Recognition: 2 theorem links
· Lean TheoremMOMO: Mars Orbital Model Foundation Model for Mars Orbital Applications
Pith reviewed 2026-05-13 20:44 UTC · model grok-4.3
The pith
Merging checkpoints from three Mars sensors aligned by equal validation loss creates a multi-sensor foundation model that outperforms standard pretraining baselines on downstream tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MOMO is constructed by independently pretraining models on large corpora from each of the three Martian sensors and then fusing them at checkpoints chosen to have equal validation loss values using task arithmetic, yielding a single model with superior generalization on Mars remote sensing benchmarks compared to non-merged alternatives.
What carries the argument
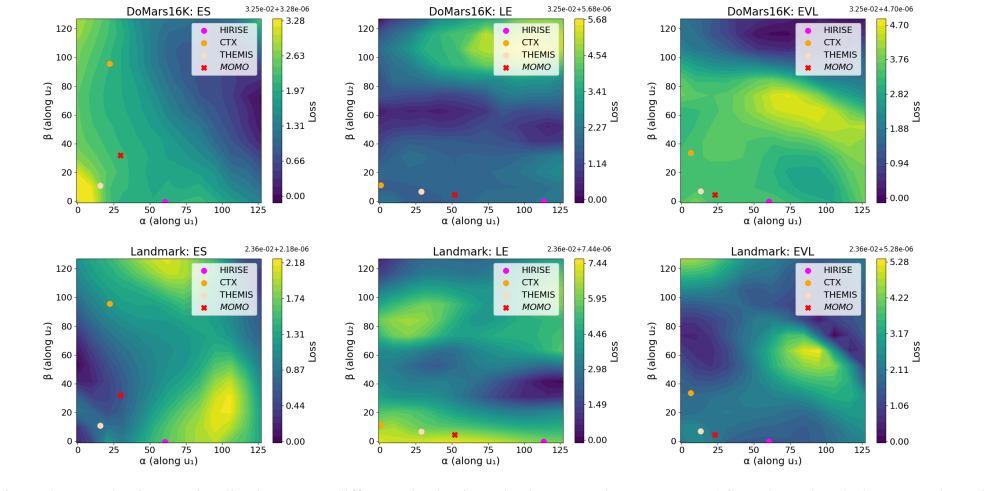
The Equal Validation Loss (EVL) strategy for aligning independently trained sensor models at similar convergence points before applying task arithmetic to merge their representations.
If this is right
- Consistent performance improvements on segmentation tasks across the Mars-Bench suite.
- Stable fusion of multi-resolution data without requiring simultaneous training on all sensors.
- Outperformance over ImageNet, earth observation, and sensor-specific baselines in overall metrics.
- Better generalization when merging models trained on data from 0.25 m/pixel to 100 m/pixel resolutions.
Where Pith is reading between the lines
- The EVL approach may extend to fusing models from other planetary or Earth remote sensing datasets with varying resolutions.
- Task arithmetic could be combined with other merging techniques for even broader multi-sensor integration.
- Releasing the model weights and code allows direct testing on new Mars tasks not in the original benchmark.
Load-bearing premise
That matching validation loss values across separately trained models from different sensors produces representations compatible enough for stable and beneficial fusion via task arithmetic.
What would settle it
Training and merging the sensor models at checkpoints with deliberately mismatched validation losses and observing whether the performance on Mars-Bench tasks drops below or matches the EVL-aligned version.
Figures



















read the original abstract
We introduce MOMO, the first multi-sensor foundation model for Mars remote sensing. MOMO uses model merge to integrate representations learned independently from three key Martian sensors (HiRISE, CTX, and THEMIS), spanning resolutions from 0.25 m/pixel to 100 m/pixel. Central to our method is our novel Equal Validation Loss (EVL) strategy, which aligns checkpoints across sensors based on validation loss similarity before fusion via task arithmetic. This ensures models are merged at compatible convergence stages, leading to improved stability and generalization. We train MOMO on a large-scale, high-quality corpus of $\sim 12$ million samples curated from Mars orbital data and evaluate it on 9 downstream tasks from Mars-Bench. MOMO achieves better overall performance compared to ImageNet pre-trained, earth observation foundation model, sensor-specific pre-training, and fully-supervised baselines. Particularly on segmentation tasks, MOMO shows consistent and significant performance improvement. Our results demonstrate that model merging through an optimal checkpoint selection strategy provides an effective approach for building foundation models for multi-resolution data. The model weights, pretraining code, pretraining data, and evaluation code are available at: https://github.com/kerner-lab/MOMO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MOMO, the first multi-sensor foundation model for Mars remote sensing. Separate models are pretrained on HiRISE, CTX, and THEMIS imagery (resolutions 0.25–100 m/pix) using a ~12M-sample corpus; checkpoints are aligned via the proposed Equal Validation Loss (EVL) heuristic and fused by task arithmetic. The merged model is evaluated on 9 downstream tasks from Mars-Bench and is reported to outperform ImageNet-pretrained, Earth-observation, sensor-specific, and fully-supervised baselines, with the largest gains on segmentation.
Significance. If the empirical gains prove robust and the EVL alignment mechanism is shown to be more than a generic checkpoint-selection heuristic, the work would offer a practical route to multi-resolution foundation models for planetary remote sensing without requiring joint multi-sensor training. Public release of weights, pretraining code, data, and evaluation scripts strengthens reproducibility.
major comments (2)
- [§3.2] §3.2 (EVL checkpoint selection): Matching raw validation-loss scalars across sensors is asserted to place models at 'compatible convergence stages,' yet HiRISE (0.25 m/pix), CTX, and THEMIS (up to 100 m/pix) differ in input statistics, label distributions, and loss landscapes. No normalization of losses, CKA/representation-similarity analysis, or ablation against alternative selection heuristics is provided to show that the observed segmentation gains are attributable to the claimed mechanism rather than any reasonable checkpoint choice.
- [§4] §4 (experimental results): The abstract and summary claim 'better overall performance' and 'consistent and significant' gains on segmentation, but no numerical deltas, standard deviations, error bars, or statistical tests are referenced. Full tables must report exact metrics for all baselines (including how they were implemented and tuned) so that the central empirical claim can be verified.
minor comments (2)
- [§3.1] Notation for the task-arithmetic merge coefficients and the precise EVL loss-matching tolerance should be defined explicitly in §3.1.
- [Figures] Figure captions for the Mars-Bench task visualizations should state the exact resolution and sensor of each input example.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the manuscript to incorporate additional analysis and reporting details where needed.
read point-by-point responses
-
Referee: [§3.2] §3.2 (EVL checkpoint selection): Matching raw validation-loss scalars across sensors is asserted to place models at 'compatible convergence stages,' yet HiRISE (0.25 m/pix), CTX, and THEMIS (up to 100 m/pix) differ in input statistics, label distributions, and loss landscapes. No normalization of losses, CKA/representation-similarity analysis, or ablation against alternative selection heuristics is provided to show that the observed segmentation gains are attributable to the claimed mechanism rather than any reasonable checkpoint choice.
Authors: We agree that the EVL heuristic, as originally presented, relies on direct comparison of raw validation-loss values without cross-sensor normalization or similarity metrics, and that the manuscript lacks explicit ablations against other checkpoint-selection strategies. In the revised version we add a dedicated subsection in §3.2 that (i) normalizes each sensor’s validation loss by its value at the first checkpoint, (ii) reports CKA similarity between the selected checkpoints across sensors, and (iii) includes an ablation table comparing EVL against fixed-epoch selection and loss-threshold selection. The new results show that EVL-selected merges consistently outperform the alternatives on the segmentation tasks, providing empirical support for the mechanism beyond a generic checkpoint choice. revision: yes
-
Referee: [§4] §4 (experimental results): The abstract and summary claim 'better overall performance' and 'consistent and significant' gains on segmentation, but no numerical deltas, standard deviations, error bars, or statistical tests are referenced. Full tables must report exact metrics for all baselines (including how they were implemented and tuned) so that the central empirical claim can be verified.
Authors: We acknowledge that the original abstract and §4 summary statements were qualitative and that the main tables did not include standard deviations or statistical tests. The revised manuscript updates the abstract to report explicit average deltas (e.g., +3.2 mIoU on segmentation), augments all tables in §4 with mean ± std across three random seeds, adds error bars to the corresponding figures, and includes a new paragraph detailing baseline implementation details and hyper-parameter search ranges. Paired t-tests with p-values are now reported for the key segmentation comparisons to substantiate the claim of significant gains. revision: yes
Circularity Check
No significant circularity; empirical method with no self-referential derivations
full rationale
The MOMO paper introduces an empirical pipeline: independent sensor-specific pretraining followed by Equal Validation Loss (EVL) checkpoint alignment and task-arithmetic fusion. No equations, fitted parameters, or uniqueness theorems are presented that reduce by construction to the authors' own inputs or prior self-citations. Performance claims on Mars-Bench segmentation and other tasks rest on direct training/evaluation comparisons against baselines, not on any quantity defined in terms of the EVL scalars themselves. The EVL heuristic is a proposed selection rule whose validity is tested experimentally rather than assumed tautologically. No load-bearing self-citation chains or ansatz smuggling appear in the described method.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith.Foundation.RealityFromDistinctionreality_from_one_distinction unclearCentral to our method is our novel Equal Validation Loss (EVL) strategy, which aligns checkpoints across sensors based on validation loss similarity before fusion via task arithmetic.
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclearwe introduce additional perceptual and structure-aware components in our loss function... Ltotal = λ1 LMSE + λ2 LSSIM + λ3 LLPIPS + λ4 Lgrad
Reference graph
Works this paper leans on
-
[1]
Git re-basin: Merging models modulo permutation symmetries
Samuel Ainsworth, Jonathan Hayase, and Siddhartha Srini- vasa. Git re-basin: Merging models modulo permutation symmetries. InThe Eleventh International Conference on Learning Representations, 2023. 8
work page 2023
-
[2]
Git re-basin: Merging models modulo permuta- tion symmetries.arXiv preprint arXiv:2209.04836, 2022
Samuel K Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permuta- tion symmetries.arXiv preprint arXiv:2209.04836, 2022. 8
-
[3]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Guillaume Astruc, Nicolas Gonthier, Clement Mallet, and Loic Landrieu. AnySat: An earth observation model for any resolutions, scales, and modalities.arXiv preprint arXiv:2412.14123, 2024. 1, 2
-
[5]
Satlaspretrain: A large- scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdi- nando, and Aniruddha Kembhavi. Satlaspretrain: A large- scale dataset for remote sensing image understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16772–16782, 2023. 2, 3
work page 2023
-
[6]
Eric Bauer and Ron Kohavi. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants.Machine learning, 36:105–139, 1999. 2
work page 1999
-
[7]
JF Bell III, MC Malin, MA Caplinger, J Fahle, MJ Wolff, BA Cantor, PB James, T Ghaemi, LV Posiolova, MA Ravine, et al. Calibration and performance of the mars reconnais- sance orbiter context camera (ctx).International Journal of Mars Science and Exploration, 8:1–14, 2013. 4
work page 2013
-
[8]
Spec- tralEarth: Training hyperspectral foundation models at scale
Nassim Ait Ali Braham, Conrad M Albrecht, Julien Mairal, Jocelyn Chanussot, Yi Wang, and Xiao Xiang Zhu. Spec- tralEarth: Training hyperspectral foundation models at scale. arXiv preprint arXiv:2408.08447, 2024. 2
-
[9]
Christina Butsko, Kristof Van Tricht, Gabriel Tseng, Gior- gia Milli, David Rolnick, Ruben Cartuyvels, Inbal Becker Reshef, Zoltan Szantoi, and Hannah Kerner. Deploying geospatial foundation models in the real world: Lessons from worldcereal.arXiv preprint arXiv:2508.00858, 2025. 1
-
[10]
The Bruce Murray Labora- tory for Planetary Visualization.http://murray-lab
California Institute of Technology - Division of Geologi- cal and Planetary Sciences. The Bruce Murray Labora- tory for Planetary Visualization.http://murray-lab. caltech.edu/CTX/. 13
-
[11]
Mars odyssey thermal emission imaging system in- frared reduced data record
PR Christensen, NS Gorelick, GL Mehall, and KC Mur- ray. Mars odyssey thermal emission imaging system in- frared reduced data record. Technical report, ODY-M-THM- 5-IRRDR-V1. 0.[Dataset]. NASA Planetary Data System. https://pds . . . , 2001. 13
work page 2001
-
[12]
Philip R Christensen, Bruce M Jakosky, Hugh H Kieffer, Michael C Malin, Harry Y McSween Jr, Kenneth Nealson, Greg L Mehall, Steven H Silverman, Steven Ferry, Michael Caplinger, et al. The thermal emission imaging system (themis) for the mars 2001 odyssey mission.Space Science Reviews, 110(1):85–130, 2004. 4, 13
work page 2001
-
[13]
P. R. Christensen, E. Engle, S. Anwar, S. Dickenshied, D. Noss, N. Gorelick, and M. Weiss-Malik. Jmars – a planetary gis.http://adsabs.harvard.edu/ abs / 2009AGUFMIN22A . .06C, 2009. NASA/JPL- Caltech/Arizona State University. 23
work page 2009
-
[14]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. SatMAE: Pre-training transformers for tem- poral and multi-spectral satellite imagery.Advances in Neu- ral Information Processing Systems, 35:197–211, 2022. 2, 3
work page 2022
-
[15]
JL Dickson, LA Kerber, CI Fassett, and BL Ehlmann. A global, blended ctx mosaic of mars with vectorized seam mapping: A new mosaicking pipeline using principles of non-destructive image editing. InLunar and planetary sci- ence conference, pages 1–2. Lunar and Planetary Institute The Woodlands, TX, USA, 2018. 13
work page 2018
-
[16]
JL Dickson, BL Ehlmann, LH Kerber, and CI Fassett. Re- lease of the global ctx mosaic of mars: An experiment in informationpreserving image data processing. In54th Lunar and Planetary Science Conference, pages 1–2, 2023. 3, 13
work page 2023
-
[17]
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization.arXiv preprint arXiv:2010.01412,
-
[18]
Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences, 55(1): 119–139, 1997. 2
work page 1997
-
[19]
Anthony Fuller, Koreen Millard, and James Green. CROMA: Remote sensing representations with contrastive radar- optical masked autoencoders.Advances in Neural Informa- tion Processing Systems, 36, 2024. 2
work page 2024
-
[20]
Task singular vectors: Reducing task in- terference in model merging
Antonio Andrea Gargiulo, Donato Crisostomi, Maria Sofia Bucarelli, Simone Scardapane, Fabrizio Silvestri, and Emanuele Rodola. Task singular vectors: Reducing task in- terference in model merging. InProceedings of the Com- puter Vision and Pattern Recognition Conference, pages 18695–18705, 2025. 8
work page 2025
-
[21]
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns.Advances in neural information processing systems, 31, 2018. 7
work page 2018
-
[22]
Karan Goel, Albert Gu, Yixuan Li, and Christopher R ´e. Model patching: Closing the subgroup performance gap with data augmentation.arXiv preprint arXiv:2008.06775, 2020. 2
-
[23]
Krzysztof M Gorski, Benjamin D Wandelt, Frode K Hansen, Eric Hivon, and Anthony J Banday. The healpix primer. arXiv preprint astro-ph/9905275, 1999. 5
work page internal anchor Pith review Pith/arXiv arXiv 1999
-
[24]
Stochastic weight aver- aging revisited.Applied Sciences, 13(5):2935, 2023
Hao Guo, Jiyong Jin, and Bin Liu. Stochastic weight aver- aging revisited.Applied Sciences, 13(5):2935, 2023. 2
work page 2023
-
[25]
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, Huimei He, Jian Wang, Jingdong Chen, Ming Yang, Yongjun Zhang, and Yansheng Li. Skysense: A multi- modal remote sensing foundation model towards universal interpretation for earth observation imagery. InProceedings of the IEEE/CVF Confere...
work page 2024
-
[26]
Bridging remote sensors with multisensor geospatial foundation models
Boran Han, Shuai Zhang, Xingjian Shi, and Markus Reich- stein. Bridging remote sensors with multisensor geospatial foundation models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 27852–27862, 2024. 1, 2
work page 2024
-
[27]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 3, 19
work page 2022
-
[28]
Danfeng Hong, Bing Zhang, Xuyang Li, Yuxuan Li, Chenyu Li, Jing Yao, Naoto Yokoya, Hao Li, Pedram Ghamisi, Xi- uping Jia, et al. SpectralGPT: Spectral remote sensing foun- dation model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2
work page 2024
-
[29]
Ziyue Huang, Hongxi Yan, Qiqi Zhan, Shuai Yang, Ming- ming Zhang, Chenkai Zhang, YiMing Lei, Zeming Liu, Qingjie Liu, and Yunhong Wang. A survey on remote sens- ing foundation models: From vision to multimodality.arXiv preprint arXiv:2503.22081, 2025. 1
-
[30]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089, 2022. 4, 19, 22
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Gabriel Ilharco, Mitchell Wortsman, Samir Yitzhak Gadre, Shuran Song, Hannaneh Hajishirzi, Simon Kornblith, Ali Farhadi, and Ludwig Schmidt. Patching open-vocabulary models by interpolating weights.Advances in Neural Infor- mation Processing Systems, 35:29262–29277, 2022. 2
work page 2022
-
[32]
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization.arXiv preprint arXiv:1803.05407, 2018. 2
-
[33]
Douglas M. Jennewein, Johnathan Lee, Chris Kurtz, William Dizon, Ian Shaeffer, Alan Chapman, Alejandro Chi- quete, Josh Burks, Amber Carlson, Natalie Mason, Arhat Kobawala, Thirugnanam Jagadeesan, Praful Bhargav Basani, Torey Battelle, Rebecca Belshe, Deb McCaffrey, Marisa Brazil, Chaitanya Inumella, Kirby Kuznia, Jade Buzinski, Dhruvil Deepakbhai Shah, S...
work page 2023
-
[34]
Shancheng Jiang, Fan Wu, Kai-Leung Yung, Yingqiao Yang, WH Ip, Ming Gao, and James Abbott Foster. A robust end- to-end deep learning framework for detecting martian land- forms with arbitrary orientations.Knowledge-Based Sys- tems, 234:107562, 2021. 2
work page 2021
-
[35]
Jean Kaddour. Stop wasting my time! saving days of ima- genet and bert training with latest weight averaging.arXiv preprint arXiv:2209.14981, 2022. 2
-
[36]
Hannah Rae Kerner, Kiri L Wagstaff, Brian D Bue, Patrick C Gray, James F Bell, and Heni Ben Amor. Toward general- ized change detection on planetary surfaces with convolu- tional autoencoders and transfer learning.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(10):3900–3918, 2019. 17
work page 2019
-
[37]
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, and Marc Rußwurm. SatCLIP: Global, general- purpose location embeddings with satellite imagery.arXiv preprint arXiv:2311.17179, 2023. 2
-
[38]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estima- tion using deep ensembles.Advances in neural information processing systems, 30, 2017. 2
work page 2017
-
[39]
Margaret Li, Suchin Gururangan, Tim Dettmers, Mike Lewis, Tim Althoff, Noah A Smith, and Luke Zettlemoyer. Branch-train-merge: Embarrassingly parallel training of ex- pert language models.arXiv preprint arXiv:2208.03306,
-
[40]
Trainable weight averaging: A general approach for subspace training
Tao Li, Zhehao Huang, Yingwen Wu, Zhengbao He, Qinghua Tao, Xiaolin Huang, and Chih-Jen Lin. Trainable weight averaging: A general approach for subspace training. arXiv preprint arXiv:2205.13104, 2022. 2
-
[41]
Noise estimation from a single image
Ce Liu, William T Freeman, Richard Szeliski, and Sing Bing Kang. Noise estimation from a single image. In2006 IEEE Computer Society Conference on Computer Vision and Pat- tern Recognition (CVPR’06), pages 901–908. IEEE, 2006. 5
work page 2006
-
[42]
Siqi Lu, Junlin Guo, James R Zimmer-Dauphinee, Jordan M Nieusma, Xiao Wang, Steven A Wernke, Yuankai Huo, et al. Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine, 2025. 1
work page 2025
-
[43]
Structure-preserving super resolution with gradient guidance
Cheng Ma, Yongming Rao, Yean Cheng, Ce Chen, Jiwen Lu, and Jie Zhou. Structure-preserving super resolution with gradient guidance. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 7769–7778, 2020. 3
work page 2020
-
[44]
Michael C Malin, James F Bell III, Bruce A Cantor, Michael A Caplinger, Wendy M Calvin, R Todd Clancy, Kenneth S Edgett, Lawrence Edwards, Robert M Haberle, Philip B James, et al. Context camera investigation on board the mars reconnaissance orbiter.Journal of Geophysical Re- search: Planets, 112(E5), 2007. 4, 13
work page 2007
-
[45]
Seasonal contrast: Un- supervised pre-training from uncurated remote sensing data
Oscar Manas, Alexandre Lacoste, Xavier Gir ´o-i Nieto, David Vazquez, and Pau Rodriguez. Seasonal contrast: Un- supervised pre-training from uncurated remote sensing data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9414–9423, 2021. 2
work page 2021
-
[46]
Alfred S McEwen, Eric M Eliason, James W Bergstrom, Nathan T Bridges, Candice J Hansen, W Alan Delamere, John A Grant, Virginia C Gulick, Kenneth E Herkenhoff, Laszlo Keszthelyi, et al. Mars reconnaissance orbiter’s high resolution imaging science experiment (hirise).Journal of Geophysical Research: Planets, 112(E5), 2007. 4
work page 2007
-
[47]
Alfred S McEwen, Shane Byrne, C Hansen, Ingrid J Daubar, Sarah Sutton, Colin M Dundas, Nicole Bardabelias, Nicole Baugh, J Bergstrom, R Beyer, et al. The high-resolution imaging science experiment (hirise) in the mro extended sci- ence phases (2009–2023).Icarus, 419:115795, 2024. 3, 13
work page 2009
-
[48]
Towards automatically- tuned neural networks
Hector Mendoza, Aaron Klein, Matthias Feurer, Jost Tobias Springenberg, and Frank Hutter. Towards automatically- tuned neural networks. InWorkshop on automatic machine learning, pages 58–65. PMLR, 2016. 2
work page 2016
-
[49]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. arXiv preprint arXiv:2110.11309, 2021. 2
-
[50]
Memory-based model editing at scale
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memory-based model editing at scale. InInternational Conference on Machine Learning, pages 15817–15831. PMLR, 2022. 2
work page 2022
-
[51]
Fixing model bugs with natural lan- guage patches.arXiv preprint arXiv:2211.03318, 2022
Shikhar Murty, Christopher D Manning, Scott Lundberg, and Marco Tulio Ribeiro. Fixing model bugs with natural lan- guage patches.arXiv preprint arXiv:2211.03318, 2022. 2
-
[52]
Understanding ssim.arXiv preprint arXiv:2006.13846, 2020
Jim Nilsson and Tomas Akenine-M ¨oller. Understanding ssim.arXiv preprint arXiv:2006.13846, 2020. 3, 5
-
[53]
Rethinking transformers pre-training for multi- spectral satellite imagery
Mubashir Noman, Muzammal Naseer, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Shah- baz Khan. Rethinking transformers pre-training for multi- spectral satellite imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27811–27819, 2024. 2
work page 2024
-
[54]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 2
work page 2022
-
[55]
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshmi- narayanan, and Jasper Snoek. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift.Advances in neural information processing systems, 32, 2019. 2
work page 2019
-
[56]
Elena Plekhanova, Damien Robert, Johannes Dollinger, Emilia Arens, Philipp Brun, Jan Dirk Wegner, and Niklaus E. Zimmermann. Ssl4eco: A global seasonal dataset for geospatial foundation models in ecology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 2428–2439, 2025. 13
work page 2025
-
[57]
Conequest: A benchmark for cone segmentation on mars
Mirali Purohit, Jacob Adler, and Hannah Kerner. Conequest: A benchmark for cone segmentation on mars. InProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6026–6035, 2024. 1
work page 2024
-
[58]
Investigating the benefits of foundation models for mars science.LPI Contributions, 3007:3535, 2024
MV Purohit, S Lu, S Diniega, UD Rebbapragada, and HR Kerner. Investigating the benefits of foundation models for mars science.LPI Contributions, 3007:3535, 2024. 1, 2
work page 2024
-
[59]
Mars-bench: A benchmark for evaluating foundation models for mars science tasks
Mirali Purohit, Bimal Gajera, Vatsal Malaviya, Irish Mehta, Kunal Sunil Kasodekar, Jacob Adler, Steven Lu, Umaa Reb- bapragada, and Hannah Kerner. Mars-bench: A benchmark for evaluating foundation models for mars science tasks. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. 1, 4, 6, 15
work page 2025
-
[60]
Mirali Purohit, Gedeon Muhawenayo, Esther Rolf, and Han- nah Kerner. How does the spatial distribution of pre-training data affect geospatial foundation models? InWorkshop on Preparing Good Data for Generative AI: Challenges and Ap- proaches, 2025. 13
work page 2025
-
[61]
Rethinking model re-basin and linear mode con- nectivity
Xingyu Qu. Rethinking model re-basin and linear mode con- nectivity. 2024. 8
work page 2024
-
[62]
Scale-MAE: A scale-aware masked autoencoder for multiscale geospatial representation learning
Colorado J Reed, Ritwik Gupta, Shufan Li, Sarah Brock- man, Christopher Funk, Brian Clipp, Kurt Keutzer, Salvatore Candido, Matt Uyttendaele, and Trevor Darrell. Scale-MAE: A scale-aware masked autoencoder for multiscale geospatial representation learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4088– 4099, 2023. 2
work page 2023
-
[63]
Position: Mission critical–satellite data is a distinct modality in machine learning
Esther Rolf, Konstantin Klemmer, Caleb Robinson, and Hannah Kerner. Position: Mission critical–satellite data is a distinct modality in machine learning. InForty-first Inter- national Conference on Machine Learning, 2024. 1
work page 2024
-
[64]
Application-driven innovation in machine learning.arXiv preprint arXiv:2403.17381, 2024
David Rolnick, Alan Aspuru-Guzik, Sara Beery, Bistra Dilk- ina, Priya L Donti, Marzyeh Ghassemi, Hannah Kerner, Claire Monteleoni, Esther Rolf, Milind Tambe, et al. Application-driven innovation in machine learning.arXiv preprint arXiv:2403.17381, 2024. 1
-
[65]
Shibani Santurkar, Dimitris Tsipras, Mahalaxmi Elango, David Bau, Antonio Torralba, and Aleksander Madry. Edit- ing a classifier by rewriting its prediction rules.Advances in Neural Information Processing Systems, 34:23359–23373,
-
[66]
Zipit! merging mod- els from different tasks without training.arXiv preprint arXiv:2305.03053, 2023
George Stoica, Daniel Bolya, Jakob Bjorner, Pratik Ramesh, Taylor Hearn, and Judy Hoffman. Zipit! merging mod- els from different tasks without training.arXiv preprint arXiv:2305.03053, 2023. 2, 3
-
[67]
Yi-Lin Sung, Varun Nair, and Colin A Raffel. Training neu- ral networks with fixed sparse masks.Advances in Neural Information Processing Systems, 34:24193–24205, 2021. 2
work page 2021
-
[68]
Going deeper with convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015. 2
work page 2015
-
[69]
Astrogeology Research Program (USGS), 2014
Kenneth L Tanaka, James A Skinner, James M Dohm, Ross- man P Irwin, Eric J Kolb, Corey M Fortezzo, Thomas Platz, Gregory G Michael, and Trent M Hare.Geologic map of Mars. Astrogeology Research Program (USGS), 2014. 4
work page 2014
-
[70]
Generalized linear mode connectivity for transformers
Alexander Theus, Alessandro Cabodi, Sotiris Anagnostidis, Antonio Orvieto, Sidak Pal Singh, and Valentina Boeva. Generalized linear mode connectivity for transformers. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 8
work page 2025
-
[71]
Gabriel Tseng, Ruben Cartuyvels, Ivan Zvonkov, Mirali Purohit, David Rolnick, and Hannah Kerner. Lightweight, pre-trained transformers for remote sensing timeseries.arXiv preprint arXiv:2304.14065, 2023. 1, 2, 3
-
[72]
Gabriel Tseng, Anthony Fuller, Marlena Reil, Henry Her- zog, Patrick Beukema, Favyen Bastani, James R Green, Evan Shelhamer, Hannah Kerner, and David Rolnick. Galileo: Learning global and local features in pretrained remote sens- ing models.arXiv preprint arXiv:2502.09356, 2025. 2, 3
-
[73]
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. GeoCLIP: Clip-inspired alignment be- tween locations and images for effective worldwide geo- localization.Advances in Neural Information Processing Systems, 36:8690–8701, 2023. 2
work page 2023
-
[74]
Deep mars: Cnn clas- sification of mars imagery for the pds imaging atlas
Kiri Wagstaff, You Lu, Alice Stanboli, Kevin Grimes, Thamme Gowda, and Jordan Padams. Deep mars: Cnn clas- sification of mars imagery for the pds imaging atlas. InPro- ceedings of the AAAI Conference on Artificial Intelligence,
-
[75]
Mars image content clas- sification: Three years of NASA deployment and recent ad- vances
Kiri Wagstaff, Steven Lu, Emily Dunkel, Kevin Grimes, Brandon Zhao, Jesse Cai, Shoshanna B Cole, Gary Doran, Raymond Francis, Jake Lee, et al. Mars image content clas- sification: Three years of NASA deployment and recent ad- vances. InProceedings of the AAAI Conference on Artificial Intelligence, pages 15204–15213, 2021. 1, 23
work page 2021
-
[76]
Florian Wenzel, Jasper Snoek, Dustin Tran, and Rodolphe Jenatton. Hyperparameter ensembles for robustness and un- certainty quantification.Advances in Neural Information Processing Systems, 33:6514–6527, 2020. 2
work page 2020
-
[77]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Re- becca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Ko- rnblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing in- ference time. InInternational conference on machine learn- ing, pages 23965–...
work page 2022
-
[78]
Beyond the permutation symmetry of transformers: The role of rotation for model fusion
Binchi Zhang, Zaiyi Zheng, Zhengzhang Chen, and Jundong Li. Beyond the permutation symmetry of transformers: The role of rotation for model fusion. InForty-second Interna- tional Conference on Machine Learning, 2025. 8
work page 2025
-
[79]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 3 A. Data Overview A.1. Pre-training Data Details Figure 4. Example of a HiRISE map-projected image u...
work page 2018
-
[80]
[75], enables researchers to efficiently identify images relevant to their investigations
This system, developed using machine learning classification techniques by Wagstaff et al. [75], enables researchers to efficiently identify images relevant to their investigations. Bright dune Crater Dark dune Impact ejecta Other Slope Streak Spider Swiss cheese Macro Avg PDS 0.860.790.87 0.300.960.67 0.04 0.94 0.68 MOMO 0.90 0.75 0.91 0.40 0.96 0.78 0.0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.