LLM Reasoning with Process Rewards for Outcome-Guided Steps
Pith reviewed 2026-05-16 06:40 UTC · model grok-4.3
The pith
Outcome-conditioned centering lets process rewards guide LLM reasoning steps without rewarding fluent errors that fail at the end.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
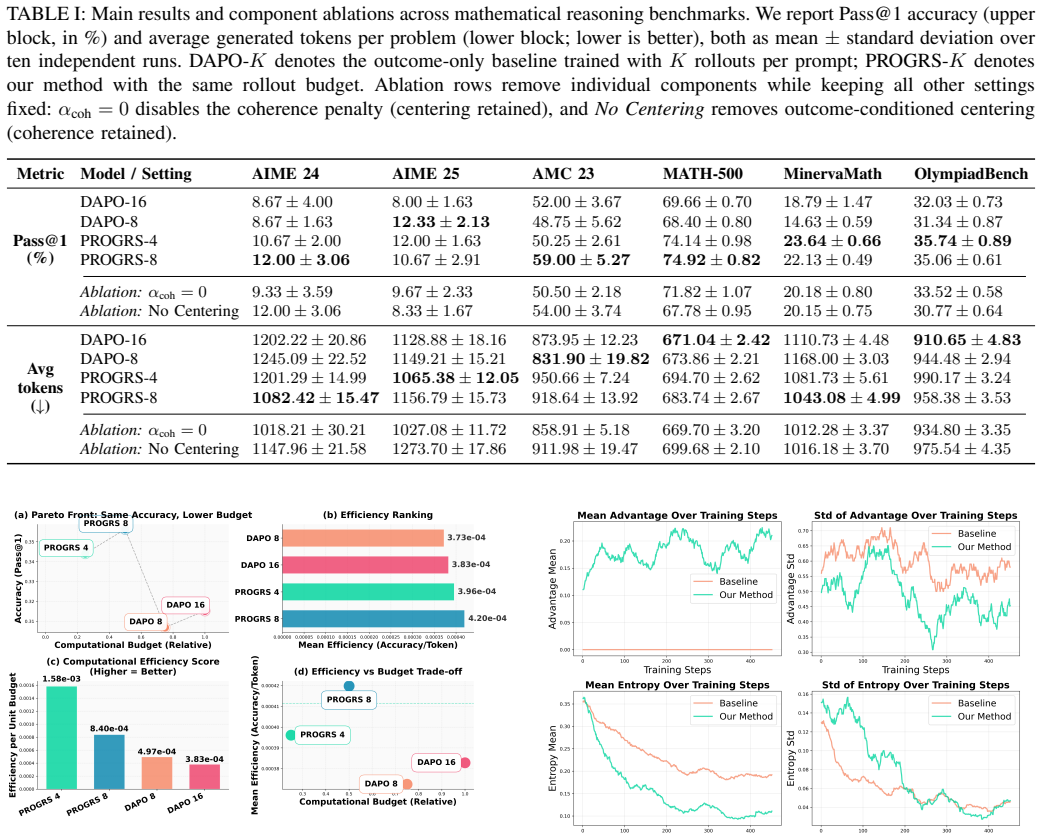
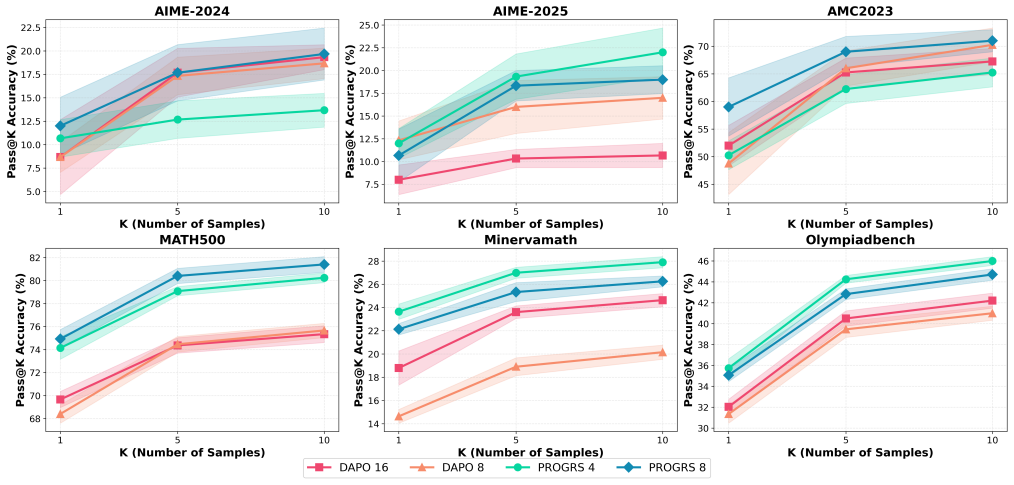
The central claim is that outcome-conditioned centering of PRM scores—shifting those of incorrect trajectories to zero mean within each prompt group—enables safe integration of process rewards into GRPO, yielding consistent Pass@1 gains on MATH-500, AMC, AIME, MinervaMath, and OlympiadBench without auxiliary objectives or additional components.
What carries the argument
Outcome-conditioned centering, which normalizes PRM scores of incorrect trajectories to zero mean inside each prompt group to remove bias while retaining relative rankings for step guidance.
If this is right
- Consistent Pass@1 improvements over outcome-only RL baselines on five mathematical reasoning datasets.
- Stronger final performance achieved with fewer rollouts during policy optimization.
- Integration of frozen PRM and coherence evaluator into GRPO without auxiliary losses or new trainable parameters.
- Reduced amplification of locally fluent but ultimately incorrect reasoning paths.
Where Pith is reading between the lines
- The same centering step could be tested on non-mathematical reasoning tasks where intermediate steps are scored but imperfectly aligned with outcomes.
- Fewer required rollouts may lower the total compute needed for effective RL fine-tuning of reasoning models.
- Extending the grouping to dynamic or cross-prompt clusters could further refine bias removal while keeping relative preferences.
Load-bearing premise
Shifting PRM scores of incorrect trajectories to zero mean within each prompt group removes systematic bias without discarding useful signal or introducing new misalignment.
What would settle it
A controlled run where models trained with the centered rewards still produce more fluent-but-wrong final answers than the outcome-only baseline, or show no accuracy gain on the same benchmarks with matched rollout counts.
Figures
read the original abstract
Mathematical reasoning in large language models has improved substantially with reinforcement learning using verifiable rewards, where final answers can be checked automatically and converted into reliable training signals. Most such pipelines optimize outcome correctness only, which yields sparse feedback for long, multi-step solutions and offers limited guidance on intermediate reasoning errors. Recent work therefore introduces process reward models (PRMs) to score intermediate steps and provide denser supervision. In practice, PRM scores are often imperfectly aligned with final correctness and can reward locally fluent reasoning that still ends in an incorrect answer. When optimized as absolute rewards, such signals can amplify fluent failure modes and induce reward hacking. We propose PROGRS, a framework that leverages PRMs while keeping outcome correctness dominant. PROGRS treats process rewards as relative preferences within outcome groups rather than absolute targets. We introduce outcome-conditioned centering, which shifts PRM scores of incorrect trajectories to have zero mean within each prompt group. It removes systematic bias while preserving informative rankings. PROGRS combines a frozen quantile-regression PRM with a multi-scale coherence evaluator. We integrate the resulting centered process bonus into Group Relative Policy Optimization (GRPO) without auxiliary objectives or additional trainable components. Across MATH-500, AMC, AIME, MinervaMath, and OlympiadBench, PROGRS consistently improves Pass@1 over outcome-only baselines and achieves stronger performance with fewer rollouts. These results show that outcome-conditioned centering enables safe and effective use of process rewards for mathematical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PROGRS, a framework for improving LLM mathematical reasoning via reinforcement learning. It combines a frozen quantile-regression process reward model (PRM) with a multi-scale coherence evaluator, applies outcome-conditioned centering that shifts PRM scores of incorrect trajectories to zero mean within each prompt group, and integrates the resulting process bonus into Group Relative Policy Optimization (GRPO) without auxiliary objectives. The central claim is that this approach yields consistent Pass@1 gains over outcome-only baselines on MATH-500, AMC, AIME, MinervaMath, and OlympiadBench while using fewer rollouts, by treating process rewards as relative preferences within outcome groups rather than absolute targets.
Significance. If the experimental controls hold, the work would demonstrate a practical way to obtain denser supervision from imperfect PRMs without amplifying fluent failure modes, by making the process signal relative to outcome correctness within prompt groups. This could improve sample efficiency and robustness in long-chain verifiable reasoning tasks.
major comments (3)
- [Abstract] Abstract: the claim of consistent Pass@1 gains provides no quantitative details on effect sizes, variance across runs, ablation of the centering step, or checks against post-hoc selection of prompt groups; the central claim therefore rests on unshown experimental controls.
- [Method] Outcome-conditioned centering (described in the method): shifting only incorrect trajectories to zero mean within prompt groups while leaving correct-trajectory scores unchanged creates an implicit assumption that absolute PRM levels on correct paths are comparable across prompts and to the zero-centered incorrect group; no analysis or sensitivity check is provided for prompt-dependent offsets or variance differences between correct and incorrect paths.
- [Experiments] Experiments section: no ablation isolates the contribution of outcome-conditioned centering from the multi-scale coherence evaluator or the frozen PRM choice, and no formal verification is given that the centered bonus remains additive to the binary outcome reward in GRPO without reintroducing misalignment.
minor comments (2)
- [Abstract] The abstract mentions the multi-scale coherence evaluator without a brief definition or citation, which would help readers understand its role in the pipeline.
- [Method] An explicit equation showing the modified GRPO objective with the centered process bonus would clarify the integration and make the method easier to reproduce.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and proposed revisions to strengthen the presentation of experimental controls and methodological assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent Pass@1 gains provides no quantitative details on effect sizes, variance across runs, ablation of the centering step, or checks against post-hoc selection of prompt groups; the central claim therefore rests on unshown experimental controls.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will expand the abstract to report absolute Pass@1 gains and standard deviations across three random seeds on each benchmark, and we will explicitly reference the ablation studies (Table 3 and Section 4.3) that isolate the centering step. Prompt groups are formed deterministically from the fixed benchmark prompts and their verifiable outcome correctness; no post-hoc selection occurs. We will add a clarifying sentence in the method section to this effect. revision: yes
-
Referee: [Method] Outcome-conditioned centering (described in the method): shifting only incorrect trajectories to zero mean within prompt groups while leaving correct-trajectory scores unchanged creates an implicit assumption that absolute PRM levels on correct paths are comparable across prompts and to the zero-centered incorrect group; no analysis or sensitivity check is provided for prompt-dependent offsets or variance differences between correct and incorrect paths.
Authors: We acknowledge the implicit assumption and appreciate the referee’s observation. The centering is applied only to incorrect trajectories because correct trajectories already receive the dominant binary outcome reward; the PRM signal on correct paths is used only for ranking within the group. To address potential prompt-dependent offsets, the revised version will include an appendix sensitivity study that perturbs correct-path PRM scores by ±0.1 and ±0.2 and reports that relative rankings and final Pass@1 remain stable. We will also add summary statistics comparing PRM score variance on correct versus incorrect trajectories across prompts. revision: partial
-
Referee: [Experiments] Experiments section: no ablation isolates the contribution of outcome-conditioned centering from the multi-scale coherence evaluator or the frozen PRM choice, and no formal verification is given that the centered bonus remains additive to the binary outcome reward in GRPO without reintroducing misalignment.
Authors: The experiments section already contains targeted ablations: Table 3 removes the centering step while keeping the coherence evaluator and frozen PRM fixed, and Section 4.3 swaps the PRM while holding centering constant. These isolate the centering contribution. For additivity, the method section derives that the centered process bonus is a zero-mean adjustment within each outcome group and therefore cannot override the binary outcome term in the GRPO objective; we will add a short formal paragraph and an empirical check (rate of fluent-but-incorrect trajectories) confirming no increase in misalignment relative to the outcome-only baseline. revision: yes
Circularity Check
No circularity: outcome-conditioned centering is an explicit algorithmic choice with empirical validation
full rationale
The paper defines PROGRS as a combination of a frozen quantile-regression PRM, outcome-conditioned centering (shifting incorrect-trajectory scores to zero mean per prompt group), and integration into GRPO. No equations reduce claimed improvements to a fitted parameter defined on the same data, no self-citation chain bears the central claim, and no ansatz or uniqueness theorem is smuggled in. The derivation is self-contained as a proposed preprocessing step whose effectiveness is tested on external benchmarks (MATH-500, AMC, AIME, etc.) rather than being tautological with its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PRM scores remain informative after outcome-conditioned centering
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
shifts PRM scores of incorrect trajectories to have zero mean within each prompt group... removes systematic bias while preserving informative rankings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” inThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
[Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Y . Wang, Q. Yang, Z. Zeng, L. Ren, L. Liu, B. Peng, H. Cheng, X. He, K. Wang, J. Gaoet al., “Reinforcement learning for reasoning in large language models with one training example,”arXiv preprint arXiv:2504.20571, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
T. Wang, Z. Jiang, Z. He, S. Tong, W. Yang, Y . Zheng, Z. Li, Z. He, and H. Gong, “Towards hierarchical multi-step reward models for enhanced reasoning in large language models,”arXiv preprint arXiv:2503.13551, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Defining and characterizing reward gaming,
J. Skalse, N. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,”Advances in Neural Information Processing Systems, vol. 35, pp. 9460–9471, 2022
work page 2022
-
[8]
The effects of reward misspecification: Mapping and mitigating misaligned models
A. Pan, K. Bhatia, and J. Steinhardt, “The effects of reward misspec- ification: Mapping and mitigating misaligned models,”arXiv preprint arXiv:2201.03544, 2022
-
[9]
Inform: Mitigating reward hacking in rlhf via information-theoretic reward modeling,
Y . Miao, S. Zhang, L. Ding, R. Bao, L. Zhang, and D. Tao, “Inform: Mitigating reward hacking in rlhf via information-theoretic reward modeling,”Advances in Neural Information Processing Systems, vol. 37, pp. 134 387–134 429, 2024
work page 2024
-
[10]
T. He, R. Mu, L. Liao, Y . Cao, M. Liu, and B. Qin, “Good learners think their thinking: Generative prm makes large reasoning model more efficient math learner,”arXiv preprint arXiv:2507.23317, 2025
-
[11]
Prl: Process reward learning improves llms’ reasoning ability and broadens the reasoning boundary,
J. Yao, R. Wang, and T. Zhang, “Prl: Process reward learning improves llms’ reasoning ability and broadens the reasoning boundary,”arXiv preprint arXiv:2601.10201, 2026
-
[12]
C. Ye, Z. Yu, Z. Zhang, H. Chen, N. Sadagopan, J. Huang, T. Zhang, and A. Beniwal, “Beyond correctness: Harmonizing process and outcome rewards through rl training,”arXiv preprint arXiv:2509.03403, 2025
-
[13]
Know what you don’t know: Uncertainty calibration of process reward models,
Y .-J. Park, K. Greenewald, K. Alim, H. Wang, and N. Azizan, “Know what you don’t know: Uncertainty calibration of process reward models,” arXiv preprint arXiv:2506.09338, 2025
-
[14]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,”Machine learning, vol. 8, no. 3, pp. 229–256, 1992
work page 1992
-
[15]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Trust region policy optimization,
J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz, “Trust region policy optimization,” inInternational conference on machine learning. PMLR, 2015, pp. 1889–1897
work page 2015
-
[17]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[19]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighanet al., “Training a helpful and harmless assistant with reinforcement learning from human feedback,” arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in neural information processing systems, vol. 36, pp. 53 728–53 741, 2023
work page 2023
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liuet al., “Dapo: An open-source llm reinforcement learning system at scale,”arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Beyond the first error: Process reward models for reflective mathematical reasoning,
Z. Yang, C. He, X. Shi, L. Li, Q. Yin, S. Deng, and D. Jiang, “Beyond the first error: Process reward models for reflective mathematical reasoning,” arXiv preprint arXiv:2505.14391, 2025
-
[23]
W. Sun, Q. Du, F. Cui, and J. Zhang, “An efficient and precise training data construction framework for process-supervised reward model in mathematical reasoning,”arXiv preprint arXiv:2503.02382, 2025
-
[24]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Linet al., “Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement,”arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Hard examples are all you need: Maximizing grpo post-training under annotation budgets,
B. Pikus, P. R. Tiwari, and B. Ye, “Hard examples are all you need: Maximizing grpo post-training under annotation budgets,”arXiv preprint arXiv:2508.14094, 2025
-
[26]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset,”arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Solv- ing quantitative reasoning problems with language models,
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V . Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Soloet al., “Solv- ing quantitative reasoning problems with language models,”Advances in neural information processing systems, vol. 35, pp. 3843–3857, 2022
work page 2022
-
[28]
C. He, R. Luo, Y . Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhanget al., “Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems,”arXiv preprint arXiv:2402.14008, 2024. APPENDIX A. Case Study: PRM Miscalibration and the Effect of Center- ing We provide a concrete example ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Correct answer: 1+ √ 5 4 , attained whenw=z,x=y, and w x = √ 5−1 2
Problem Instance:Question:Find the maximum value of wx+xy+yz w2+x2+y2+z2 for positive real numbersw, x, y, z. Correct answer: 1+ √ 5 4 , attained whenw=z,x=y, and w x = √ 5−1 2 . Model’s answer (incorrect): 3 4, obtained by assumingw= x=y=z=t
-
[30]
Reasoning Analysis:The model’s solution is locally well-structured (e.g., applies AM–GM, derives equality con- ditions, and performs consistent algebra), which yields low within-window variance and a high coherence-modulated pro- cess score. The error is global: the equality casew=x= y=zis not optimal under the full constraint set, so the final answer is ...
-
[31]
Advantage Computation:In this prompt group, all sam- pled solutions were incorrect, so the outcome-based advantage is zero and provides no discrimination. The positiveA final indicates that this incorrect solution is preferredrelative to TABLE II: Metrics for a miscalibrated incorrect solution in the case study. Metric Value Outcome rewardr outcome 0.0 Ra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.