Recognition: unknown
Towards Robust Text-to-Image Person Retrieval: Multi-View Reformulation for Semantic Compensation
Pith reviewed 2026-05-10 04:42 UTC · model grok-4.3
The pith
LLM-generated multi-view text reformulations compensate for phrasing variations to improve text-to-image person retrieval without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a training-free semantic compensation framework uses LLMs to produce multi-view reformulations of texts through dual-branch prompting that extracts key visual features for guidance while encouraging diversity, then applies mean-pooling across the resulting embeddings with residual connections to reinforce shared meaning and suppress phrasing noise; a parallel visual compensation step generates multi-perspective image descriptions that are themselves reformulated to address implicit visual semantics, yielding improved cross-modal alignment for person retrieval.
What carries the argument
Multi-view reformulation that uses LLM dual-branch prompting for key-feature-guided and diversity-aware text variants, followed by mean-pooling of embeddings plus residual connections to capture semantic echoes.
If this is right
- Existing text-to-image retrieval models gain accuracy on person search tasks when the compensation is applied at inference time with no retraining.
- State-of-the-art results are reached on three standard text-to-image person retrieval datasets.
- Both textual phrasing variations and visual semantic gaps are handled by the same reformulation and compensation steps.
- The improvements require no changes to model parameters or additional training data.
Where Pith is reading between the lines
- The same input-enrichment idea could be tested on related cross-modal tasks such as text-to-video retrieval where phrasing diversity also causes mismatches.
- If the averaging reliably extracts consistent signals, simpler base models might approach the performance of more heavily trained systems simply by using richer inputs.
- The method's effectiveness will likely scale with future improvements in how accurately language models generate meaning-preserving paraphrases.
Load-bearing premise
That the reformulations created by the language model keep exactly the same meaning as the original while differing enough in wording for averaging to reduce the embedding shifts caused by those wording differences.
What would settle it
If applying the multi-view reformulation and feature averaging to any base retrieval model produces no gain or a loss in standard accuracy metrics such as rank-1 or mean average precision on the three person retrieval benchmarks, the compensation benefit would be refuted.
Figures




read the original abstract
In text-to-image person retrieval tasks, the diversity of natural language expressions and the implicitness of visual semantics often lead to the problem of Expression Drift, where semantically equivalent texts exhibit significant feature discrepancies in the embedding space due to phrasing variations, thereby degrading the robustness of image-text alignment. This paper proposes a semantic compensation framework (MVR) driven by Large Language Models (LLMs), which enhances cross-modal representation consistency through multi-view semantic reformulation and feature compensation. The core methodology comprises three components: Multi-View Reformulation (MVR): A dual-branch prompting strategy combines key feature guidance (extracting visually critical components via feature similarity) and diversity-aware rewriting to generate semantically equivalent yet distributionally diverse textual variants; Textual Feature Robustness Enhancement: A training-free latent space compensation mechanism suppresses noise interference through multi-view feature mean-pooling and residual connections, effectively capturing "Semantic Echoes"; Visual Semantic Compensation: VLM generates multi-perspective image descriptions, which are further enhanced through shared text reformulation to address visual semantic gaps. Experiments demonstrate that our method can improve the accuracy of the original model well without training and performs SOTA on three text-to-image person retrieval datasets.
Editorial analysis
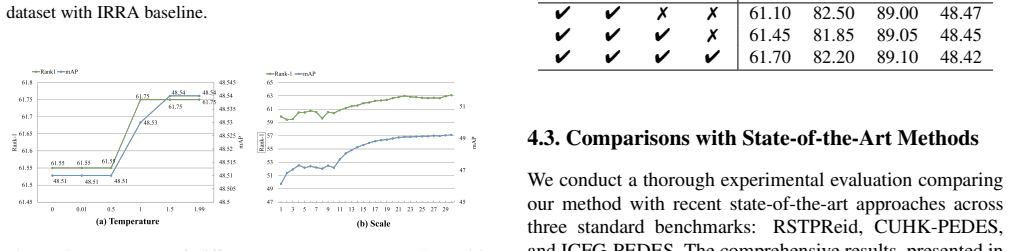
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a training-free Multi-View Reformulation (MVR) framework for text-to-image person retrieval to address 'Expression Drift' caused by phrasing variations. It uses LLMs in a dual-branch prompting strategy (key-feature guidance plus diversity-aware rewriting) to generate semantically equivalent yet diverse text variants, applies mean-pooling with residual connections to capture 'Semantic Echoes' for feature compensation, and incorporates VLM-generated multi-perspective image descriptions. The authors claim this improves base model accuracy without training and achieves SOTA results on three datasets.
Significance. If the core compensation mechanism proves reliable, the approach offers a practical, parameter-free way to boost robustness in existing cross-modal retrieval systems by leveraging LLMs/VLMs for semantic augmentation. This could be valuable for real-world person retrieval where linguistic variability is common, provided the gains are shown to stem from the proposed 'Semantic Echoes' rather than incidental effects.
major comments (2)
- [Abstract / Textual Feature Robustness Enhancement] Abstract and Textual Feature Robustness Enhancement: The central compensation step relies on the unverified premise that LLM-generated multi-view reformulations remain semantically equivalent to the originals (while adding distributional diversity) so that mean-pooling plus residuals can capture 'Semantic Echoes'. No quantitative checks (embedding cosine similarity, entailment scores, or human equivalence ratings) are reported between original and reformulated texts, leaving open the possibility that the method injects noise rather than compensating for drift.
- [Abstract] Abstract: The claim of SOTA performance and consistent accuracy improvements without training is asserted without any reported metrics, baselines, ablation studies, dataset details, or statistical tests. This makes it impossible to evaluate whether reported gains exceed noise or post-hoc selection effects, which is load-bearing for the central claim of robust semantic compensation.
minor comments (1)
- [Methodology] The term 'Semantic Echoes' is introduced without a formal definition or mathematical formulation, which could be clarified in the methodology section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to specific revisions where appropriate to strengthen the paper.
read point-by-point responses
-
Referee: The central compensation step relies on the unverified premise that LLM-generated multi-view reformulations remain semantically equivalent to the originals (while adding distributional diversity) so that mean-pooling plus residuals can capture 'Semantic Echoes'. No quantitative checks (embedding cosine similarity, entailment scores, or human equivalence ratings) are reported between original and reformulated texts, leaving open the possibility that the method injects noise rather than compensating for drift.
Authors: We appreciate this observation on the need for explicit verification of semantic equivalence. The dual-branch prompting strategy (key-feature guidance combined with diversity-aware rewriting) is explicitly designed to preserve core semantics while introducing distributional variety, as described in Section 3.1. However, we acknowledge that the original submission did not include quantitative metrics such as embedding cosine similarities or entailment scores between original and reformulated texts. In the revised manuscript, we will add these analyses (using the same embedding model as the retrieval backbone and an off-the-shelf NLI model for entailment) to empirically support that mean-pooling captures 'Semantic Echoes' rather than noise. Human equivalence ratings on a sample subset will also be included if space permits. revision: yes
-
Referee: The claim of SOTA performance and consistent accuracy improvements without training is asserted without any reported metrics, baselines, ablation studies, dataset details, or statistical tests. This makes it impossible to evaluate whether reported gains exceed noise or post-hoc selection effects, which is load-bearing for the central claim of robust semantic compensation.
Authors: The full manuscript (Sections 4 and 5) reports all requested elements: quantitative metrics (Rank-1, mAP), comparisons against multiple baselines, ablation studies isolating each component (MVR, feature compensation, visual compensation), dataset details (CUHK-PEDES, ICFG-PEDES, RSTPReid), and statistical tests where relevant. The abstract follows conventional practice by summarizing these results at a high level. To directly address the concern, we will revise the abstract to include specific key numbers (e.g., average improvements and SOTA margins) while keeping it concise, ensuring the central claims are immediately verifiable. revision: partial
Circularity Check
No significant circularity in the proposed framework
full rationale
The paper describes a training-free methodological pipeline (dual-branch LLM prompting for multi-view reformulation followed by mean-pooling and residual connections for compensation) whose central claims rest on experimental results across three datasets rather than any closed mathematical derivation. No equations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The semantic-equivalence assumption is an unverified premise that affects correctness but does not reduce any claimed result to its inputs by construction, satisfying the default expectation of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can produce semantically equivalent yet distributionally diverse textual variants from key feature guidance
- ad hoc to paper Multi-view mean-pooling with residual connections suppresses noise and captures consistent semantic features
invented entities (1)
-
Semantic Echoes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Rasa: relation and sensitivity aware representation learning for text-based person search
Yang Bai, Min Cao, Daming Gao, Ziqiang Cao, Chen Chen, Zhenfeng Fan, Liqiang Nie, and Min Zhang. Rasa: relation and sensitivity aware representation learning for text-based person search. InProceedings of the Thirty-Second Interna- tional Joint Conference on Artificial Intelligence, pages 555– 563, 2023. 2, 5
2023
-
[3]
Text-based person search without parallel image-text data
Yang Bai, Jingyao Wang, Min Cao, Chen Chen, Ziqiang Cao, Liqiang Nie, and Min Zhang. Text-based person search without parallel image-text data. InProceedings of the 31st ACM International Conference on Multimedia, pages 757– 767, 2023. 2
2023
-
[4]
An empirical study of clip for text-based person search
Min Cao, Yang Bai, Ziyin Zeng, Mang Ye, and Min Zhang. An empirical study of clip for text-based person search. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 465–473, 2024. 2, 5
2024
-
[5]
Tipcb: A simple but effective part-based convolutional baseline for text-based person search.Neuro- computing, 494:171–181, 2022
Yuhao Chen, Guoqing Zhang, Yujiang Lu, Zhenxing Wang, and Yuhui Zheng. Tipcb: A simple but effective part-based convolutional baseline for text-based person search.Neuro- computing, 494:171–181, 2022. 2
2022
-
[6]
arXiv preprint arXiv:2107.12666 (2021) 2, 3, 11, 15
Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. Semantically self-aligned network for text-to- image part-aware person re-identification.arXiv preprint arXiv:2107.12666, 2021. 1, 2, 5
-
[7]
Large-scale pre-training for person re-identification with noisy labels
Dengpan Fu, Dongdong Chen, Hao Yang, Jianmin Bao, Lu Yuan, Lei Zhang, Houqiang Li, Fang Wen, and Dong Chen. Large-scale pre-training for person re-identification with noisy labels. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2476–2486, 2022. 2
2022
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2
2016
-
[10]
Vgsg: Vision-guided semantic-group network for text- based person search.IEEE Transactions on Image Process- ing, 33:163–176, 2023
Shuting He, Hao Luo, Wei Jiang, Xudong Jiang, and Henghui Ding. Vgsg: Vision-guided semantic-group network for text- based person search.IEEE Transactions on Image Process- ing, 33:163–176, 2023. 5
2023
-
[11]
Empowering visible- infrared person re-identification with large foundation mod- els.Advances in Neural Information Processing Systems, 37: 117363–117387, 2024
Zhangyi Hu, Bin Yang, and Mang Ye. Empowering visible- infrared person re-identification with large foundation mod- els.Advances in Neural Information Processing Systems, 37: 117363–117387, 2024. 1, 2, 3, 4, 6
2024
-
[12]
Cross-modal implicit relation rea- soning and aligning for text-to-image person retrieval
Ding Jiang and Mang Ye. Cross-modal implicit relation rea- soning and aligning for text-to-image person retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2787–2797, 2023. 2, 5, 6 8
2023
-
[13]
Jiayu Jiang, Changxing Ding, Wentao Tan, Junhong Wang, Jin Tao, and Xiangmin Xu. Modeling thousands of hu- man annotators for generalizable text-to-image person re- identification.arXiv preprint arXiv:2503.09962, 2025. 1, 2, 5, 6
-
[14]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 1, 2
2022
-
[15]
Learning semantic polymorphic mapping for text-based per- son retrieval.IEEE Transactions on Multimedia, 2024
Jiayi Li, Min Jiang, Jun Kong, Xuefeng Tao, and Xi Luo. Learning semantic polymorphic mapping for text-based per- son retrieval.IEEE Transactions on Multimedia, 2024. 5
2024
-
[16]
Person search with natural lan- guage description
Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. Person search with natural lan- guage description. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1970–1979,
1970
-
[17]
Dcel: deep cross-modal evi- dential learning for text-based person retrieval
Shenshen Li, Xing Xu, Yang Yang, Fumin Shen, Yijun Mo, Yujie Li, and Heng Tao Shen. Dcel: deep cross-modal evi- dential learning for text-based person retrieval. InProceed- ings of the 31st ACM International Conference on Multime- dia, pages 6292–6300, 2023. 2, 5
2023
-
[18]
Adaptive uncertainty-based learning for text-based person retrieval
Shenshen Li, Chen He, Xing Xu, Fumin Shen, Yang Yang, and Heng Tao Shen. Adaptive uncertainty-based learning for text-based person retrieval. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 3172–3180, 2024. 5
2024
-
[19]
Text and image are mutually beneficial: Enhancing training-free few-shot classification with clip
Yayuan Li, Jintao Guo, Lei Qi, Wenbin Li, and Yinghuan Shi. Text and image are mutually beneficial: Enhancing training-free few-shot classification with clip. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 5039–5047, 2025. 2
2025
-
[20]
Cross-modal adaptive dual association for text-to- image person retrieval.IEEE Transactions on Multimedia, 26:6609–6620, 2024
Dixuan Lin, Yi-Xing Peng, Jingke Meng, and Wei-Shi Zheng. Cross-modal adaptive dual association for text-to- image person retrieval.IEEE Transactions on Multimedia, 26:6609–6620, 2024. 2, 5
2024
-
[21]
Feature pyramid net- works for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid net- works for object detection. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2117–2125, 2017. 2
2017
-
[22]
Try harder: Hard sample generation and learning for cloth-changing per- son re-id
Hankun Liu, Yujian Zhao, and Guanglin Niu. Try harder: Hard sample generation and learning for cloth-changing per- son re-id. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 1704–1713, 2025. 2
2025
-
[23]
Causality-inspired invariant representation learning for text-based person retrieval
Yu Liu, Guihe Qin, Haipeng Chen, Zhiyong Cheng, and Xun Yang. Causality-inspired invariant representation learning for text-based person retrieval. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 14052–14060, 2024. 5
2024
-
[24]
Zanwu Liu, Chao Yuan, Bo Li, Xiaowei Zhang, and Guan- glin Niu. Looking alike from far to near: Enhancing cross- resolution re-identification via feature vector panning.arXiv preprint arXiv:2510.00936, 2025. 2
-
[25]
Omniperson: Unified identity-preserving pedestrian generation.arXiv preprint arXiv:2512.02554,
Changxiao Ma, Chao Yuan, Xincheng Shi, Yuzhuo Ma, Yongfei Zhang, Longkun Zhou, Yujia Zhang, Shangze Li, and Yifan Xu. Omniperson: Unified identity-preserving pedestrian generation.arXiv preprint arXiv:2512.02554,
-
[26]
Gpt-4o: Openai’s multimodal language model,
OpenAI. Gpt-4o: Openai’s multimodal language model,
-
[27]
Plot: Text-based person search with part slot attention for corresponding part discovery
Jicheol Park, Dongwon Kim, Boseung Jeong, and Suha Kwak. Plot: Text-based person search with part slot attention for corresponding part discovery. InEuropean Conference on Computer Vision, pages 474–490. Springer, 2024. 5
2024
-
[28]
Noisy-correspondence learning for text-to-image person re-identification
Yang Qin, Yingke Chen, Dezhong Peng, Xi Peng, Joey Tianyi Zhou, and Peng Hu. Noisy-correspondence learning for text-to-image person re-identification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27197–27206, 2024. 2, 5, 6
2024
-
[29]
Yuxuan Qiu, Liyang Wang, Wei Song, Jiawei Liu, Zhip- ing Shi, and Na Jiang. Advancing visible-infrared person re-identification: Synergizing visual-textual reasoning and cross-modal feature alignment.IEEE Transactions on Infor- mation Forensics and Security, 20:2184–2196, 2025. 2
2025
-
[30]
Language models are unsuper- vised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsuper- vised multitask learners.OpenAI blog, 1(8):9, 2019. 2
2019
-
[31]
Learn- ing transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2, 4
2021
-
[32]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 10684–10695, 2022. 2
2022
-
[33]
Adversarial representation learning for text-to-image match- ing
Nikolaos Sarafianos, Xiang Xu, and Ioannis A Kakadiaris. Adversarial representation learning for text-to-image match- ing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 5814–5824, 2019. 2
2019
-
[34]
Learning granularity-unified representations for text-to-image person re-identification
Zhiyin Shao, Xinyu Zhang, Meng Fang, Zhifeng Lin, Jian Wang, and Changxing Ding. Learning granularity-unified representations for text-to-image person re-identification. In Proceedings of the 30th acm international conference on mul- timedia, pages 5566–5574, 2022. 5
2022
-
[35]
Unified pre-training with pseudo texts for text-to-image person re-identification
Zhiyin Shao, Xinyu Zhang, Changxing Ding, Jian Wang, and Jingdong Wang. Unified pre-training with pseudo texts for text-to-image person re-identification. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11174–11184, 2023. 2, 5
2023
-
[36]
See finer, see more: Implicit modality alignment for text-based person retrieval
Xiujun Shu, Wei Wen, Haoqian Wu, Keyu Chen, Yiran Song, Ruizhi Qiao, Bo Ren, and Xiao Wang. See finer, see more: Implicit modality alignment for text-based person retrieval. InEuropean Conference on Computer Vision, pages 624–
-
[37]
From data deluge to data curation: A filtering-wora paradigm for efficient text-based person search
Jintao Sun, Hao Fei, Gangyi Ding, and Zhedong Zheng. From data deluge to data curation: A filtering-wora paradigm for efficient text-based person search. InTHE WEB CON- FERENCE 2025. 5
2025
-
[38]
Harnessing the power of mllms for transferable text-to-image person reid
Wentan Tan, Changxing Ding, Jiayu Jiang, Fei Wang, Yib- ing Zhan, and Dapeng Tao. Harnessing the power of mllms for transferable text-to-image person reid. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17127–17137, 2024. 2
2024
-
[39]
Fine-grained semantics- aware representation learning for text-based person retrieval
Di Wang, Feng Yan, Yifeng Wang, Lin Zhao, Xiao Liang, Haodi Zhong, and Ronghua Zhang. Fine-grained semantics- aware representation learning for text-based person retrieval. InProceedings of the 2024 International Conference on Mul- timedia Retrieval, pages 92–100, 2024. 5 9
2024
-
[40]
High-order information matters: Learning relation and topology for occluded person re-identification
Guan’an Wang, Shuo Yang, Huanyu Liu, Zhicheng Wang, Yang Yang, Shuliang Wang, Gang Yu, Erjin Zhou, and Jian Sun. High-order information matters: Learning relation and topology for occluded person re-identification. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6449–6458, 2020. 2
2020
-
[41]
When large vision-language models meet person re-identification,
Qizao Wang, Bin Li, and Xiangyang Xue. When large vision-language models meet person re-identification.arXiv preprint arXiv:2411.18111, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[42]
Vi- taa: Visual-textual attributes alignment in person search by natural language
Zhe Wang, Zhiyuan Fang, Jun Wang, and Yezhou Yang. Vi- taa: Visual-textual attributes alignment in person search by natural language. InComputer vision–ECCV 2020: 16th Eu- ropean conference, glasgow, UK, August 23–28, 2020, pro- ceedings, part XII 16, pages 402–420. Springer, 2020. 2
2020
-
[43]
Caibc: Capturing all-round infor- mation beyond color for text-based person retrieval
Zijie Wang, Aichun Zhu, Jingyi Xue, Xili Wan, Chao Liu, Tian Wang, and Yifeng Li. Caibc: Capturing all-round infor- mation beyond color for text-based person retrieval. InPro- ceedings of the 30th ACM international conference on multi- media, pages 5314–5322, 2022. 5
2022
-
[44]
Grok 3 beta — the age of reasoning agents.https: //x.ai/blog/grok-3, 2025
xAI. Grok 3 beta — the age of reasoning agents.https: //x.ai/blog/grok-3, 2025. 3, 7
2025
-
[45]
Lv-reid: Large language-vision alignment model for text-based per- son re-identification
Yinghui Xia, Chao Wang, and Jinsong Yang. Lv-reid: Large language-vision alignment model for text-based per- son re-identification. InICASSP 2025-2025 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5. IEEE, 2025. 2
2025
-
[46]
arXiv preprint arXiv:2603.14243 (2026)
Haoxuan Xu and Guanglin Niu. Bit: Matching- based bi-directional interaction transformation network for visible-infrared person re-identification.arXiv preprint arXiv:2603.14243, 2026. 2
-
[47]
Identity-aware feature decoupling learning for clothing-change person re- identification
Haoxuan Xu, Bo Li, and Guanglin Niu. Identity-aware feature decoupling learning for clothing-change person re- identification. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[48]
CMCC-ReID: Cross-Modality Clothing-Change Person Re-Identification
Haoxuan Xu, Hanzi Wang, and Guanglin Niu. Cmcc-reid: Cross-modality clothing-change person re-identification. arXiv preprint arXiv:2604.02808, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Learning comprehensive representations with richer self for text-to-image person re-identification
Shuanglin Yan, Neng Dong, Jun Liu, Liyan Zhang, and Jinhui Tang. Learning comprehensive representations with richer self for text-to-image person re-identification. InProceed- ings of the 31st ACM international conference on multimedia, pages 6202–6211, 2023. 5
2023
-
[50]
Clip-driven fine-grained text-image person re-identification
Shuanglin Yan, Neng Dong, Liyan Zhang, and Jinhui Tang. Clip-driven fine-grained text-image person re-identification. IEEE Transactions on Image Processing, 32:6032–6046,
-
[51]
Prototypical prompting for text-to-image person re- identification
Shuanglin Yan, Jun Liu, Neng Dong, Liyan Zhang, and Jinhui Tang. Prototypical prompting for text-to-image person re- identification. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2331–2340, 2024. 5
2024
-
[52]
Shan Yang and Yongfei Zhang. Mllmreid: multimodal large language model-based person re-identification.arXiv preprint arXiv:2401.13201, 2024. 2
-
[53]
Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark
Shuyu Yang, Yinan Zhou, Zhedong Zheng, Yaxiong Wang, Li Zhu, and Yujiao Wu. Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark. InProceedings of the 31st ACM International Conference on Multimedia, pages 4492–4501, 2023. 2, 5
2023
-
[54]
Chao Yuan, Zanwu Liu, Guiwei Zhang, Haoxuan Xu, Yujian Zhao, Guanglin Niu, and Bo Li. Modality- transition representation learning for visible-infrared person re-identification.arXiv preprint arXiv:2511.02685, 2025. 2
-
[55]
From poses to identity: Training-free per- son re-identification via feature centralization
Chao Yuan, Guiwei Zhang, Changxiao Ma, Tianyi Zhang, and Guanglin Niu. From poses to identity: Training-free per- son re-identification via feature centralization. InProceed- ings of the Computer Vision and Pattern Recognition Confer- ence, pages 24409–24418, 2025. 3
2025
-
[56]
Neighbor- based feature and index enhancement for person re- identification
Chao Yuan, Tianyi Zhang, and Guanglin Niu. Neighbor- based feature and index enhancement for person re- identification. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5762–5769, 2025. 3
2025
-
[57]
Deep cross-modal projection learning for image-text matching
Ying Zhang and Huchuan Lu. Deep cross-modal projection learning for image-text matching. InProceedings of the Euro- pean conference on computer vision (ECCV), pages 686–701,
-
[58]
Yujian Zhao, Hankun Liu, and Guanglin Niu. Mos: Mit- igating optical-sar modality gap for cross-modal ship re- identification.arXiv preprint arXiv:2512.03404, 2025. 2
-
[59]
Ccup: A controllable synthetic data generation pipeline for pretraining cloth-changing per- son re-identification models
Yujian Zhao, Chengru Wu, Yinong Xu, Xuanzheng Du, Ruiyu Li, and Guanglin Niu. Ccup: A controllable synthetic data generation pipeline for pretraining cloth-changing per- son re-identification models. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025. 2
2025
-
[60]
Uni- fying multi-modal uncertainty modeling and semantic align- ment for text-to-image person re-identification
Zhiwei Zhao, Bin Liu, Yan Lu, Qi Chu, and Nenghai Yu. Uni- fying multi-modal uncertainty modeling and semantic align- ment for text-to-image person re-identification. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 7534–7542, 2024. 5
2024
-
[61]
Dual-path convolutional image-text embeddings with instance loss.ACM Transac- tions on Multimedia Computing, Communications, and Ap- plications (TOMM), 16(2):1–23, 2020
Zhedong Zheng, Liang Zheng, Michael Garrett, Yi Yang, Mingliang Xu, and Yi-Dong Shen. Dual-path convolutional image-text embeddings with instance loss.ACM Transac- tions on Multimedia Computing, Communications, and Ap- plications (TOMM), 16(2):1–23, 2020. 2
2020
-
[62]
Dssl: Deep surroundings-person separation learning for text-based per- son retrieval
Aichun Zhu, Zijie Wang, Yifeng Li, Xili Wan, Jing Jin, Tian Wang, Fangqiang Hu, and Gang Hua. Dssl: Deep surroundings-person separation learning for text-based per- son retrieval. InProceedings of the 29th ACM international conference on multimedia, pages 209–217, 2021. 1, 2, 5
2021
-
[63]
Plip: Language-image pre-training for person repre- sentation learning.Advances in Neural Information Process- ing Systems, 37:45666–45702, 2024
Jialong Zuo, Jiahao Hong, Feng Zhang, Changqian Yu, Hanyu Zhou, Changxin Gao, Nong Sang, and Jingdong Wang. Plip: Language-image pre-training for person repre- sentation learning.Advances in Neural Information Process- ing Systems, 37:45666–45702, 2024. 1, 2
2024
-
[64]
Ufinebench: Towards text-based person retrieval with ultra- fine granularity
Jialong Zuo, Hanyu Zhou, Ying Nie, Feng Zhang, Tianyu Guo, Nong Sang, Yunhe Wang, and Changxin Gao. Ufinebench: Towards text-based person retrieval with ultra- fine granularity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22010– 22019, 2024. 5 10 Towards Robust Text-to-Image Person Retrieval: Multi-View Refor...
2024
-
[65]
Computation cost For each generation, for DeepSeek-V3 as example, it re- quires approximately 0.246 TFLOPs per token, making it highly efficient for multi-round generation. In our setting, producing 15 reformulations incurs a total cost equivalent to only a few billion floating-point operations, which can be completed within 0.5 seconds either on a local ...
-
[66]
Prompts 7.1. Our prompt withP key Prompt withP key System: Instructions: Suppose you now have a picture of a pedestrian, I will give you a caption and its key words list, your task is to rewrite the caption. - Contains every key word must be used, but can change order and replace other words in a similar meaning. - Give me 15 different captions and return...
-
[67]
Query compensation withP key Example Input: Caption: This man has short black hair and wears a suit jacket,black trousers with a pair of sneakers.He is looking at left side
Examples 8.1. Query compensation withP key Example Input: Caption: This man has short black hair and wears a suit jacket,black trousers with a pair of sneakers.He is looking at left side. Keywords: ’man’, ’short’, ’black’, ’hair’, ’suit’, ’jacket’, ’trousers’, ’sneakers’, ’looking’, ’left’. Output: [ - A man with short black hair is dressed in a suit jack...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.