Recognition: 2 theorem links
· Lean TheoremCMCC-ReID: Cross-Modality Clothing-Change Person Re-Identification
Pith reviewed 2026-05-13 20:30 UTC · model grok-4.3
The pith
A Progressive Identity Alignment Network separates identity cues from clothing and modality variations to match people across visible and infrared images even when outfits change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
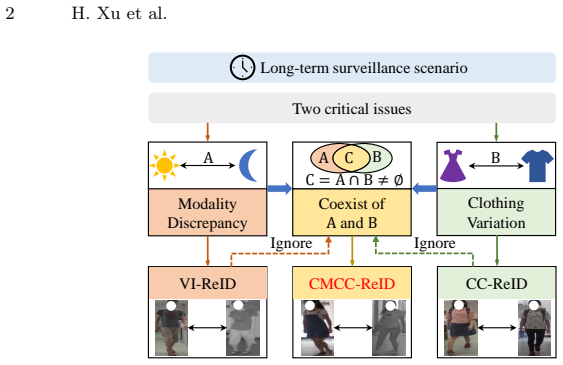
The paper introduces the CMCC-ReID task to match pedestrians when both modality (visible versus infrared) and clothing differ between views. It supplies the SYSU-CMCC benchmark containing paired visible-infrared images of the same identities in distinct outfits. The Progressive Identity Alignment Network progressively mitigates the two sources of variation by applying Dual-Branch Disentangling Learning to produce clothing-agnostic representations and Bi-Directional Prototype Learning to perform intra- and inter-modality contrast that further suppresses clothing interference.
What carries the argument
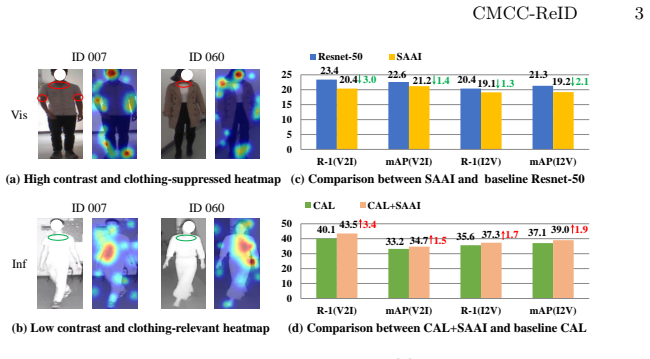
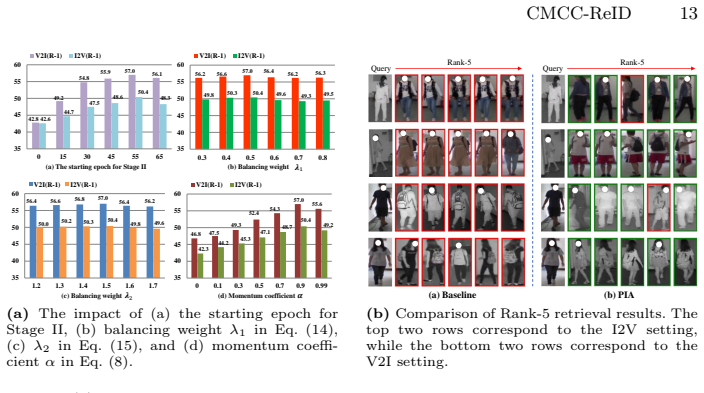
Progressive Identity Alignment Network (PIA) built from a Dual-Branch Disentangling Learning module that separates identity-related cues from clothing-related factors and a Bi-Directional Prototype Learning module that conducts contrastive alignment across modalities in embedding space.
Load-bearing premise
Identity cues can be reliably isolated from clothing factors in the learned features without losing the discriminative power needed for accurate matching under real surveillance conditions.
What would settle it
If ablation tests on SYSU-CMCC show that removing either the Dual-Branch Disentangling Learning module or the Bi-Directional Prototype Learning module produces no accuracy drop, or if the full PIA network fails to outperform adapted baselines from visible-infrared and clothing-change re-identification.
Figures


read the original abstract
Person Re-Identification (ReID) faces severe challenges from modality discrepancy and clothing variation in long-term surveillance scenario. While existing studies have made significant progress in either Visible-Infrared ReID (VI-ReID) or Clothing-Change ReID (CC-ReID), real-world surveillance system often face both challenges simultaneously. To address this overlooked yet realistic problem, we define a new task, termed Cross-Modality Clothing-Change Re-Identification (CMCC-ReID), which targets pedestrian matching across variations in both modality and clothing. To advance research in this direction, we construct a new benchmark SYSU-CMCC, where each identity is captured in both visible and infrared domains with distinct outfits, reflecting the dual heterogeneity of long-term surveillance. To tackle CMCC-ReID, we propose a Progressive Identity Alignment Network (PIA) that progressively mitigates the issues of clothing variation and modality discrepancy. Specifically, a Dual-Branch Disentangling Learning (DBDL) module separates identity-related cues from clothing-related factors to achieve clothing-agnostic representation, and a Bi-Directional Prototype Learning (BPL) module performs intra-modality and inter-modality contrast in the embedding space to bridge the modality gap while further suppressing clothing interference. Extensive experiments on the SYSU-CMCC dataset demonstrate that PIA establishes a strong baseline for this new task and significantly outperforms existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines a new task called Cross-Modality Clothing-Change Person Re-Identification (CMCC-ReID) that requires matching pedestrians across simultaneous visible-infrared modality shifts and clothing changes. It introduces the SYSU-CMCC benchmark dataset in which each identity appears in both modalities with distinct outfits. The authors propose the Progressive Identity Alignment Network (PIA) whose Dual-Branch Disentangling Learning (DBDL) module separates identity cues from clothing factors and whose Bi-Directional Prototype Learning (BPL) module performs intra- and inter-modality contrastive alignment. Extensive experiments are claimed to show that PIA establishes a strong baseline and significantly outperforms adapted VI-ReID and CC-ReID methods on SYSU-CMCC.
Significance. If the quantitative results and fair baseline comparisons hold, the work is significant because it formalizes and provides the first benchmark for a realistic long-term surveillance scenario that combines two previously studied but separately addressed heterogeneities. The DBDL and BPL modules offer a concrete architectural approach to clothing-agnostic and modality-bridging representations; successful validation would supply both a reproducible starting point and falsifiable performance targets for subsequent CMCC-ReID research.
major comments (3)
- [Experiments] Experiments section: the central claim that PIA 'significantly outperforms existing methods' is load-bearing yet unsupported by any reported rank-1, mAP, or CMC numbers, ablation tables, or error bars in the manuscript text. Without these metrics it is impossible to assess the magnitude of improvement or the contribution of DBDL versus BPL.
- [Experiments] Baseline adaptation paragraph: the paper must document that all compared VI-ReID and CC-ReID methods were re-trained from scratch on SYSU-CMCC using identical backbone, optimizer, data augmentation, batch size, and loss weighting as PIA. Any deviation in training protocol would render the performance gap non-attributable to the proposed modules.
- [Dataset] Dataset construction subsection: the number of identities, total images per modality, train/test splits, and clothing-change statistics for SYSU-CMCC are not stated. These details are required to judge whether the benchmark is sufficiently challenging and whether the reported gains generalize beyond the specific split used.
minor comments (2)
- [Method] The abstract states that PIA 'progressively mitigates' clothing and modality issues, but the manuscript never defines the progressive schedule or the order in which DBDL and BPL are applied during training.
- [Method] Notation for the prototype embeddings in the BPL module should be introduced with explicit dimensionality and normalization details to avoid ambiguity when readers attempt re-implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened for clarity and reproducibility. We address each major comment below and will revise the manuscript accordingly to incorporate the requested details.
read point-by-point responses
-
Referee: Experiments section: the central claim that PIA 'significantly outperforms existing methods' is load-bearing yet unsupported by any reported rank-1, mAP, or CMC numbers, ablation tables, or error bars in the manuscript text. Without these metrics it is impossible to assess the magnitude of improvement or the contribution of DBDL versus BPL.
Authors: We agree that explicit quantitative metrics are essential for evaluating the claims. The manuscript includes experimental tables with rank-1, mAP, CMC curves, and ablation results, but these are not summarized in the main text. In the revision, we will add a concise summary of the key performance numbers (including error bars from multiple runs) directly in the Experiments section, along with explicit discussion of the contributions from DBDL and BPL based on the ablations. revision: yes
-
Referee: Baseline adaptation paragraph: the paper must document that all compared VI-ReID and CC-ReID methods were re-trained from scratch on SYSU-CMCC using identical backbone, optimizer, data augmentation, batch size, and loss weighting as PIA. Any deviation in training protocol would render the performance gap non-attributable to the proposed modules.
Authors: We confirm that all baselines were re-implemented and trained from scratch on SYSU-CMCC under identical protocols to PIA. To address the concern, we will expand the baseline adaptation paragraph to explicitly state the shared backbone, optimizer, data augmentation, batch size, and loss weighting details for every compared method, ensuring the performance differences can be attributed to the proposed modules. revision: yes
-
Referee: Dataset construction subsection: the number of identities, total images per modality, train/test splits, and clothing-change statistics for SYSU-CMCC are not stated. These details are required to judge whether the benchmark is sufficiently challenging and whether the reported gains generalize beyond the specific split used.
Authors: We acknowledge that these statistics are necessary for assessing the benchmark. In the revised manuscript, we will expand the Dataset construction subsection to report the exact number of identities, total images per modality, train/test splits, and clothing-change statistics (e.g., number of outfit variations per identity). This will allow readers to evaluate the dataset's difficulty and the generalizability of the results. revision: yes
Circularity Check
No circularity: new task definition, modules, and empirical claims stand independently
full rationale
The paper defines CMCC-ReID as a new task, constructs the SYSU-CMCC benchmark, and introduces PIA with DBDL (separating identity from clothing cues) and BPL (intra- and inter-modality contrast) modules whose descriptions are functional rather than self-referential. No equations appear that reduce claimed performance or alignment metrics to fitted parameters from the same data by construction, and no self-citation chain is invoked to justify uniqueness or force the architecture. The outperformance statement is presented as an empirical observation on the new dataset, not a renaming or definitional tautology. This is the common case of a self-contained proposal whose central claims do not collapse to their inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDual-Branch Disentangling Learning (DBDL) module separates identity-related cues from clothing-related factors ... orthogonality constraint loss L_orth
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclearBi-Directional Prototype Learning (BPL) module performs intra-modality and inter-modality contrast ... progressive learning paradigm
Forward citations
Cited by 1 Pith paper
-
Towards Robust Text-to-Image Person Retrieval: Multi-View Reformulation for Semantic Compensation
A multi-view semantic reformulation and feature compensation method using LLMs and VLMs improves text-to-image person retrieval accuracy without training and reaches SOTA on three datasets.
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
- [5]
- [6]
- [7]
- [8]
- [9]
- [10]
- [11]
- [12]
- [13]
- [14]
- [15]
- [16]
-
[17]
In: International conference on machine learning
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning. pp. 448–456. pmlr (2015) 16 H. Xu et al
work page 2015
- [18]
- [19]
-
[20]
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. NeurIPS33, 18661–18673 (2020)
work page 2020
- [21]
-
[22]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [23]
-
[24]
arXiv preprint arXiv:2005.04966 (2020)
Li, J., Zhou, P., Xiong, C., Hoi, S.C.: Prototypical contrastive learning of unsuper- vised representations. arXiv preprint arXiv:2005.04966 (2020)
-
[25]
IEEE Transactions on Multimedia 25, 8432–8444 (2023)
Liang, T., Jin, Y., Liu, W., Li, Y.: Cross-modality transformer with modality min- ing for visible-infrared person re-identification. IEEE Transactions on Multimedia 25, 8432–8444 (2023)
work page 2023
- [26]
-
[27]
Liu, F., Ye, M., Du, B.: Dual level adaptive weighting for cloth-changing person re-identification. TIP32, 5075–5086 (2023)
work page 2023
-
[28]
Liu, F., Ye, M., Du, B.: Cloth-aware augmentation for cloth-generalized person re-identification. In: ACM MM. pp. 4053–4062 (2024)
work page 2024
- [29]
- [30]
- [31]
- [32]
- [33]
- [34]
-
[35]
Qian, X., Wang, W., Zhang, L., Zhu, F., Fu, Y., Xiang, T., Jiang, Y.G., Xue, X.: Long-term cloth-changing person re-identification. In: ACCV (2020)
work page 2020
- [36]
- [37]
- [38]
- [39]
- [40]
- [41]
- [42]
- [43]
- [44]
- [45]
- [46]
- [47]
-
[48]
Xu, H., Li, B., Niu, G.: Identity-aware feature decoupling learning for clothing- change person re-identification. In: ICASSP. pp. 1–5 (2025)
work page 2025
-
[49]
arXiv preprint arXiv:2603.14243 (2026)
Xu, H., Niu, G.: Bit: Matching-based bi-directional interaction transformation net- work for visible-infrared person re-identification. arXiv preprint arXiv:2603.14243 (2026)
- [50]
- [51]
-
[52]
IEEE TPAMI43(6), 2029–2046 (2019)
Yang, Q., Wu, A., Zheng, W.S.: Person re-identification by contour sketch under moderate clothing change. IEEE TPAMI43(6), 2029–2046 (2019)
work page 2029
- [53]
- [54]
-
[55]
Ye, M., Shen, J., J. Crandall, D., Shao, L., Luo, J.: Dynamic dual-attentive aggre- gation learning for visible-infrared person re-identification. In: ECCV. pp. 229–247 (2020)
work page 2020
-
[56]
IEEE TPAMI44(6), 2872–2893 (2021)
Ye, M., Shen, J., Lin, G., Xiang, T., Shao, L., Hoi, S.C.: Deep learning for person re-identification: A survey and outlook. IEEE TPAMI44(6), 2872–2893 (2021)
work page 2021
- [57]
- [58]
- [59]
- [60]
- [61]
-
[62]
Zhang, Y., Yan, Y., Lu, Y., Wang, H.: Towards a unified middle modality learning for visible-infrared person re-identification. In: ACM MM. pp. 788–796 (2021)
work page 2021
- [63]
- [64]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.