Recognition: 3 theorem links
· Lean TheoremAuditRepairBench: A Paired-Execution Trace Corpus for Evaluator-Channel Ranking Instability in Agent Repair
Pith reviewed 2026-05-08 17:47 UTC · model grok-4.3
The pith
Screening-guided blinding cuts rank displacement in agent repair leaderboards by 55-74 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Agent-repair leaderboards reorder under evaluator reconfiguration, and a measurable share of the reordering is produced by methods that consult evaluator-derived signal during internal selection of candidate repairs. AuditRepairBench supplies a paired-execution trace corpus of 576,000 registered cells that operationalizes evaluator-channel-blocking ranking instability. A modular screening architecture decides pathway-blocking through four interchangeable implementations combined into a screening posterior that feeds cell-level flip functionals, set-valued labels, stratified system scores, and set-valued leaderboards. On this corpus screening-guided blinding patches reduce rank displacement 5
What carries the argument
The screening posterior formed by combining four interchangeable channel-detection proxies (learned influence, rule-based exposure ratio, counterfactual sensitivity, and sparse human-audit) that identifies and blocks evaluator-channel leakage before it reaches the repair selector.
If this is right
- The paired-trace corpus supports reproducible measurement of ranking instability across evaluator reconfigurations.
- Uncertainty propagation through the posterior raises 95 percent coverage from 0.81 to 0.95 on the validation subset.
- A rule-only lightweight configuration preserves the original leaderboard at Kendall tau 0.88 after twenty-four GPU-hours.
- Forward transfer to independent community evaluators yields pooled Spearman rho of 0.65.
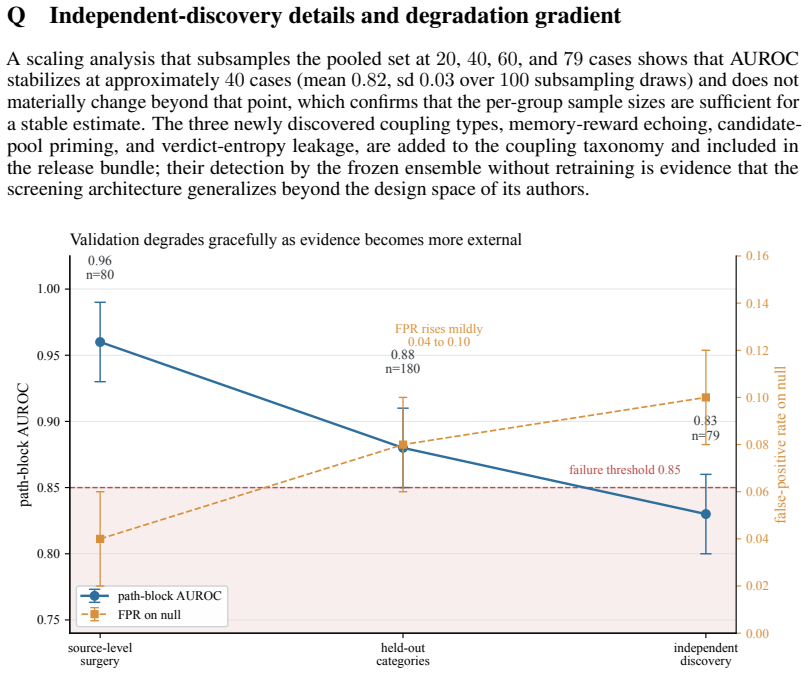
- The 80-case source-level channel-surgery subset attains pooled AUROC 0.83 under blinded independent discovery.
Where Pith is reading between the lines
- Declared observability boundaries may be needed in other agent evaluation pipelines to prevent similar hidden leakage.
- Repair agents could embed lightweight screening as a default step before final candidate ranking.
- The same paired-trace approach could be applied to measure evaluator influence in code generation or planning tasks.
Load-bearing premise
The four screening implementations can be combined into a posterior that reliably identifies evaluator-channel leakage without introducing new selection bias of its own.
What would settle it
A fresh collection of agent repairs run through the screening posterior where the resulting blinding fails to reduce rank displacement below 30 percent would show the reported mitigation does not hold.
Figures








read the original abstract
Agent-repair leaderboards reorder under evaluator reconfiguration, and a measurable share of the reordering is produced by methods that consult evaluator-derived signal during internal selection of candidate repairs. We document this failure mode on a public leaderboard and release AuditRepairBench, a paired-execution trace corpus of 576,000 registered cells (96,000 executed) that operationalizes evaluator-channel-blocking ranking instability within a declared observability boundary. A modular screening architecture decides pathway-blocking through four interchangeable implementations, a learned influence proxy, a rule-based channel-exposure ratio that uses no trained model, a counterfactual sensitivity proxy, and a sparse human-audit proxy, combined into a screening posterior that feeds a cell-level flip functional, a set-valued label, a stratified system score, and a set-valued leaderboard. The resource is supported by mechanism-anchored validation on an 80-case source-level channel-surgery subset, an independent-discovery protocol under which two annotator groups separated from the pipeline developers discover coupling patterns blinded to the screening design and the frozen ensemble attains pooled AUROC 0.83 on their 79 cases, implementation robustness, uncertainty propagation that raises 95% coverage from 0.81 to 0.95, and forward transfer with pooled community-evaluator Spearman \r{ho} = 0.65. Screening-guided blinding patches reduce rank displacement by 55--74% (mean 62%) at fewer than 50 lines of code, whereas random channel blinding produces at most 7% reduction and generic retraining at most 13%. AuditRepairBench-Lite, a rule-only configuration on a 12,000-cell subset, preserves the leaderboard at Kendall {\tau} = 0.88 under twenty-four GPU-hours and is the primary release artifact at 42 GB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AuditRepairBench, a paired-execution trace corpus of 576,000 registered cells (96,000 executed) to document evaluator-channel leakage in agent repair leaderboards. It proposes a modular screening architecture with four implementations (learned influence proxy, rule-based channel-exposure ratio, counterfactual sensitivity proxy, sparse human-audit proxy) combined into a screening posterior that drives a cell-level flip functional, set-valued labels, and a stratified leaderboard. Key results include mechanism-anchored validation on an 80-case subset, independent discovery by blinded annotators yielding pooled AUROC 0.83 on 79 cases, uncertainty propagation improving coverage from 0.81 to 0.95, and screening-guided blinding reducing rank displacement by 55-74% (mean 62%) at under 50 lines of code, outperforming random blinding (≤7%) and generic retraining (≤13%). A rule-only Lite configuration on a 12,000-cell subset achieves Kendall τ = 0.88.
Significance. If the central attribution holds, the work supplies a low-overhead, auditable method to stabilize agent-repair leaderboards against evaluator-derived signal leakage, with the public corpus release, independent annotation protocol, and emphasis on reproducibility (uncertainty propagation, forward transfer Spearman ρ = 0.65) as clear strengths for the AI evaluation community.
major comments (2)
- [Screening Architecture and Posterior] Screening Architecture: The screening posterior combines three evaluator-derived proxies (learned influence, counterfactual sensitivity, sparse human-audit) with a rule-based ratio; because the posterior is defined in terms of the same signals whose leakage it is intended to detect, the 80-case source-level channel-surgery validation and 79-case independent-discovery AUROC do not yet rule out selection bias in the cell-level flip functional or stratified system score applied to the remaining ~95,920 cells.
- [Results on Rank Displacement] Rank Reduction Results: The claim that screening-guided blinding produces 55-74% (mean 62%) reduction in rank displacement is load-bearing for the paper's contribution, yet the provided support is limited to the small validated subset; without an explicit bias audit or ablation showing that the posterior does not confound the stratified leaderboard on the full corpus, the contrast to random blinding (≤7%) and retraining (≤13%) cannot be fully attributed to leakage detection.
minor comments (3)
- [Abstract] The abstract states 'forward transfer with pooled community-evaluator Spearman ρ = 0.65' but provides no definition of the community evaluators or the exact pooling procedure.
- [Methods] Uncertainty propagation that raises 95% coverage from 0.81 to 0.95 is mentioned without a formula, pseudocode, or appendix reference.
- [Corpus Release] AuditRepairBench-Lite is described as the primary 42 GB artifact on a 12,000-cell subset; the exact selection criteria for this subset and how it preserves the full leaderboard properties should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the careful review and valuable feedback on our manuscript. We address the major comments point by point below and outline the revisions we will incorporate.
read point-by-point responses
-
Referee: Screening Architecture: The screening posterior combines three evaluator-derived proxies (learned influence, counterfactual sensitivity, sparse human-audit) with a rule-based ratio; because the posterior is defined in terms of the same signals whose leakage it is intended to detect, the 80-case source-level channel-surgery validation and 79-case independent-discovery AUROC do not yet rule out selection bias in the cell-level flip functional or stratified system score applied to the remaining ~95,920 cells.
Authors: We recognize the validity of this concern about potential selection bias arising from the use of evaluator-derived signals in the screening posterior. The design mitigates this through the inclusion of a purely rule-based channel-exposure ratio that requires no training, and by training the learned proxies on data disjoint from the target traces. Critically, the independent-discovery protocol—conducted by annotators blinded to the screening architecture—achieved a pooled AUROC of 0.83 on 79 cases, indicating alignment with external judgment. The mechanism-anchored validation on the 80-case subset further grounds the approach. Nevertheless, we agree that additional safeguards are warranted for the large-scale application. In the revised manuscript, we will include a dedicated discussion of this issue and an ablation experiment that assesses the sensitivity of the cell-level flip functional and stratified scores to variations in the posterior components on the validated subset, with extrapolation to the full corpus where possible. revision: partial
-
Referee: Rank Reduction Results: The claim that screening-guided blinding produces 55-74% (mean 62%) reduction in rank displacement is load-bearing for the paper's contribution, yet the provided support is limited to the small validated subset; without an explicit bias audit or ablation showing that the posterior does not confound the stratified leaderboard on the full corpus, the contrast to random blinding (≤7%) and retraining (≤13%) cannot be fully attributed to leakage detection.
Authors: The rank displacement reductions were calculated by applying the screening posterior to generate blinding patches across the full corpus and then recomputing the stratified leaderboards, with the validated subsets serving to confirm the reliability of the screening decisions rather than limiting the scope of the measurement. The comparisons to random blinding and generic retraining were performed under the same protocol. We concur that an explicit bias audit or ablation on the full corpus would provide stronger attribution. We will revise the manuscript to clarify the experimental scope and add an ablation study on the 12,000-cell AuditRepairBench-Lite subset, where we vary the posterior and measure impact on Kendall τ and rank stability. This will be supported by the released code to allow community verification on the full set. revision: yes
Circularity Check
No significant circularity; derivation supported by independent blinded annotator validation and rule-only baseline
full rationale
The paper's central claims rest on a screening posterior whose performance is measured against an 80-case channel-surgery subset and an independent-discovery protocol using two annotator groups separated from pipeline developers and blinded to the screening design, yielding pooled AUROC 0.83 on 79 cases. A rule-only Lite configuration achieves Kendall τ = 0.88 on a 12,000-cell subset without any learned components. These external human-grounded benchmarks and the explicit separation of annotators from the screening construction prevent the reported rank reductions from reducing to self-definition or fitted inputs by construction. No load-bearing step equates the screening posterior to the evaluator signals it detects; the validation protocol supplies an independent falsifiability check.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The evaluator-derived signals used inside repair selection are observable and can be blocked without changing the underlying repair distribution.
Reference graph
Works this paper leans on
-
[1]
Jimenez, C.E., Yang, J., Wettig, A., et al. (2023). SWE-bench: Can language models resolve real-world github issues?ICLR
2023
-
[2]
Chowdhury, N., Aung, J., Shern, C.J., et al. (2024). Introducing SWE-bench Verified.OpenAI Technical Report
2024
-
[3]
Yang, J., Jimenez, C.E., Wettig, A., et al. (2024). SWE-agent: Agent-computer interfaces enable automated software engineering.NeurIPS
2024
-
[4]
Wang, X., Li, B., Song, Y ., et al. (2024). OpenHands: An open platform for AI software developers as generalist agents.ICLR
2024
-
[5]
Gauthier, P. et al. (2024). Aider: AI pair programming in your terminal.Open-source release
2024
-
[6]
Zhang, Y ., Ruan, H., Fan, Z., Roychoudhury, A. (2024). AutoCodeRover: Autonomous program improve- ment.ISSTA
2024
-
[7]
Tian, R., Ye, Y ., Qin, Y ., et al. (2024). DebugBench: Evaluating debugging capability of large language models.ACL Findings
2024
-
[8]
Rafi, T.H., Silva, A., Monperrus, M. (2025). RepairBench: Leaderboard of frontier models for program repair.arXiv
2025
-
[9]
Zhao, W., Jiang, N., Moon, C., et al. (2024). Commit0: Library generation from scratch.NeurIPS
2024
-
[10]
Jain, N., Han, K., Gu, A., et al. (2024). LiveCodeBench: Holistic and contamination-free evaluation of large language models for code.ICLR
2024
-
[11]
Du, Y ., Li, S., Torralba, A., Tenenbaum, J.B., Mordatch, I. (2023). Improving factuality and reasoning in language models through multiagent debate.ICML Workshop
2023
-
[12]
Liu, X., Yu, H., Zhang, H., et al. (2023). AgentBench: Evaluating LLMs as agents.ICLR
2023
-
[13]
Qin, Y ., Liang, S., Ye, Y ., et al. (2023). ToolLLM: Facilitating large language models to master 16000+ real-world APIs.NeurIPS
2023
-
[14]
Zhou, S., Xu, F.F., Zhu, H., et al. (2023). WebArena: A realistic web environment for building autonomous agents.ICLR
2023
-
[15]
Kiela, D., Bartolo, M., Nie, Y ., et al. (2021). Dynabench: Rethinking benchmarking in NLP.NAACL
2021
-
[16]
Koh, P.W., Sagawa, S., Marklund, H., et al. (2021). WILDS: A benchmark of in-the-wild distribution shifts.ICML
2021
-
[17]
Zheng, L., Chiang, W.-L., Sheng, Y ., et al. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena.NeurIPS
2023
-
[18]
Dubois, Y ., Galambosi, B., Liang, P., Hashimoto, T.B. (2024). Length-controlled AlpacaEval: A simple way to debias automatic evaluators.arXiv
2024
-
[19]
Panickssery, A., Bowman, S.R., Feng, S. (2024). LLM evaluators recognize and favor their own generations. NeurIPS
2024
-
[20]
Li, J., Sun, S., Yuan, W., et al. (2024). Generative judge for evaluating alignment.ICLR
2024
-
[21]
Saad-Falcon, J., Khattab, O., Potts, C., Zaharia, M. (2024). ARES: Automated evaluation framework for retrieval-augmented generation.NAACL
2024
-
[22]
Chen, T., Tang, Y ., Qiao, X., et al. (2024). Do LLM judges understand code? Analyzing rater reliability on program-repair tasks.EMNLP
2024
-
[23]
Zhuo, T.Y ., Vu, M.C., Chim, J., et al. (2024). BigCodeBench: Benchmarking code generation with diverse function calls and complex instructions.arXiv
2024
-
[24]
Dorner, F.E., Nastl, V .Y ., Hardt, M. (2024). Don’t label twice: Quantity beats quality when comparing binary classifiers on a budget.ICML
2024
-
[25]
Bowman, S.R., Dahl, G.E. (2021). What will it take to fix benchmarking in natural language understanding? NAACL
2021
-
[26]
Ethayarajh, K., Jurafsky, D. (2020). Utility is in the eye of the user: A critique of NLP leaderboards. EMNLP. 10
2020
-
[27]
Rodriguez, P., Barrow, J., Hoyle, A.M., et al. (2021). Evaluation examples are not equally informative: How should that change NLP leaderboards?ACL
2021
-
[28]
Dawid, A.P., Skene, A.M. (1979). Maximum likelihood estimation of observer error-rates using the EM algorithm.Applied Statistics, 28(1), 20–28
1979
-
[29]
Raykar, V .C., Yu, S., Zhao, L.H., et al. (2010). Learning from crowds.JMLR, 11, 1297–1322
2010
-
[30]
Whitehill, J., Ruvolo, P., Wu, T., Bergsma, J., Movellan, J. (2009). Whose vote should count more? NeurIPS
2009
-
[31]
(2003).Partial Identification of Probability Distributions
Manski, C.F. (2003).Partial Identification of Probability Distributions. Springer
2003
-
[32]
(2005).Algorithmic Learning in a Random World
V ovk, V ., Gammerman, A., Shafer, G. (2005).Algorithmic Learning in a Random World. Springer
2005
-
[33]
Gardner, M., Artzi, Y ., Basmov, V ., et al. (2020). Evaluating models’ local decision boundaries via contrast sets.EMNLP Findings
2020
-
[34]
Wu, T., Ribeiro, M.T., Heer, J., Weld, D.S. (2021). Polyjuice: Generating counterfactuals for explaining, evaluating, and improving models.ACL
2021
-
[35]
Kang, H.J., Le Goues, C., Pradel, M. (2022). A survey of machine learning for big code and naturalness. ACM Computing Surveys
2022
-
[36]
Clarkson, M.R., Schneider, F.B. (2008). Quantification of integrity.CSF
2008
-
[37]
Geva, M., Bastings, J., Filippova, K., Globerson, A. (2023). Dissecting recall of factual associations in auto-regressive language models.EMNLP
2023
-
[38]
Wang, K., Variengien, A., Conmy, A., et al. (2023). Interpretability in the wild: A circuit for indirect object identification in GPT-2 small.ICLR
2023
-
[39]
Henderson, P., Hu, J., Romoff, J., et al. (2020). Towards the systematic reporting of the energy and carbon footprints of machine learning.JMLR, 21, 1–43
2020
-
[40]
Dodge, J., Prewitt, T., Combes, R.T., et al. (2022). Measuring the carbon intensity of AI in cloud instances. FAccT
2022
-
[41]
Gebru, T., Morgenstern, J., Vecchione, B., et al. (2021). Datasheets for datasets.Communications of the ACM, 64(12), 86–92
2021
-
[42]
Pushkarna, M., Zaldivar, A., Kjartansson, O. (2022). Data cards: Purposeful and transparent dataset documentation for responsible AI.FAccT
2022
-
[43]
Xiang, J., Xu, X., Chu, X., et al. (2026). Empowering autonomous debugging agents with efficient dynamic analysis.FSE 2026
2026
-
[44]
TraceCoder: A trace-driven multi-agent framework for automated debugging of LLM-generated code.ICSE 2026
Anonymous (2026). TraceCoder: A trace-driven multi-agent framework for automated debugging of LLM-generated code.ICSE 2026
2026
-
[45]
Wang, Z.G., et al. (2026). AgentTrace: Causal graph tracing for root cause analysis in deployed multi-agent systems.ICLR 2026
2026
- [46]
-
[47]
Stein, A., Brown, D., Hassani, H., et al. (2026). Detecting safety violations across many agent traces. arXiv:2604.11806
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Anonymous (2025). Holistic agent leaderboard: The missing infrastructure for AI agent evaluation. arXiv:2510.11977
-
[49]
Wu, Z., Wu, Y ., et al. (2026). Runtime execution traces guided automated program repair with multi-agent debate.arXiv:2604.02647
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [50]
-
[51]
Haque, M., et al. (2025). Towards effectively leveraging execution traces for program repair with code LLMs.ACL Workshop on Knowledge-Augmented NLP
2025
-
[52]
Ye, B., Li, R., Yang, Q., Liu, Y ., Yao, L., Lv, H., Xie, Z., An, C., Li, L., Kong, L., Liu, Q., Sui, Z., Yang, T. (2026). Claw-Eval: Toward trustworthy evaluation of autonomous agents.arXiv:2604.06132
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Tu, X., Wang, T., Lu, Y ., Huang, K., Qu, Y ., Mostafavi, S. (2026). BenchGuard: Who guards the benchmarks? Automated auditing of LLM agent benchmarks.arXiv:2604.24955
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [54]
-
[55]
Debenedetti, E., Zhang, J., Balunovi´c, M., Beurer-Kellner, L., Fischer, M., Tramèr, F. (2024). AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents.NeurIPS Datasets and Benchmarks Track. 11
2024
- [56]
-
[57]
Yang, W., Song, C., Li, X., Ganguly, D., Ma, C., Wang, S., Dou, Z., Zhou, Y ., Chaudhary, V ., Han, X. (2026). ACE-Bench: Agent configurable evaluation with scalable horizons and controllable difficulty. arXiv:2604.06111
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Denison, C., Barez, A., Duvenaud, D., et al. (2025). Recent frontier models are reward hacking.arXiv
2025
-
[59]
Chen, Z., Kishore, R., et al. (2025). MONA: A method for addressing multi-step reward hacking.arXiv
2025
-
[60]
cell_id":
Polo, F.M., Choshen, L., Sun, W., Xu, H., Alvarez-Melis, D. (2024). tinyBenchmarks: Evaluating LLMs with fewer examples.ICML. A Benchmark composition and release schema (A) Registered design space and executed release tiers 60 systems × 8 task families × 6 evaluator families × 4 paired seeds × 5 interventions = 576,000 registered cells registered: 576k ce...
2024
-
[61]
Justification: The work does not involve human-subject experiments or collection of per- sonal data from participants
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.