Recognition: no theorem link
THOM: Generating Physically Plausible Hand-Object Meshes From Text
Pith reviewed 2026-05-13 20:40 UTC · model grok-4.3
The pith
THOM generates physically plausible 3D hand-object meshes from text prompts in a training-free two-stage process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
THOM is a training-free pipeline that first produces hand and object 3D Gaussians conditioned on text, then extracts meshes via an explicit vertex-to-Gaussian mapping that permits topology-aware regularization, and finally improves physical plausibility through contact-aware optimization plus vision-language model-guided translation refinement, yielding HOI meshes that satisfy visual realism, text fidelity, and interaction stability without any template object meshes.
What carries the argument
Mesh extraction with explicit vertex-to-Gaussian mapping that supplies topology-aware regularization for subsequent physics-based optimization.
If this is right
- Hand-object meshes can be produced directly from arbitrary text prompts without supplying pre-existing object templates.
- Topology-aware regularization makes Gaussian-to-mesh conversion stable enough for contact-aware physics refinement.
- VLM-guided translation adjustments further reduce interpenetrations and improve grasp realism.
- The full pipeline remains training-free, allowing immediate use on new prompts without dataset-specific fine-tuning.
Where Pith is reading between the lines
- Similar explicit mapping techniques could be tested on full-body or multi-object scenes to extend physical plausibility beyond hands.
- The generated meshes could serve as starting points for real-world robot grasp planning if transferred to a physics engine that models friction and deformation.
- Integration with real-time rendering pipelines might allow on-the-fly generation of interactive AR content from spoken instructions.
Load-bearing premise
The explicit vertex-to-Gaussian mapping reliably supplies topology information that keeps the physics optimization stable and produces plausible contacts.
What would settle it
Running the extracted meshes through a rigid-body simulator and observing frequent failures such as objects passing through the hand or unstable resting poses would falsify the claim that the method produces physically plausible interactions.
Figures



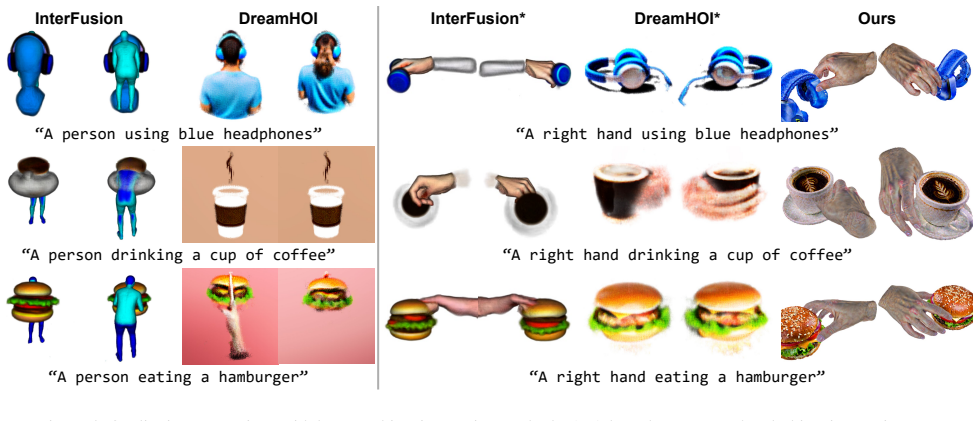






read the original abstract
Generating photorealistic 3D hand-object interactions (HOIs) from text is important for applications like robotic grasping and AR/VR content creation. In practice, however, achieving both visual fidelity and physical plausibility remains difficult, as mesh extraction from text-generated Gaussians is inherently ill-posed and the resulting meshes are often unreliable for physics-based optimization. We present THOM, a training-free framework that generates physically plausible 3D HOI meshes directly from text prompts, without requiring template object meshes. THOM follows a two-stage pipeline: it first generates hand and object Gaussians guided by text, and then refines their interaction using physics-based optimization. To enable reliable interaction modeling, we introduce a mesh extraction method with an explicit vertex-to-Gaussian mapping, which enables topology-aware regularization. We further improve physical plausibility through contact-aware optimization and vision-language model (VLM)-guided translation refinement. Extensive experiments show that THOM produces high-quality HOIs with strong text alignment, visual realism, and interaction plausibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces THOM, a training-free two-stage framework for generating 3D hand-object interaction (HOI) meshes from text prompts. Stage one produces hand and object Gaussians conditioned on text; stage two extracts meshes via a novel explicit vertex-to-Gaussian mapping that supports topology-aware regularization, followed by contact-aware physics optimization and VLM-guided translation refinement. The central claim is that this pipeline yields meshes with strong text alignment, visual realism, and physical plausibility without template meshes or training.
Significance. If the quantitative claims hold, the work would be significant for text-to-3D HOI generation. It removes the requirement for object templates and supervised training while directly targeting physical plausibility through an explicit mapping that addresses the ill-posed Gaussian-to-mesh conversion. The training-free design and the vertex-to-Gaussian component are concrete technical strengths that could transfer to robotic grasping and AR/VR pipelines.
major comments (2)
- [Abstract] Abstract: the statement that 'extensive experiments show that THOM produces high-quality HOIs with strong text alignment, visual realism, and interaction plausibility' is unsupported by any reported metrics, baselines, ablation studies, or quantitative comparisons in the provided text. Without these, the central claim of physical plausibility cannot be evaluated.
- [Mesh extraction method] Mesh extraction method: the explicit vertex-to-Gaussian mapping is presented as the key enabler of reliable topology-aware regularization for physics-based optimization, yet the manuscript supplies neither the precise mapping equations nor ablation results isolating its contribution relative to standard Gaussian-to-mesh conversions. This leaves the weakest assumption unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation of our results and technical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments show that THOM produces high-quality HOIs with strong text alignment, visual realism, and interaction plausibility' is unsupported by any reported metrics, baselines, ablation studies, or quantitative comparisons in the provided text. Without these, the central claim of physical plausibility cannot be evaluated.
Authors: We agree that the abstract claim should be directly supported by evidence. The full manuscript (Section 4) reports quantitative results with metrics for text alignment (CLIP similarity scores), visual realism (user studies and perceptual metrics), and physical plausibility (penetration depth, contact area, and force metrics), along with baseline comparisons. We will revise the abstract to reference these specific quantitative findings and include key numerical results to substantiate the claims. revision: yes
-
Referee: [Mesh extraction method] Mesh extraction method: the explicit vertex-to-Gaussian mapping is presented as the key enabler of reliable topology-aware regularization for physics-based optimization, yet the manuscript supplies neither the precise mapping equations nor ablation results isolating its contribution relative to standard Gaussian-to-mesh conversions. This leaves the weakest assumption unverified.
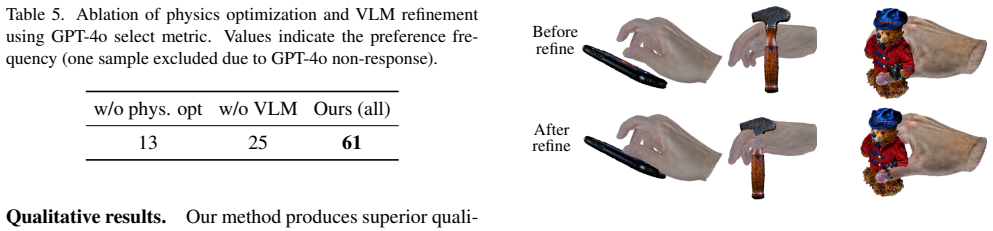
Authors: We acknowledge that the current manuscript describes the vertex-to-Gaussian mapping at a high level without the full equations or dedicated ablations. We will add the precise mathematical formulation of the mapping (including the explicit vertex-to-Gaussian correspondence and topology regularization terms) to Section 3.2. We will also include a new ablation study in Section 4 comparing our mapping against standard conversions (e.g., Marching Cubes) on regularization stability and downstream physical plausibility metrics. This will directly verify its contribution. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The provided abstract and context describe THOM as introducing a new mesh extraction method with explicit vertex-to-Gaussian mapping to address an acknowledged ill-posed problem in Gaussian-to-mesh conversion. This constitutes an independent technical contribution rather than a reduction of outputs to inputs by definition, fitted parameters renamed as predictions, or load-bearing self-citations. No equations, uniqueness theorems, or prior-author citations are invoked to force the central claims; the two-stage pipeline (text-guided Gaussian generation followed by physics-based refinement with topology-aware regularization and VLM guidance) stands as self-contained without circular reduction. The reader's assessment of score 2 aligns with minor framework novelty but does not trigger any enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physics-based optimization applied after mesh extraction from Gaussians produces physically plausible hand-object contacts
Reference graph
Works this paper leans on
-
[1]
Generalized few-shot 3d point cloud segmentation with vision-language model
Zhaochong An, Guolei Sun, Yun Liu, Runjia Li, Junlin Han, Ender Konukoglu, and Serge Belongie. Generalized few-shot 3d point cloud segmentation with vision-language model. InCVPR, pages 16997–17007, 2025. 3
work page 2025
-
[2]
Yukang Cao, Liang Pan, Kai Han, Kwan-Yee K. Wong, and Ziwei Liu. AvatarGO: Zero-shot 4d human-object interaction generation and animation.arXiv preprint arXiv:2410.07164, 2024. 1
-
[3]
Realtime multi-person 2d pose estimation using part affinity fields
Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. InCVPR, 2017. 4
work page 2017
-
[4]
Text2HOI: Text-guided 3d motion generation for hand-object interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, and Seungryul Baek. Text2HOI: Text-guided 3d motion generation for hand-object interaction. InCVPR, pages 1577–1585, 2024. 1, 2, 4, 5, 6
work page 2024
-
[5]
Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation. InICCV, pages 22246– 22256, 2023. 2
work page 2023
-
[6]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Text-to-3d using gaussian splatting
Zilong Chen, Feng Wang, Yikai Wang, and Huaping Liu. Text-to-3d using gaussian splatting. InCVPR, pages 21401– 21412, 2024. 2
work page 2024
-
[8]
3DTopia-XL: High-quality 3d pbr asset generation via primitive diffusion
Zhaoxi Chen, Jiaxiang Tang, Yuhao Dong, Ziang Cao, Fangzhou Hong, Yushi Lan, Tengfei Wang, Haozhe Xie, Tong Wu, Shunsuke Saito, Liang Pan, Dahua Lin, and Zi- wei Liu. 3DTopia-XL: High-quality 3d pbr asset generation via primitive diffusion. InCVPR, 2025. 2
work page 2025
-
[9]
Spatial- rgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- rgpt: Grounded spatial reasoning in vision-language models. NeurIPS, 37:135062–135093, 2024. 2, 3
work page 2024
-
[10]
Inter- Fusion: Text-driven generation of 3d human-object interac- tion
Sisi Dai, Wenhao Li, Haowen Sun, Haibin Huang, Chongyang Ma, Hui Huang, Kai Xu, and Ruizhen Hu. Inter- Fusion: Text-driven generation of 3d human-object interac- tion. InECCV, 2024. 1, 2, 6, 7
work page 2024
-
[11]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InCVPR, pages 13142– 13153, 2023. 1
work page 2023
-
[12]
Cg-hoi: Contact-guided 3d human-object interaction generation
Christian Diller and Angela Dai. Cg-hoi: Contact-guided 3d human-object interaction generation. InCVPR, pages 19888–19901, 2024. 2
work page 2024
-
[13]
Herbert Edelsbrunner, David Kirkpatrick, and Raimund Sei- del. On the shape of a set of points in the plane.IEEE Trans- actions on information theory, 29(4):551–559, 2003. 4
work page 2003
-
[14]
ARCTIC: A dataset for dexterous bimanual hand- object manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Otmar Hilliges. ARCTIC: A dataset for dexterous bimanual hand- object manipulation. InCVPR, pages 12943–12954, 2023. 1, 5
work page 2023
-
[15]
Ruiqi Gao*, Aleksander Holynski*, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul P. Srinivasan, Jonathan T. Barron, and Ben Poole*. CAT3D: Create any- thing in 3d with multi-view diffusion models.NeurIPS,
-
[16]
IMoS: Intent-driven full-body motion synthesis for human-object interactions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Chris- tian Theobalt, and Philipp Slusallek. IMoS: Intent-driven full-body motion synthesis for human-object interactions. In Computer Graphics Forum, pages 1–12. Wiley Online Li- brary, 2023. 2
work page 2023
-
[17]
Antoine Gu ´edon and Vincent Lepetit. Sugar: Surface- aligned gaussian splatting for efficient 3d mesh reconstruc- tion and high-quality mesh rendering. InCVPR, pages 5354– 5363, 2024. 2, 4
work page 2024
-
[18]
Honnotate: A method for 3d annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vin- cent Lepetit. Honnotate: A method for 3d annotation of hand and object poses. InCVPR, pages 3196–3206, 2020. 1
work page 2020
-
[19]
T3Bench: Benchmarking current progress in text-to-3d gen- eration, 2023
Yuze He, Yushi Bai, Matthieu Lin, Wang Zhao, Yubin Hu, Jenny Sheng, Ran Yi, Juanzi Li, and Yong-Jin Liu. T3Bench: Benchmarking current progress in text-to-3d gen- eration, 2023. 6, 7, 5
work page 2023
-
[20]
Expres- sive gaussian human avatars from monocular rgb video
Hezhen Hu, Zhiwen Fan, Tianhao Wu, Yihan Xi, Seoyoung Lee, Georgios Pavlakos, and Zhangyang Wang. Expres- sive gaussian human avatars from monocular rgb video. In NeurIPS, 2024. 4
work page 2024
-
[21]
Turbo3D: Ultra-fast text-to-3d generation.arXiv preprint arXiv:2412.04470, 2024
Hanzhe Hu, Tianwei Yin, Fujun Luan, Yiwei Hu, Hao Tan, Zexiang Xu, Sai Bi, Shubham Tulsiani, and Kai Zhang. Turbo3D: Ultra-fast text-to-3d generation.arXiv preprint arXiv:2412.04470, 2024. 7
-
[22]
Fire- place: Geometric refinements of llm common sense reason- ing for 3d object placement
Ian Huang, Yanan Bao, Karen Truong, Howard Zhou, Cordelia Schmid, Leonidas Guibas, and Alireza Fathi. Fire- place: Geometric refinements of llm common sense reason- ing for 3d object placement. InCVPR, pages 13466–13476,
-
[23]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Affordpose: A large-scale dataset of hand-object inter- actions with affordance-driven hand pose
Juntao Jian, Xiuping Liu, Manyi Li, Ruizhen Hu, and Jian Liu. Affordpose: A large-scale dataset of hand-object inter- actions with affordance-driven hand pose. InICCV, pages 14713–14724, 2023. 5
work page 2023
-
[25]
Hand-object contact consistency reasoning for human grasps generation
Hanwen Jiang, Shaowei Liu, Jiashun Wang, and Xiaolong Wang. Hand-object contact consistency reasoning for human grasps generation. InICCV, pages 11107–11116, 2021. 5
work page 2021
-
[26]
Poisson surface reconstruction
Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. InProceedings of the fourth Eurographics symposium on Geometry processing, 2006. 2
work page 2006
-
[27]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[28]
Shaping the future of vr hand interactions: Lessons learned from modern methods
ByungMin Kim, DongHeun Han, and HyeongYeop Kang. Shaping the future of vr hand interactions: Lessons learned from modern methods. In2025 IEEE Conference Virtual Reality and 3D User Interfaces (VR), pages 165–174. IEEE,
-
[29]
arXiv preprint arXiv:2506.16504 , year=
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxi- ang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3d 2.5: Towards high- fidelity 3d assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025. 2
-
[30]
Maniptrans: Efficient dexterous bimanual manip- ulation transfer via residual learning
Kailin Li, Puhao Li, Tengyu Liu, Yuyang Li, and Siyuan Huang. Maniptrans: Efficient dexterous bimanual manip- ulation transfer via residual learning. InCVPR, pages 6991– 7003, 2025. 1
work page 2025
-
[31]
LatentHOI: On the generalizable hand object motion generation with latent hand diffusion
Muchen Li, Sammy Christen, Chengde Wan, Yujun Cai, Renjie Liao, Leonid Sigal, and Shugao Ma. LatentHOI: On the generalizable hand object motion generation with latent hand diffusion. InCVPR, pages 17416–17425, 2025. 1
work page 2025
-
[32]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. BridgeVLA: Input-output alignment for efficient 3d manipu- lation learning with vision-language models.arXiv preprint arXiv:2506.07961, 2025. 2, 3
-
[33]
Seeground: See and ground for zero-shot open- vocabulary 3d visual grounding
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Jun- wei Liang. Seeground: See and ground for zero-shot open- vocabulary 3d visual grounding. InCVPR, pages 3707– 3717, 2025. 2, 3
work page 2025
-
[34]
Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiao- gang Xu, and Yingcong Chen. Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching. In CVPR, pages 6517–6526, 2024. 2, 3
work page 2024
-
[35]
Dexhanddiff: Interaction-aware diffu- sion planning for adaptive dexterous manipulation
Zhixuan Liang, Yao Mu, Yixiao Wang, Tianxing Chen, Wenqi Shao, Wei Zhan, Masayoshi Tomizuka, Ping Luo, and Mingyu Ding. Dexhanddiff: Interaction-aware diffu- sion planning for adaptive dexterous manipulation. InCVPR, pages 1745–1755, 2025. 1
work page 2025
-
[36]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InCVPR, pages 300–309, 2023. 2, 4
work page 2023
-
[37]
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimiza- tion.NeurIPS, 36:22226–22246, 2023. 2
work page 2023
-
[38]
One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Ji- ayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. InCVPR, pages 10072–10083, 2024. 2
work page 2024
-
[39]
Minghua Liu, Chong Zeng, Xinyue Wei, Ruoxi Shi, Linghao Chen, Chao Xu, Mengqi Zhang, Zhaoning Wang, Xiaoshuai Zhang, Isabella Liu, Hongzhi Wu, and Hao Su. MeshFormer : High-quality mesh generation with 3d-guided reconstruc- tion model.NeurIPS, 37:59314–59341, 2024. 2
work page 2024
-
[40]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, pages 9298– 9309, 2023. 2
work page 2023
-
[41]
Soft ras- terizer: A differentiable renderer for image-based 3d reason- ing
Shichen Liu, Tianye Li, Weikai Chen, and Hao Li. Soft ras- terizer: A differentiable renderer for image-based 3d reason- ing. InICCV, pages 7708–7717, 2019. 4
work page 2019
-
[42]
Core4d: A 4d human-object-human interaction dataset for collaborative object rearrangement
Yun Liu, Chengwen Zhang, Ruofan Xing, Bingda Tang, Bowen Yang, and Li Yi. Core4d: A 4d human-object-human interaction dataset for collaborative object rearrangement. In CVPR, pages 1769–1782, 2025. 1
work page 2025
-
[43]
Score distillation via reparametrized ddim.NeurIPS, 37:26011–26044, 2024
Artem Lukoianov, Haitz S ´aez de Oc ´ariz Borde, Kristjan Greenewald, Vitor Guizilini, Timur Bagautdinov, Vincent Sitzmann, and Justin M Solomon. Score distillation via reparametrized ddim.NeurIPS, 37:26011–26044, 2024. 2
work page 2024
-
[44]
Latent-nerf for shape-guided generation of 3d shapes and textures
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. Latent-nerf for shape-guided generation of 3d shapes and textures. InCVPR, pages 12663–12673, 2023. 2
work page 2023
-
[45]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2
work page 2021
-
[46]
Expressive whole-body 3d gaussian avatar
Gyeongsik Moon, Takaaki Shiratori, and Shunsuke Saito. Expressive whole-body 3d gaussian avatar. InECCV, 2024. 4
work page 2024
-
[47]
Extracting triangular 3d models, materials, and lighting from images
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas M¨uller, and Sanja Fi- dler. Extracting triangular 3d models, materials, and lighting from images. InCVPR, pages 8280–8290, 2022. 2, 4
work page 2022
-
[48]
Hand- iffuser: Text-to-image generation with realistic hand appear- ances
Supreeth Narasimhaswamy, Uttaran Bhattacharya, Xiang Chen, Ishita Dasgupta, Saayan Mitra, and Minh Hoai. Hand- iffuser: Text-to-image generation with realistic hand appear- ances. InCVPR, pages 2468–2479, 2024. 3
work page 2024
-
[49]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-e: A system for generat- ing 3d point clouds from complex prompts.arXiv preprint arXiv:2212.08751, 2022. 8
work page internal anchor Pith review arXiv 2022
-
[50]
Reconstruct- ing hands in 3D with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstruct- ing hands in 3D with transformers. InCVPR, 2024. 4
work page 2024
-
[51]
Manus: Markerless grasp capture using articulated 3d gaussians
Chandradeep Pokhariya, Ishaan Nikhil Shah, Angela Xing, Zekun Li, Kefan Chen, Avinash Sharma, and Srinath Srid- har. Manus: Markerless grasp capture using articulated 3d gaussians. InCVPR, pages 2197–2208, 2024. 4
work page 2024
-
[52]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, pages 8748–8763. PmLR, 2021. 6
work page 2021
-
[54]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 4
work page 2022
-
[55]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied Hands: Modeling and capturing hands and bod- ies together.ACM Transactions on Graphics, (Proc. SIG- GRAPH Asia), 36(6), 2017. 4
work page 2017
-
[56]
MD Sayem, Mubarrat Tajoar Chowdhury, Yihalem Yimolal Tiruneh, Muneeb A Khan, Muhammad Salman Ali, Binod Bhattarai, and Seungryul Baek. Handvqa: Diagnosing and improving fine-grained spatial reasoning about hands in vision-language models.arXiv preprint arXiv:2603.26362,
-
[57]
Layoutvlm: Differentiable optimization of 3d layout via vision-language models
Fan-Yun Sun, Weiyu Liu, Siyi Gu, Dylan Lim, Goutam Bhat, Federico Tombari, Manling Li, Nick Haber, and Jiajun Wu. Layoutvlm: Differentiable optimization of 3d layout via vision-language models. InCVPR, pages 29469–29478,
-
[58]
GRAB: A dataset of whole-body human grasping of objects
Omid Taheri, Nima Ghorbani, Michael J Black, and Dim- itrios Tzionas. GRAB: A dataset of whole-body human grasping of objects. InECCV, pages 581–600. Springer,
-
[59]
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation.arXiv preprint arXiv:2309.16653,
-
[60]
Delicate textured mesh recovery from nerf via adaptive surface refinement
Jiaxiang Tang, Hang Zhou, Xiaokang Chen, Tianshu Hu, Er- rui Ding, Jingdong Wang, and Gang Zeng. Delicate textured mesh recovery from nerf via adaptive surface refinement. In ICCV, pages 17739–17749, 2023. 2
work page 2023
-
[61]
Lgm: Large multi-view gaus- sian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaus- sian model for high-resolution 3d content creation. InECCV, pages 1–18. Springer, 2024. 1, 2
work page 2024
-
[62]
Masatoshi Tateno, Gido Kato, Hirokatsu Kataoka, Yoichi Sato, and Takuma Yagi. Handyvqa: A video qa benchmark for fine-grained hand-object interaction dynamics.arXiv preprint arXiv:2512.00885, 2025. 3
-
[63]
Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A Yeh, and Greg Shakhnarovich. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. InCVPR, pages 12619–12629, 2023. 2
work page 2023
-
[64]
arXiv preprint arXiv:2106.10689 , year=
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv preprint arXiv:2106.10689, 2021. 2, 4
-
[65]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Unigrasptransformer: Simplified policy distilla- tion for scalable dexterous robotic grasping
Wenbo Wang, Fangyun Wei, Lei Zhou, Xi Chen, Lin Luo, Xiaohan Yi, Yizhong Zhang, Yaobo Liang, Chang Xu, Yan Lu, et al. Unigrasptransformer: Simplified policy distilla- tion for scalable dexterous robotic grasping. InCVPR, pages 12199–12208, 2025. 1
work page 2025
-
[67]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. ProlificDreamer: High-fidelity and diverse text-to-3d generation with variational score dis- tillation. InNeurIPS, 2023. 4, 6
work page 2023
-
[68]
SpatialCLIP: Learning 3d- aware image representations from spatially discriminative language
Zehan Wang, Sashuai Zhou, Shaoxuan He, Haifeng Huang, Lihe Yang, Ziang Zhang, Xize Cheng, Shengpeng Ji, Tao Jin, Hengshuang Zhao, et al. SpatialCLIP: Learning 3d- aware image representations from spatially discriminative language. InCVPR, pages 29656–29666, 2025. 3
work page 2025
-
[69]
arXiv preprint arXiv:2404.12385 , year=
Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, and Zex- iang Xu. MeshLRM: Large reconstruction model for high- quality meshes.arXiv preprint arXiv:2404.12385, 2024. 1, 2
-
[70]
Ouroboros3d: Image-to-3d generation via 3d- aware recursive diffusion
Hao Wen, Zehuan Huang, Yaohui Wang, Xinyuan Chen, and Lu Sheng. Ouroboros3d: Image-to-3d generation via 3d- aware recursive diffusion. InCVPR, pages 21631–21641,
-
[71]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models.arXiv preprint arXiv:2404.07191,
work page internal anchor Pith review arXiv
-
[72]
Hash3d: Training-free acceleration for 3d generation
Xingyi Yang, Songhua Liu, and Xinchao Wang. Hash3d: Training-free acceleration for 3d generation. InCVPR, pages 21481–21491, 2025. 6
work page 2025
-
[73]
Affordance diffusion: Synthesizing hand-object inter- actions
Yufei Ye, Xueting Li, Abhinav Gupta, Shalini De Mello, Stan Birchfield, Jiaming Song, Shubham Tulsiani, and Sifei Liu. Affordance diffusion: Synthesizing hand-object inter- actions. InCVPR, pages 22479–22489, 2023. 2, 5
work page 2023
-
[74]
G-HOP: Generative hand-object prior for interaction reconstruction and grasp synthesis
Yufei Ye, Abhinav Gupta, Kris Kitani, and Shubham Tul- siani. G-HOP: Generative hand-object prior for interaction reconstruction and grasp synthesis. InCVPR, 2024. 2, 1, 5
work page 2024
-
[75]
GaussianDreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, and Xinggang Wang. GaussianDreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. InCVPR,
-
[76]
Taoran Yi, Jiemin Fang, Zanwei Zhou, Junjie Wang, Guan- jun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Xing- gang Wang, and Qi Tian. Gaussiandreamerpro: Text to ma- nipulable 3d gaussians with highly enhanced quality.arXiv preprint arXiv:2406.18462, 2024. 2, 3, 6
-
[77]
Visual programming for zero-shot open-vocabulary 3d visual grounding
Zhihao Yuan, Jinke Ren, Chun-Mei Feng, Hengshuang Zhao, Shuguang Cui, and Zhen Li. Visual programming for zero-shot open-vocabulary 3d visual grounding. InCVPR, pages 20623–20633, 2024. 3
work page 2024
-
[78]
High-fidelity lightweight mesh reconstruction from point clouds
Chen Zhang, Wentao Wang, Ximeng Li, Xinyao Liao, Wan- juan Su, and Wenbing Tao. High-fidelity lightweight mesh reconstruction from point clouds. InCVPR, pages 11739– 11748, 2025. 3
work page 2025
-
[79]
Mengqi Zhang, Yang Fu, Zheng Ding, Sifei Liu, Zhuowen Tu, and Xiaolong Wang. HOIDiffusion: Generating re- alistic 3d hand-object interaction data.arXiv preprint arXiv:2403.12011, 2024. 2
-
[80]
Yuqi Zhang, Han Luo, and Yinjie Lei. Towards clip-driven language-free 3d visual grounding via 2d-3d relational en- hancement and consistency. InCVPR, pages 13063–13072,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.