Recognition: no theorem link
From Theory to Practice: Code Generation Using LLMs for CAPEC and CWE Frameworks
Pith reviewed 2026-05-13 20:48 UTC · model grok-4.3
The pith
Large language models generate a dataset of 615 vulnerable code snippets corresponding to CAPEC and CWE descriptions across Java, Python, and JavaScript.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
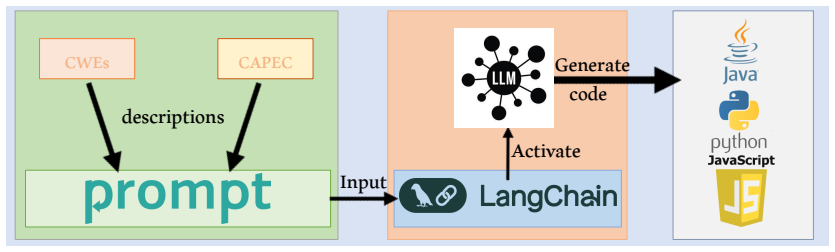
The authors develop a methodology using GPT-4o, Llama, and Claude to generate vulnerable code snippets that correspond to CAPEC and CWE documentation. Preliminary evaluations indicate high accuracy, with consistent results across the three models showing 0.98 cosine similarity. The resulting dataset contains 615 CAPEC code snippets in Java, Python, and JavaScript and is positioned as a reliable resource for vulnerability identification systems and machine learning model training.
What carries the argument
Multi-model code generation where GPT-4o, Llama, and Claude each produce snippets for the same CAPEC and CWE descriptions, with inter-model cosine similarity serving as the primary validation metric.
If this is right
- The dataset can train machine learning models for automatic vulnerability detection and remediation.
- It provides a reference resource that improves understanding of how security vulnerabilities appear in source code.
- Consistent cross-model results support its use in vulnerability identification systems.
- Coverage in three languages makes the collection more applicable to diverse software projects than prior resources.
- The size and linkage structure position it as one of the more extensive datasets in this domain.
Where Pith is reading between the lines
- If the snippets were later verified through dynamic analysis or expert audit, the collection could serve as a standard benchmark for evaluating code-security tools.
- The same generation approach might be applied to produce examples for additional security taxonomies beyond CAPEC and CWE.
- Incorporating the dataset into existing static or dynamic analyzers could raise their coverage of specific attack patterns.
- Future extensions could test whether models fine-tuned on this data produce fewer vulnerable outputs when asked to write code.
Load-bearing premise
The generated code snippets actually contain the specific vulnerabilities described in the CAPEC and CWE entries, which is inferred only from similarity between model outputs rather than direct testing or review.
What would settle it
Running each generated snippet in an isolated execution environment and confirming whether it can be exploited in the exact manner described by its linked CAPEC or CWE entry.
Figures



read the original abstract
The increasing complexity and volume of software systems have heightened the importance of identifying and mitigating security vulnerabilities. The existing software vulnerability datasets frequently fall short in providing comprehensive, detailed code snippets explicitly linked to specific vulnerability descriptions, reducing their utility for advanced research and hindering efforts to develop a deeper understanding of security vulnerabilities. To address this challenge, we present a novel dataset that provides examples of vulnerable code snippets corresponding to Common Attack Pattern Enumerations and Classifications (CAPEC) and Common Weakness Enumeration (CWE) descriptions. By employing the capabilities of Generative Pre-trained Transformer (GPT) models, we have developed a robust methodology for generating these examples. Our approach utilizes GPT-4o, Llama and Claude models to generate code snippets that exhibit specific vulnerabilities as described in CAPEC and CWE documentation. This dataset not only enhances the understanding of security vulnerabilities in code but also serves as a valuable resource for training machine learning models focused on automatic vulnerability detection and remediation. Preliminary evaluations suggest that the dataset generated by Large Language Models demonstrates high accuracy and can serve as a reliable reference for vulnerability identification systems. We found consistent results across the three models, with 0.98 cosine similarity among codes. The final dataset comprises 615 CAPEC code snippets in three programming languages: Java, Python, and JavaScript, making it one of the most extensive and diverse resources in this domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a dataset of 615 code snippets in Java, Python, and JavaScript generated by three LLMs (GPT-4o, Llama, Claude) to illustrate vulnerabilities described in CAPEC and CWE entries. Generation relies on prompting the models with the official vulnerability descriptions; the authors report 0.98 cosine similarity across model outputs as evidence of accuracy and claim the dataset is suitable for training vulnerability-detection models.
Significance. A large, publicly available collection of code examples explicitly tied to standardized CAPEC/CWE taxonomies would be a useful resource for security research and ML-based detection if the snippets are verifiably vulnerable. The multi-LLM generation strategy is a reasonable starting point, but the current evaluation provides no evidence that the claimed vulnerabilities are actually present.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the claim that the dataset demonstrates 'high accuracy' rests exclusively on 0.98 cosine similarity between the three models' outputs. Cosine similarity measures textual resemblance, not the presence of the specific weaknesses enumerated in the CAPEC/CWE documentation; no static analysis, dynamic execution, compilation checks, or expert review is reported.
- [Methodology] Methodology: the generation pipeline contains no verification step that would confirm the produced snippets actually trigger the targeted vulnerabilities (e.g., via CWE-specific static analyzers, test-case execution, or manual inspection). Without such validation the dataset labels are ungrounded and any downstream training claims are unsupported.
minor comments (2)
- [Abstract] Abstract: the text refers to both CAPEC and CWE yet states the dataset contains '615 CAPEC code snippets'; clarify the exact counts and mapping for each taxonomy.
- [Abstract] Abstract: the breakdown of the 615 snippets across the three languages (Java, Python, JavaScript) is not stated; provide these numbers to allow assessment of balance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting important limitations in our evaluation. We agree that the current reliance on cosine similarity alone does not sufficiently validate the presence of the targeted vulnerabilities and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the claim that the dataset demonstrates 'high accuracy' rests exclusively on 0.98 cosine similarity between the three models' outputs. Cosine similarity measures textual resemblance, not the presence of the specific weaknesses enumerated in the CAPEC/CWE documentation; no static analysis, dynamic execution, compilation checks, or expert review is reported.
Authors: We agree that cosine similarity measures textual consistency rather than confirming the presence of specific CAPEC/CWE vulnerabilities. Our use of the metric was intended only to show agreement across LLMs, not as proof of correctness. In the revised manuscript we will remove the unqualified 'high accuracy' claim from the abstract and evaluation section, replace it with a description of inter-model consistency, and add an explicit limitations paragraph noting the absence of static or dynamic verification. revision: yes
-
Referee: [Methodology] Methodology: the generation pipeline contains no verification step that would confirm the produced snippets actually trigger the targeted vulnerabilities (e.g., via CWE-specific static analyzers, test-case execution, or manual inspection). Without such validation the dataset labels are ungrounded and any downstream training claims are unsupported.
Authors: This observation is correct. The original pipeline relied solely on prompt-based generation and post-hoc similarity checks. We will revise the methodology section to describe an added verification stage that applies CWE-aware static analyzers (e.g., CodeQL or SonarQube) to a stratified sample of snippets and reports detection rates. We will also qualify all downstream-use claims by stating that the labels are model-generated and have not yet received exhaustive manual or automated validation, thereby making the limitation transparent. revision: yes
Circularity Check
No circularity: methodology is self-contained with direct generation and similarity checks
full rationale
The paper presents a dataset generation process using LLMs (GPT-4o, Llama, Claude) prompted from CAPEC/CWE descriptions, followed by cosine similarity evaluation (0.98) across model outputs. No equations, fitted parameters, predictions derived from prior fits, or self-citation chains appear in the derivation. The central claim of 'high accuracy' and 'exhibit specific vulnerabilities' rests on prompt adherence and inter-model consistency rather than any reduction to inputs by construction. This is a standard descriptive ML data-generation workflow without self-referential loops.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate code that accurately exhibits specific security vulnerabilities when given CAPEC and CWE descriptions.
Reference graph
Works this paper leans on
-
[1]
A literature review of financial losses statistics for cyber security and future trend,
Sharif, Md Haris Uddin and Mohammed, Mehmood Ali, “A literature review of financial losses statistics for cyber security and future trend,” World Journal of Advanced Research and Reviews, vol. 15, pp. 138–156, 2022
work page 2022
-
[2]
Examining the costs and causes of cyber incidents,
Romanosky, Sasha, “Examining the costs and causes of cyber incidents,” Journal of Cybersecurity, vol. 2, pp. 121–135, 2016
work page 2016
-
[3]
Financial consequences of cyber attacks leading to data breaches in healthcare sector,
Meisner, Marta, “Financial consequences of cyber attacks leading to data breaches in healthcare sector,”Copernican Journal of Finance & Accounting, vol. 6, pp. 63–73, 2017
work page 2017
-
[4]
F. Seehusen, ”Using CAPEC for Risk-Based Security Testing,” inRisk Assessment and Risk-Driven Testing, Springer, Cham, 2015, pp. 84–99. doi:10.1007/978-3-319-26416-5 6
-
[5]
Harrison Chase, ”LangChain,”Online, 2022. Available at: https://python. langchain.com/v0.2/docs/introduction/. Accessed: 2024-11-15
work page 2022
-
[6]
Lionel Sujay Vailshery, ”Most used programming lan- guages among developers worldwide as of 2023,”Online,
work page 2023
-
[7]
Available: https://www.statista.com/statistics/793628/ worldwide-developer-survey-most-used-languages/. Accessed: 2024- 11-15
work page 2024
-
[8]
Fan, Jiahao and Li, Yi and Wang, Shaohua and Nguyen, Tien N, ”AC/C++ code vulnerability dataset with code changes and CVE sum- maries,” pp. 508–512, 2020
work page 2020
-
[9]
An empirical study of tactical vulnerabil- ities,
Santos, Joanna CS and Tarrit, Katy and Sejfia, Adriana and Mirakhorli, Mehdi and Galster, Matthias, “An empirical study of tactical vulnerabil- ities,”Journal of Systems and Software, vol. 149, pp. 263–284, 2019
work page 2019
-
[10]
Vuldeepecker: A deep learning-based system for vulnerability detection,
Li, Zhen and Zou, Deqing and Xu, Shouhuai and Ou, Xinyu and Jin, Hai and Wang, Sujuan and Deng, Zhijun and Zhong, Yuyi, “Vuldeepecker: A deep learning-based system for vulnerability detection,”arXiv preprint arXiv:1801.01681, 2018
-
[11]
Sysevr: A framework for using deep learning to detect software vulnerabilities,
Li, Zhen and Zou, Deqing and Xu, Shouhuai and Jin, Hai and Zhu, Yawei and Chen, Zhaoxuan, “Sysevr: A framework for using deep learning to detect software vulnerabilities,”IEEE Transactions on De- pendable and Secure Computing, vol. 19, pp. 2244–2258, 2021
work page 2021
-
[12]
Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection,
Chen, Yizheng and Ding, Zhoujie and Alowain, Lamya and Chen, Xinyun and Wagner, David, “Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection,” pp. 654–668, 2023
work page 2023
-
[13]
Deep learning based vulnerability detection: Are we there yet?,
Chakraborty, Saikat and Krishna, Rahul and Ding, Yangruibo and Ray, Baishakhi, “Deep learning based vulnerability detection: Are we there yet?,”IEEE Transactions on Software Engineering, vol. 48, pp. 3280– 3296, 2021
work page 2021
-
[14]
Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap,
Zhou, Xin and Cao, Sicong and Sun, Xiaobing and Lo, David, “Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap,”arXiv preprint arXiv:2404.02525, 2024
-
[15]
LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs’ Vulnerability Reasoning,
Sun, Yuqiang and Wu, Daoyuan and Xue, Yue and Liu, Han and Ma, Wei and Zhang, Lyuye and Shi, Miaolei and Liu, Yang, “LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs’ Vulnerability Reasoning,”arXiv preprint arXiv:2401.16185, 2024
-
[16]
An analysis of large language models: their impact and potential applications,
Bharathi Mohan, G and Prasanna Kumar, R and Vishal Krishh, P and Keerthinathan, A and Lavanya, G and Meghana, Meka Kavya Uma and Sulthana, Sheba and Doss, Srinath, “An analysis of large language models: their impact and potential applications,”Knowledge and Information Systems, pp. 1–24, 2024
work page 2024
-
[17]
Large language model assisted software engineering: prospects, challenges, and a case study,
Belzner, Lenz and Gabor, Thomas and Wirsing, Martin, “Large language model assisted software engineering: prospects, challenges, and a case study,” pp. 355–374, 2023
work page 2023
-
[18]
Large language models for software engineering: Survey and open problems
Fan, Angela and Gokkaya, Beliz and Harman, Mark and Lyubarskiy, Mitya and Sengupta, Shubho and Yoo, Shin and Zhang, Jie M, “Large language models for software engineering: Survey and open problems,” arXiv preprint arXiv:2310.03533, 2023
-
[19]
Large Language Model for Vulnerability Detection: Emerging Results and Future Directions,
Zhou, Xin and Zhang, Ting and Lo, David, “Large Language Model for Vulnerability Detection: Emerging Results and Future Directions,” arXiv preprint arXiv:2401.15468, 2024
-
[20]
Prompt-enhanced software vulnerability detection using chatgpt,
Zhang, Chenyuan and Liu, Hao and Zeng, Jiutian and Yang, Kejing and Li, Yuhong and Li, Hui, “Prompt-enhanced software vulnerability detection using chatgpt,” pp. 276–277, 2024
work page 2024
-
[21]
Y . Nong, Y . Ou, M. Pradel, F. Chen, and H. Cai, ”Generating Realis- tic Vulnerabilities via Neural Code Editing: An Empirical Study,” in Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the F oundations of Software Engineering (ESEC/FSE), 2022, pp. 1097–1109
work page 2022
- [22]
-
[23]
Software vulnerability detection using large language models,
Purba, Moumita Das and Ghosh, Arpita and Radford, Benjamin J and Chu, Bill, “Software vulnerability detection using large language models,” pp. 112–119, 2023
work page 2023
-
[24]
Examining zero-shot vulnerability repair with large language models,
Pearce, Hammond and Tan, Benjamin and Ahmad, Baleegh and Karri, Ramesh and Dolan-Gavitt, Brendan, “Examining zero-shot vulnerability repair with large language models,” pp. 2339–2356, 2023
work page 2023
-
[25]
Can large language models find and fix vulnerable software?,
Noever, David, “Can large language models find and fix vulnerable software?,”arXiv preprint arXiv:2308.10345, 2023
-
[26]
Chatgpt for vulnerability detection, classification, and repair: How far are we?,
Fu, Michael and Tantithamthavorn, Chakkrit Kla and Nguyen, Van and Le, Trung, “Chatgpt for vulnerability detection, classification, and repair: How far are we?,” pp. 632–636, 2023
work page 2023
-
[27]
Al Azher, Ibrahim and Devesh Reddy, Venkata and Alhoori, Hamed and Akella, Akhil Pandey, “LimTopic: LLM-based Topic Modeling and Text Summarization for Analyzing Scientific Articles limita- tions. ACM/IEE Joint Conference on Digital Libraries (JCDL), 2024.” doi:10.1145/3677389.3702605
-
[28]
I. Al Azher and H. Alhoori, ”Mitigating Visual Limitations of Re- search Papers,” 2024 IEEE International Conference on Big Data (Big- Data), Washington, DC, USA, 2024, pp. 8614-8616, doi: 10.1109/Big- Data62323.2024.10826112
-
[29]
Large language models are zero-shot reasoners,
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and Matsuo, Yutaka and Iwasawa, Yusuke, “Large language models are zero-shot reasoners,”Advances in neural information processing systems, vol. 35, pp. 22199–22213, 2022
work page 2022
-
[30]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna, “Sentence-bert: Sentence embed- dings using siamese bert-networks,”arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[31]
Brown, Tom B., ”Language models are few-shot learners,”arXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[32]
Mungoli, Neelesh, “Exploring the Synergy of Prompt Engineering and Reinforcement Learning for Enhanced Control and Responsiveness in Chat GPT,”Journal of Electrical Electronics Engineering, vol. 2, pp. 201–205, 2023
work page 2023
-
[33]
Faithful chain-of-thought reasoning, 2023
Lyu, Qing and Havaldar, Shreya and Stein, Adam and Zhang, Li and Rao, Delip and Wong, Eric and Apidianaki, Marianna and Callison- Burch, Chris, “Faithful chain-of-thought reasoning,”arXiv preprint arXiv:2301.13379, 2023
-
[34]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang,et al., “CodeBERT: A pre-trained model for programming and natural languages,”arXiv preprint arXiv:2002.08155, 2020
work page internal anchor Pith review arXiv 2002
-
[35]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, et al., ”Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
Matthew Lombard, Jennifer Snyder-Duch, and Cheryl Campanella Bracken. Content analysis in mass communication: Assessment and reporting of intercoder reliability.Human Communication Research, 28(4):587–604, 2002. Wiley Online Library
work page 2002
-
[37]
Mary L. McHugh. Interrater reliability: The kappa statistic.Biochemia Medica, 22(3):276–282, 2012. Medicinska Naklada
work page 2012
-
[38]
Steven E. Stemler. A comparison of consensus, consistency, and measurement approaches to estimating interrater reliability.Practical Assessment, Research, and Evaluation, 9(1):4, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.