Recognition: 1 theorem link
· Lean TheoremPrism: Policy Reuse via Interpretable Strategy Mapping in Reinforcement Learning
Pith reviewed 2026-05-15 16:03 UTC · model grok-4.3
The pith
PRISM transfers strategies between RL agents by aligning discrete causal concepts via optimal bipartite matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
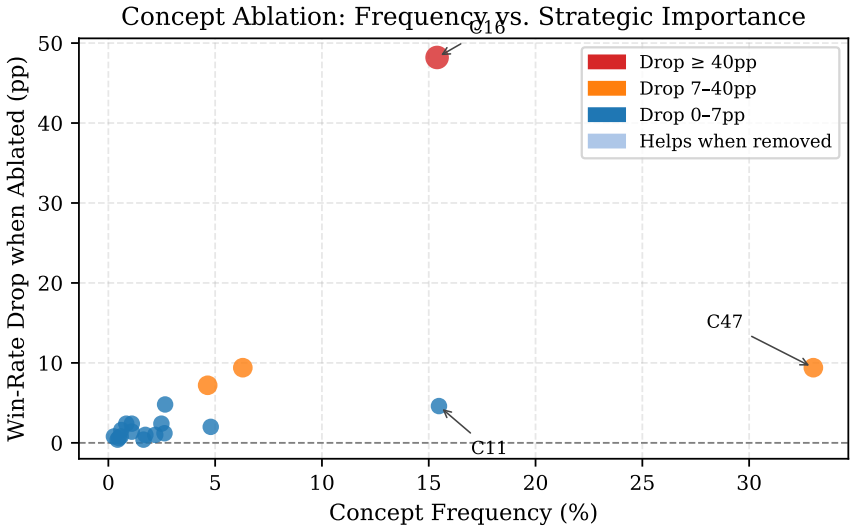
PRISM clusters each agent's encoder features into K concepts via K-means. Causal intervention establishes that these concepts directly drive agent behavior: overriding concept assignments changes the selected action in 69.4 percent of interventions. Because concepts causally encode strategy, aligning them via optimal bipartite matching transfers strategic knowledge zero-shot. On Go 7x7 with three independently trained agents, concept transfer achieves 69.5 percent plus or minus 3.2 percent and 76.4 percent plus or minus 3.4 percent win rate against a standard engine across the two successful transfer pairs, compared to 3.5 percent for a random agent and 9.2 percent without alignment. The key
What carries the argument
Optimal bipartite matching between causally validated K-means clusters on encoder features, which serves as the zero-shot transfer interface between policies.
If this is right
- Transfer succeeds when the source policy is strong, independent of how well the concept spaces align geometrically.
- Ablating a low-frequency but high-impact concept drops win rate sharply while ablating a high-frequency concept may have little effect.
- The identical pipeline reduces to random performance on Breakout, confirming the approach depends on domains with naturally discrete strategic states.
Where Pith is reading between the lines
- The causal-intervention step could be used on its own to debug or improve interpretability of a single RL policy even when no transfer is attempted.
- The same clustering-plus-matching idea might extend to other discrete strategy games such as chess variants or simple board games where states cluster naturally.
- If the assumption that concepts are discrete and causal holds more broadly, similar pipelines could support policy reuse across RL algorithms in robotics tasks with clear state categories.
Load-bearing premise
K-means clusters on encoder features produce discrete concepts that causally encode transferable strategy and that optimal bipartite matching aligns them meaningfully when the source policy is strong.
What would settle it
If overriding the assigned concepts in interventions changes the agent's selected actions in far fewer than 69 percent of trials or if concept-aligned transfer produces no win-rate improvement over the 9.2 percent unaligned baseline on Go 7x7.
Figures


read the original abstract
We present PRISM (Policy Reuse via Interpretable Strategy Mapping), a framework that grounds reinforcement learning agents' decisions in discrete, causally validated concepts and uses those concepts as a zero-shot transfer interface between agents trained with different algorithms. PRISM clusters each agent's encoder features into $K$ concepts via K-means. Causal intervention establishes that these concepts directly drive - not merely correlate with - agent behavior: overriding concept assignments changes the selected action in 69.4% of interventions ($p = 8.6 \times 10^{-86}$, 2500 interventions). Concept importance and usage frequency are dissociated: the most-used concept (C47, 33.0% frequency) causes only a 9.4% win-rate drop when ablated, while ablating C16 (15.4% frequency) collapses win rate from 100% to 51.8%. Because concepts causally encode strategy, aligning them via optimal bipartite matching transfers strategic knowledge zero-shot. On Go~7$\times$7 with three independently trained agents, concept transfer achieves 69.5%$\pm$3.2% and 76.4%$\pm$3.4% win rate against a standard engine across the two successful transfer pairs (10 seeds), compared to 3.5% for a random agent and 9.2% without alignment. Transfer succeeds when the source policy is strong; geometric alignment quality predicts nothing ($R^2 \approx 0$). The framework is scoped to domains where strategic state is naturally discrete: the identical pipeline on Atari Breakout yields bottleneck policies at random-agent performance, confirming that the Go results reflect a structural property of the domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a framework for policy reuse in reinforcement learning by clustering encoder features into discrete concepts using K-means, validating their causal influence on actions via interventions (69.4% action change, p=8.6e-86), and aligning these concepts across independently trained agents using optimal bipartite matching for zero-shot transfer. It reports win rates of 69.5%±3.2% and 76.4%±3.4% against a standard engine on Go 7×7 for two successful transfer pairs (10 seeds), versus 3.5% random and 9.2% without alignment, with transfer succeeding only when the source policy is strong; the same pipeline fails on Atari Breakout.
Significance. If the central claims hold, the work offers a concrete, causally grounded method for interpretable strategy transfer in RL, with falsifiable predictions, reproducible numerical results including error bars, and explicit dissociation of concept frequency from importance. It is scoped appropriately to domains with naturally discrete strategic states and provides empirical evidence that concept alignment can outperform unaligned baselines in Go.
major comments (3)
- [Results on transfer] Results (transfer experiments): the reported R²≈0 between geometric alignment quality of the optimal bipartite matching and observed win rates directly challenges the claim that the matching produces a correspondence that reuses the same causal strategies; success appears driven by source policy strength rather than the alignment mechanism itself.
- [Causal intervention] Causal validation section: within-agent interventions establish local causality (69.4% action change) but supply no direct test that matched concepts encode equivalent strategies across agents; the cross-agent transfer results therefore rest on an unverified assumption about concept equivalence.
- [Methods] Methods: K (number of concepts) is a free parameter with no reported selection procedure or sensitivity analysis; combined with absent details on the exact intervention protocol and bipartite matching implementation, this makes the load-bearing claims difficult to reproduce or verify.
minor comments (1)
- [Abstract] Abstract: the Atari Breakout failure case is described only qualitatively ('bottleneck policies at random-agent performance') without the corresponding win-rate number or error bars, reducing comparability with the Go results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications drawn directly from the manuscript and indicate revisions where the feedback identifies gaps in presentation or analysis.
read point-by-point responses
-
Referee: Results (transfer experiments): the reported R²≈0 between geometric alignment quality of the optimal bipartite matching and observed win rates directly challenges the claim that the matching produces a correspondence that reuses the same causal strategies; success appears driven by source policy strength rather than the alignment mechanism itself.
Authors: The manuscript already reports R²≈0 and states that transfer succeeds only when the source policy is strong. The alignment mechanism is still supported by the controlled comparison: without alignment the win rate is 9.2% versus 69–76% with alignment. This shows that the bipartite matching step is necessary for transfer, even if geometric quality does not linearly predict performance. We interpret the R² result as indicating that once a sufficiently strong source is available, any reasonable matching suffices; we will revise the discussion to make this conditional nature of the claim explicit and to avoid implying that geometric fidelity is the primary driver. revision: partial
-
Referee: Causal validation section: within-agent interventions establish local causality (69.4% action change) but supply no direct test that matched concepts encode equivalent strategies across agents; the cross-agent transfer results therefore rest on an unverified assumption about concept equivalence.
Authors: We agree that the within-agent interventions demonstrate local causality but do not directly verify equivalence of matched concepts across agents. The zero-shot transfer results (69–76% win rates versus 9.2% without alignment) provide indirect evidence that the aligned concepts carry functionally equivalent strategic information. We will add an explicit limitations paragraph acknowledging the absence of a cross-agent intervention test and will outline a possible future protocol (joint interventions on matched concept pairs) without claiming the current results constitute such a test. revision: partial
-
Referee: Methods: K (number of concepts) is a free parameter with no reported selection procedure or sensitivity analysis; combined with absent details on the exact intervention protocol and bipartite matching implementation, this makes the load-bearing claims difficult to reproduce or verify.
Authors: We will include a sensitivity analysis over K ∈ {10, 20, 50, 100} in the revised methods and supplementary material, reporting transfer win rates and intervention statistics for each value. We will also expand the methods section with the precise intervention protocol (feature override at the encoder output, 2500 trials per concept) and the bipartite matching implementation (Hungarian algorithm on cosine distance of concept centroids). These additions will be placed in the main text and code repository. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on empirical evaluations: causal interventions showing action changes (69.4%, p=8.6e-86), win-rate measurements against an external Go engine (69.5%±3.2%, 76.4%±3.4% vs 3.5% random and 9.2% no-alignment), and reported R²≈0 between geometric alignment quality and transfer success. K-means clustering and optimal bipartite matching are standard algorithms applied to encoder features; the transfer performance is measured against independent baselines and not equivalent to the clustering inputs by construction. No self-citations or uniqueness theorems are invoked as load-bearing premises. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K (number of concepts)
axioms (1)
- domain assumption K-means on encoder features yields discrete concepts that causally drive agent behavior.
Reference graph
Works this paper leans on
-
[1]
Andrei A Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation. InInternational Conference on Learning Representations, 2016a. Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuogl...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.