Qian, Ziang Luo, Tianze Zhu, Yang Zhong, Yihong Tang, Menglin Kong, Yunlong Wang, Siwen Jiao, et al. A survey on vision-language-action models for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4524–4536, 2025
work page 2025
-
[14]
Indooruav: Benchmarking vision-language uav navigation in continuous indoor environments, 2025
Xu Liu, Yu Liu, Hanshuo Qiu, Yang Qirong, and Zhouhui Lian. Indooruav: Benchmarking vision-language uav navigation in continuous indoor environments, 2025
work page 2025
-
[15]
Trackvla: Embodied visual tracking in the wild
Shaoan Wang, Jiazhao Zhang, Minghan Li, Jiahang Liu, Anqi Li, Kui Wu, Fangwei Zhong, Junzhi Yu, Zhizheng Zhang, and He Wang. Trackvla: Embodied visual tracking in the wild. In Joseph Lim, Shuran Song, and Hae-Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 4139–4164. PMLR,...
work page 2025
-
[16]
Yuze Wu, Mo Zhu, Xingxing Li, Yuheng Du, Yuxin Fan, Wenjun Li, Zhichao Han, Xin Zhou, and Fei Gao. Vla-an: An efficient and onboard vision-language-action framework for aerial navigation in complex environments, 2025
work page 2025
-
[17]
Dengdi Sun, Leilei Cheng, Song Chen, Chenglong Li, Yun Xiao, and Bin Luo. Uav-ground visual tracking: A unified dataset and collaborative learning approach.IEEE Transactions on Circuits and Systems for Video Technology, 34(5):3619–3632, 2023
work page 2023
-
[18]
You Wu, Yongxin Li, Mengyuan Liu, Xucheng Wang, Xiangyang Yang, Hengzhou Ye, Dan Zeng, Qijun Zhao, and Shuiwang Li. Learning an adaptive and view-invariant vision transformer for real-time uav tracking.IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[19]
Refdrone: A challenging benchmark for referring expression comprehension in drone scenes
Zhichao Sun, Yepeng Liu, Zhiling Su, Huachao Zhu, Yuliang Gu, Yuda Zou, Zelong Liu, Gui-Song Xia, Bo Du, and Yongchao Xu. Refdrone: A challenging benchmark for referring expression comprehension in drone scenes. arXiv preprint arXiv:2502.00392, 2025
-
[20]
Similarity-guided layer-adaptive vision transformer for uav tracking
Chaocan Xue, Bineng Zhong, Qihua Liang, Yaozong Zheng, Ning Li, Yuanliang Xue, and Shuxiang Song. Similarity-guided layer-adaptive vision transformer for uav tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6730–6740, June 2025
work page 2025
-
[21]
Wenhan Luo, Peng Sun, Fangwei Zhong, Wei Liu, Tong Zhang, and Yizhou Wang. End-to-end active object tracking and its real-world deployment via reinforcement learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(6):1317–1332, 2020
work page 2020
-
[22]
Qihui Wu, Jiahao Li, Fuhui Zhou, Jiahuan Ji, Haoyang Wang, Hongtao Liang, and Kai-Kuang Ma. Cognitive embodied learning for anomaly active target tracking.Communications Engineering, 4(1):224, Nov 2025
work page 2025
-
[23]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks, 2025
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks, 2025
work page 2025
-
[24]
Hierarchical instruction-aware embodied visual tracking, 2025
Kui Wu, Hao Chen, Churan Wang, Fakhri Karray, Zhoujun Li, Yizhou Wang, and Fangwei Zhong. Hierarchical instruction-aware embodied visual tracking, 2025
work page 2025
-
[25]
Kui Wu, Shuhang Xu, Hao Chen, Churan Wang, Zhoujun Li, Yizhou Wang, and Fangwei Zhong. Vlm can be a good assistant: Enhancing embodied visual tracking with self-improving vision-language models. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13154–13161, 2025
work page 2025
-
[26]
Jiahang Liu, Yunpeng Qi, Jiazhao Zhang, Minghan Li, Shaoan Wang, Kui Wu, Hanjing Ye, Hong Zhang, Zhibo Chen, Fangwei Zhong, Zhizheng Zhang, and He Wang. Trackvla++: Unleashing reasoning and memory capabilities in vla models for embodied visual tracking, 2025
work page 2025
-
[27]
Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai
Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, and Yizhou Wang. Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5769–5779, October 2025
work page 2025
-
[28]
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, Hao Niu, Wenxuan Ou, Wanli Peng, Zeyu Ren, Haixin Shi, Jiawen Tian, Hongtao Wu, Xin Xiao, Yuyang Xiao, Jiafeng Xu, and Yichu Yang. Gr-3 technical report, 2025
work page 2025
-
[29]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov...
work page 2023
-
[30]
Octo: An open-source generalist robot policy, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024
work page 2024
-
[31]
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual-language-action model.arXiv preprint arXiv:2505.21432, 2025
-
[32]
A dual process vla: Efficient robotic manipulation leveraging vlm, 2024
ByungOk Han, Jaehong Kim, and Jinhyeok Jang. A dual process vla: Efficient robotic manipulation leveraging vlm, 2024
work page 2024
-
[33]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, and Baining Guo. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation, 2024
work page 2024
-
[34]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page 2025
-
[35]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine Glossop, Thomas Godden, Ivan Goryachev, Lachy Groom, Hunter Hancock, Karol Hausman, Gashon Hussein, Brian Ichter, Szym...
work page 2025
-
[36]
Gr-rl: Going dexterous and precise for long-horizon robotic manipulation, 2025
Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhigang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, Wanli Peng, Jingchao Qiao, Zeyu Ren, Haixin Shi, Zhi Su, Jiawen Tian, Yuyang Xiao, Shenyu Zhang, Liwei Zheng, Hang Li, and Yonghui Wu. Gr-rl: Going dexterous and precise for long-horizon robotic manipulation, 2025
work page 2025
-
[37]
Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning, 2025
Xiangyu Wang, Donglin Yang, Yue Liao, Wenhao Zheng, wenjun wu, Bin Dai, Hongsheng Li, and Si Liu. Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning, 2025
work page 2025
-
[38]
Autofly: Vision-language-action model for uav autonomous navigation in the wild, 2026
Xiaolou Sun, Wufei Si, Wenhui Ni, Yuntian Li, Dongming Wu, Fei Xie, Runwei Guan, He-Yang Xu, Henghui Ding, Yuan Wu, Yutao Yue, Yongming Huang, and Hui Xiong. Autofly: Vision-language-action model for uav autonomous navigation in the wild, 2026
work page 2026
-
[39]
Navdreamer: Video models as zero-shot 3d navigators, 2026
Xijie Huang, Weiqi Gai, Tianyue Wu, Congyu Wang, Zhiyang Liu, Xin Zhou, Yuze Wu, and Fei Gao. Navdreamer: Video models as zero-shot 3d navigators, 2026
work page 2026
-
[40]
Racevla: Vla-based racing drone navigation with human-like behaviour, 2025
Valerii Serpiva, Artem Lykov, Artyom Myshlyaev, Muhammad Haris Khan, Ali Alridha Abdulkarim, Oleg Sautenkov, and Dzmitry Tsetserukou. Racevla: Vla-based racing drone navigation with human-like behaviour, 2025
work page 2025
-
[41]
Artem Lykov, Valerii Serpiva, Muhammad Haris Khan, Oleg Sautenkov, Artyom Myshlyaev, Grik Tadevosyan, Yasheerah Yaqoot, and Dzmitry Tsetserukou. Cognitivedrone: A vla model and evaluation benchmark for real-time cognitive task solving and reasoning in uavs, 2025
work page 2025
-
[42]
Air-vla: Vision-language-action systems for aerial manipulation, 2026
Jianli Sun, Bin Tian, Qiyao Zhang, Chengxiang Li, Zihan Song, Zhiyong Cui, Yisheng Lv, and Yonglin Tian. Air-vla: Vision-language-action systems for aerial manipulation, 2026
work page 2026
-
[43]
Herath Mpc Jayaweera and Samer Hanoun. A dynamic artificial potential field (d-apf) uav path planning technique for following ground moving targets.IEEE access, 8:192760–192776, 2020. 12 UA V-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models
work page 2020
-
[44]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Sigmoid loss for language image pre- training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[46]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023
work page 2023
-
[48]
Andy Zhai, Brae Liu, Bruno Fang, Chalse Cai, Ellie Ma, Ethan Yin, Hao Wang, Hugo Zhou, James Wang, Lights Shi, Lucy Liang, Make Wang, Qian Wang, Roy Gan, Ryan Yu, Shalfun Li, Starrick Liu, Sylas Chen, Vincent Chen, and Zach Xu. Igniting vlms toward the embodied space, 2025. 13 UA V-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models Appe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.