Recognition: 2 theorem links
· Lean TheoremDo Audio-Visual Large Language Models Really See and Hear?
Pith reviewed 2026-05-13 20:53 UTC · model grok-4.3
The pith
AVLLMs encode audio semantics in intermediate layers but vision suppresses them in final text outputs on conflicts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Although AVLLMs encode rich audio semantics at intermediate layers, these capabilities largely fail to surface in the final text generation when audio conflicts with vision. Probing analyses show that useful latent audio information is present, but deeper fusion layers disproportionately privilege visual representations that tend to suppress audio cues. The AVLLM's audio behavior strongly matches its vision-language base model, indicating limited additional alignment to audio supervision.
What carries the argument
Layer-wise probing of evolving audio and visual features combined with tests where audio and vision inputs conflict to observe which modality influences the final output.
If this is right
- AVLLMs will produce vision-dominated responses in scenarios with conflicting audio-visual information.
- Latent audio representations exist but are not utilized in the model's text generation process.
- Current training approaches for AVLLMs provide insufficient audio alignment relative to their vision-language foundations.
- Modality fusion occurs unevenly, with visual information overriding audio in deeper layers.
Where Pith is reading between the lines
- Developers might need to introduce explicit balancing mechanisms during training to ensure audio contributes equally.
- Similar probing techniques could reveal biases in other multimodal models handling text, images, or video.
- This finding points to potential improvements by intervening at the fusion layers to amplify suppressed audio signals.
Load-bearing premise
The specific layer-wise probing and audio-visual conflict tests used are sufficient to reveal the general fusion mechanism in AVLLMs rather than being limited to the models and cases tested.
What would settle it
If an AVLLM is retrained with additional audio-focused supervision and the conflict tests then show final outputs incorporating audio semantics instead of being suppressed by vision.
Figures














read the original abstract
Audio-Visual Large Language Models (AVLLMs) are emerging as unified interfaces to multimodal perception. We present the first mechanistic interpretability study of AVLLMs, analyzing how audio and visual features evolve and fuse through different layers of an AVLLM to produce the final text outputs. We find that although AVLLMs encode rich audio semantics at intermediate layers, these capabilities largely fail to surface in the final text generation when audio conflicts with vision. Probing analyses show that useful latent audio information is present, but deeper fusion layers disproportionately privilege visual representations that tend to suppress audio cues. We further trace this imbalance to training: the AVLLM's audio behavior strongly matches its vision-language base model, indicating limited additional alignment to audio supervision. Our findings reveal a fundamental modality bias in AVLLMs and provide new mechanistic insights into how multimodal LLMs integrate audio and vision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first mechanistic interpretability study of Audio-Visual Large Language Models (AVLLMs). Through layer-wise probing and audio-visual conflict tests, it claims that rich audio semantics are encoded at intermediate layers but largely fail to surface in final text outputs when audio conflicts with vision; this is traced to vision-dominant fusion layers and limited additional audio alignment during training, as the AVLLM's behavior closely matches its vision-language base model.
Significance. If the central claims hold after methodological clarification, the work would be significant as the first detailed mechanistic analysis of audio-visual fusion in LLMs. It identifies a modality bias with potential implications for training more balanced multimodal models and supplies concrete evidence via probing and training-match comparisons that could guide future alignment techniques.
major comments (3)
- [Conflict Tests] The description of conflict-test construction (how audio-visual pairs are selected, formatted, and balanced) is insufficient to rule out test-specific artifacts favoring vision; without this, the claim that audio is actively suppressed by fusion layers rather than by input design remains hard to verify.
- [Probing Analyses] Layer-wise probing results lack details on probe training (architecture, data, regularization) and quantitative metrics for 'rich audio semantics' and 'suppression'; this makes it difficult to assess whether the intermediate-layer encoding is robust or probe-dependent.
- [Training Comparison] The training-match analysis to the vision-language base model is presented without explicit similarity metrics or controls for shared pre-training data; this weakens the causal link to 'limited additional alignment to audio supervision'.
minor comments (2)
- [Figures] Figure captions and axis labels for layer-wise activation plots should explicitly state the probe type and normalization used.
- [Abstract] The term 'parameter-free' is used in the abstract for certain ratios; clarify whether any hyperparameters were tuned in the probing setup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify key aspects of our methodology. We address each major point below and will revise the manuscript to incorporate additional details and controls as outlined.
read point-by-point responses
-
Referee: [Conflict Tests] The description of conflict-test construction (how audio-visual pairs are selected, formatted, and balanced) is insufficient to rule out test-specific artifacts favoring vision; without this, the claim that audio is actively suppressed by fusion layers rather than by input design remains hard to verify.
Authors: We agree that the original description of conflict-test construction was insufficiently detailed. In the revised manuscript, we will expand Section 3.2 to explicitly describe the pair selection process (drawing from balanced subsets of AudioSet and Visual Genome with explicit cross-modal conflict criteria), formatting steps (including prompt templates and tokenization), and balancing procedures (ensuring equal numbers of vision-dominant, audio-dominant, and neutral pairs with statistical verification of label distributions). We will also add controls such as vision-only and audio-only baselines to demonstrate that observed suppression is not an artifact of input design but arises from the fusion layers. revision: yes
-
Referee: [Probing Analyses] Layer-wise probing results lack details on probe training (architecture, data, regularization) and quantitative metrics for 'rich audio semantics' and 'suppression'; this makes it difficult to assess whether the intermediate-layer encoding is robust or probe-dependent.
Authors: We acknowledge this gap in methodological transparency. The revised version will include a new appendix detailing the probe architecture (linear classifiers and 2-layer MLPs), training data (held-out audio classification subsets with 10k examples), regularization (L2 with coefficient 0.01 and early stopping), and quantitative metrics (layer-wise accuracy, precision-recall AUC, and a suppression index defined as the drop in audio probe performance from middle to final layers). These additions will allow direct assessment of robustness independent of specific probe choices. revision: yes
-
Referee: [Training Comparison] The training-match analysis to the vision-language base model is presented without explicit similarity metrics or controls for shared pre-training data; this weakens the causal link to 'limited additional alignment to audio supervision'.
Authors: We will strengthen the training comparison analysis by adding explicit similarity metrics, including cosine similarity between corresponding layer activations on audio-only inputs and KL divergence between output distributions on conflict tasks. We will also include a discussion of controls for shared pre-training data (noting the base model's vision-language corpus and the limited audio fine-tuning steps in the AVLLM), along with ablation results comparing behavior before and after audio alignment phases. This will provide stronger evidence for the limited additional audio supervision claim. revision: yes
Circularity Check
No circularity: empirical probing and comparison study
full rationale
The paper conducts a mechanistic interpretability analysis using layer-wise probing, conflict tests, and direct comparisons between the AVLLM and its vision-language base model. No mathematical derivations, equations, or self-referential definitions appear in the claims; results are presented as empirical observations from model activations and outputs. These are independently verifiable by replicating the probes on the same or similar checkpoints, with no reduction of predictions to fitted inputs or load-bearing self-citations. The central finding on modality bias follows directly from the observed layer behaviors without circular construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probing classifiers can accurately recover latent audio information from intermediate layers without introducing artifacts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
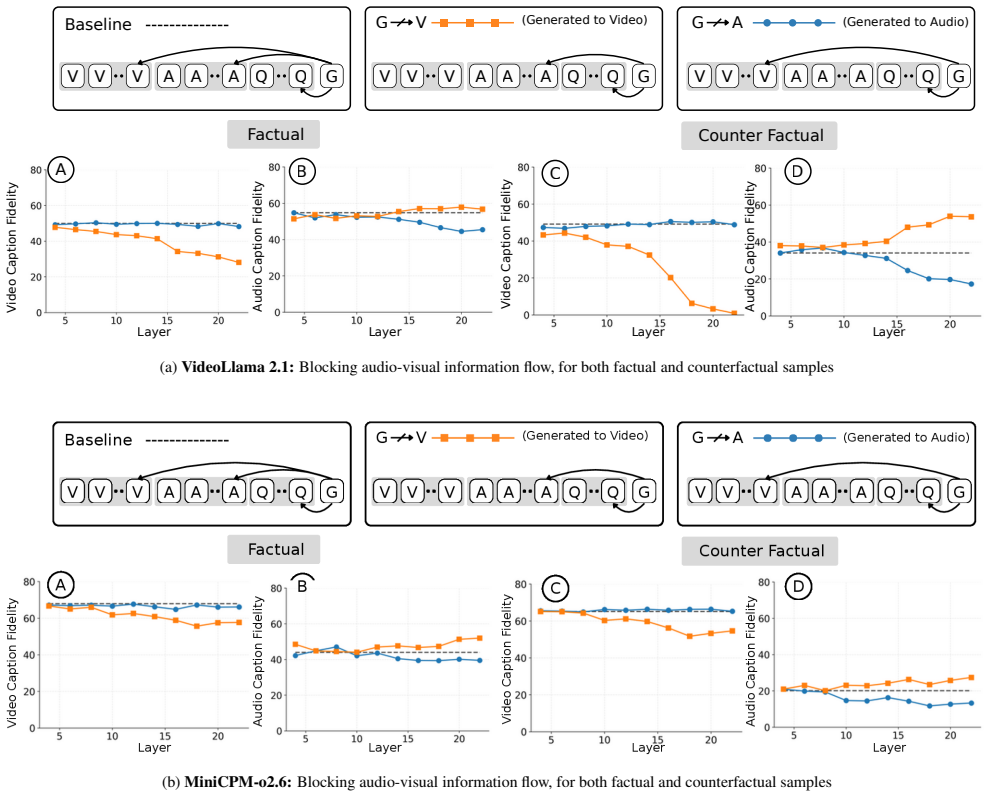
Probing analyses show that useful latent audio information is present, but deeper fusion layers disproportionately privilege visual representations that tend to suppress audio cues... attention knockout experiments... blocking visual pathways recovers audio understanding
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We observe that these decoded tokens meaningfully capture sound sources... meaningful audio information emerging in the last 5 layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Omni-DeepSearch: A Benchmark for Audio-Driven Omni-Modal Deep Search
Omni-DeepSearch is a 640-sample benchmark for audio-driven omni-modal search where the best model reaches only 43.44% accuracy, exposing bottlenecks in audio inference, tool use, and cross-modal reasoning.
Reference graph
Works this paper leans on
-
[1]
Internomni: Extending internvl with audio modality, 2024. Accessed: 2025-11-12. 2, 14
work page 2024
-
[2]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding inter- mediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Rana AlShaikh, Norah Al-Malki, and Maida Almasre. The implementation of the cognitive theory of multimedia learn- ing in the design and evaluation of an ai educational video assistant utilising large language models.Heliyon, 10(3): e25361, 2024. 1
work page 2024
-
[4]
Is your large language model knowledgeable or a choices-only cheater?ArXiv, abs/2407.01992, 2024
Nishant Balepur and Rachel Rudinger. Is your large language model knowledgeable or a choices-only cheater?ArXiv, abs/2407.01992, 2024. 3
-
[5]
Nishant Balepur, Abhilasha Ravichander, and Rachel Rudinger. Artifacts or abduction: How do llms answer multiple-choice questions without the question? InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10308–10330, 2024. 3
work page 2024
-
[6]
Meteor: An automatic metric for mt evaluation with improved correlation with hu- man judgments
Satanjeev Banerjee and Alon Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with hu- man judgments. InProceedings of the acl workshop on in- trinsic and extrinsic evaluation measures for machine trans- lation and/or summarization, pages 65–72, 2005. 4
work page 2005
-
[7]
Lvlm-intrepret: An interpretability tool for large vision-language models
Gabriela Ben Melech Stan, Estelle Aflalo, Raanan Yehezkel Rohekar, Anahita Bhiwandiwalla, Shao-Yen Tseng, Matthew Lyle Olson, Yaniv Gurwicz, Chenfei Wu, Nan Duan, and Vasudev Lal. Lvlm-intrepret: An interpretability tool for large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8182–8187, ...
work page 2024
-
[8]
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma˜nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, M...
work page 2024
-
[9]
The revo- lution of multimodal large language models: A survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. The revo- lution of multimodal large language models: A survey. In Findings of the Association for Computational Linguistics: ACL 2024, pages 13590–13618, Bangkok, Thailand, 2024. Association for Comput...
work page 2024
-
[10]
Clair: Evaluating image captions with large language models.arXiv preprint arXiv:2310.12971, 2023
David Chan, Suzanne Petryk, Joseph E Gonzalez, Trevor Darrell, and John Canny. Clair: Evaluating image captions with large language models.arXiv preprint arXiv:2310.12971, 2023. 4
-
[11]
Emova: Empowering language models to see, hear and speak with vivid emotions
Kai Chen, Yunhao Gou, Runhui Huang, Zhili Liu, Daxin Tan, Jing Xu, Chunwei Wang, Yi Zhu, Yihan Zeng, Kuo Yang, et al. Emova: Empowering language models to see, hear and speak with vivid emotions. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5455–5466, 2025. 1
work page 2025
-
[12]
Om- nixr: Evaluating omni-modality language models on reason- ing across modalities
Lichang Chen, Hexiang Hu, Mingda Zhang, Yiwen Chen, Zifeng Wang, Y ANDONG LI, Pranav Shyam, Tianyi Zhou, Heng Huang, Ming-Hsuan Yang, and Boqing Gong. Om- nixr: Evaluating omni-modality language models on reason- ing across modalities. InThe Thirteenth International Con- ference on Learning Representations, 2025. 1
work page 2025
-
[13]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 2, 15
work page 2024
-
[14]
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Yaot- ing Wang, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Avtrustbench: Assessing and enhancing relia- bility and robustness in audio-visual llms.arXiv preprint arXiv:2501.02135, 2025. 4
-
[15]
Clotho: An audio captioning dataset
Konstantinos Drossos, Samuel Lipping, and Tuomas Virta- nen. Clotho: An audio captioning dataset. InICASSP 2020- 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 736–740. IEEE,
work page 2020
-
[16]
Transcoders find interpretable llm feature circuits
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable llm feature circuits. InAd- vances in Neural Information Processing Systems, pages 24375–24410. Curran Associates, Inc., 2024. 1
work page 2024
-
[17]
A mathemati- cal framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathemati- cal framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021. 2, 5
work page 2021
-
[18]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021. 2
work page 2021
-
[19]
Wes Gurnee, Neel Nanda, Matthew Pauly, Katherine Harvey, Dmitrii Troitskii, and Dimitris Bertsimas. Finding neurons in a haystack: Case studies with sparse probing.arXiv preprint arXiv:2305.01610, 2023. 1
-
[20]
Clipscore: A reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning. InProceedings of the 2021 confer- ence on empirical methods in natural language processing, pages 7514–7528, 2021. 4
work page 2021
-
[21]
Musashi Hinck, Carolin Holtermann, Matthew Lyle Olson, Florian Schneider, Sungduk Yu, Anahita Bhiwandiwalla, Anne Lauscher, Shao-Yen Tseng, and Vasudev Lal. Why do LLaV A vision-language models reply to images in English? InFindings of the Association for Computational Linguis- tics: EMNLP 2024, pages 13402–13421, Miami, Florida, USA, 2024. Association fo...
work page 2024
-
[22]
Noriaki Hirose, Catherine Glossop, Dhruv Shah, and Sergey Levine. Omnivla: An omni-modal vision- language-action model for robot navigation.arXiv preprint arXiv:2509.19480, 2025. 1
-
[23]
Worldsense: Evaluating real-world omnimodal understanding for multimodal llms, 2025
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omni- modal understanding for multimodal llms.arXiv preprint arXiv:2502.04326, 2025. 13
-
[24]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395, 2024. 2, 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Jinsheng Huang, Liang Chen, Taian Guo, Fu Zeng, Yusheng Zhao, Bohan Wu, Ye Yuan, Haozhe Zhao, Zhihui Guo, Yichi Zhang, Jingyang Yuan, Wei Ju, Luchen Liu, Tianyu Liu, Baobao Chang, and Ming Zhang. Mmevalpro: Calibrating multimodal benchmarks towards trustworthy and efficient evaluation.ArXiv, abs/2407.00468, 2024. 3
-
[26]
Vlind- bench: Measuring language priors in large vision-language models
Kang il Lee, Minbeom Kim, Seunghyun Yoon, Minsu Kim, Dongryeol Lee, Hyukhun Koh, and Kyomin Jung. Vlind- bench: Measuring language priors in large vision-language models. InNorth American Chapter of the Association for Computational Linguistics, 2024. 4
work page 2024
-
[27]
What’s in the im- age? a deep-dive into the vision of vision language models
Omri Kaduri, Shai Bagon, and Tali Dekel. What’s in the im- age? a deep-dive into the vision of vision language models. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 14549–14558, 2025. 1, 2, 4
work page 2025
-
[28]
Text encoders bottleneck compositionality in contrastive vision- language models
Amita Kamath, Jack Hessel, and Kai-Wei Chang. Text encoders bottleneck compositionality in contrastive vision- language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4933–4944, 2023. 4
work page 2023
-
[29]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. InNAACL-HLT, 2019. 4, 12
work page 2019
-
[30]
Abhinav Kumar, Chenhao Tan, and Amit Sharma. Prob- ing classifiers are unreliable for concept removal and detec- tion.Advances in Neural Information Processing Systems, 35:17994–18008, 2022. 3
work page 2022
-
[31]
The unlocking spell on base llms: Re- thinking alignment via in-context learning
Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavat- ula, and Yejin Choi. The unlocking spell on base llms: Re- thinking alignment via in-context learning. InThe Twelfth International Conference on Learning Representations. 7
-
[32]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 4
work page 2004
-
[33]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
work page 2023
-
[34]
Yi Liu, Lianzhe Huang, Shicheng Li, Sishuo Chen, Hao Zhou, Fandong Meng, Jie Zhou, and Xu Sun. Recall: A benchmark for llms robustness against external counterfac- tual knowledge.ArXiv, abs/2311.08147, 2023. 4
-
[35]
arXiv preprint arXiv:2306.09093 , year=
Chenyang Lyu, Minghao Wu, Longyue Wang, Xinting Huang, Bingshuai Liu, Zefeng Du, Shuming Shi, and Zhaopeng Tu. Macaw-llm: Multi-modal language modeling with image, audio, video, and text integration.arXiv preprint arXiv:2306.09093, 2023. 1
-
[36]
Yujian Ma, Jinqiu Sang, and Ruizhe Li. Behind the scenes: Mechanistic interpretability of lora-adapted whis- per for speech emotion recognition.arXiv preprint arXiv:2509.08454, 2025. 1
-
[37]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in gpt.Ad- vances in neural information processing systems, 35:17359– 17372, 2022. 2
work page 2022
-
[38]
Bertalan Mesk ´o. The impact of multimodal large language models on health care’s future.Journal of medical Internet research, 25:e52865, 2023. 1
work page 2023
-
[39]
Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiuding Sun, et al. The quest for the right mediator: A history, survey, and the- oretical grounding of causal interpretability.arXiv preprint arXiv:2408.01416, 2024. 3
-
[40]
J ¨org M ¨uller, Oliver Mitesser, H Martin Schaefer, Sebastian Seibold, Annika Busse, Peter Kriegel, Dominik Rabl, Rudy Gelis, Alejandro Arteaga, Juan Freile, et al. Soundscapes and deep learning enable tracking biodiversity recovery in tropical forests.Nature communications, 14(1):6191, 2023. 1
work page 2023
-
[41]
Fact finding: Attempting to reverse-engineer factual recall on the neuron level
Neel Nanda, Senthooran Rajamanoharan, Janos Kramar, and Rohin Shah. Fact finding: Attempting to reverse-engineer factual recall on the neuron level. InAlignment Forum, page 6, 2023. 2
work page 2023
-
[42]
Towards interpreting visual in- formation processing in vision-language models
Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez. Towards interpreting visual in- formation processing in vision-language models. InThe Thirteenth International Conference on Learning Represen- tations. 1, 2, 5
-
[43]
Sfr-rag: Towards contextually faithful llms.ArXiv, abs/2409.09916, 2024
Xuan-Phi Nguyen, Shrey Pandit, Senthil Purushwalkam, Austin Xu, Hailin Chen, Yifei Ming, Zixuan Ke, Silvio Savarese, Caiming Xong, and Shafiq Joty. Sfr-rag: Towards contextually faithful llms.ArXiv, abs/2409.09916, 2024. 4
-
[44]
Interpreting gpt: The logit lens
Nostalgebraist. Interpreting gpt: The logit lens. https : / / www . alignmentforum . org / posts / AcKRB8wDpdaN6v6ru/interpreting- gpt- the- logit-lens, 2020. Accessed: 2024-09-23. 3
work page 2020
-
[45]
In-context learning and induction heads.CoRR, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.CoRR, 2022. 2
work page 2022
- [46]
-
[47]
Learning interpretable features in audio latent spaces via sparse autoencoders
Nathan Paek, Yongyi Zang, Qihui Yang, and Randal Leis- tikow. Learning interpretable features in audio latent spaces via sparse autoencoders. InMechanistic Interpretability Workshop at NeurIPS 2025. 1
work page 2025
-
[48]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[49]
Object hallucination in image cap- tioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045,
work page 2018
-
[50]
Pandagpt: One model to instruction-follow them all.arXiv preprint arXiv:2305.16355, 2023
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all.arXiv preprint arXiv:2305.16355, 2023. 2
-
[51]
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. video-salmonn: Speech-enhanced audio-visual large language models.arXiv preprint arXiv:2406.15704, 2024. 1
-
[52]
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. Avhbench: A cross- modal hallucination benchmark for audio-visual large lan- guage models.arXiv preprint arXiv:2410.18325, 2024. 4, 13
-
[53]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Simas Sakenis, Jason Huang, Yaron Singer, and Stuart Shieber. Causal mediation analysis for in- terpreting neural nlp: The case of gender bias.arXiv preprint arXiv:2004.12265, 2020. 3
-
[54]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. In The Eleventh International Conference on Learning Repre- sentations. 2
-
[55]
Do llamas work in English? on the latent language of multilingual transformers
Chris Wendler, Veniamin Veselovsky, Giovanni Monea, and Robert West. Do llamas work in English? on the latent language of multilingual transformers. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 15366– 15394, Bangkok, Thailand, 2024. Association for Computa- tional Linguistics. 5
work page 2024
-
[56]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2. 5-omni technical report.arXiv preprint arXiv:2503.20215, 2025. 1, 2, 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Qwen3-omni technical report, 2025
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page 2025
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Chih-Kai Yang, Neo Ho, Yi-Jyun Lee, and Hung-yi Lee. Audiolens: A closer look at auditory attribute percep- tion of large audio-language models.arXiv preprint arXiv:2506.05140, 2025. 1, 2
-
[60]
Yiqun Yao, Xiang Li, Xin Jiang, Xuezhi Fang, Naitong Yu, Aixin Sun, and Yequan Wang. Roboego system card: An omnimodal model with native full duplexity.arXiv preprint arXiv:2506.01934, 2025. 1
-
[61]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision- language models behave like bags-of-words, and what to do about it? InThe Eleventh International Conference on Learning Representations. 4
-
[62]
Fred Zhang and Neel Nanda. Towards best practices of ac- tivation patching in language models: Metrics and methods. arXiv preprint arXiv:2309.16042, 2023. 1
-
[63]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing: System Demonstrations, pages 543–553, 2023. 1, 2, 4, 14
work page 2023
-
[64]
Qwen3 em- bedding: Advancing text embedding and reranking through foundation models, 2025
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 em- bedding: Advancing text embedding and reranking through foundation models, 2025. 13
work page 2025
-
[65]
Cross-modal information flow in multimodal large language models
Zhi Zhang, Srishti Yadav, Fengze Han, and Ekaterina Shutova. Cross-modal information flow in multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19781–19791, 2025. 2
work page 2025
-
[66]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025
Ziwei Zhou, Rui Wang, and Zuxuan Wu. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities.arXiv preprint arXiv:2505.17862, 2025. 1, 4 Do Audio-Visual Large Language Models Really See and Hear? Supplementary Material Contents
-
[67]
Experimental Setup 3
-
[68]
Investigating Attention Pattern 4
-
[69]
Probing Audio Representations 5
-
[70]
Factual Audio-Visual Understanding
Investigating Information Flow 5 7.1. Factual Audio-Visual Understanding . . . . 6 7.2. Counter-Factual Audio-Visual Understanding 7
-
[71]
Investigating Origins of Visual Bias 7
-
[72]
Conclusion, Limitations, and Future Work 8 A . Dataset 12 A.1 . Data Source . . . . . . . . . . . . . . . . . . 12 A.2 . Counterfactual Sample Curation . . . . . . . 13 A.3 . Existing Benchmarks . . . . . . . . . . . . . 13 B . Evaluation 14 B.1. Human Evaluation Study . . . . . . . . . . . 14 B.2. LLM Judge Prompts . . . . . . . . . . . . . 14 C . Qualit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.