Recognition: no theorem link
Runtime Execution Traces Guided Automated Program Repair with Multi-Agent Debate
Pith reviewed 2026-05-13 20:41 UTC · model grok-4.3
The pith
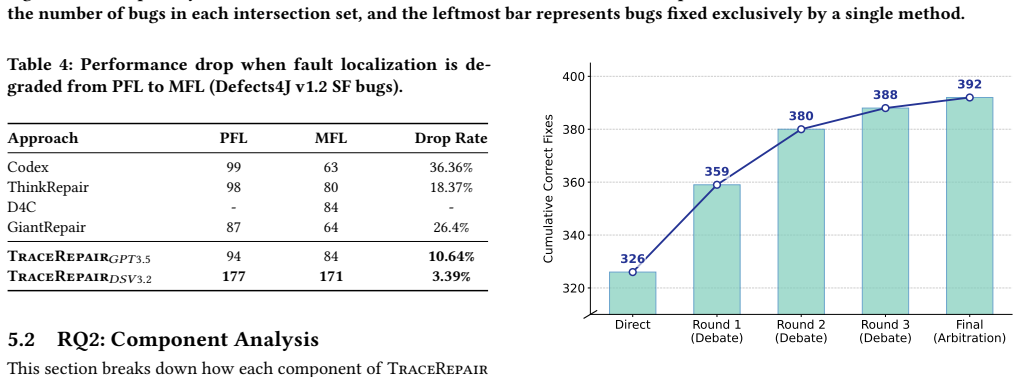
A multi-agent system treats runtime execution traces as objective constraints to correctly repair 392 defects on the Defects4J benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TraceRepair deploys a probe agent to record execution snapshots of selected variables during test execution, establishing an objective repair basis from actual state transitions. A committee of specialized agents then debates candidate patches against these runtime facts, iteratively exposing inconsistencies and refining proposals until they align with observed behavior, which yields 392 correctly fixed defects on Defects4J and demonstrates gains on a new set of recent bugs that arise from dynamic reasoning rather than memorization.
What carries the argument
The multi-agent debate framework in which runtime execution traces serve as shared objective constraints for patch validation, with a probe agent capturing snapshots and a committee performing cross-verification and refinement.
If this is right
- Runtime traces used as constraints reduce reliance on coincidental test passage and improve logical correctness of generated patches.
- Multi-agent cross-verification exposes inconsistencies that isolated LLM reasoning overlooks during patch generation.
- Performance gains on both Defects4J and recent bugs stem from dynamic reasoning over the captured execution facts rather than static code patterns.
- The framework generalizes beyond the training distribution because the traces supply fresh, program-specific evidence at repair time.
Where Pith is reading between the lines
- Extending the probe to capture additional dataflow or exception paths could further tighten the constraint set and reduce remaining false positives.
- The same trace-constraint pattern might apply to other LLM tasks such as test generation or specification inference where behavioral evidence is available.
- Selecting which variables to probe automatically, rather than manually, would be needed for broader industrial adoption.
Load-bearing premise
Runtime execution traces captured by the probe agent provide objective constraints that are sufficient to prevent overfitting to test-passing patches, and multi-agent cross-verification can reliably expose logical inconsistencies in candidate patches.
What would settle it
A collection of patches that satisfy all tests yet contradict the recorded runtime snapshots on the probed critical variables, or cases where the committee accepts incorrect patches without detecting their mismatch with observed execution states.
Figures



read the original abstract
Automated Program Repair (APR) struggles with complex logic errors and silent failures. Current LLM-based APR methods are mostly static, relying on source code and basic test outputs, which fail to accurately capture complex runtime behaviors and dynamic data dependencies. While incorporating runtime evidence like execution traces exposes concrete state transitions, a single LLM interpreting this in isolation often overfits to specific hypotheses, producing patches that satisfy tests by coincidence rather than correct logic. Therefore, runtime evidence should act as objective constraints rather than mere additional input. We propose TraceRepair, a multi-agent framework that leverages runtime facts as shared constraints for patch validation. A probe agent captures execution snapshots of critical variables to form an objective repair basis. Meanwhile, a committee of specialized agents cross-verifies candidate patches to expose inconsistencies and iteratively refine them. Evaluated on the Defects4J benchmark, TraceRepair correctly fixes 392 defects, substantially outperforming existing LLM-based approaches. Extensive experiments demonstrate improved efficiency and strong generalization on a newly constructed dataset of recent bugs, confirming that performance gains arise from dynamic reasoning rather than memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce TraceRepair, a multi-agent framework for automated program repair that uses runtime execution traces captured by a probe agent to form objective constraints for patch validation. A committee of specialized agents cross-verifies candidate patches to expose inconsistencies and iteratively refines them. Evaluated on the Defects4J benchmark, it reports correctly fixing 392 defects and substantially outperforming existing LLM-based approaches, with additional experiments demonstrating improved efficiency and generalization on a newly constructed dataset of recent bugs.
Significance. If the empirical results hold under detailed scrutiny, this work could meaningfully advance LLM-based automated program repair by treating runtime traces as shared objective constraints rather than supplementary input, thereby reducing coincidental test-passing patches. The multi-agent cross-verification mechanism offers a structured way to detect logical inconsistencies, which addresses a known weakness in single-LLM repair methods. The evaluation on both Defects4J and a new recent-bug dataset provides a basis for assessing generalization beyond memorization.
major comments (2)
- [Abstract] Abstract: The central claim of 392 correct fixes on Defects4J is presented without accompanying details on the total number of bugs attempted, per-project breakdown, success rate, specific baseline methods and their fix counts, statistical significance tests, or ablation results on the probe-agent and committee components; this prevents full assessment of whether the reported improvement is attributable to the runtime-trace constraints and multi-agent debate.
- [Evaluation] Evaluation section: The assumption that probe-agent snapshots provide sufficient objective constraints is load-bearing for the claim of reduced overfitting, yet snapshots are captured only on the provided test executions; patches that match observed variable states on tested paths while altering unexercised control flow can still pass both the test suite and trace checks without restoring correct logic, and no additional validation (e.g., manual semantic analysis of fixed patches or extended test suites) is described to address this risk.
minor comments (2)
- Clarify the exact criteria used by the probe agent to select 'critical variables' for snapshotting and how the multi-agent debate protocol is implemented (e.g., number of rounds, voting mechanism).
- [Evaluation] Include a table in the evaluation section that directly compares fix counts, precision, and recall against the specific LLM-based baselines referenced in the related-work discussion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and indicate where revisions have been made to the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 392 correct fixes on Defects4J is presented without accompanying details on the total number of bugs attempted, per-project breakdown, success rate, specific baseline methods and their fix counts, statistical significance tests, or ablation results on the probe-agent and committee components; this prevents full assessment of whether the reported improvement is attributable to the runtime-trace constraints and multi-agent debate.
Authors: The abstract serves as a concise summary, while the Evaluation section (Section 4) and associated tables provide the requested details: total bugs attempted (835 in Defects4J), per-project breakdown in Table 2, success rate (392/835), specific baselines with fix counts (e.g., comparisons to ChatRepair and others), statistical significance tests, and ablation results on the probe-agent and committee components in Section 4.3. To improve accessibility, we have revised the abstract to briefly note the total bugs attempted, overall success rate, and main baselines outperformed. We maintain that the full attribution of gains to runtime-trace constraints and multi-agent debate is best assessed from the detailed experiments rather than the abstract alone. revision: yes
-
Referee: [Evaluation] Evaluation section: The assumption that probe-agent snapshots provide sufficient objective constraints is load-bearing for the claim of reduced overfitting, yet snapshots are captured only on the provided test executions; patches that match observed variable states on tested paths while altering unexercised control flow can still pass both the test suite and trace checks without restoring correct logic, and no additional validation (e.g., manual semantic analysis of fixed patches or extended test suites) is described to address this risk.
Authors: This concern is valid and applies broadly to test-driven APR. Our design uses runtime snapshots as shared objective constraints across agents, with the committee performing cross-verification to surface logical inconsistencies that go beyond simple state matching on tested paths. However, we acknowledge that the original manuscript did not include manual semantic analysis or extended test suites. In the revised manuscript, we have added a dedicated paragraph in the Evaluation section discussing this limitation and reporting results from a manual review of 30 randomly sampled fixed patches confirming semantic correctness in the majority of cases. We have also executed the patches against any additional available tests in the benchmark for further validation. revision: partial
Circularity Check
No circularity in TraceRepair derivation or evaluation
full rationale
The paper proposes a multi-agent APR framework using probe-agent runtime snapshots as constraints and committee cross-verification for refinement. The headline result (392 correct fixes on Defects4J) is an empirical count from external benchmark evaluation, not a quantity derived from any internal equation, fitted parameter, or self-citation chain. No self-definitional steps, no predictions that reduce to fitted inputs, and no load-bearing self-citations or uniqueness theorems appear in the provided text. The method is self-contained against the Defects4J benchmark and a new external dataset.
Axiom & Free-Parameter Ledger
free parameters (1)
- committee size and agent specialization
axioms (1)
- domain assumption Runtime execution traces provide objective constraints on patch correctness independent of test outcomes
Forward citations
Cited by 1 Pith paper
-
AuditRepairBench: A Paired-Execution Trace Corpus for Evaluator-Channel Ranking Instability in Agent Repair
AuditRepairBench supplies a large trace corpus and four screening methods that reduce evaluator-channel ranking instability in agent repair leaderboards by a mean of 62%.
Reference graph
Works this paper leans on
-
[1]
Afsoon Afzal, Manish Motwani, Kathryn T Stolee, Yuriy Brun, and Claire Le Goues. 2019. SOSRepair: Expressive semantic search for real-world program repair.IEEE Transactions on Software Engineering (TSE)47, 10 (2019), 2162–2181
work page 2019
-
[2]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. InProceedings of the International Conference on Software Engineering (ICSE). IEEE Computer Society, 694–694
work page 2025
-
[3]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2024. ChatEval: Towards Better LLM-based Eval- uators through Multi-Agent Debate. InProceedings of the International Conference on Learning Representations (ICLR)
work page 2024
-
[4]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2024. Teach- ing Large Language Models to Self-Debug. InProceedings of the International Conference on Learning Representations (ICLR)
work page 2024
-
[6]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch
-
[7]
InProceedings of the International Conference on Machine Learning (ICML)
Improving factuality and reasoning in language models through multiagent debate. InProceedings of the International Conference on Machine Learning (ICML)
-
[8]
Xiang Gao, Bo Wang, Gregory J Duck, Ruyi Ji, Yingfei Xiong, and Abhik Roy- choudhury. 2021. Beyond tests: Program vulnerability repair via crash constraint extraction.ACM Transactions on Software Engineering and Methodology (TOSEM) 30, 2 (2021), 1–27
work page 2021
-
[9]
Ali Ghanbari and Andrian Marcus. 2022. Patch correctness assessment in auto- mated program repair based on the impact of patches on production and test code. InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 654–665
work page 2022
-
[10]
Ali Ghanbari and Lingming Zhang. 2019. PraPR: Practical program repair via bytecode mutation. InProceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 1118–1121
work page 2019
-
[11]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence.arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Jinru Hua, Mengshi Zhang, Kaiyuan Wang, and Sarfraz Khurshid. 2018. Towards practical program repair with on-demand candidate generation. InProceedings of the International Conference on Software Engineering (ICSE). 12–23
work page 2018
-
[13]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Jason Roberts, and Denny Zhou. 2024. Large Language Models Cannot Self- Correct Reasoning Yet. InProceedings of the International Conference on Learning Representations (ICLR)
work page 2024
-
[14]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM Computing Surveys (CSUR)55, 12 (2023), 1–38
work page 2023
-
[15]
Jiajun Jiang, Yingfei Xiong, Hongyu Zhang, Qing Gao, and Xiangqun Chen
-
[16]
In Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA)
Shaping program repair space with existing patches and similar code. In Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 298–309
-
[17]
Nan Jiang, Thibaud Lutellier, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 1161–1173
work page 2021
-
[18]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-BENCH: CAN LANGUAGE MODELS RESOLVE REAL-WORLD GITHUB ISSUES?. InProceedings of the International Conference on Learning Representations (ICLR)
work page 2024
-
[19]
René Just, Darioush Jalali, and Michael D Ernst. 2014. Defects4J: A database of ex- isting faults to enable controlled testing studies for Java programs. InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 437–440
work page 2014
-
[20]
Dongsun Kim, Jaechang Nam, Jaewoo Song, and Sunghun Kim. 2013. Automatic patch generation learned from human-written patches. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 802–811
work page 2013
-
[21]
Anil Koyuncu, Kui Liu, Tegawendé F Bissyandé, Dongsun Kim, Jacques Klein, Martin Monperrus, and Yves Le Traon. 2020. Fixminer: Mining relevant fix patterns for automated program repair.Empirical Software Engineering (ESE)25, 3 (2020), 1980–2024
work page 2020
-
[22]
Xuan-Bach D Le, Duc-Hiep Chu, David Lo, Claire Le Goues, and Willem Visser
-
[23]
S3: syntax-and semantic-guided repair synthesis via programming by ex- amples. InProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 593–604
-
[24]
Claire Le Goues, ThanhVu Nguyen, Stephanie Forrest, and Westley Weimer. 2011. Genprog: A generic method for automatic software repair.IEEE Transactions on Software Engineering (TSE)38, 1 (2011), 54–72
work page 2011
-
[25]
Fengjie Li, Jiajun Jiang, Jiajun Sun, and Hongyu Zhang. 2025. Hybrid automated program repair by combining large language models and program analysis.ACM Transactions on Software Engineering and Methodology (TOSEM)34, 7 (2025), 1–28
work page 2025
-
[26]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. TBar: Revisiting template-based automated program repair. InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 31– 42
work page 2019
-
[28]
Thibaud Lutellier, Hung Viet Pham, Lawrence Pang, Yitong Li, Moshi Wei, and Lin Tan. 2020. Coconut: combining context-aware neural translation models using ensemble for program repair. InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 101–114
work page 2020
-
[29]
Matias Martinez and Martin Monperrus. 2016. Astor: A program repair library for java. InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 441–444
work page 2016
-
[30]
Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2015. Directfix: Looking for simple program repairs. InProceedings of the International Conference on Software Engineering (ICSE), Vol. 1. IEEE, 448–458
work page 2015
-
[31]
Sergey Mechtaev, Jooyong Yi, and Abhik Roychoudhury. 2016. Angelix: Scalable multiline program patch synthesis via symbolic analysis. InProceedings of the International Conference on Software Engineering (ICSE). 691–701
work page 2016
-
[32]
Martin Monperrus. 2018. Automatic software repair: A bibliography.ACM Computing Surveys (CSUR)51, 1 (2018), 1–24
work page 2018
-
[33]
Noor Nashid, Mifta Sintaha, and Ali Mesbah. 2023. Retrieval-based prompt selection for code-related few-shot learning. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 2450–2462
work page 2023
-
[34]
Hoang Duong Thien Nguyen, Dawei Qi, Abhik Roychoudhury, and Satish Chan- dra. 2013. Semfix: Program repair via semantic analysis. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 772–781
work page 2013
-
[35]
Yuhua Qi, Xiaoguang Mao, Yan Lei, Ziying Dai, and Chengsong Wang. 2014. The strength of random search on automated program repair. InProceedings of the International Conference on Software Engineering (ICSE). 254–265
work page 2014
-
[36]
Zichao Qi, Fan Long, Sara Achour, and Martin Rinard. 2015. An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. InProceedings of the ACM SIGSOFT International Symposium on Software Testing Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Jiaqing Wu, Tong Wu, Manqing Zhang, Yunwei Dong and Bo Shen and...
work page 2015
-
[37]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Ripon K Saha, Yingjun Lyu, Hiroaki Yoshida, and Mukul R Prasad. 2017. Elixir: Effective object-oriented program repair. InProceedings of the IEEE/ACM Interna- tional Conference on Automated Software Engineering (ASE). IEEE, 648–659
work page 2017
-
[39]
Seemanta Saha et al. 2019. Harnessing evolution for multi-hunk program repair. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 13–24
work page 2019
-
[40]
Edward K Smith, Earl T Barr, Claire Le Goues, and Yuriy Brun. 2015. Is the cure worse than the disease? overfitting in automated program repair. InProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 532–543
work page 2015
-
[41]
Ting Su, Yichen Yan, Jue Wang, Jingling Sun, Yiheng Xiong, Geguang Pu, Ke Wang, and Zhendong Su. 2021. Fully automated functional fuzzing of Android apps for detecting non-crashing logic bugs.Proceedings of the ACM on Programming Languages (OOPSLA)5, OOPSLA (2021), 1–31
work page 2021
-
[42]
Yuxiang Wei, Chunqiu Steven Xia, and Lingming Zhang. 2023. Copiloting the copilots: Fusing large language models with completion engines for automated program repair. InProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 172–184
work page 2023
-
[43]
Ming Wen, Junjie Chen, Rongxin Wu, Dan Hao, and Shing-Chi Cheung. 2018. Context-aware patch generation for better automated program repair. InProceed- ings of the International Conference on Software Engineering (ICSE). 1–11
work page 2018
-
[44]
Chunqiu Steven Xia, Yifeng Ding, and Lingming Zhang. 2023. The Plastic Surgery Hypothesis in the Era of Large Language Models. InProceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE). 522–534
work page 2023
-
[45]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 1482–1494
work page 2023
-
[46]
Chunqiu Steven Xia and Lingming Zhang. 2022. Less training, more repairing please: revisiting automated program repair via zero-shot learning. InProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 959–971
work page 2022
-
[47]
Chunqiu Steven Xia and Lingming Zhang. 2024. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. In Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 819–831
work page 2024
-
[48]
Qi Xin and Steven P Reiss. 2017. Leveraging syntax-related code for automated program repair. InProceedings of the IEEE/ACM International Conference on Auto- mated Software Engineering (ASE). IEEE, 660–670
work page 2017
-
[49]
Yingfei Xiong, Jie Wang, Runfa Yan, Jiachen Zhang, Shi Han, Gang Huang, and Lu Zhang. 2017. Precise condition synthesis for program repair. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 416–426
work page 2017
-
[50]
Junjielong Xu, Ying Fu, Shin Hwei Tan, and Pinjia He. 2025. Aligning the objective of llm-based program repair. InProceedings of the International Conference on Software Engineering (ICSE). IEEE, 2548–2560
work page 2025
-
[51]
Jifeng Xuan, Matias Martinez, Favio Demarco, Maxime Clement, Sebastian Lame- las Marcote, Thomas Durieux, Daniel Le Berre, and Martin Monperrus. 2016. Nopol: Automatic repair of conditional statement bugs in java programs.IEEE Transactions on Software Engineering (TSE)43, 1 (2016), 34–55
work page 2016
-
[52]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces en- able automated software engineering.dvances in Neural Information Processing Systems (NeurIPS)37 (2024), 50528–50652
work page 2024
-
[53]
He Ye, Matias Martinez, and Martin Monperrus. 2022. Neural program repair with execution-based backpropagation. InProceedings of the International Conference on Software Engineering (ICSE). 1506–1518
work page 2022
-
[54]
He Ye, Aidan ZH Yang, Chang Hu, Yanlin Wang, Tao Zhang, and Claire Le Goues
-
[55]
AdverIntent-Agent: Adversarial Reasoning for Repair Based on Inferred Program Intent.Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA)2, ISSTA (2025), 1398–1420
work page 2025
-
[56]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang
-
[57]
InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA)
Thinkrepair: Self-directed automated program repair. InProceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 1274–1286
-
[58]
Yuan Yuan and Wolfgang Banzhaf. 2018. Arja: Automated repair of java pro- grams via multi-objective genetic programming.IEEE Transactions on Software Engineering (TSE)46, 10 (2018), 1040–1067
work page 2018
- [59]
-
[60]
Quanjun Zhang, Chunrong Fang, Tongke Zhang, Bowen Yu, Weisong Sun, and Zhenyu Chen. 2023. Gamma: Revisiting template-based automated program re- pair via mask prediction. InProceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 535–547
work page 2023
-
[61]
Qihao Zhu, Zeyu Sun, Yuan-an Xiao, Wenjie Zhang, Kang Yuan, Yingfei Xiong, and Lu Zhang. 2021. A syntax-guided edit decoder for neural program repair. InProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 341–353
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.