Recognition: no theorem link
Mitigating LLM biases toward spurious social contexts using direct preference optimization
Pith reviewed 2026-05-13 20:29 UTC · model grok-4.3
The pith
Debiasing-DPO pairs neutral reasoning with biased reasoning to cut LLM sensitivity to spurious social contexts by 84 percent while raising predictive accuracy by 52 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Debiasing-DPO reduces bias by 84% and improves predictive accuracy by 52% on average when applied to Llama 3B and 8B and Qwen 3B and 7B Instruct models evaluated on U.S. classroom transcripts paired with expert rubric scores.
What carries the argument
Debiasing-DPO, a direct preference optimization objective that treats neutral reasoning generated from the query alone as the preferred response and the model's own reasoning generated with added spurious context as the dispreferred response.
If this is right
- Model predictions on teacher evaluation tasks become stable even when irrelevant details about experience, education, or identity are supplied.
- The same training procedure raises alignment with expert rubric scores rather than trading robustness for accuracy.
- The gains hold for both 3B and 7-8B scale models from two different families.
- Standard prompt engineering and unmodified DPO remain insufficient to achieve comparable robustness.
Where Pith is reading between the lines
- The pairing of self-generated neutral and biased reasoning traces may serve as a general template for preference optimization on other forms of context sensitivity.
- If the method scales to larger models, it could reduce the need for costly human preference data when correcting spurious-context biases.
- The result implies that explicit contrastive reasoning supervision can substitute for further model scaling in robustness tasks.
Load-bearing premise
Generating a neutral reasoning trace from the query alone supplies a trustworthy positive example that, when contrasted against the model's biased trace, trains the model to ignore spurious context without creating new distortions or accuracy losses.
What would settle it
Applying Debiasing-DPO to a new collection of spurious contexts or a different high-stakes prediction task and observing either no reduction in prediction shift or a decline in accuracy relative to the base model.
Figures



read the original abstract
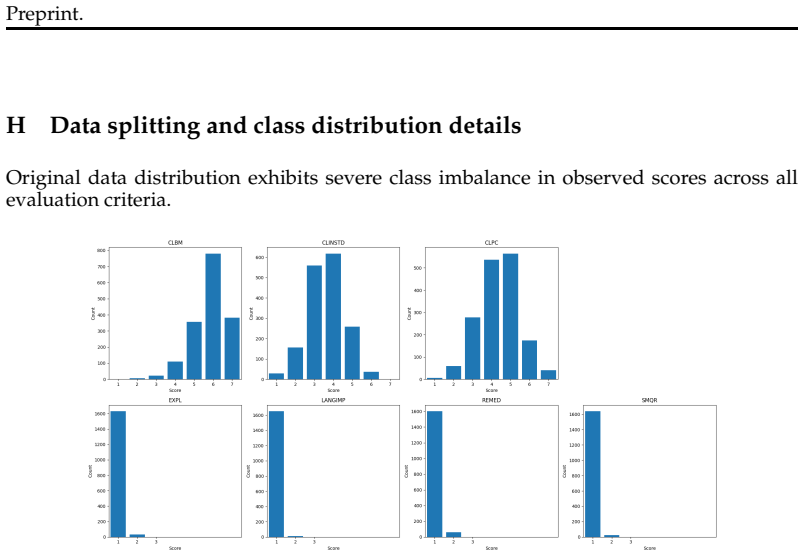
LLMs are increasingly used for high-stakes decision-making, yet their sensitivity to spurious contextual information can introduce harmful biases. This is a critical concern when models are deployed for tasks like evaluating teachers' instructional quality, where biased assessment can affect teachers' professional development and career trajectories. We investigate model robustness to spurious social contexts using the largest publicly available dataset of U.S. classroom transcripts (NCTE) paired with expert rubric scores. Evaluating seven frontier and open-weight models across seven categories of spurious contexts -- including teacher experience, education level, demographic identity, and sycophancy-inducing framings -- we find that irrelevant contextual information can shift model predictions by up to 1.48 points on a 7-point scale, with larger models sometimes exhibiting greater sensitivity despite higher predictive accuracy. Mitigations using prompts and standard direct preference optimization (DPO) prove largely insufficient. We propose **Debiasing-DPO**,, a self-supervised training method that pairs neutral reasoning generated from the query alone, with the model's biased reasoning generated with both the query and additional spurious context. We further combine this objective with supervised fine-tuning on ground-truth labels to prevent losses in predictive accuracy. Applied to Llama 3B \& 8B and Qwen 3B \& 7B Instruct models, Debiasing-DPO reduces bias by 84\% and improves predictive accuracy by 52\% on average. Our findings from the educational case study highlight that robustness to spurious context is not a natural byproduct of model scaling and that our proposed method can yield substantial gains in both accuracy and robustness for prompt-based prediction tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs are sensitive to spurious social contexts (e.g., teacher demographics, experience) when scoring classroom transcripts from the NCTE dataset, with shifts up to 1.48 points on a 7-point rubric. Standard prompting and DPO fail to mitigate this. The authors introduce Debiasing-DPO, which constructs preference pairs by contrasting the model's query-only reasoning (treated as neutral) against its reasoning when spurious context is appended, then combines this DPO objective with SFT on ground-truth labels. On Llama-3B/8B and Qwen-3B/7B Instruct models, the method is reported to reduce bias by 84% while improving predictive accuracy by 52% on average.
Significance. If the empirical claims hold under proper controls, the work is significant for practical deployment of LLMs in high-stakes educational assessment, where biased scoring can affect careers. The self-supervised construction of preference pairs without extra human annotations is a practical strength, and the explicit combination with SFT to preserve accuracy addresses a common trade-off in debiasing methods. The finding that larger models can be more sensitive to spurious context also challenges scaling-based assumptions about robustness.
major comments (2)
- [§3] §3 (Debiasing-DPO definition): The central assumption that query-only generations are verifiably neutral is load-bearing for the 84% bias-reduction claim, yet the manuscript provides no quantitative validation (e.g., measuring the same bias metric on query-only outputs versus spurious-context outputs on a held-out set). If pretraining biases remain in the 'neutral' branch, the DPO objective optimizes toward flawed pairs.
- [§4.3] §4.3 (Results): The reported 84% bias reduction and 52% accuracy improvement are given only as averages across four models; no per-model tables, standard deviations, or statistical tests (e.g., paired t-tests or bootstrap CIs) are shown, and no ablation isolating the contribution of the neutral-vs-biased pairing versus the added SFT step is provided. This makes it impossible to assess whether the gains are robust or attributable to the proposed method.
minor comments (2)
- [Abstract] Abstract: Typo with double comma after 'Debiasing-DPO,'.
- [§4.1] Notation: The bias metric (shift on 7-point scale converted to percentage reduction) should be defined explicitly with an equation in §3 or §4.1 rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The points raised highlight important aspects of our method's assumptions and the need for more granular reporting of results. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Debiasing-DPO definition): The central assumption that query-only generations are verifiably neutral is load-bearing for the 84% bias-reduction claim, yet the manuscript provides no quantitative validation (e.g., measuring the same bias metric on query-only outputs versus spurious-context outputs on a held-out set). If pretraining biases remain in the 'neutral' branch, the DPO objective optimizes toward flawed pairs.
Authors: We agree that explicit validation of the query-only branch as a neutral reference is necessary to support the bias-reduction results. In the revised manuscript we will add a new subsection that applies the same bias metric to query-only outputs versus spurious-context outputs on a held-out portion of the NCTE data. This will quantify the degree to which query-only generations already exhibit lower sensitivity to the spurious contexts. We will also include a brief discussion of the possibility of residual pretraining biases and how the combined DPO+SFT objective mitigates their impact on downstream predictions. revision: yes
-
Referee: [§4.3] §4.3 (Results): The reported 84% bias reduction and 52% accuracy improvement are given only as averages across four models; no per-model tables, standard deviations, or statistical tests (e.g., paired t-tests or bootstrap CIs) are shown, and no ablation isolating the contribution of the neutral-vs-biased pairing versus the added SFT step is provided. This makes it impossible to assess whether the gains are robust or attributable to the proposed method.
Authors: We acknowledge that aggregate averages alone limit interpretability. The revised version will include a new table reporting per-model bias reduction and accuracy change for all four models (Llama-3B/8B, Qwen-3B/7B), together with standard deviations computed over three independent training runs. We will add paired t-tests (or bootstrap confidence intervals) comparing Debiasing-DPO against the standard DPO and prompt baselines. Finally, we will insert an ablation study that isolates the neutral-vs-biased preference pairing from the SFT component, reporting the incremental contribution of each term to both bias reduction and accuracy preservation. revision: yes
Circularity Check
No circularity: empirical measurements independent of method definition
full rationale
The paper defines Debiasing-DPO explicitly as a self-supervised pairing of query-only generations (treated as neutral) against context-augmented generations, followed by DPO plus SFT on ground-truth labels. The headline results (84% bias reduction, 52% accuracy gain) are reported as post-training measurements on the NCTE dataset across models, not quantities that algebraically reduce to the training objective or to any fitted parameter by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core pairing or to derive the performance numbers. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The NCTE dataset paired with expert rubric scores is a valid benchmark for measuring sensitivity to spurious social contexts.
Forward citations
Cited by 1 Pith paper
-
Medical Model Synthesis Architectures: A Case Study
MedMSA framework retrieves knowledge via language models then builds formal probabilistic models to produce uncertainty-weighted differential diagnoses from symptoms.
Reference graph
Works this paper leans on
- [1]
-
[2]
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky
URL https://arxiv.org/abs/2401.09566. Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. Elephant: Measuring and understanding social sycophancy in llms,
-
[3]
ELEPHANT: Measuring and understanding social sycophancy in LLMs
URL https: //arxiv.org/abs/2505.13995. Andrea Cuadra, Maria Wang, Lynn Andrea Stein, Malte F Jung, Nicola Dell, Deborah Estrin, and James A Landay. The illusion of empathy? notes on displays of emotion in human-computer interaction. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pp. 1–18,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
URLhttps://arxiv.org/abs/2211.11772. Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, Ethan Perez, and Evan Hubinger. Sycophancy to subterfuge: Investigating reward-tampering in large language models,
-
[5]
Bowman, Ethan Perez, and Evan Hubinger
URL https://arxiv.org/abs/2406.10162. Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. Toxicity in chatgpt: Analyzing persona-assigned language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 1236–1270, Singapore, December
-
[6]
doi: 10.18653/v1/2023.findings-emnlp.88
Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.88. URL https:// aclanthology.org/2023.findings-emnlp.88/. Aaron Fanous, Jacob Goldberg, Ank A. Agarwal, Joanna Lin, Anson Zhou, Roxana Daneshjou, and Sanmi Koyejo. Syceval: Evaluating llm sycophancy,
-
[7]
Richard G¨ollner, Rebecca Lazarides, and Philipp Stark
URL https://arxiv.org/abs/2502.08177. Richard G¨ollner, Rebecca Lazarides, and Philipp Stark. Revealing teaching quality through lesson semantics: A gpt-assisted analysis of transcripts.British Journal of Educational Psychology, 95:S300–S315,
-
[8]
Learnlm: Improving gemini for learning.arXiv preprint arXiv:2412.16429,
LearnLM Team Google. Learnlm: Improving gemini for learning.arXiv preprint arXiv:2412.16429,
-
[9]
11 Preprint. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://arxiv.org/abs/2311.04892. Michael Hardy. “all that glitters”: Techniques for evaluations with unreliable model and human annotations. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.),Findings of the Association for Computational Linguistics: NAACL 2025, pp. 2250–2278, Albuquerque, New Mexico, April
-
[11]
Association for Computational Linguistics. ISBN 979-8-89176- 195-7. doi: 10.18653/v1/2025.findings-naacl.120. URL https://aclanthology.org/2025. findings-naacl.120/. Heather C Hill, Merrie L Blunk, Charalambos Y Charalambous, Jennifer M Lewis, Geoffrey C Phelps, Laurie Sleep, and Deborah Loewenberg Ball. Mathematical knowledge for teaching and the mathema...
-
[12]
Jian Hu, Xibin Wu, Zilin Zhu, Xianyu, Weixun Wang, Dehao Zhang, and Yu Cao. Open- rlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143,
-
[13]
The Asian Federa- tion of Natural Language Processing and The Association for Computational Linguistics. ISBN 979-8-89176-298-5. URLhttps://aclanthology.org/2025.ijcnlp-long.4/. Sal Khan. Harnessing gpt-4 so that all students benefit. a nonprofit approach for equal access.Khan Academy Blog,
work page 2025
-
[14]
Kexin Li, Pengjin Wang, and Gaowei Chen
URLhttps://arxiv.org/abs/2508.01674. Kexin Li, Pengjin Wang, and Gaowei Chen. How can ai be integrated into teacher profes- sional development programs? a systematic review based on an adapted technology- based learning model.Teaching and Teacher Education, 168:105219, 2025a. Shuyue Stella Li, Avinandan Bose, Faeze Brahman, Simon Shaolei Du, Pang Wei Koh,...
-
[15]
The lessons of developing process reward models in mathematical reasoning
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.findings-acl.586. URLhttps://aclanthology.org/2024.findings-acl.586/. Yun Long, Haifeng Luo, and Yu Zhang. Evaluating large language models in analysing classroom dialogue.npj Science of Learning, 9(1), October
-
[16]
doi: 10.1038/s41539-024-00273-3
ISSN 2056-7936. doi: 10.1038/s41539-024-00273-3. URLhttp://dx.doi.org/10.1038/s41539-024-00273-3. 12 Preprint. Pedro Henrique Luz de Araujo and Benjamin Roth. Helpful assistant or fruitful facilitator? investigating how personas affect language model behavior.PLOS One, 20(6):e0325664, June
-
[17]
doi: 10.1371/journal.pone.0325664
ISSN 1932-6203. doi: 10.1371/journal.pone.0325664. URL http://dx.doi.org/ 10.1371/journal.pone.0325664. Lars Malmqvist. Sycophancy in large language models: Causes and mitigations,
-
[18]
URL https://arxiv.org/abs/2411.15287. Baptiste Moreau-Pernet, Yu Tian, Sandra Sawaya, Peter Foltz, Jie Cao, Brent Milne, and Thomas Christie. Classifying tutor discursive moves at scale in mathematics classrooms with large language models. InProceedings of the Eleventh ACM Conference on Learning @ Scale, L@S ’24, pp. 361–365, New York, NY, USA,
-
[19]
Association for Computing Machinery. ISBN 9798400706332. doi: 10.1145/3657604.3664664. URL https://doi.org/ 10.1145/3657604.3664664. Alexander Pan, Erik Jones, Meena Jagadeesan, and Jacob Steinhardt. Feedback loops with language models drive in-context reward hacking,
-
[20]
Feedback loops with language models drive in-context reward hacking, 2024
URL https://arxiv.org/abs/ 2402.06627. Robert C Pianta, Karen M La Paro, and Bridget K Hamre.Classroom Assessment Scoring System™: Manual K-3.Paul H. Brookes Publishing Co.,
-
[21]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
URLhttps://arxiv.org/abs/2305.18290. Leonard Salewski, Stephan Alaniz, Isabel Rio-Torto, Eric Schulz, and Zeynep Akata. In- context impersonation reveals large language models’ strengths and biases,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti, and Robert West
URL https://arxiv.org/abs/2305.14930. Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti, and Robert West. On the con- versational persuasiveness of gpt-4.Nature Human Behaviour, 9(8):1645–1653, May
-
[23]
Nature Human Behaviour9(8), 1645–1653 (2025)
ISSN 2397-3374. doi: 10.1038/s41562-025-02194-6. URL http://dx.doi.org/10.1038/ s41562-025-02194-6. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Y...
-
[24]
URLhttps://arxiv.org/abs/2310.13548. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker- Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Ale...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URLhttps://arxiv.org/abs/2601.03267. Zhongxiang Sun, Yi Zhan, Chenglei Shen, Weijie Yu, Xiao Zhang, Ming He, and Jun Xu. When personalization misleads: Understanding and mitigating hallucinations in person- alized llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Mei Tan, Christopher Mah, and Dorottya Demszky
URLhttps://arxiv.org/abs/2601.11000. Mei Tan, Christopher Mah, and Dorottya Demszky. Reframing authority: A computational measure of power-affirming feedback on student writing. InProceedings of the Eleventh ACM Conference on Learning @ Scale, L@S ’24, pp. 417–421, New York, NY, USA,
-
[27]
Association for Computing Machinery. ISBN 9798400706332. doi: 10.1145/3657604. 3664680. URLhttps://doi.org/10.1145/3657604.3664680. Mei Tan, Lena Phalen, and Dorottya Demszky. Marked pedagogies: Examining linguistic biases in personalized automated writing feedback. InProceedings of the 16th International Conference on Learning Analytics & Knowledge (LAK ’26),
-
[28]
Anvesh Rao Vijjini, Somnath Basu Roy Chowdhury, and Snigdha Chaturvedi
URL https: //arxiv.org/abs/2406.08680. Anvesh Rao Vijjini, Somnath Basu Roy Chowdhury, and Snigdha Chaturvedi. Exploring safety-utility trade-offs in personalized language models,
-
[29]
Angelina Wang, Erin Beeghly, Sanmi Koyejo, and Daniel E
URL https://arxiv.org/ abs/2406.11107. Angelina Wang, Erin Beeghly, Sanmi Koyejo, and Daniel E. Ho. Personalization double binds: When user preferences meet group-based chatbot behaviors, 2025a. URL https: //angelina-wang.github.io/files/chatbot personalization.pdf. Deliang Wang, Dapeng Shan, Yaqian Zheng, Kai Guo, Gaowei Chen, and Yu Lu. Can chatgpt dete...
-
[30]
International Educational Data Mining Society. ISBN 978-1-7336736-4-8. doi: 10.5281/zenodo.8115772. Rose E. Wang and Dorottya Demszky. Is chatgpt a good teacher coach? measuring zero-shot performance for scoring and providing actionable insights on classroom instruction,
-
[31]
URLhttps://arxiv.org/abs/2306.03090. Rose E. Wang, Ana T. Ribeiro, Carly D. Robinson, Susanna Loeb, and Dora Demszky. Tutor copilot: A human-ai approach for scaling real-time expertise, 2025b. URL https: //arxiv.org/abs/2410.03017. Marcus Williams, Micah Carroll, Adhyyan Narang, Constantin Weisser, Brendan Murphy, and Anca Dragan. On targeted manipulation...
-
[32]
Paiheng Xu, Jing Liu, Nathan Jones, Julie Cohen, and Wei Ai
URLhttps://arxiv.org/abs/2411.02306. Paiheng Xu, Jing Liu, Nathan Jones, Julie Cohen, and Wei Ai. The promises and pitfalls of using language models to measure instruction quality in education. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa...
-
[33]
doi: 10.18653/v1/2024.naacl-long.246. URL http: //dx.doi.org/10.18653/v1/2024.naacl-long.246. 15 Preprint. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingre...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.naacl-long.246 2024
-
[34]
URL https://arxiv.org/abs/ 2601.09141. 16 Preprint. A Additional related work Biases in LLMs.Despite numerous safety training and red-teaming efforts, LLMs still exhibit harmful biases. Specifically, we study how biases can be introduced through a user’s prompts in two ways: (1) persona prompting, and (2) the sharing of user contexts or attributes for in-...
-
[35]
For all DPO implementations, we used a beta value of 0.1
5 Debiasing DPO uses a fixed learning rate of 1e-6. For all DPO implementations, we used a beta value of 0.1. For Debiasing-DPO, the capability loss is weighted byw SFT =0.1 relative tow DPO =1. We also observed that sometimes Debiasing DPO benefits for training for 2 episodes on the same dataset, so each training data point is used for update twice. All ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.