Recognition: no theorem link
Overcoming the "Impracticality" of RAG: Proposing a Real-World Benchmark and Multi-Dimensional Diagnostic Framework
Pith reviewed 2026-05-13 20:24 UTC · model grok-4.3
The pith
RAG models that score well on academic tests often fail in enterprise use because benchmarks miss interlocking real-world factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
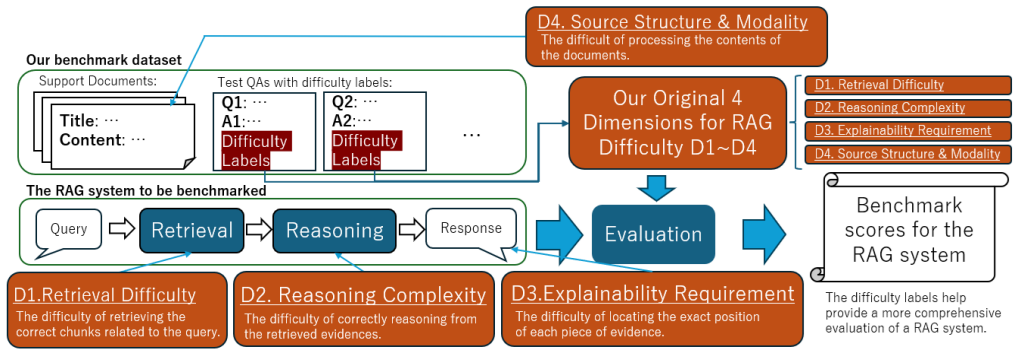
Existing academic benchmarks fail to systematically diagnose these interlocking challenges, resulting in a critical gap where models achieving high performance scores fail to meet the expected reliability in practical deployment. To bridge this discrepancy, this research proposes a multi-dimensional diagnostic framework by defining a four-axis difficulty taxonomy and integrating it into an enterprise RAG benchmark to diagnose potential system weaknesses.
What carries the argument
Four-axis difficulty taxonomy (reasoning complexity, retrieval difficulty, document structure, operational explainability) integrated into an enterprise RAG benchmark for targeted diagnosis of system weaknesses.
If this is right
- Models with high scores on existing benchmarks can be re-tested to reveal previously hidden weaknesses across the four axes.
- The framework supports diagnosis of specific failure points in RAG pipelines before full enterprise rollout.
- Enterprise RAG development can prioritize fixes along the dimensions of reasoning, retrieval, structure, and explainability.
- Future benchmark design for generative systems will need to incorporate multi-dimensional testing to better match deployment conditions.
Where Pith is reading between the lines
- Adoption of this taxonomy could encourage similar structured diagnostics for other AI generation tasks outside RAG.
- If the benchmark correlates strongly with real outcomes, companies could use it to de-risk RAG projects and cut costly failures.
- Researchers might test extensions of the axes to include factors such as response latency or data privacy constraints.
- The approach opens a path for standardized reporting of RAG performance that includes diagnostic breakdowns rather than single scores.
Load-bearing premise
The four-axis taxonomy adequately captures the composite factors that determine real-world RAG reliability and the proposed enterprise benchmark is representative enough to expose deployment gaps.
What would settle it
Run models on the new benchmark, then deploy the same models in real enterprise RAG tasks and measure whether benchmark scores predict actual reliability or if key failures still occur outside the four axes.
Figures

read the original abstract
Performance evaluation of Retrieval-Augmented Generation (RAG) systems within enterprise environments is governed by multi-dimensional and composite factors extending far beyond simple final accuracy checks. These factors include reasoning complexity, retrieval difficulty, the diverse structure of documents, and stringent requirements for operational explainability. Existing academic benchmarks fail to systematically diagnose these interlocking challenges, resulting in a critical gap where models achieving high performance scores fail to meet the expected reliability in practical deployment. To bridge this discrepancy, this research proposes a multi-dimensional diagnostic framework by defining a four-axis difficulty taxonomy and integrating it into an enterprise RAG benchmark to diagnose potential system weaknesses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that existing academic benchmarks for Retrieval-Augmented Generation (RAG) systems are inadequate for enterprise use because they overlook interlocking factors such as reasoning complexity, retrieval difficulty, document structure, and operational explainability. This creates a gap where high benchmark scores do not predict reliable real-world performance. To address the gap, the authors propose a four-axis difficulty taxonomy that is integrated into a new enterprise RAG benchmark intended to diagnose system weaknesses.
Significance. If the taxonomy is given concrete, reproducible definitions and the benchmark is validated on representative enterprise data, the work could supply a practical diagnostic tool that helps close the academic-to-deployment gap in RAG evaluation. The proposal is constructive rather than empirical, which is appropriate for a framework paper provided the axes are operationalized.
major comments (2)
- [Abstract] Abstract: the claim that 'existing academic benchmarks fail to systematically diagnose these interlocking challenges' is asserted without citing any specific benchmarks, studies, or quantitative evidence of the performance-deployment discrepancy, which is the central motivation for the proposed framework.
- [Proposed Framework] Four-axis taxonomy (reasoning complexity, retrieval difficulty, document structure, operational explainability): the axes are named but supplied with neither operational definitions, scoring rubrics, example queries, nor inter-axis independence checks, leaving the adequacy of the taxonomy as an untestable assertion rather than a load-bearing, evaluable component of the proposal.
minor comments (1)
- Add a brief comparison table or paragraph contrasting the proposed benchmark with at least two existing RAG benchmarks (e.g., those focused on retrieval accuracy or end-to-end QA) to clarify the incremental diagnostic value.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'existing academic benchmarks fail to systematically diagnose these interlocking challenges' is asserted without citing any specific benchmarks, studies, or quantitative evidence of the performance-deployment discrepancy, which is the central motivation for the proposed framework.
Authors: We agree that the abstract would be strengthened by explicit citations and evidence. In the revision we will add references to representative studies and benchmarks (e.g., those documenting the gap between high academic RAG scores and enterprise reliability) to substantiate the motivation. revision: yes
-
Referee: [Proposed Framework] Four-axis taxonomy (reasoning complexity, retrieval difficulty, document structure, operational explainability): the axes are named but supplied with neither operational definitions, scoring rubrics, example queries, nor inter-axis independence checks, leaving the adequacy of the taxonomy as an untestable assertion rather than a load-bearing, evaluable component of the proposal.
Authors: We accept that the taxonomy requires concrete operationalization to be evaluable. The revised manuscript will include explicit definitions, scoring rubrics, representative enterprise example queries for each axis, and a brief analysis of inter-axis independence. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript is a proposal paper that introduces a four-axis difficulty taxonomy (reasoning complexity, retrieval difficulty, document structure, operational explainability) and integrates it into an enterprise RAG benchmark. There are no equations, fitted parameters, derivations, or self-citations that reduce the central claim to prior inputs by construction. The framework is defined explicitly as a new diagnostic structure to address identified gaps in existing benchmarks, making the adequacy of the axes the explicit object of the proposal rather than a hidden premise. This is a constructive contribution without any load-bearing steps that exhibit circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Enterprise RAG performance evaluation is governed by multi-dimensional factors including reasoning complexity, retrieval difficulty, document structure, and operational explainability.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
M.; Zobeiri, A.; Dehghani, M.; Mohammadkhani, M.; Mohammadi, B.; Ghahroodi, O.; Baghshah, M
Abootorabi, M. M.; Zobeiri, A.; Dehghani, M.; Mohammadkhani, M.; Mohammadi, B.; Ghahroodi, O.; Baghshah, M. S.; and Asgari, E. 2025. Ask in any modality: A comprehensive survey on multimodal retrieval-augmented generation. arXiv preprint arXiv:2502.08826
-
[4]
Chen, J.; Lin, H.; Han, X.; and Sun, L. 2024. Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 17754--17762
work page 2024
- [5]
-
[6]
Gu, J.; Jiang, X.; Shi, Z.; Tan, H.; Zhai, X.; Xu, C.; Li, W.; Shen, Y.; Ma, S.; Liu, H.; et al. 2024. A survey on llm-as-a-judge. arXiv preprint arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
u ttler, H.; Lewis, M.; Yih, W.-t.; Rockt\
Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; K\" u ttler, H.; Lewis, M.; Yih, W.-t.; Rockt\" a schel, T.; Riedel, S.; and Kiela, D. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS '20. Red Hook, NY, USA: Cu...
work page 2020
- [8]
-
[9]
Luo, S.; Liu, Y.; Lin, D.; Zhai, Y.; Wang, B.; Yang, X.; and Liu, J. 2025. ETRQA: A Comprehensive Benchmark for Evaluating Event Temporal Reasoning Abilities of Large Language Models. In Findings of the Association for Computational Linguistics: ACL 2025, 23321--23339
work page 2025
- [10]
-
[11]
Suri, M.; Mathur, P.; Dernoncourt, F.; Goswami, K.; Rossi, R. A.; and Manocha, D. 2024. Visdom: Multi-document qa with visually rich elements using multimodal retrieval-augmented generation. arXiv preprint arXiv:2412.10704
- [12]
- [13]
- [14]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.