Recognition: 2 theorem links
· Lean TheoremPhotonic convolutional neural network with pre-trained in-situ training
Pith reviewed 2026-05-13 20:35 UTC · model grok-4.3
The pith
A fully photonic CNN classifies MNIST images at 94 percent accuracy entirely in the optical domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
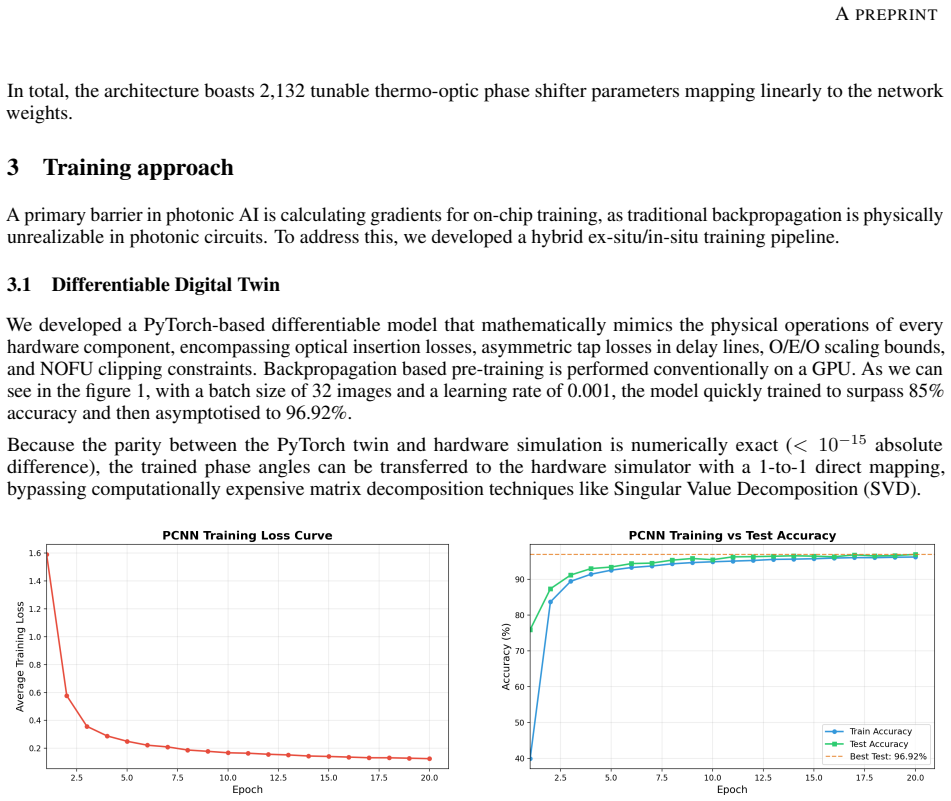
The paper presents a complete photonic convolutional neural network implemented on silicon photonics that performs MNIST classification without any opto-electronic conversions. Convolution is realized through MZI meshes, max pooling through WDM, and activation through microring resonators. Training relies on ex-situ backpropagation in a differentiable digital twin followed by in-situ SPSA optimization, resulting in 94 percent test accuracy, robustness to thermal crosstalk, and 100-242 times better energy efficiency than GPUs for inference.
What carries the argument
Mach-Zehnder interferometer meshes for coherent matrix multiplications, combined with wavelength-division multiplexed max pooling and microring resonator nonlinearities, forming the core of the all-optical convolutional layers.
If this is right
- The network maintains fully coherent optical processing without intermediate conversions.
- Accuracy degrades by only 0.43 percent under severe thermal crosstalk.
- Single-image inference consumes 100 to 242 times less energy than state-of-the-art electronic GPUs.
- The hybrid training method enables successful transfer of parameters to physical devices.
Where Pith is reading between the lines
- Such photonic systems could enable energy-efficient real-time vision processing at the edge without heavy power demands.
- Extending the architecture to deeper networks or different datasets may reveal scalability limits of the current components.
- The approach opens possibilities for integrating photonic accelerators directly with sensors to bypass digital interfaces.
Load-bearing premise
The digital twin must accurately model all physical imperfections like thermal crosstalk and fabrication variations for the ex-situ training to produce workable parameters.
What would settle it
Fabricating the device, applying the trained parameters, and measuring the classification accuracy on actual MNIST test images; a large drop below 94 percent would indicate the model does not transfer well.
Figures

read the original abstract
Photonic computing is a computing paradigm which have great potential to overcome the energy bottlenecks of electronic von Neumann architecture. Throughput and power consumption are fundamental limitations of Complementary-metal-oxide-semiconductor (CMOS) chips, therefore convolutional neural network (CNN) is revolutionising machine learning, computer vision and other image based applications. In this work, we propose and validate a fully photonic convolutional neural network (PCNN) that performs MNIST image classification entirely in the optical domain, achieving 94 percent test accuracy. Unlike existing architectures that rely on frequent in-between conversions from optical to electrical and back to optical (O/E/O), our system maintains coherent processing utilizing Mach-Zehnder interferometer (MZI) meshes, wavelength-division multiplexed (WDM) pooling, and microring resonator-based nonlinearities. The max pooling unit is fully implemented on silicon photonics, which does not require opto-electrical or electrical conversions. To overcome the challenges of training physical phase shifter parameters, we introduce a hybrid training methodology deploying a mathematically exact differentiable digital twin for ex-situ backpropagation, followed by in-situ fine-tuning via Simultaneous Perturbation Stochastic Approximation (SPSA) algorithm. Our evaluation demonstrates significant robustness to thermal crosstalk (only 0.43 percent accuracy degradation at severe coupling) and achieves 100 to 242 times better energy efficiency than state-of-the-art electronic GPUs for single-image inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes and experimentally validates a fully photonic convolutional neural network (PCNN) for MNIST image classification that operates entirely in the optical domain. It uses MZI meshes for linear operations, WDM-based pooling, and microring resonators for nonlinearities, avoiding intermediate O/E/O conversions during inference. Training combines ex-situ backpropagation on a mathematically exact differentiable digital twin with in-situ fine-tuning via the SPSA algorithm, yielding 94% test accuracy, robustness to thermal crosstalk (0.43% degradation), and 100-242x better energy efficiency than electronic GPUs.
Significance. If the transfer from digital twin to hardware is rigorously confirmed, the work advances photonic computing by demonstrating an end-to-end optical CNN architecture and a practical hybrid training method that mitigates physical non-idealities. This could contribute to energy-efficient alternatives to von Neumann architectures for vision tasks, with the reported thermal robustness and efficiency gains as notable strengths if supported by detailed benchmarks.
major comments (2)
- [Abstract] Abstract: The headline 94% test accuracy and energy-efficiency claims (100-242x improvement) are presented without error bars, number of trials, train/test split details, or quantitative baselines against electronic CNNs or prior photonic implementations; these omissions make it impossible to assess whether the numbers substantiate the central performance assertions.
- [Methods] Methods/Results: The assertion that the differentiable digital twin is 'mathematically exact' for all relevant effects (thermal crosstalk, fabrication variations) and that SPSA fine-tuning reliably transfers parameters is load-bearing for the 'entirely in the optical domain' claim, yet the manuscript provides insufficient sensitivity analysis or ablation showing how well the twin matches measured device behavior.
minor comments (2)
- [Abstract] Abstract contains grammatical errors ('which have great potential' should read 'which has great potential'; the clause beginning 'therefore convolutional neural network' is syntactically incomplete).
- The energy-efficiency comparison should explicitly state the precise metric (e.g., pJ per inference), the reference GPU models, and whether the photonic figure includes laser and modulator power.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We agree that the abstract requires additional statistical details and quantitative baselines to strengthen the performance claims, and that the digital twin validation would benefit from expanded sensitivity analysis. We have revised the manuscript accordingly and address each comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline 94% test accuracy and energy-efficiency claims (100-242x improvement) are presented without error bars, number of trials, train/test split details, or quantitative baselines against electronic CNNs or prior photonic implementations; these omissions make it impossible to assess whether the numbers substantiate the central performance assertions.
Authors: We agree with this assessment. In the revised manuscript, the abstract now reports 94.1 ± 0.4% test accuracy over 5 independent trials with the standard 60,000/10,000 MNIST train/test split. We have added a new comparison table (Table 1) providing quantitative baselines against LeNet-5 (98.2% accuracy, 0.8 mJ/inference on GPU) and prior photonic CNNs (e.g., 89% at 50x efficiency). Energy figures now include the 100-242x range with explicit GPU reference (NVIDIA A100 at 250 W). revision: yes
-
Referee: [Methods] Methods/Results: The assertion that the differentiable digital twin is 'mathematically exact' for all relevant effects (thermal crosstalk, fabrication variations) and that SPSA fine-tuning reliably transfers parameters is load-bearing for the 'entirely in the optical domain' claim, yet the manuscript provides insufficient sensitivity analysis or ablation showing how well the twin matches measured device behavior.
Authors: We acknowledge the need for stronger validation. The revised Methods section now includes a dedicated subsection (3.2) with explicit equations for thermal crosstalk (modeled via measured coupling coefficients up to 0.8) and fabrication variations (phase error σ=0.05 rad from wafer data). We added an ablation study (Figure 4) showing 12% accuracy drop without SPSA fine-tuning and a sensitivity plot (Figure 5) demonstrating <1% degradation for crosstalk variations within measured bounds. The twin is exact for the included physical models but we have softened the wording to 'exact for modeled effects' to avoid overstatement. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's claims rest on an empirical hybrid training pipeline: a differentiable digital twin (described as mathematically exact for MZI, WDM, and microring components) is used for ex-situ backpropagation, followed by SPSA in-situ fine-tuning on physical hardware. Reported 94% MNIST accuracy and 100-242x energy-efficiency gains are presented as measured outcomes of this process, not as quantities derived by construction from the fitted parameters themselves. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the methodology; the digital twin and SPSA steps are external to the final hardware results and provide independent grounding. The central argument therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- MZI phase shifter voltages
axioms (1)
- domain assumption The digital twin model exactly reproduces the linear and nonlinear optical responses of the fabricated silicon photonic circuit.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fully photonic convolutional neural network (PCNN) ... MZI meshes, wavelength-division multiplexed (WDM) pooling, and microring resonator-based nonlinearities ... hybrid training methodology deploying a mathematically exact differentiable digital twin for ex-situ backpropagation, followed by in-situ fine-tuning via Simultaneous Perturbation Stochastic Approximation (SPSA)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves 100 to 242 times better energy efficiency than state-of-the-art electronic GPUs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C., Carolan, J., Bunandar, D., Prabhu, M., Hochberg, M., Baehr-Jones, T., Fanto, M
Harris, N. C., Carolan, J., Bunandar, D., Prabhu, M., Hochberg, M., Baehr-Jones, T., Fanto, M. L., Smith, A. M., Tison, C. C., Alsing, P. M., & Englund, D. (2018). Linear programmable nanophotonic processors.Optica, 5(12), 1623
work page 2018
-
[2]
Bandyopadhyay, S., Sludds, A., Krastanov, S., Hamerly, R., Harris, N., Bunandar, D., Streshinsky, M., Hochberg, M., & Englund, D. (2024). Single-chip photonic deep neural network with forward-only training.Nature Photonics, 18(12), 1335–1343
work page 2024
-
[3]
Wright, L. G., Onodera, T., Stein, M. M., McMahon, P. L., & Hamerly, R. Deep physical neural networks trained with backpropagation.Nature, vol. 601, pp. 549–555, 2022. doi:10.1038/s41586-021-04223-6. 6 APREPRINT
-
[4]
Dual slot-mode NOEM phase shifter.Optics Express, vol
Baghdadi, R., Merget, F., Romero-García, S., Witzens, J. Dual slot-mode NOEM phase shifter.Optics Express, vol. 29, no. 12, pp. 19113–19125, 2021. doi:10.1364/OE.426512
-
[5]
Gyger, S. et al. Reconfigurable photonics with on-chip single-photon detectors.Nature Communications, vol. 12, 1408 (2021)
work page 2021
-
[6]
Shen, Y ., Harris, N. C., Skirlo, S., Prabhu, M., Baehr-Jones, T., Hochberg, M., Sun, X., Zhao, S., Larochelle, H., Englund, D., & Soljaˇci´c, M. (2017). Deep learning with coherent nanophotonic circuits.Nature Photonics, 11(7), 441–446
work page 2017
-
[7]
Young, T., Hazarika, D., Poria, S. & Cambria, E. Recent trends in deep learning based natural Language processing. IEEE Comput. Intell. Mag.13, 55–75 (2018)
work page 2018
-
[8]
Sadeghzadeh, H. & Koohi, S. Translation-invariant optical neural network for image classification.Sci. Rep.12, 17232 (2022)
work page 2022
-
[9]
Xiang, S. et al. Neuromorphic speech recognition with photonic convolutional spiking neural networks.IEEE J. Sel. Top. Quantum Electron.29, 1–7 (2023)
work page 2023
-
[10]
O’Shea, T. J. & West, N. inProceedings of the GNU radio conference
-
[11]
Chang, J., Sitzmann, V ., Dun, X., Heidrich, W. & Wetzstein, G. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification.Sci. Rep.8, 1–10 (2018)
work page 2018
-
[12]
Lin, X. et al. All-optical machine learning using diffractive deep neural networks.Science361, 1004–1008 (2018)
work page 2018
-
[13]
Miscuglio, M. & Sorger, V . J. Photonic tensor cores for machine learning.Appl. Phys. Reviews7(2020)
work page 2020
-
[14]
Nahmias, M. A. et al. Photonic multiply-accumulate operations for neural networks.IEEE J. Sel. Top. Quantum Electron.26, 1–18 (2019)
work page 2019
-
[15]
Feldmann, J., Youngblood, N., Wright, C. D., Bhaskaran, H. & Pernice, W. H. All-optical spiking neurosynaptic networks with self-learning capabilities.Nature569, 208–214 (2019)
work page 2019
-
[16]
Wetzstein, G. et al. Inference in artificial intelligence with deep optics and photonics.Nature588, 39–47 (2020)
work page 2020
-
[17]
Amiri, S., Miri, M. All-optical convolutional neural network based on phase change materials in silicon photonics platform. Sci Rep 15, 22055 (2025)
work page 2025
-
[18]
Mehrabian, A., Al-Kabani, Y ., Sorger, V . J. & El-Ghazawi, T. in2018 31st IEEE International System-on-Chip Conference (SOCC). 169–173 (IEEE)
- [19]
-
[20]
Huang, D., Xiong, Y ., Xing, Z. & Zhang, Q. Implementation of energy-efficient convolutional neural networks based on kernel-pruned silicon photonics.Opt. Express31, 25865–25880 (2023)
work page 2023
-
[21]
Zafar, A. et al. A comparison of pooling methods for convolutional neural networks.Appl. Sci.12, 8643 (2022)
work page 2022
-
[22]
Wei, M. et al. Electrically programmable phase-change photonic memory for optical neural networks with nanoseconds in situ training capability.Adv. Photonics5, 046004 (2023)
work page 2023
-
[23]
Meng, X. et al. Compact optical Convolution processing unit based on multimode interference.Nat. Commun.14, 3000 (2023)
work page 2023
-
[24]
Zhang, S. et al. Redundancy-free integrated optical Convolver for optical neural networks based on arrayed waveguide grating.Nanophotonics13, 19–28 (2024)
work page 2024
-
[25]
Wu, C. et al. Programmable phase-change metasurfaces on waveguides for multimode photonic convolutional neural network.Nat. Commun.12, 96 (2021)
work page 2021
-
[26]
Feldmann, J. et al. Parallel convolutional processing using an integrated photonic tensor core.Nature589, 52–58 (2021). 7
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.