Recognition: 2 theorem links
· Lean TheoremCommunication-free Sampling and 4D Hybrid Parallelism for Scalable Mini-batch GNN Training
Pith reviewed 2026-05-13 20:34 UTC · model grok-4.3
The pith
Uniform vertex sampling without any inter-process communication, combined with 3D parallel matrix multiplication, enables mini-batch GNN training to scale to thousands of GPUs while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ScaleGNN demonstrates that a uniform vertex sampling procedure allows every process to construct statistically usable mini-batch subgraphs with zero inter-process communication, and that this sampling can be combined with 3D parallel matrix multiplication plus data parallelism to train GNNs on graphs at scales up to 2048 GPUs while matching the convergence behavior of communication-heavy baselines.
What carries the argument
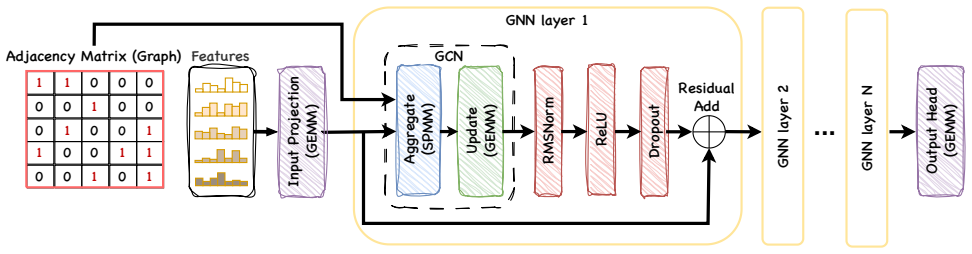
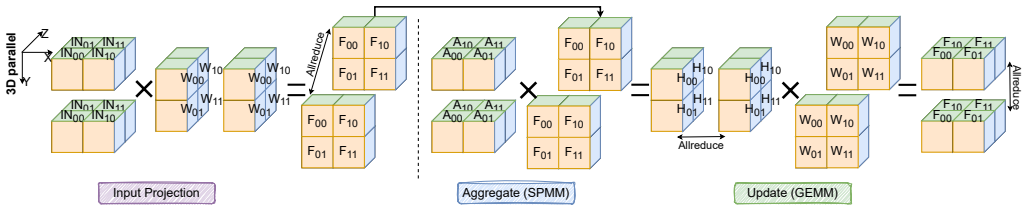
The uniform vertex sampling algorithm that builds each process's mini-batch subgraph locally without communication, together with 3D parallel matrix multiplication that reduces training-phase data movement.
If this is right
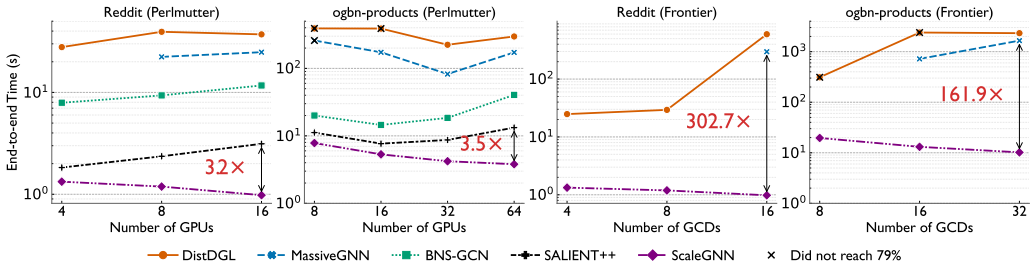
- Mini-batch GNN training scales strongly to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne.
- End-to-end training time on ogbn-products improves by 3.5 times over the prior state-of-the-art baseline.
- Sampling can be overlapped with computation and data can be sent in reduced precision to hide communication cost.
- Kernel fusion and communication-computation overlap further reduce per-iteration overhead.
- The same framework applies across five different graph datasets without custom per-dataset tuning.
Where Pith is reading between the lines
- The same communication-free sampling idea could be tested on message-passing models that are not strictly GNNs, provided their neighborhood aggregation can tolerate independent sampling.
- Lower interconnect bandwidth requirements may allow comparable scaling on cloud clusters that lack high-speed fabrics.
- If the statistical equivalence holds only approximately, the method could still be useful for very large graphs where exact sampling is prohibitively expensive.
- The 4D decomposition suggests a natural path to combine the approach with model parallelism for graphs too large to fit even one mini-batch on a single device.
Load-bearing premise
The uniform vertex sampling must generate mini-batch subgraphs whose statistical properties match those produced by communicating samplers closely enough to keep training accuracy and convergence unchanged.
What would settle it
A side-by-side run on ogbn-products or a similar large graph where the ScaleGNN-trained model reaches materially lower validation accuracy or requires substantially more epochs to converge than the identical model trained with a standard communicating sampler.
Figures





read the original abstract
Graph neural networks (GNNs) are widely used for learning on graph datasets derived from various real-world scenarios. Learning from extremely large graphs requires distributed training, and mini-batching with sampling is a popular approach for parallelizing GNN training. Existing distributed mini-batch approaches have significant performance bottlenecks due to expensive sampling methods and limited scaling when using data parallelism. In this work, we present ScaleGNN, a 4D parallel framework for scalable mini-batch GNN training that combines communication-free distributed sampling, 3D parallel matrix multiplication (PMM), and data parallelism. ScaleGNN introduces a uniform vertex sampling algorithm, enabling each process (GPU device) to construct its local mini-batch, i.e., subgraph partitions without any inter-process communication. 3D PMM enables scaling mini-batch training to much larger GPU counts than vanilla data parallelism with significantly lower communication overheads. We also present additional optimizations to overlap sampling with training, reduce communication overhead by sending data in lower precision, kernel fusion, and communication-computation overlap. We evaluate ScaleGNN on five graph datasets and demonstrate strong scaling up to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne. On Perlmutter, ScaleGNN achieves 3.5x end-to-end training speedup over the SOTA baseline on ogbn-products.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScaleGNN, a 4D hybrid parallelism framework for mini-batch GNN training that combines communication-free uniform vertex sampling (allowing each GPU to build local subgraphs independently), 3D parallel matrix multiplication, and data parallelism, together with optimizations such as sampling-training overlap and low-precision communication. It reports strong scaling to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne, plus a 3.5x end-to-end training speedup over the SOTA baseline on ogbn-products.
Significance. If the uniform sampling produces mini-batches whose neighborhood statistics and convergence behavior remain statistically equivalent to communicating samplers, the work would meaningfully advance scalable GNN training by removing a major communication bottleneck and enabling higher GPU counts with lower overhead.
major comments (2)
- [Abstract] Abstract: the 3.5x end-to-end speedup on ogbn-products is stated without any accompanying test accuracy, validation loss, or convergence comparison to the baseline; because the central claim rests on the sampling preserving model quality, the absence of these metrics leaves the performance result unverifiable.
- [§3] §3 (uniform vertex sampling): the algorithm is presented as producing statistically equivalent mini-batch subgraphs without inter-process communication, yet no formal argument, sampling-probability derivation, or empirical distribution comparison (e.g., degree histograms or multi-hop coverage on power-law graphs) is supplied to support equivalence to standard fan-out samplers.
minor comments (2)
- The abstract states results on five datasets but reports concrete numbers only for ogbn-products; a summary table across all datasets would improve clarity.
- [Evaluation] Scaling plots lack error bars or run counts, and exact sampling parameters (batch size, fan-out, number of hops) are not listed, limiting reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 3.5x end-to-end speedup on ogbn-products is stated without any accompanying test accuracy, validation loss, or convergence comparison to the baseline; because the central claim rests on the sampling preserving model quality, the absence of these metrics leaves the performance result unverifiable.
Authors: We agree that the abstract should explicitly reference model quality metrics to make the speedup claim verifiable. The full manuscript (Section 5.2, Figure 4, and Table 2) reports that ScaleGNN achieves test accuracy and validation loss values statistically indistinguishable from the baseline (within experimental variance) with matching convergence behavior on ogbn-products. We will revise the abstract to include a concise statement of these accuracy and convergence results. revision: yes
-
Referee: [§3] §3 (uniform vertex sampling): the algorithm is presented as producing statistically equivalent mini-batch subgraphs without inter-process communication, yet no formal argument, sampling-probability derivation, or empirical distribution comparison (e.g., degree histograms or multi-hop coverage on power-law graphs) is supplied to support equivalence to standard fan-out samplers.
Authors: We acknowledge the value of a formal argument. Uniform vertex sampling selects a fixed number of vertices uniformly at random from the global vertex set independently on each GPU; because the selection probability is identical for every vertex and independent of local degree, the expected neighborhood coverage in the induced subgraph converges to that of a global fan-out sampler as the graph size grows (by the law of large numbers). We did not include the derivation or empirical histograms in the original submission. We will add an appendix containing the sampling-probability derivation together with degree-distribution and multi-hop coverage histograms comparing our sampler to standard fan-out sampling on ogbn-products and other power-law graphs. revision: yes
Circularity Check
No significant circularity in empirical scaling and sampling claims
full rationale
The paper presents an engineering framework whose central results are measured end-to-end speedups and scaling curves on external graph datasets (ogbn-products, etc.) against published SOTA baselines. The uniform vertex sampling algorithm is introduced as a concrete implementation whose statistical equivalence to communicating samplers is asserted only via experimental accuracy preservation, not by any equation that defines the output in terms of itself or by a self-citation chain that supplies the missing proof. No fitted parameters are relabeled as predictions, no uniqueness theorem is imported from prior author work, and no ansatz is smuggled through citation. The derivation chain is therefore self-contained empirical comparison rather than a closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uniform vertex sampling produces statistically equivalent mini-batches to communicating samplers for GNN training
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
uniform vertex sampling algorithm, enabling each process to construct its local mini-batch subgraph partitions without any inter-process communication... rescaled adjacency Ãuv = avu/p ... p = (B-1)/(N-1)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
3D PMM ... Gx × Gy × Gz ... layer rotation ... cyclic reassignment with period three
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The graph neural network model,
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfar- dini, “The graph neural network model,”IEEE transactions on neural networks, vol. 20, no. 1, pp. 61–80, 2008
work page 2008
-
[2]
A survey of graph neural networks for recommender systems: Challenges, methods, and directions,
C. Gao, Y . Zheng, N. Li, Y . Li, Y . Qin, J. Piao, Y . Quan, J. Chang, D. Jin, X. Heet al., “A survey of graph neural networks for recommender systems: Challenges, methods, and directions,”ACM Transactions on Recommender Systems, vol. 1, no. 1, pp. 1–51, 2023
work page 2023
-
[3]
Graph neural networks for social recommendation,
W. Fan, Y . Ma, Q. Li, Y . He, E. Zhao, J. Tang, and D. Yin, “Graph neural networks for social recommendation,” inThe world wide web conference, 2019, pp. 417–426
work page 2019
-
[4]
Weidele, Claudio Bellei, Tom Robinson, and Charles E
M. Weber, G. Domeniconi, J. Chen, D. K. I. Weidele, C. Bellei, T. Robinson, and C. E. Leiserson, “Anti-money laundering in bitcoin: Experimenting with graph convolutional networks for financial foren- sics,”arXiv preprint arXiv:1908.02591, 2019
-
[5]
G. Corso, H. Stark, S. Jegelka, T. Jaakkola, and R. Barzilay, “Graph neural networks,”Nature Reviews Methods Primers, vol. 4, no. 1, p. 17, 2024
work page 2024
-
[6]
A gentle introduction to graph neural networks,
B. Sanchez-Lengeling, E. Reif, A. Pearce, and A. B. Wiltschko, “A gentle introduction to graph neural networks,”Distill, 2021, https://distill.pub/2021/gnn-intro
work page 2021
-
[7]
Semi-Supervised Classification with Graph Convolutional Networks
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,”CoRR, vol. abs/1609.02907, 2016. [Online]. Available: http://arxiv.org/abs/1609.02907
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Inductive Representation Learning on Large Graphs
W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” 2018. [Online]. Available: https://arxiv.org/ abs/1706.02216
work page Pith review arXiv 2018
-
[9]
Fastgcn: Fast learning with graph convolutional networks via importance sampling,
J. Chen, T. Ma, and C. Xiao, “Fastgcn: Fast learning with graph convolutional networks via importance sampling,” 2018. [Online]. Available: https://arxiv.org/abs/1801.10247
-
[10]
Layer-dependent importance sampling for training deep and large graph convolutional networks,
D. Zou, Z. Hu, Y . Wang, S. Jiang, Y . Sun, and Q. Gu, “Layer-dependent importance sampling for training deep and large graph convolutional networks,” 2019. [Online]. Available: https://arxiv.org/abs/1911.07323
-
[11]
Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks,
W.-L. Chiang, X. Liu, S. Si, Y . Li, S. Bengio, and C.-J. Hsieh, “Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. ACM, Jul. 2019. [Online]. Available: http://dx.doi.org/10.1145/3292500.3330925
- [12]
-
[13]
Graph neural network training systems: A performance comparison of full-graph and mini-batch,
S. Bajaj, H. Son, J. Liu, H. Guan, and M. Serafini, “Graph neural network training systems: A performance comparison of full-graph and mini-batch,”Proceedings of the VLDB Endowment, vol. 18, no. 4, pp. 1196–1209, 2024
work page 2024
-
[14]
Reducing communication in graph neural network training,
A. Tripathy, K. Yelick, and A. Buluc ¸, “Reducing communication in graph neural network training,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’20. IEEE Press, 2020
work page 2020
-
[15]
Sparsity-aware communication for distributed graph neural network training,
U. Mukhopadhyay, A. Tripathy, O. Selvitopi, K. Yelick, and A. Buluc, “Sparsity-aware communication for distributed graph neural network training,” inProceedings of the 53rd International Conference on Parallel Processing, ser. ICPP ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 117–126. [Online]. Available: https://doi.org/10.1145/...
-
[16]
Plexus: Taming billion-edge graphs with 3D parallel full-graph GNN training,
A. K. Ranjan, S. Singh, C. Wei, and A. Bhatele, “Plexus: Taming billion-edge graphs with 3D parallel full-graph GNN training,” in Proceedings of the ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. ACM, Nov. 2025. [Online]. Available: https://doi.acm.org/10. 1145/3712285.3759890
-
[17]
Distdgl: Distributed graph neural network training for billion-scale graphs,
D. Zheng, C. Ma, M. Wang, J. Zhou, Q. Su, X. Song, Q. Gan, Z. Zhang, and G. Karypis, “Distdgl: Distributed graph neural network training for billion-scale graphs,” in2020 IEEE/ACM 10th Workshop on Irregular Applications: Architectures and Algorithms (IA3). IEEE, 2020, pp. 36–44
work page 2020
-
[18]
T. Kaler, A. Iliopoulos, P. Murzynowski, T. Schardl, C. E. Leiserson, and J. Chen, “Communication-efficient graph neural networks with proba- bilistic neighborhood expansion analysis and caching,”Proceedings of Machine Learning and Systems, vol. 5, pp. 477–494, 2023
work page 2023
-
[19]
Massivegnn: Efficient training via prefetching for massively connected distributed graphs,
A. Sarkar, S. Ghosh, N. R. Tallent, and A. Jannesari, “Massivegnn: Efficient training via prefetching for massively connected distributed graphs,” in2024 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 2024, pp. 62–73
work page 2024
-
[20]
Distributed matrix-based sam- pling for graph neural network training,
A. Tripathy, K. Yelick, and A. Buluc ¸, “Distributed matrix-based sam- pling for graph neural network training,”Proceedings of Machine Learning and Systems, vol. 6, pp. 253–265, 2024
work page 2024
-
[21]
A three-dimensional approach to parallel matrix multiplication,
R. C. Agarwal, S. M. Balle, F. G. Gustavson, M. Joshi, and P. Palkar, “A three-dimensional approach to parallel matrix multiplication,”IBM Journal of Research and Development, vol. 39, no. 5, pp. 575–582, 1995
work page 1995
-
[22]
Democratizing AI: Open-source scalable LLM training on GPU-based supercomputers,
S. Singh, P. Singhania, A. Ranjan, J. Kirchenbauer, J. Geiping, Y . Wen, N. Jain, A. Hans, M. Shu, A. Tomar, T. Goldstein, and A. Bhatele, “Democratizing AI: Open-source scalable LLM training on GPU-based supercomputers,” inProceedings of the ACM/IEEE International Con- ference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’24,...
work page 2024
-
[23]
AxoNN: An asynchronous, message-driven parallel framework for extreme-scale deep learning,
S. Singh and A. Bhatele, “AxoNN: An asynchronous, message-driven parallel framework for extreme-scale deep learning,” inProceedings of the IEEE International Parallel & Distributed Processing Symposium, ser. IPDPS ’22. IEEE Computer Society, May 2022
work page 2022
-
[24]
Colossal-AI: a unified deep learning system for large-scale parallel training,
S. Li, H. Liu, Z. Bian, J. Fang, H. Huang, Y . Liu, B. Wang, and Y . You, “Colossal-AI: a unified deep learning system for large-scale parallel training,” inProceedings of the 52nd International Conference on Parallel Processing, ser. ICPP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 766–775
work page 2023
-
[25]
Oslo: Open source for large-scale optimization,
“Oslo: Open source for large-scale optimization,” https://github.com/ EleutherAI/oslo, 2021
work page 2021
-
[26]
Acceleration algorithms in gnns: A survey,
L. Ma, Z. Sheng, X. Li, X. Gao, Z. Hao, L. Yang, X. Nie, J. Jiang, W. Zhang, and B. Cui, “Acceleration algorithms in gnns: A survey,” IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[27]
Classic gnns are strong baselines: Re- assessing gnns for node classification,
Y . Luo, L. Shi, and X.-M. Wu, “Classic gnns are strong baselines: Re- assessing gnns for node classification,”Advances in Neural Information Processing Systems, vol. 37, pp. 97 650–97 669, 2024
work page 2024
-
[28]
A comprehensive survey on graph neural networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A comprehensive survey on graph neural networks,”IEEE transactions on neural networks and learning systems, vol. 32, no. 1, pp. 4–24, 2020
work page 2020
-
[29]
Sur- vey on graph neural network acceleration: An algorithmic perspective,
X. Liu, M. Yan, L. Deng, G. Li, X. Ye, D. Fan, S. Pan, and Y . Xie, “Sur- vey on graph neural network acceleration: An algorithmic perspective,” arXiv preprint arXiv:2202.04822, 2022
-
[30]
Learning steady- states of iterative algorithms over graphs,
H. Dai, Z. Kozareva, B. Dai, A. Smola, and L. Song, “Learning steady- states of iterative algorithms over graphs,” inInternational conference on machine learning. PMLR, 2018, pp. 1106–1114
work page 2018
-
[31]
Layer-dependent importance sampling for training deep and large graph convolutional networks,
D. Zou, Z. Hu, Y . Wang, S. Jiang, Y . Sun, and Q. Gu, “Layer-dependent importance sampling for training deep and large graph convolutional networks,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[32]
Adaptive sampling towards fast graph representation learning,
W. Huang, T. Zhang, Y . Rong, and J. Huang, “Adaptive sampling towards fast graph representation learning,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[33]
Accurate, efficient and scalable graph embedding,
H. Zeng, H. Zhou, A. Srivastava, R. Kannan, and V . Prasanna, “Accurate, efficient and scalable graph embedding,” in2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2019, pp. 462–471
work page 2019
-
[34]
Ripple walk training: A subgraph-based training framework for large and deep graph neural network,
J. Bai, Y . Ren, and J. Zhang, “Ripple walk training: A subgraph-based training framework for large and deep graph neural network,” in2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021, pp. 1–8
work page 2021
-
[35]
Parallel and distributed graph neural networks: An in-depth concurrency analysis,
M. Besta and T. Hoefler, “Parallel and distributed graph neural networks: An in-depth concurrency analysis,”IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, vol. 46, no. 5, pp. 2584–2606, 2024
work page 2024
-
[36]
Distributed graph neural network training: A survey,
Y . Shao, H. Li, X. Gu, H. Yin, Y . Li, X. Miao, W. Zhang, B. Cui, and L. Chen, “Distributed graph neural network training: A survey,”ACM Computing Surveys, vol. 56, no. 8, pp. 1–39, 2024
work page 2024
-
[37]
A comprehensive survey on distributed training of graph neural networks,
H. Lin, M. Yan, X. Ye, D. Fan, S. Pan, W. Chen, and Y . Xie, “A comprehensive survey on distributed training of graph neural networks,” Proceedings of the IEEE, vol. 111, no. 12, pp. 1572–1606, 2023
work page 2023
-
[38]
C. Wan, Y . Li, C. R. Wolfe, A. Kyrillidis, N. S. Kim, and Y . Lin, “Pipegcn: Efficient full-graph training of graph convolutional networks with pipelined feature communication,” 2022. [Online]. Available: https://arxiv.org/abs/2203.10428
-
[39]
{NeuGraph}: Parallel deep neural network computation on large graphs,
L. Ma, Z. Yang, Y . Miao, J. Xue, M. Wu, L. Zhou, and Y . Dai, “{NeuGraph}: Parallel deep neural network computation on large graphs,” in2019 USENIX Annual Technical Conference (USENIX ATC 19), 2019, pp. 443–458
work page 2019
-
[40]
Improving the accuracy, scalability, and performance of graph neural networks with roc,
Z. Jia, S. Lin, M. Gao, M. Zaharia, and A. Aiken, “Improving the accuracy, scalability, and performance of graph neural networks with roc,”Proceedings of Machine Learning and Systems, vol. 2, pp. 187– 198, 2020
work page 2020
-
[41]
C. Wan, Y . Li, A. Li, N. S. Kim, and Y . Lin, “Bns-gcn: Efficient full-graph training of graph convolutional networks with partition- parallelism and random boundary node sampling,” 2022. [Online]. Available: https://arxiv.org/abs/2203.10983
-
[42]
Gnnpipe: Scaling deep gnn training with pipelined model parallelism,
J. Chen, Z. Chen, and X. Qian, “Gnnpipe: Scaling deep gnn training with pipelined model parallelism,”arXiv preprint arXiv:2308.10087, 2023
-
[43]
Mithril: A scalable system for deep gnn training,
——, “Mithril: A scalable system for deep gnn training,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1052–1065
work page 2025
-
[44]
Deep graph library: A graph-centric, highly-performant package for graph neural networks,
M. Wang, D. Zheng, Z. Ye, Q. Gan, M. Li, X. Song, J. Zhou, C. Ma, L. Yu, Y . Gai, T. Xiao, T. He, G. Karypis, J. Li, and Z. Zhang, “Deep graph library: A graph-centric, highly-performant package for graph neural networks,” 2020. [Online]. Available: https://arxiv.org/abs/1909.01315
-
[45]
{BGL}:{GPU-Efficient}{GNN}training by optimizing graph data{I/O}and preprocessing,
T. Liu, Y . Chen, D. Li, C. Wu, Y . Zhu, J. He, Y . Peng, H. Chen, H. Chen, and C. Guo, “{BGL}:{GPU-Efficient}{GNN}training by optimizing graph data{I/O}and preprocessing,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 2023, pp. 103–118
work page 2023
-
[46]
Fastgl: A gpu-efficient framework for accelerating sampling-based gnn training at large scale,
Z. Zhu, P. Wang, Q. Hu, G. Li, X. Liang, and J. Cheng, “Fastgl: A gpu-efficient framework for accelerating sampling-based gnn training at large scale,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 4, 2024, pp. 94–110
work page 2024
-
[47]
Gsplit: Scaling graph neural network training on large graphs via split-parallelism,
S. Polisetty, J. Liu, K. Falus, Y . R. Fung, S.-H. Lim, H. Guan, and M. Serafini, “Gsplit: Scaling graph neural network training on large graphs via split-parallelism,”arXiv preprint arXiv:2303.13775, 2023
-
[48]
Root mean square layer normalization,
B. Zhang and R. Sennrich, “Root mean square layer normalization,” Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[49]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” 2016. [Online]. Available: https://arxiv.org/abs/1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Empirical evaluation of rectified activations in convolutional network,
B. Xu, N. Wang, T. Chen, and M. Li, “Empirical evaluation of rectified activations in convolutional network,” 2015
work page 2015
-
[51]
Improving neural networks with dropout,
N. Srivastava, “Improving neural networks with dropout,”University of Toronto, vol. 182, no. 566, p. 7, 2013
work page 2013
-
[52]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[53]
Deeper insights into graph convolu- tional networks for semi-supervised learning,
Q. Li, Z. Han, and X.-M. Wu, “Deeper insights into graph convolu- tional networks for semi-supervised learning,” inProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, ser. AAAI’18...
work page 2018
-
[54]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu, “Mixed precision training,” inInternational Conference on Learning Representations, 2018. [Online]. Available: https: //openreview.net/forum?id=r1gs9JgRZ
work page 2018
-
[55]
A Study of BFLOAT16 for Deep Learning Training
D. Kalamkar, D. Mudigere, N. Mellempudi, D. Das, K. Banerjee, S. Avancha, D. T. V ooturi, N. Jammalamadaka, J. Huang, H. Yuen et al., “A study of bfloat16 for deep learning training,”arXiv preprint arXiv:1905.12322, 2019
work page Pith review arXiv 1905
-
[56]
Optimization of gnn training through half-precision,
A. K. Tarafder, Y . Gong, and P. Kumar, “Optimization of gnn training through half-precision,” inProceedings of the 34th International Sympo- sium on High-Performance Parallel and Distributed Computing, 2025, pp. 1–13
work page 2025
-
[57]
Open graph benchmark: Datasets for machine learning on graphs,
W. Hu, M. Fey, M. Zitnik, Y . Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,” 2021. [Online]. Available: https://arxiv.org/abs/2005.00687
-
[58]
A. Azad, G. A. Pavlopoulos, C. A. Ouzounis, N. C. Kyrpides, and A. Buluc ¸, “Hipmcl: a high-performance parallel implementation of the markov clustering algorithm for large-scale networks,”Nucleic Acids Research, vol. 46, no. 6, pp. e33–e33, 01 2018. [Online]. Available: https://doi.org/10.1093/nar/gkx1313
-
[59]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects,
J. Ni, J. Li, and J. McAuley, “Justifying recommendations using distantly-labeled reviews and fine-grained aspects,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), K. Inui, J. Jiang, V . Ng, and X. Wan, Eds. Hong Kong, China:...
work page 2019
-
[60]
The big send-off: High per- formance collectives on gpu-based supercomputers,
S. Singh, M. Singh, and A. Bhatele, “The big send-off: High per- formance collectives on gpu-based supercomputers,”arXiv preprint arXiv:2504.18658, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.