Recognition: no theorem link
UNICA: A Unified Neural Framework for Controllable 3D Avatars
Pith reviewed 2026-05-13 19:43 UTC · model grok-4.3
The pith
UNICA unifies motion planning, rigging, physical simulation, and rendering into one skeleton-free neural model for controllable 3D avatars from keyboard inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UNICA is a skeleton-free generative model that unifies the workflow of motion planning, rigging, physical simulation, and rendering by generating avatar geometry through an action-conditioned diffusion model operating on 2D position maps and then mapping the result to 3D Gaussian Splatting for free-view rendering.
What carries the argument
Action-conditioned diffusion model on 2D position maps, followed by a point transformer to 3D Gaussian Splatting primitives.
Load-bearing premise
An action-conditioned diffusion model operating on 2D position maps can reliably capture complex dynamics such as hair and loose clothing without any explicit physical simulation or skeleton.
What would settle it
Generate long sequences with rapid movements of loose clothing or long hair and check whether the resulting deformations match observed real-world video dynamics or deviate in ways that break physical plausibility.
Figures









read the original abstract
Controllable 3D human avatars have found widespread applications in 3D games, the metaverse, and AR/VR scenarios. The conventional approach to creating such a 3D avatar requires a lengthy, intricate pipeline encompassing appearance modeling, motion planning, rigging, and physical simulation. In this paper, we introduce UNICA (UNIfied neural Controllable Avatar), a skeleton-free generative model that unifies all avatar control components into a single neural framework. Given keyboard inputs akin to video game controls, UNICA generates the next frame of a 3D avatar's geometry through an action-conditioned diffusion model operating on 2D position maps. A point transformer then maps the resulting geometry to 3D Gaussian Splatting for high-fidelity free-view rendering. Our approach naturally captures hair and loose clothing dynamics without manually designed physical simulation, and supports extra-long autoregressive generation. To the best of our knowledge, UNICA is the first model to unify the workflow of "motion planning, rigging, physical simulation, and rendering". Code is released at https://github.com/zjh21/UNICA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UNICA, a skeleton-free generative model for controllable 3D avatars. Given keyboard inputs, an action-conditioned diffusion model generates the next frame of avatar geometry via 2D position maps; a point transformer then converts this geometry to 3D Gaussian Splatting for free-view rendering. The central claim is that this single neural framework unifies motion planning, rigging, physical simulation, and rendering, naturally capturing non-rigid dynamics such as hair and loose clothing without explicit physics or skeletons, while supporting extra-long autoregressive rollouts.
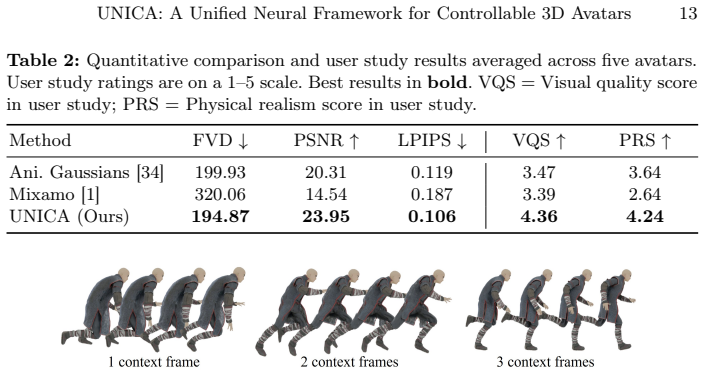
Significance. If the implicit dynamics capture and unification hold under quantitative scrutiny, the work could simplify avatar pipelines for games, metaverse, and AR/VR applications by removing multi-stage engineering. The public code release is a clear strength for reproducibility. However, the absence of reported error metrics, ablations, or comparisons in the abstract leaves the practical advantage over conventional pipelines unverified.
major comments (3)
- [Abstract] Abstract: the claim that the diffusion model 'naturally captures hair and loose clothing dynamics without manually designed physical simulation' is load-bearing for the unification thesis, yet no quantitative results, ablation studies, or error analysis are provided to demonstrate that 2D position maps suffice for 3D non-rigid motion without drift or loss of depth ordering.
- [Abstract] Abstract: the assertion that UNICA is 'the first model to unify the workflow of motion planning, rigging, physical simulation, and rendering' requires a concrete comparison section showing how prior skeleton-based or hybrid methods fail at end-to-end unification; without such evidence the novelty claim remains ungrounded.
- [Abstract] The autoregressive generation claim for 'extra-long' sequences rests on the diffusion model avoiding geometric drift, but the 2D map representation and lack of explicit skeleton or physics prior create a high risk of accumulation errors over long horizons; this must be tested with metrics on sequence length and out-of-distribution actions.
minor comments (1)
- [Abstract] The abstract states 'Code is released at https://github.com/zjh21/UNICA' but provides no details on the exact release contents (e.g., training scripts, pretrained weights, or evaluation protocols).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our abstract claims. We agree that strengthening the grounding of our assertions with explicit references to experimental evidence will improve the manuscript. We address each major comment point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the diffusion model 'naturally captures hair and loose clothing dynamics without manually designed physical simulation' is load-bearing for the unification thesis, yet no quantitative results, ablation studies, or error analysis are provided to demonstrate that 2D position maps suffice for 3D non-rigid motion without drift or loss of depth ordering.
Authors: We acknowledge that the abstract would benefit from direct references to supporting results. The full paper presents qualitative results in Section 4.2 and quantitative geometry error metrics (e.g., Chamfer distance and normal consistency) in Section 5.1 that demonstrate effective capture of non-rigid dynamics such as hair and loose clothing. In the revision we will update the abstract to cite these metrics briefly and add a dedicated ablation on the 2D position map representation to quantify its handling of depth ordering and drift. revision: partial
-
Referee: [Abstract] Abstract: the assertion that UNICA is 'the first model to unify the workflow of motion planning, rigging, physical simulation, and rendering' requires a concrete comparison section showing how prior skeleton-based or hybrid methods fail at end-to-end unification; without such evidence the novelty claim remains ungrounded.
Authors: We agree that a dedicated comparison would better substantiate the unification claim. In the revised manuscript we will insert a new subsection (likely in Related Work or Experiments) that includes a comparison table and analysis contrasting UNICA against representative skeleton-based and hybrid pipelines, explicitly showing the multi-stage engineering required by prior methods versus our single neural framework. revision: yes
-
Referee: [Abstract] The autoregressive generation claim for 'extra-long' sequences rests on the diffusion model avoiding geometric drift, but the 2D map representation and lack of explicit skeleton or physics prior create a high risk of accumulation errors over long horizons; this must be tested with metrics on sequence length and out-of-distribution actions.
Authors: We recognize the importance of quantifying long-horizon stability. Our current experiments (Section 5.3 and supplementary material) evaluate autoregressive rollouts up to 1000 frames with reported per-frame error curves showing limited drift on in-distribution actions. To directly address the concern we will add explicit quantitative metrics on sequence length, error accumulation rates, and out-of-distribution action performance in the revised version. revision: partial
Circularity Check
No circularity: UNICA unification is an architectural design choice, not a derivation reducing to inputs
full rationale
The paper proposes a new generative model that combines an action-conditioned diffusion process on 2D position maps with a subsequent point transformer to produce 3D Gaussian Splatting output. This single-framework unification of motion planning, rigging, simulation, and rendering is presented as an empirical engineering result rather than a mathematical derivation. No equations are shown that define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing claims rest on self-citations or imported uniqueness theorems. The central claim is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models conditioned on action signals can produce coherent next-frame 3D geometry from 2D position maps
Reference graph
Works this paper leans on
-
[1]
Adobe: Mixamo.https://www.mixamo.com/(2026), accessed: 2026-01-21
work page 2026
- [2]
- [3]
-
[4]
https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/ (2025)
Ball, P.J., Bauer, J., Belletti, F., et al.: Genie 3: A new frontier for world models. https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/ (2025)
work page 2025
- [5]
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [7]
-
[8]
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: CVPR (2017)
work page 2017
-
[9]
Chen, B., Martí Monsó, D., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: DiffusionForcing:Next-tokenpredictionmeetsfull-sequencediffusion.In:NeurIPS. vol. 37, pp. 24081–24125 (2024)
work page 2024
- [10]
-
[11]
Chen, Y., Mihajlovic, M., Chen, X., Wang, Y., Prokudin, S., Tang, S.: Splatformer: Point transformer for robust 3D gaussian splatting. In: ICLR (2025)
work page 2025
-
[12]
Ding, J., Zhang, Y., Shang, Y., et al.: Understanding world or predicting future? A comprehensive survey of world models. ACM Comput. Surv.58(3) (2025)
work page 2025
- [13]
- [14]
-
[15]
Feng, Y., Choutas, V., Bolkart, T., Tzionas, D., Black, M.J.: Collaborative regres- sion of expressive bodies using moderation. In: 3DV. pp. 792–804 (2021)
work page 2021
-
[16]
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y., Geiger, A., Zhang, J., Li, H.: Vista: A generalizable driving world model with high fidelity and versatile controllability. In: NeurIPS. vol. 37, pp. 91560–91596 (2024)
work page 2024
-
[17]
Advancing open-source world models,
Gao, Z., Wang, Q., Zeng, Y., et al.: Advancing open-source world models. arXiv preprint arXiv:2601.20540 (2026)
- [18]
- [19]
-
[20]
ACM TOG39(4), 60:1–60:12 (2020) 16 J
Harvey, F.G., Yurick, M., Nowrouzezahrai, D., Pal, C.: Robust motion in- betweening. ACM TOG39(4), 60:1–60:12 (2020) 16 J. Zhuet al
work page 2020
-
[21]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
He, X., Peng, C., Liu, Z., et al.: Matrix-Game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS. vol. 33, pp. 6840–6851 (2020)
work page 2020
-
[24]
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS Workshop (2021)
work page 2021
-
[25]
ACM TOG36(4), 42:1–42:13 (2017)
Holden, D., Komura, T., Saito, J.: Phase-functioned neural networks for character control. ACM TOG36(4), 42:1–42:13 (2017)
work page 2017
- [26]
-
[27]
Jiang, Y., Zhang, L., Gao, J., Hu, W., Yao, Y.: Consistent4D: Consistent 360° dynamic object generation from monocular video. In: ICLR (2024)
work page 2024
- [28]
-
[29]
Nature638(8051), 656–663 (2025)
Kanervisto, A., Bignell, D., Wen, L.Y., et al.: World and human action models towards gameplay ideation. Nature638(8051), 656–663 (2025)
work page 2025
-
[30]
Kaufmann,M.,Aksan,E.,Song,J.,Pece,F.,Ziegler,R.,Hilliges,O.:Convolutional autoencoders for human motion infilling. In: 3DV. pp. 918–927 (2020)
work page 2020
-
[31]
ACM TOG42(4), 139:1–139:14 (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3D Gaussian splatting for real-time radiance field rendering. ACM TOG42(4), 139:1–139:14 (2023)
work page 2023
-
[32]
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: ICLR (2013)
work page 2013
-
[33]
ACM TOG40(4), 130:1–130:15 (2021)
Li, P., Aberman, K., Hanocka, R., Liu, L., Sorkine-Hornung, O., Chen, B.: Learning skeletal articulations with neural blend shapes. ACM TOG40(4), 130:1–130:15 (2021)
work page 2021
- [34]
- [35]
-
[36]
ACM TOG44(4), 122:1–122:12 (2025)
Liu, I., Xu, Z., Yifan, W., Tan, H., Xu, Z., Wang, X., Su, H., Shi, Z.: RigAny- thing: Template-free autoregressive rigging for diverse 3D assets. ACM TOG44(4), 122:1–122:12 (2025)
work page 2025
-
[37]
ACM TOG34(6), 248:1–248:16 (2015)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM TOG34(6), 248:1–248:16 (2015)
work page 2015
- [38]
-
[39]
Yume-1.5: A text-controlled interactive world generation model,
Mao, X., Li, Z., Li, C., Xu, X., Ying, K., He, T., Pang, J., Qiao, Y., Zhang, K.: Yume-1.5: A text-controlled interactive world generation model. arXiv preprint arXiv:2512.22096 (2025)
- [40]
- [41]
-
[42]
van den Oord, A., Vinyals, O., kavukcuoglu, k.: Neural discrete representation learning. In: NeurIPS. vol. 30, pp. 6309–6318 (2017) UNICA: A Unified Neural Framework for Controllable 3D Avatars 17
work page 2017
-
[43]
Parker-Holder, J., Ball, P., Bruce, J., et al.: Genie 2: A large-scale foundation world model.https://deepmind.google/discover/blog/genie- 2- a- large- scale- foundation-world-model/(2024)
work page 2024
- [44]
-
[45]
Plappert, M., Mandery, C., Asfour, T.: The kit motion-language dataset. Big Data 4(4), 236–252 (2016)
work page 2016
-
[46]
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: DreamFusion: Text-to-3D using 2D diffusion. In: ICLR (2023)
work page 2023
- [47]
-
[48]
Ren, J., Xie, K., Mirzaei, A., et al.: L4GM: Large 4D Gaussian reconstruction model. In: NeurIPS. vol. 37, pp. 56828–56858 (2024)
work page 2024
- [49]
-
[50]
ACM TOG36(6), 245:1–245:17 (2017)
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. ACM TOG36(6), 245:1–245:17 (2017)
work page 2017
-
[51]
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomed- ical image segmentation. In: MICCAI. pp. 234–241 (2015)
work page 2015
-
[52]
Saharia, C., Chan, W., Saxena, S., et al.: Photorealistic text-to-image diffusion models with deep language understanding. In: NeurIPS. vol. 35, pp. 36479–36494 (2022)
work page 2022
-
[53]
Shi, Y., Wang, P., Ye, J., Mai, L., Li, K., Yang, X.: MVDream: Multi-view diffusion for 3D generation. In: ICLR (2024)
work page 2024
- [54]
-
[55]
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
work page 2021
-
[56]
ACM TOG41(4), 136:1–136:13 (2022)
Starke, S., Mason, I., Komura, T.: DeepPhase: Periodic autoencoders for learning motion phase manifolds. ACM TOG41(4), 136:1–136:13 (2022)
work page 2022
-
[57]
ACM TOG38(6), 209:1–209:14 (2019)
Starke, S., Zhang, H., Komura, T., Saito, J.: Neural state machine for character- scene interactions. ACM TOG38(6), 209:1–209:14 (2019)
work page 2019
-
[58]
ACM TOG39(4), 54:1–54:13 (2020)
Starke, S., Zhao, Y., Komura, T., Zaman, K.: Local motion phases for learning multi-contact character movements. ACM TOG39(4), 54:1–54:13 (2020)
work page 2020
-
[59]
Su, S.Y., Yu, F., Zollhöfer, M., Rhodin, H.: A-NeRF: Articulated neural radiance fields for learning human shape, appearance, and pose. In: NeurIPS. vol. 34, pp. 12278–12291 (2021)
work page 2021
-
[60]
Sun, W., Zhang, H., Wang, H., Wu, J., Wang, Z., Wang, Z., Wang, Y., Zhang, J., Wang, T., Guo, C.: WorldPlay: Towards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614 (2025)
-
[61]
Tao, H., Hou, S., Zou, C., Bao, H., Xu, W.: Neural motion graph. In: SIGGRAPH Asia. pp. 84:1–84:11 (2023)
work page 2023
-
[62]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. In: ICLR (2023)
work page 2023
-
[63]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[64]
Valevski, D., Leviathan, Y., Arar, M., Fruchter, S.: Diffusion models are real-time game engines. In: ICLR (2025) 18 J. Zhuet al
work page 2025
- [65]
-
[66]
Wang, L., Zhao, X., Sun, J., Zhang, Y., Zhang, H., Yu, T., Liu, Y.: StyleAvatar: Real-time photo-realistic portrait avatar from a single video. In: SIGGRAPH. pp. 67:1–67:10 (2023)
work page 2023
-
[67]
arXiv preprint arXiv:2305.10874 (2023)
Wang, W., Yang, H., Tuo, Z., He, H., Zhu, J., Fu, J., Liu, J.: VideoFactory: Swap attention in spatiotemporal diffusions for text-to-video generation. arXiv preprint arXiv:2305.10874 (2023)
-
[68]
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE TIP13(4), 600–612 (2004)
work page 2004
-
[69]
Wu, X., Jiang, L., Wang, P.S., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T., Zhao, H.:PointTransformerV3:Simplerfasterstronger.In:CVPR.pp.4840–4851(2024)
work page 2024
-
[70]
Xie, Y., Yao, C.H., Voleti, V., Jiang, H., Jampani, V.: SV4D: Dynamic 3D content generation with multi-frame and multi-view consistency. In: ICLR (2025)
work page 2025
-
[71]
Xu, M., Dai, W., Liu, C., Gao, X., Lin, W., Qi, G.J., Xiong, H.: Spatial-temporal transformer networks for traffic flow forecasting. arXiv preprint arXiv:2001.02908 (2020)
-
[72]
ACM TOG39(4), 58:1–58:14 (2020)
Xu, Z., Zhou, Y., Kalogerakis, E., Landreth, C., Singh, K.: RigNet: Neural rigging for articulated characters. ACM TOG39(4), 58:1–58:14 (2020)
work page 2020
-
[73]
Xu, Z., Zhou, Y., Kalogerakis, E., Singh, K.: Predicting animation skeletons for 3D articulated models via volumetric nets. In: 3DV. pp. 298–307 (2019)
work page 2019
-
[74]
arXiv preprint arXiv:2503.13435 (2025)
Yang, L., Zhu, K., Tian, J., Zeng, B., Lin, M., Pei, H., Zhang, W., Yan, S.: WideRange4D: Enabling high-quality 4D reconstruction with wide-range move- ments and scenes. arXiv preprint arXiv:2503.13435 (2025)
-
[75]
Yang, Z., Pan, Z., Gu, C., Zhang, L.: Diffusion2: Dynamic 3D content generation via score composition of video and multi-view diffusion models. In: ICLR (2025)
work page 2025
-
[76]
arXiv preprint arXiv:2503.16396 (2025)
Yao, C.H., Xie, Y., Voleti, V., Jiang, H., Jampani, V.: SV4D 2.0: Enhancing spatio- temporal consistency in multi-view video diffusion for high-quality 4D generation. arXiv preprint arXiv:2503.16396 (2025)
-
[77]
Yenphraphai, J., Mirzaei, A., Chen, J., Zou, J., Tulyakov, S., Yeh, R.A., Wonka, P., Wang, C.: ShapeGen4D: Towards high quality 4D shape generation from videos. In: ICLR (2026)
work page 2026
-
[78]
ACM TOG37(4), 145:1–145:11 (2018)
Zhang, H., Starke, S., Komura, T., Saito, J.: Mode-adaptive neural networks for quadruped motion control. ACM TOG37(4), 145:1–145:11 (2018)
work page 2018
-
[79]
ACM TOG44(4), 123:1–123:18 (2025)
Zhang, J.P., Pu, C.F., Guo, M.H., Cao, Y.P., Hu, S.M.: One model to rig them all: Diverse skeleton rigging with unirig. ACM TOG44(4), 123:1–123:18 (2025)
work page 2025
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.