Recognition: no theorem link
A Paradigm Shift: Fully End-to-End Training for Temporal Sentence Grounding in Videos
Pith reviewed 2026-05-13 19:40 UTC · model grok-4.3
The pith
Fully end-to-end training of video backbones and localization heads, guided by a sentence-conditioned adapter, outperforms frozen-backbone methods on temporal sentence grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a fully end-to-end training paradigm, in which the video backbone and localization head are optimized together, combined with the Sentence Conditioned Adapter that uses sentence embeddings to modulate feature maps, resolves the task discrepancy between classification pre-training and temporal sentence grounding and delivers higher localization performance than prior state-of-the-art methods that keep backbones frozen.
What carries the argument
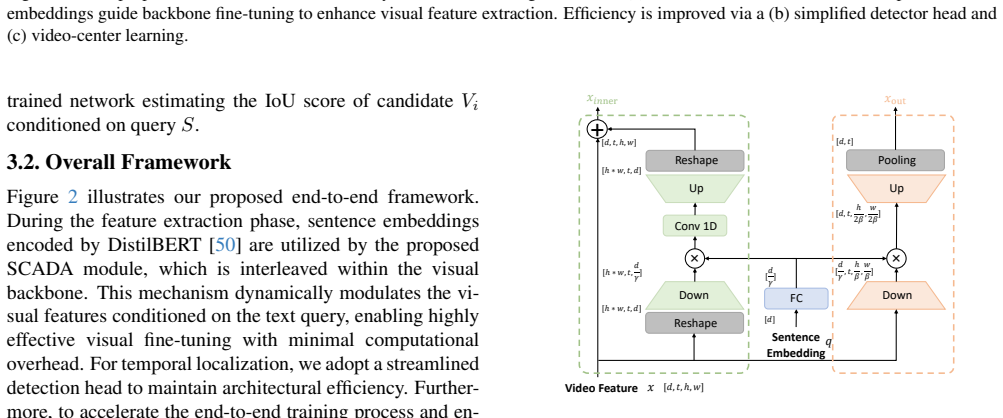
Sentence Conditioned Adapter (SCADA), a lightweight module that conditions a small subset of video-backbone parameters on linguistic embeddings to adaptively modulate feature maps during joint optimization.
If this is right
- End-to-end training improves results over frozen baselines at multiple model scales.
- SCADA permits deeper backbones to be trained with lower peak memory than full fine-tuning.
- Visual features become more task-aligned for sentence-guided localization through direct linguistic modulation.
- The overall pipeline exceeds previously published state-of-the-art numbers on the two evaluated datasets.
Where Pith is reading between the lines
- Similar lightweight conditioning adapters could be tested on other video-language tasks that currently rely on frozen encoders.
- The memory savings reported for deeper networks suggest the method may scale to larger backbones where full fine-tuning is currently prohibitive.
- If SCADA-style modulation proves stable across datasets, it could reduce reliance on massive classification pre-training corpora for grounding-specific models.
Load-bearing premise
End-to-end optimization together with a small sentence-conditioned adapter can close the classification-to-grounding gap without causing overfitting or exceeding practical memory limits.
What would settle it
Training the same deeper backbone end-to-end without SCADA or with a random adapter on the two reported benchmarks yields no accuracy gain or a clear drop relative to the frozen baseline while memory usage remains comparable.
Figures



read the original abstract
Temporal sentence grounding in videos (TSGV) aims to localize a temporal segment that semantically corresponds to a sentence query from an untrimmed video. Most current methods adopt pre-trained query-agnostic visual encoders for offline feature extraction, and the video backbones are frozen and not optimized for TSGV. This leads to a task discrepancy issue for the video backbone trained for visual classification, but utilized for TSGV. To bridge this gap, we propose a fully end-to-end paradigm that jointly optimizes the video backbone and localization head. We first conduct an empirical study validating the effectiveness of end-to-end learning over frozen baselines across different model scales. Furthermore, we introduce a Sentence Conditioned Adapter (SCADA), which leverages sentence features to train a small portion of video backbone parameters adaptively. SCADA facilitates the deployment of deeper network backbones with reduced memory and significantly enhances visual representation by modulating feature maps through precise integration of linguistic embeddings. Experiments on two benchmarks show that our method outperforms state-of-the-art approaches. The code and models will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fully end-to-end training paradigm for temporal sentence grounding in videos (TSGV) that jointly optimizes the video backbone and localization head, in contrast to prior work that freezes pre-trained query-agnostic visual encoders. It introduces the Sentence Conditioned Adapter (SCADA) to adaptively modulate a small subset of backbone parameters using sentence features, enabling deeper networks with lower memory while addressing the classification-to-grounding task discrepancy. An empirical study across model scales plus experiments on two benchmarks are reported to show outperformance over state-of-the-art methods.
Significance. If the empirical gains hold under rigorous controls, the work would mark a meaningful shift in TSGV by demonstrating that end-to-end optimization with a lightweight sentence-conditioned adapter can close the task gap without prohibitive memory costs, potentially improving visual representations for video-language localization tasks and encouraging similar joint training in related domains.
major comments (2)
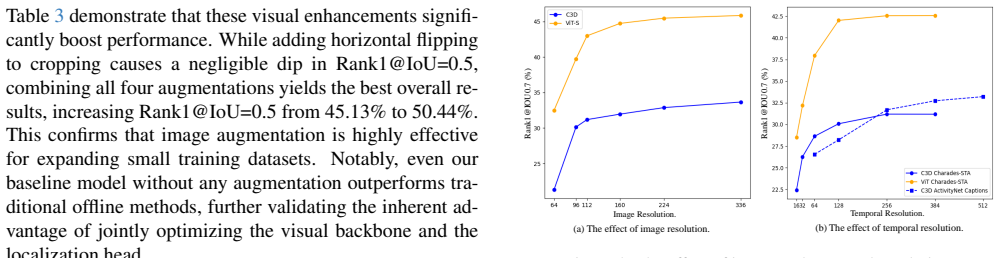
- [Empirical study and experiments section] The empirical study validating end-to-end learning (mentioned in the abstract and presumably detailed in the experiments section) reports benchmark gains but provides no information on statistical significance testing, variance across runs, or full ablation controls isolating the contribution of joint backbone optimization versus the SCADA adapter alone; this weakens support for the central claim that the paradigm shift is effective across model scales.
- [SCADA introduction and method] The description of SCADA (abstract and method) claims it modulates feature maps through precise integration of linguistic embeddings while training only a small portion of parameters, yet no explicit formulation, pseudocode, or memory analysis is referenced to confirm it avoids overfitting or enables the stated deeper backbones; this is load-bearing for the weakest assumption identified in the review.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the empirical validation and methodological clarity of our work on fully end-to-end training for temporal sentence grounding. We address each major comment below and will incorporate revisions to provide additional statistical details, expanded ablations, and explicit SCADA documentation.
read point-by-point responses
-
Referee: The empirical study validating end-to-end learning (mentioned in the abstract and presumably detailed in the experiments section) reports benchmark gains but provides no information on statistical significance testing, variance across runs, or full ablation controls isolating the contribution of joint backbone optimization versus the SCADA adapter alone; this weakens support for the central claim that the paradigm shift is effective across model scales.
Authors: We agree that reporting variance, statistical significance, and more targeted ablations would provide stronger support for the claims. In the revised manuscript, we will add results from multiple independent runs (reporting mean and standard deviation), paired t-tests for significance on key gains, and expanded ablation tables that separately quantify the contribution of joint backbone optimization versus the SCADA adapter across model scales. The existing study already demonstrates consistent improvements over frozen baselines, but these additions will address the noted gaps directly. revision: yes
-
Referee: The description of SCADA (abstract and method) claims it modulates feature maps through precise integration of linguistic embeddings while training only a small portion of parameters, yet no explicit formulation, pseudocode, or memory analysis is referenced to confirm it avoids overfitting or enables the stated deeper backbones; this is load-bearing for the weakest assumption identified in the review.
Authors: Section 3.2 of the manuscript provides the mathematical formulation for SCADA's sentence-conditioned modulation of feature maps. To further clarify, the revision will include pseudocode for the adapter integration, a quantitative memory analysis (comparing trainable parameters and peak GPU usage against full fine-tuning), and explicit discussion of how the low parameter count reduces overfitting risk while supporting deeper backbones. These additions will make the implementation details self-contained. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances a fully end-to-end training paradigm for temporal sentence grounding, backed by an empirical study of end-to-end vs. frozen backbones across scales and by benchmark results showing gains from the SCADA adapter. No derivation chain, equations, or first-principles claims appear that reduce to fitted inputs or self-citations by construction. The method is presented as a practical design choice whose value is measured externally via experiments, not internally forced by its own definitions or prior self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained visual encoders are query-agnostic and induce task discrepancy when used frozen for grounding
invented entities (1)
-
Sentence Conditioned Adapter (SCADA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Quo vadis, action recognition? A new model and the kinetics dataset
Jo ˜ao Carreira and Andrew Zisserman. Quo vadis, action recognition? A new model and the kinetics dataset. InCVPR, pages 4724–4733, 2017. 3, 6
work page 2017
-
[2]
Temporally grounding natural sentence in video
Jingyuan Chen, Xinpeng Chen, Lin Ma, Zequn Jie, and Tat- Seng Chua. Temporally grounding natural sentence in video. InEMNLP, pages 162–171, 2018. 2
work page 2018
-
[3]
Plugmark: A plug- in zero-watermarking framework for diffusion models
Pengzhen Chen, Yanwei Liu, Xiaoyan Gu, Enci Liu, Zhuoyi Shang, Xiangyang Ji, and Wu Liu. Plugmark: A plug- in zero-watermarking framework for diffusion models. In ICCV, pages 17335–17345, 2025
work page 2025
-
[4]
MAPLE: masked pseudo- labeling autoencoder for semi-supervised point cloud action recognition
Xiaodong Chen, Wu Liu, Xinchen Liu, Yongdong Zhang, Jungong Han, and Tao Mei. MAPLE: masked pseudo- labeling autoencoder for semi-supervised point cloud action recognition. InACM Multimedia, pages 708–718, 2022. 2
work page 2022
-
[5]
Mevis: A large-scale benchmark for video segmentation with motion expressions
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, and Chen Change Loy. Mevis: A large-scale benchmark for video segmentation with motion expressions. InICCV, pages 2694–2703, 2023. 2
work page 2023
-
[6]
Mose: A new dataset for video object segmentation in complex scenes
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, Philip HS Torr, and Song Bai. Mose: A new dataset for video object segmentation in complex scenes. InICCV, pages 20224–20234, 2023. 2
work page 2023
-
[7]
Mevis: A multi-modal dataset for referring motion expres- sion video segmentation.IEEE TPAMI, 2025
Henghui Ding, Chang Liu, Shuting He, Kaining Ying, Xudong Jiang, Chen Change Loy, and Yu-Gang Jiang. Mevis: A multi-modal dataset for referring motion expres- sion video segmentation.IEEE TPAMI, 2025. 2
work page 2025
-
[8]
Multimodal referring segmentation: A survey.arXiv preprint arXiv:2508.00265, 2025
Henghui Ding, Song Tang, Shuting He, Chang Liu, Zuxuan Wu, and Yu-Gang Jiang. Multimodal referring segmentation: A survey.arXiv preprint arXiv:2508.00265, 2025. 2
-
[9]
Henghui Ding, Kaining Ying, Chang Liu, Shuting He, Xudong Jiang, Yu-Gang Jiang, Philip HS Torr, and Song Bai. Mosev2: A more challenging dataset for video object segmentation in complex scenes.arXiv preprint arXiv:2508.05630, 2025. 2
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 6
work page 2021
-
[11]
Heterogeneous memory en- hanced multimodal attention model for video question an- swering
Chenyou Fan, Xiaofan Zhang, Shu Zhang, Wensheng Wang, Chi Zhang, and Heng Huang. Heterogeneous memory en- hanced multimodal attention model for video question an- swering. InCVPR, pages 1999–2007, 2019. 1
work page 1999
-
[12]
Ac- tom sequence models for efficient action detection
Adrien Gaidon, Za ¨ıd Harchaoui, and Cordelia Schmid. Ac- tom sequence models for efficient action detection. InCVPR, pages 3201–3208, 2011. 2
work page 2011
-
[13]
TALL: temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. TALL: temporal activity localization via language query. In ICCV, pages 5277–5285, 2017. 1, 2, 4, 5
work page 2017
-
[14]
Relation-aware video reading comprehension for temporal language grounding
Jialin Gao, Xin Sun, Mengmeng Xu, Xi Zhou, and Bernard Ghanem. Relation-aware video reading comprehension for temporal language grounding. InEMNLP (1), pages 3978– 3988, 2021. 2
work page 2021
-
[15]
MAC: mining activity concepts for language-based tempo- ral localization
Runzhou Ge, Jiyang Gao, Kan Chen, and Ram Nevatia. MAC: mining activity concepts for language-based tempo- ral localization. InWACV, pages 245–253, 2019. 2
work page 2019
- [16]
-
[17]
Vtg-llm: Integrating timestamp knowl- edge into video llms for enhanced video temporal grounding,
Yongxin Guo, Jingyu Liu, Mingda Li, Xiaoying Tang, Xi Chen, and Bo Zhao. VTG-LLM: integrating timestamp knowledge into video llms for enhanced video temporal grounding.CoRR, abs/2405.13382, 2024. 2
-
[18]
TRACE: temporal grounding video LLM via causal event modeling
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang. TRACE: temporal grounding video LLM via causal event modeling. InICLR, 2025. 5
work page 2025
-
[19]
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan C. Russell. Localizing mo- ments in video with natural language. InICCV, pages 5804– 5813, 2017. 1, 2
work page 2017
-
[20]
Vtimellm: Empower LLM to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower LLM to grasp video moments. CoRR, abs/2311.18445, 2023. 2
-
[21]
Lita: Language instructed temporal-localization assistant,
De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. LITA: language instructed temporal-localization assistant. CoRR, abs/2403.19046, 2024. 2
-
[22]
Cross- modal video moment retrieval with spatial and language- temporal attention
Bin Jiang, Xin Huang, Chao Yang, and Junsong Yuan. Cross- modal video moment retrieval with spatial and language- temporal attention. InICMR, pages 217–225, 2019. 2
work page 2019
-
[23]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In ICCV, pages 706–715, 2017. 4
work page 2017
-
[24]
G2L: semantically aligned and uniform video grounding via geodesic and game theory
Hongxiang Li, Meng Cao, Xuxin Cheng, Yaowei Li, Zhi- hong Zhu, and Yuexian Zou. G2L: semantically aligned and uniform video grounding via geodesic and game theory. In ICCV, pages 11998–12008, 2023. 5
work page 2023
-
[25]
Proposal-free video grounding with contextual pyramid network
Kun Li, Dan Guo, and Meng Wang. Proposal-free video grounding with contextual pyramid network. InAAAI, pages 1902–1910, 2021. 2
work page 1902
-
[26]
Single shot tem- poral action detection
Tianwei Lin, Xu Zhao, and Zheng Shou. Single shot tem- poral action detection. InACM Multimedia, pages 988–996,
-
[27]
BMN: boundary-matching network for temporal action pro- posal generation
Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, and Shilei Wen. BMN: boundary-matching network for temporal action pro- posal generation. InICCV, pages 3888–3897, 2019. 4
work page 2019
-
[28]
Moment retrieval via cross-modal interaction networks with query reconstruction.IEEE Trans
Zhijie Lin, Zhou Zhao, Zhu Zhang, Zijian Zhang, and Deng Cai. Moment retrieval via cross-modal interaction networks with query reconstruction.IEEE Trans. Image Process., 29: 3750–3762, 2020. 2
work page 2020
-
[29]
Adaptive proposal generation network for temporal sentence localization in videos
Daizong Liu, Xiaoye Qu, Jianfeng Dong, and Pan Zhou. Adaptive proposal generation network for temporal sentence localization in videos. InEMNLP (1), pages 9292–9301,
-
[30]
Context-aware biaffine localizing network for temporal sentence grounding
Daizong Liu, Xiaoye Qu, Jianfeng Dong, Pan Zhou, Yu Cheng, Wei Wei, Zichuan Xu, and Yulai Xie. Context-aware biaffine localizing network for temporal sentence grounding. InCVPR, pages 11235–11244, 2021. 2
work page 2021
-
[31]
Progressively guide to attend: An iterative alignment framework for tem- poral sentence grounding
Daizong Liu, Xiaoye Qu, and Pan Zhou. Progressively guide to attend: An iterative alignment framework for tem- poral sentence grounding. InEMNLP (1), pages 9302–9311, 2021
work page 2021
-
[32]
Memory-guided semantic learning network for temporal sentence grounding
Daizong Liu, Xiaoye Qu, Xing Di, Yu Cheng, Zichuan Xu, and Pan Zhou. Memory-guided semantic learning network for temporal sentence grounding. InAAAI, pages 1665– 1673, 2022. 2
work page 2022
-
[33]
Single-frame supervision for spatio-temporal video grounding.IEEE TPAMI, 47(7):5177– 5191, 2024
Kun Liu, Mengxue Qu, Yang Liu, Yunchao Wei, Wenming Zhe, Yao Zhao, and Wu Liu. Single-frame supervision for spatio-temporal video grounding.IEEE TPAMI, 47(7):5177– 5191, 2024. 2
work page 2024
-
[34]
Attentive moment retrieval in videos
Meng Liu, Xiang Wang, Liqiang Nie, Xiangnan He, Bao- quan Chen, and Tat-Seng Chua. Attentive moment retrieval in videos. InSIGIR, pages 15–24, 2018. 1, 2
work page 2018
-
[35]
Qi Liu, Xinchen Liu, Kun Liu, Xiaoyan Gu, and Wu Liu. Sigformer: Sparse signal-guided transformer for multi- modal action segmentation.ACM ToMM, 20(8):1–22, 2024. 2
work page 2024
-
[36]
ETAD: training action detection end to end on a laptop
Shuming Liu, Mengmeng Xu, Chen Zhao, Xu Zhao, and Bernard Ghanem. ETAD: training action detection end to end on a laptop. InCVPR Workshops, pages 4525–4534,
-
[37]
End-to-end temporal action detection with 1b pa- rameters across 1000 frames
Shuming Liu, Chen-Lin Zhang, Chen Zhao, and Bernard Ghanem. End-to-end temporal action detection with 1b pa- rameters across 1000 frames. InCVPR, 2024. 2
work page 2024
-
[38]
Vehicle retrieval and trajectory inference in urban traffic surveillance scene
Xinchen Liu, Huadong Ma, Huiyuan Fu, and Mo Zhou. Vehicle retrieval and trajectory inference in urban traffic surveillance scene. InICDSC, pages 26:1–26:6, 2014. 2
work page 2014
-
[39]
An empirical study of end-to-end temporal action detection
Xiaolong Liu, Song Bai, and Xiang Bai. An empirical study of end-to-end temporal action detection. InCVPR, pages 19978–19987, 2022. 2
work page 2022
-
[40]
End-to-end temporal ac- tion detection with transformer.IEEE Trans
Xiaolong Liu, Qimeng Wang, Yao Hu, Xu Tang, Shiwei Zhang, Song Bai, and Xiang Bai. End-to-end temporal ac- tion detection with transformer.IEEE Trans. Image Process., 31:5427–5441, 2022. 2
work page 2022
-
[41]
DEBUG: A dense bottom-up grounding approach for natural language video localization
Chujie Lu, Long Chen, Chilie Tan, Xiaolin Li, and Jun Xiao. DEBUG: A dense bottom-up grounding approach for natural language video localization. InEMNLP/IJCNLP (1), pages 5143–5152, 2019. 2
work page 2019
-
[42]
Zero-shot video grounding with pseudo query lookup and verification
Yu Lu, Ruijie Quan, Linchao Zhu, and Yi Yang. Zero-shot video grounding with pseudo query lookup and verification. IEEE Trans. Image Process., 33:1643–1654, 2024. 2
work page 2024
-
[43]
Humannerf-se: A simple yet effec- tive approach to animate humannerf with diverse poses
Caoyuan Ma, Yu-Lun Liu, Zhixiang Wang, Wu Liu, Xinchen Liu, and Zheng Wang. Humannerf-se: A simple yet effec- tive approach to animate humannerf with diverse poses. In CVPR, pages 1460–1470, 2024. 2
work page 2024
-
[44]
Interaction-integrated network for natural language moment localization.IEEE Trans
Ke Ning, Lingxi Xie, Jianzhuang Liu, Fei Wu, and Qi Tian. Interaction-integrated network for natural language moment localization.IEEE Trans. Image Process., 30:2538–2548, 2021
work page 2021
-
[45]
Cristian Rodriguez Opazo, Edison Marrese-Taylor, Fate- meh Sadat Saleh, Hongdong Li, and Stephen Gould. Proposal-free temporal moment localization of a natural- language query in video using guided attention. InWACV, pages 2453–2462, 2020. 2
work page 2020
-
[46]
Video captioning with transferred semantic attributes
Yingwei Pan, Ting Yao, Houqiang Li, and Tao Mei. Video captioning with transferred semantic attributes. InCVPR, pages 984–992, 2017. 1
work page 2017
-
[47]
Automatic differentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Al- ban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. InNeurIPS Workshop, 2017. 5
work page 2017
-
[48]
Momentor: Ad- vancing video large language model with fine-grained temporal reasoning,
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat- Seng Chua, Yueting Zhuang, and Siliang Tang. Momen- tor: Advancing video large language model with fine-grained temporal reasoning.CoRR, abs/2402.11435, 2024. 2, 5
-
[49]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding.CoRR, abs/2312.02051,
-
[50]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter.CoRR, abs/1910.01108,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[51]
Temporal action localization in untrimmed videos via multi-stage cnns
Zheng Shou, Dongang Wang, and Shih-Fu Chang. Temporal action localization in untrimmed videos via multi-stage cnns. InCVPR, pages 1049–1058, 2016. 2
work page 2016
-
[52]
Sigurdsson, G ¨ul Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta
Gunnar A. Sigurdsson, G ¨ul Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity under- standing. InECCV (1), pages 510–526, 2016. 4
work page 2016
-
[53]
V AL: visual-attention ac- tion localizer
Xiaomeng Song and Yahong Han. V AL: visual-attention ac- tion localizer. InPCM (2), pages 340–350, 2018. 2
work page 2018
-
[54]
You need to read again: Multi-granularity perception net- work for moment retrieval in videos
Xin Sun, Xuan Wang, Jialin Gao, Qiong Liu, and Xi Zhou. You need to read again: Multi-granularity perception net- work for moment retrieval in videos. InSIGIR, pages 1022– 1032, 2022. 2, 5
work page 2022
-
[55]
Bourdev, Rob Fergus, Lorenzo Torre- sani, and Manohar Paluri
Du Tran, Lubomir D. Bourdev, Rob Fergus, Lorenzo Torre- sani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. InICCV, pages 4489–4497,
-
[56]
Structured multi-level interaction network for video moment localization via language query
Hao Wang, Zheng-Jun Zha, Liang Li, Dong Liu, and Jiebo Luo. Structured multi-level interaction network for video moment localization via language query. InCVPR, pages 7026–7035, 2021. 2
work page 2021
-
[57]
Tempo- rally grounding language queries in videos by contextual boundary-aware prediction
Jingwen Wang, Lin Ma, and Wenhao Jiang. Tempo- rally grounding language queries in videos by contextual boundary-aware prediction. InAAAI, pages 12168–12175,
-
[58]
Videomae V2: scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yi- nan He, Yi Wang, Yali Wang, and Yu Qiao. Videomae V2: scaling video masked autoencoders with dual masking. In CVPR, pages 14549–14560, 2023. 3, 6
work page 2023
-
[59]
Internvideo: General video foundation models via generative and discriminative learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning.CoRR, abs/2212.03191, 2022. 2
-
[60]
Hawkeye: Training video-text llms for grounding text in videos,
Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. Hawkeye: Training video-text llms for grounding text in videos.CoRR, abs/2403.10228,
-
[61]
Negative sample matters: A renaissance of metric learning for temporal grounding
Zhenzhi Wang, Limin Wang, Tao Wu, Tianhao Li, and Gang- shan Wu. Negative sample matters: A renaissance of metric learning for temporal grounding. InAAAI, pages 2613–2623,
-
[62]
Boundary proposal network for two-stage natural language video localization
Shaoning Xiao, Long Chen, Songyang Zhang, Wei Ji, Jian Shao, Lu Ye, and Jun Xiao. Boundary proposal network for two-stage natural language video localization. InAAAI, pages 2986–2994, 2021. 2
work page 2021
-
[63]
Video question answer- ing via gradually refined attention over appearance and mo- tion
Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video question answer- ing via gradually refined attention over appearance and mo- tion. InACM Multimedia, pages 1645–1653, 2017. 1
work page 2017
-
[64]
R-C3D: region convolutional 3d network for temporal activity detection
Huijuan Xu, Abir Das, and Kate Saenko. R-C3D: region convolutional 3d network for temporal activity detection. In ICCV, pages 5794–5803, 2017. 2
work page 2017
-
[65]
Learning multimodal attention LSTM networks for video captioning
Jun Xu, Ting Yao, Yongdong Zhang, and Tao Mei. Learning multimodal attention LSTM networks for video captioning. InACM Multimedia, pages 537–545, 2017. 1
work page 2017
-
[66]
Shuo Yang and Xinxiao Wu. Entity-aware and motion- aware transformers for language-driven action localization in videos.CoRR, abs/2205.05854, 2022. 2
-
[67]
Shuo Yang, Xinxiao Wu, Zirui Shang, and Jiebo Luo. Dy- namic pathway for query-aware feature learning in language- driven action localization.IEEE Trans. Multim., 26:7451– 7461, 2024. 5
work page 2024
-
[68]
Shuo Yang, Xinxiao Wu, Zirui Shang, and Jiebo Luo. Dy- namic pathway for query-aware feature learning in language- driven action localization.IEEE Trans. Multim., 26:7451– 7461, 2024. 2
work page 2024
-
[69]
Yitian Yuan, Tao Mei, and Wenwu Zhu. To find where you talk: Temporal sentence localization in video with attention based location regression. InAAAI, pages 9159–9166, 2019. 2
work page 2019
-
[70]
Dense regression network for video grounding
Runhao Zeng, Haoming Xu, Wenbing Huang, Peihao Chen, Mingkui Tan, and Chuang Gan. Dense regression network for video grounding. InCVPR, pages 10284–10293, 2020. 2
work page 2020
-
[71]
Factorized learning for temporally grounded video-language models
Wenzheng Zeng, Difei Gao, Mike Zheng Shou, and Hwee Tou Ng. Factorized learning for temporally grounded video-language models. InICCV, pages 20683–20693,
-
[72]
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lu- cas Beyer. Scaling vision transformers. InCVPR, pages 1204–1213, 2022. 6
work page 2022
-
[73]
Span-based localizing network for natural language video lo- calization
Hao Zhang, Aixin Sun, Wei Jing, and Joey Tianyi Zhou. Span-based localizing network for natural language video lo- calization. InACL, pages 6543–6554, 2020. 5
work page 2020
-
[74]
Exploiting temporal relationships in video moment localization with natural language
Songyang Zhang, Jinsong Su, and Jiebo Luo. Exploiting temporal relationships in video moment localization with natural language. InACM Multimedia, pages 1230–1238,
-
[75]
Learning 2d temporal adjacent networks for moment local- ization with natural language
Songyang Zhang, Houwen Peng, Jianlong Fu, and Jiebo Luo. Learning 2d temporal adjacent networks for moment local- ization with natural language. InAAAI, pages 12870–12877,
-
[76]
Multi-scale 2d temporal adjacency networks for moment localization with natural language.IEEE Trans
Songyang Zhang, Houwen Peng, Jianlong Fu, Yijuan Lu, and Jiebo Luo. Multi-scale 2d temporal adjacency networks for moment localization with natural language.IEEE Trans. Pattern Anal. Mach. Intell., 44(12):9073–9087, 2022. 2, 4, 5
work page 2022
-
[77]
Text-visual prompting for efficient 2d temporal video grounding
Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, and Ke Ding. Text-visual prompting for efficient 2d temporal video grounding. InCVPR, pages 14794–14804, 2023. 2
work page 2023
-
[78]
Videoexpert: Augmented LLM for temporal- sensitive video understanding.CoRR, abs/2504.07519, 2025
Henghao Zhao, Ge-Peng Ji, Rui Yan, Huan Xiong, and Zechao Li. Videoexpert: Augmented LLM for temporal- sensitive video understanding.CoRR, abs/2504.07519, 2025. 5
-
[79]
Temporal action detection with structured segment networks.Int
Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xi- aoou Tang, and Dahua Lin. Temporal action detection with structured segment networks.Int. J. Comput. Vis., 128(1): 74–95, 2020. 2
work page 2020
-
[80]
Cas- caded prediction network via segment tree for temporal video grounding
Yang Zhao, Zhou Zhao, Zhu Zhang, and Zhijie Lin. Cas- caded prediction network via segment tree for temporal video grounding. InCVPR, pages 4197–4206, 2021. 2, 5
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.