Recognition: 2 theorem links
· Lean TheoremToken Warping Helps MLLMs Look from Nearby Viewpoints
Pith reviewed 2026-05-13 21:04 UTC · model grok-4.3
The pith
Warping tokens rather than pixels enables multimodal large language models to reason reliably from nearby viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
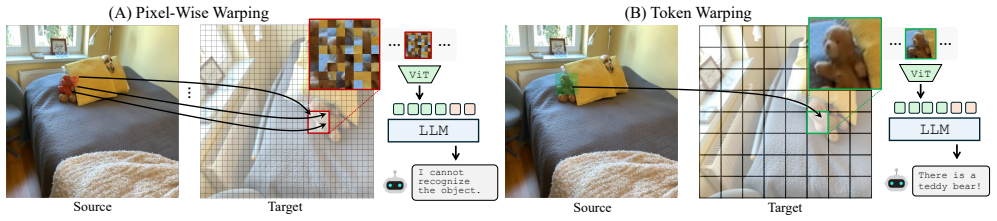
Backward token warping defines a dense grid on the target viewpoint and retrieves the corresponding source-view token for each grid point, supplying the MLLM with a viewpoint-shifted token map that preserves semantic coherence without the distortions introduced by pixel-level operations.
What carries the argument
Backward token warping on ViT image tokens, which maps each point in a target-view grid back to its matching token in the source view to create a coherent warped representation.
If this is right
- MLLMs can handle small viewpoint changes without retraining or pixel-level editing.
- Backward token warping maintains semantic coherence better than pixel warping or generative alternatives.
- The same token-warping step works across different ViT-based MLLM architectures.
- ViewBench provides a concrete testbed for measuring viewpoint robustness in multimodal models.
Where Pith is reading between the lines
- ViT tokens may already encode enough part structure to support simple mental-rotation operations inside language models.
- Chaining multiple small warps could extend the method to moderately larger viewpoint differences.
- Robotics and augmented-reality systems that need quick viewpoint-invariant descriptions could adopt token warping as a lightweight preprocessing step.
Load-bearing premise
Image tokens produced by the vision transformer correspond to part-level structural representations that can be warped to simulate viewpoint changes.
What would settle it
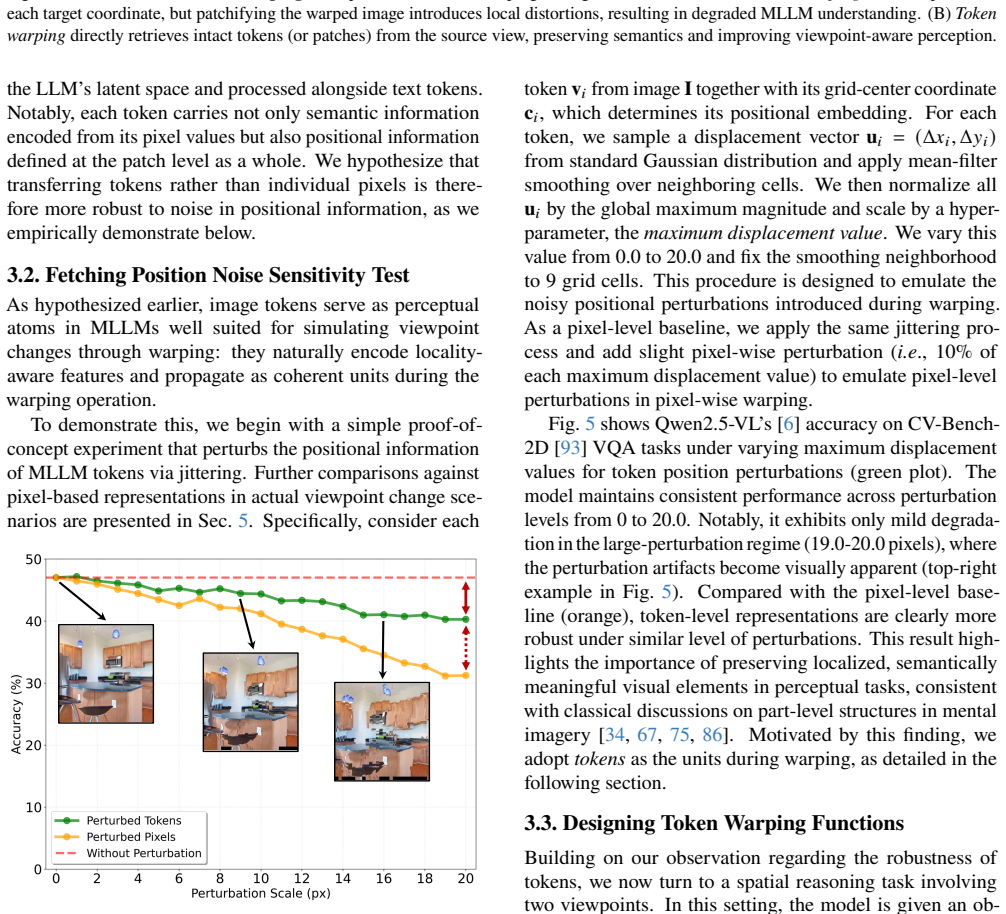
A direct comparison on ViewBench where token warping produces no gain or lower accuracy than pixel warping once viewpoint shifts introduce noticeable occlusions or depth errors.
Figures





read the original abstract
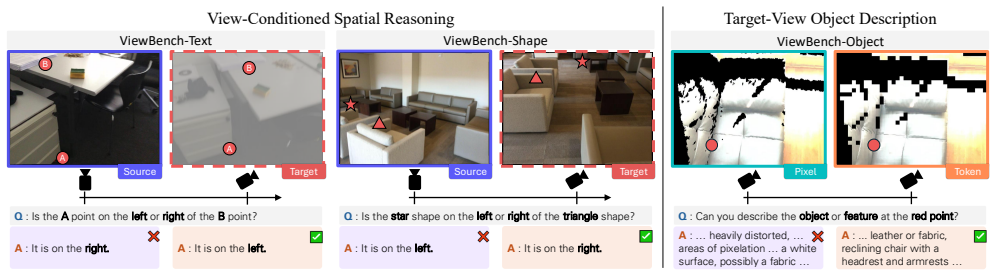
Can warping tokens, rather than pixels, help multimodal large language models (MLLMs) understand how a scene appears from a nearby viewpoint? While MLLMs perform well on visual reasoning, they remain fragile to viewpoint changes, as pixel-wise warping is highly sensitive to small depth errors and often introduces geometric distortions. Drawing on theories of mental imagery that posit part-level structural representations as the basis for human perspective transformation, we examine whether image tokens in ViT-based MLLMs serve as an effective substrate for viewpoint changes. We compare forward and backward warping, finding that backward token warping, which defines a dense grid on the target view and retrieves a corresponding source-view token for each grid point, achieves greater stability and better preserves semantic coherence under viewpoint shifts. Experiments on our proposed ViewBench benchmark demonstrate that token-level warping enables MLLMs to reason reliably from nearby viewpoints, consistently outperforming all baselines including pixel-wise warping approaches, spatially fine-tuned MLLMs, and a generative warping method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that backward token warping on ViT image tokens allows MLLMs to better reason about scenes from nearby viewpoints compared to pixel warping and other baselines. It introduces the ViewBench benchmark and reports consistent outperformance, attributing this to the tokens serving as part-level structural representations inspired by mental imagery theories.
Significance. Should the findings be substantiated with detailed metrics and controls, this could represent a meaningful advance in making MLLMs more robust to viewpoint variations through efficient token manipulation rather than retraining or pixel-level operations.
major comments (2)
- [Abstract and Experiments] The abstract states that token-level warping 'consistently outperforming all baselines' on ViewBench, but no specific accuracy numbers, standard deviations, or details on the benchmark construction (e.g., number of scenes, viewpoint shifts) are provided, which is load-bearing for assessing the central empirical claim.
- [Theoretical Motivation] The link to mental imagery theories posits part-level representations in tokens, but the manuscript does not include any analysis or ablation showing that the warped tokens maintain part consistency across views; this leaves the interpretation open to alternative explanations such as embedding-space robustness.
minor comments (1)
- [Notation] Clarify the exact definition of forward vs backward warping in the methods section, as the distinction is central but described only at high level in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] The abstract states that token-level warping 'consistently outperforming all baselines' on ViewBench, but no specific accuracy numbers, standard deviations, or details on the benchmark construction (e.g., number of scenes, viewpoint shifts) are provided, which is load-bearing for assessing the central empirical claim.
Authors: We agree that the abstract would be strengthened by including concrete quantitative details. The experimental section already reports accuracy numbers, standard deviations, and full benchmark construction details (including scene count and viewpoint shift ranges). We have revised the abstract to summarize the key performance metrics and benchmark scale for improved readability while preserving its concise nature. revision: yes
-
Referee: [Theoretical Motivation] The link to mental imagery theories posits part-level representations in tokens, but the manuscript does not include any analysis or ablation showing that the warped tokens maintain part consistency across views; this leaves the interpretation open to alternative explanations such as embedding-space robustness.
Authors: This observation is fair and highlights an opportunity to better support the theoretical framing. While the empirical gains in semantic coherence are shown through end-task performance, we have added a targeted ablation in the revised manuscript that quantifies part-level token consistency across warped views (via cross-view feature alignment metrics), helping differentiate the part-structure hypothesis from general embedding robustness. revision: yes
Circularity Check
No circularity: purely empirical comparison with independent baselines
full rationale
The paper presents a method (backward token warping on ViT tokens) and evaluates it empirically on the newly proposed ViewBench benchmark against multiple external baselines (pixel-wise warping, spatially fine-tuned MLLMs, generative warping). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on experimental outperformance rather than any reduction to prior self-defined quantities. The mental-imagery reference is an external citation, not a load-bearing self-citation. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearDrawing on theories of mental imagery that posit part-level structural representations as the basis for human perspective transformation, we examine whether image tokens in ViT-based MLLMs serve as an effective substrate for viewpoint changes.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe compare forward and backward warping, finding that backward token warping... achieves greater stability and better preserves semantic coherence under viewpoint shifts.
Reference graph
Works this paper leans on
-
[1]
Remyx AI. Spaceqwen2.5-vl-3b-instruct. https:// huggingface.co/remyxai/SpaceQwen2.5-VL- 3B-Instruct, 2025. 15
work page 2025
-
[2]
Remyx AI. Spacethinker-qwen2.5vl-3b. https : / / huggingface . co / remyxai / SpaceThinker - Qwen2.5VL-3B, 2025. 15
work page 2025
- [3]
-
[4]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
XiangAn,YinXie,KaichengYang,WenkangZhang,Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen,ChunshengWu,etal. Llava-onevision-1.5: Fullyopen framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025. 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Scanqa: 3d question answering for spatial scene understanding
DaichiAzuma,TaikiMiyanishi,ShuheiKurita,andMotoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. InCVPR, 2022. 3
work page 2022
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 4, 6, 7, 8, 15, 16, 17, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Yunpeng Bai, Haoxiang Li, and Qixing Huang. Positional encoding field. InICLR, 2026. 3
work page 2026
-
[8]
Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, et al. Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. InNeurIPS, 2021. 18
work page 2021
-
[9]
Perception tokens enhance visual reasoning in multimodal language models
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G Shapiro, and Ranjay Krishna. Perception tokens enhance visual reasoning in multimodal language models. InCVPR, 2025. 3
work page 2025
-
[10]
Depth pro: Sharp monocular metric depth in less than a second
Aleksei Bochkovskii, AmaÃG, l Delaunoy, Hugo Germain, MarcelSantos,YichaoZhou,StephanRRichter,andVladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InICLR, 2025. 1, 15
work page 2025
-
[11]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. InICRA, 2025. 2
work page 2025
-
[12]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. InCVPR, 2024. 2, 15, 16
work page 2024
-
[13]
Subobject-levelimagetokenization
Delong Chen, Samuel Cahyawijaya, Jianfeng Liu, Baoyuan Wang,andPascaleFung. Subobject-levelimagetokenization. InICML, 2025. 3
work page 2025
-
[14]
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. InCVPR, 2024. 2
work page 2024
-
[15]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagina- tion grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025. 1, 3
-
[16]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. InNeurIPS, 2024. 2
work page 2024
-
[17]
3d aware region prompted vision language model
An-Chieh Cheng, Yang Fu, Yukang Chen, Zhijian Liu, Xiaolong Li, Subhashree Radhakrishnan, Song Han, Yao Lu, Jan Kautz, Pavlo Molchanov, et al. 3d aware region prompted vision language model. InICLR, 2026. 2
work page 2026
-
[18]
Accelerating Vision Transformers with Adaptive Patch Sizes
Rohan Choudhury, JungEun Kim, Jinhyung Park, Eunho Yang, László A Jeni, and Kris M Kitani. Accelerating visiontransformerswithadaptivepatchsizes.arXivpreprint arXiv:2510.18091, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Scannet: Richly- annotated 3d reconstructions of indoor scenes
AngelaDai,AngelX.Chang,ManolisSavva,MaciejHalber, ThomasFunkhouser,andMatthiasNießner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InCVPR,
-
[20]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. In ICCV, 2025. 2
work page 2025
-
[21]
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. InNeurIPS, 2022. Outstanding Paper Award. 16, 17
work page 2022
-
[22]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
MattDeitke,ChristopherClark,SanghoLee,RohunTripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InCVPR, 2025. 2
work page 2025
-
[23]
3d-llava: Towardsgeneralist3dlmms with omni superpoint transformer
Jiajun Deng, Tianyu He, Li Jiang, Tianyu Wang, Feras Dayoub,andIanReid. 3d-llava: Towardsgeneralist3dlmms with omni superpoint transformer. InCVPR, 2025. 2
work page 2025
-
[24]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 2, 3
work page 2021
-
[25]
Palm-e: anembodiedmultimodallanguagemodel
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: anembodiedmultimodallanguagemodel. InICML,2023. 2
work page 2023
-
[26]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmentedwithinstruction-aligned3dreconstruction.arXiv preprint arXiv:2505.20279, 2025. 1, 2, 3, 6, 8, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
A., Tihanyi, N., and Debbah, M
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678,
- [28]
-
[29]
Scene-llm: Extending language model for 3d visual reasoning
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual reasoning. InWACV, 2025. 2
work page 2025
-
[30]
Blink: Multimodal large language models can see but not perceive
XingyuFu,YushiHu,BangzhengLi,YuFeng,HaoyuWang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InECCV, 2024. 2, 19
work page 2024
-
[31]
Tokenflow: Con- sistent diffusion features for consistent video editing,
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistentdiffusionfeaturesforconsistentvideo editing.arXiv preprint arXiv:2307.10373, 2023. 3
-
[32]
Gracjan Góral, Alicja Ziarko, Michal Nauman, and Maciej Wołczyk. Seeing through their eyes: Evaluating visual perspectivetakinginvisionlanguagemodels.arXivpreprint arXiv:2409.12969, 2024. 3
-
[33]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Geoffrey Hinton. Some demonstrations of the effects of structuraldescriptionsinmentalimagery.CognitiveScience, 3(3):231–250, 1979. 1, 2, 3, 4, 8
work page 1979
-
[35]
3d-llm: Inject- ing the 3d world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Inject- ing the 3d world into large language models. InNeurIPS,
-
[36]
3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model
Wenbo Hu, Yining Hong, Yanjun Wang, Leison Gao, Zibu Wei, Xingcheng Yao, Nanyun Peng, Yonatan Bitton, Idan Szpektor, and Kai-Wei Chang. 3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model. InNeurIPS, 2025. 2
work page 2025
-
[37]
An embodied generalist agent in 3d world
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. InICML, 2024. 2
work page 2024
-
[38]
Ting Huang, Zeyu Zhang, and Hao Tang. 3d-r1: Enhancing reasoning in 3d vlms for unified scene understanding.arXiv preprint arXiv:2507.23478, 2025. 2
-
[39]
Mllms need 3d-aware representation supervision for scene understanding
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. Mllms need 3d-aware representation supervision for scene understanding. InNeurIPS, 2025. 2
work page 2025
-
[40]
Robobrain: Aunifiedbrainmodel forroboticmanipulationfromabstracttoconcrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, YaoMu,PengjuAn,etal. Robobrain: Aunifiedbrainmodel forroboticmanipulationfromabstracttoconcrete. InCVPR,
-
[41]
Region- aware pretraining for open-vocabulary object detection with vision transformers
Dahun Kim, Anelia Angelova, and Weicheng Kuo. Region- aware pretraining for open-vocabulary object detection with vision transformers. InCVPR, 2023. 3
work page 2023
-
[42]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InICCV, 2023. 3
work page 2023
-
[43]
Videohandles: Editing 3d object com- positions in videos using video generative priors
JuilKoo, PaulGuerrero,Chun-HaoPHuang, DuyguCeylan, and Minhyuk Sung. Videohandles: Editing 3d object com- positions in videos using video generative priors. InCVPR,
-
[44]
S. M. Kosslyn, T. M. Ball, and B. J. Reiser. Visual images preserve metric spatial information: Evidence from studies of image scanning.Journal of Experimental Psychology: Human Perception and Performance, 1978. 1
work page 1978
-
[45]
Black Forest Labs. Flux. https://github.com/ black-forest-labs/flux, 2024. 3
work page 2024
-
[46]
arXiv preprint arXiv:2508.07917 (2025) 1, 3, 9
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 3
-
[47]
Groundit: Grounding diffusion transformers via noisy patch transplan- tation
PhillipY.Lee,TaehoonYoon,andMinhyukSung. Groundit: Grounding diffusion transformers via noisy patch transplan- tation. InNeurIPS, 2024. 3
work page 2024
-
[48]
Lee, Jihyeon Je, Chanho Park, Mikaela Angelina Uy,LeonidasGuibas,andMinhyukSung
Phillip Y. Lee, Jihyeon Je, Chanho Park, Mikaela Angelina Uy,LeonidasGuibas,andMinhyukSung. Perspective-aware reasoning in vision-language models via mental imagery simulation. InICCV, 2025. 1, 3
work page 2025
-
[49]
Llava-onevision: Easy visual task transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. TMLR, 2025. 2
work page 2025
-
[50]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluating multi-perspective spatial localization in vision- language models.arXiv preprint arXiv:2505.21500, 2025. 3
-
[51]
Spatialladder: Progressive training for spatial reasoning in vision-language models
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models. In ICLR, 2025. 2, 15, 16
work page 2025
-
[52]
See&trek: Training-free spatial prompting for multimodal large lan- guage model
Pengteng Li, Pinhao Song, Wuyang Li, Weiyu Guo, Huizai Yao, Yijie Xu, Dugang Liu, and Hui Xiong. See&trek: Training-free spatial prompting for multimodal large lan- guage model. InNeurIPS, 2025. 2
work page 2025
-
[53]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InCVPR, 2023. 3
work page 2023
-
[54]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InCVPR, 2024. 19
work page 2024
-
[55]
The 3d-pc: a benchmark for visual perspective taking in humans and machines
Drew Linsley, Peisen Zhou, Alekh Karkada Ashok, Akash Nagaraj, Gaurav Gaonkar, Francis E Lewis, Zygmunt Pizlo, and Thomas Serre. The 3d-pc: a benchmark for visual perspective taking in humans and machines. InICLR, 2025. 3
work page 2025
-
[56]
HaotianLiu, ChunyuanLi, QingyangWu, andYongJaeLee. Visual instruction tuning. InNeurIPS, 2023. 3
work page 2023
-
[57]
YuechengLiu,DafengChi,ShiguangWu,ZhanguangZhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spatialcot: Advancing spatial reasoning through coordinate alignment and chain- of-thought for embodied task planning.arXiv preprint arXiv:2501.10074, 2025. 2
-
[58]
Visual embodied brain: Let multimodal large language models see, think, and control in spaces
Gen Luo, Ganlin Yang, Ziyang Gong, Guanzhou Chen, Hao- nan Duan, Erfei Cui, Ronglei Tong, Zhi Hou, Tianyi Zhang, Zhe Chen, et al. Visual embodied brain: Let multimodal large language models see, think, and control in spaces. arXiv preprint arXiv:2506.00123, 2025. 15, 16
-
[59]
Chenyang Ma, Kai Lu, Ta-Ying Cheng, Niki Trigoni, and Andrew Markham. Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors. InNeurIPS, 2024. 2
work page 2024
-
[60]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InICCV,
-
[61]
Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning
WufeiMa,Yu-ChengChou,QihaoLiu,XingruiWang,Celso de Melo, Jianwen Xie, and Alan Yuille. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning. In NeurIPS, 2025. 1, 2, 6, 8, 16
work page 2025
-
[62]
Spatialllm: A compound 3d-informed design towards spatially-intelligent large multimodal models
Wufei Ma, Luoxin Ye, Celso M de Melo, Alan Yuille, and Jieneng Chen. Spatialllm: A compound 3d-informed design towards spatially-intelligent large multimodal models. In CVPR, 2025. 2
work page 2025
-
[63]
Sqa3d: Situated question answering in 3d scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes. InICLR, 2022. 3
work page 2022
-
[64]
Bui Duc Manh, Soumyaratna Debnath, Zetong Zhang, Shri- ram Damodaran, Arvind Kumar, Yueyi Zhang, Lu Mi, Erik Cambria, and Lin Wang. Mind meets space: Rethinking agentic spatial intelligence from a neuroscience-inspired perspective.arXiv preprint arXiv:2509.09154, 2025. 3
-
[65]
Visual agentic ai for spatial reasoning with a dynamic api
Damiano Marsili, Rohun Agrawal, Yisong Yue, and Georgia Gkioxari. Visual agentic ai for spatial reasoning with a dynamic api. InCVPR, 2025. 2
work page 2025
-
[66]
Simple open-vocabulary object detection
Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, et al. Simple open-vocabulary object detection. In ECCV, 2022. 3
work page 2022
-
[67]
A framework for representing knowl- edge, 1974
Marvin Minsky et al. A framework for representing knowl- edge, 1974. 2, 3, 4, 8
work page 1974
-
[68]
Embodiedgpt: Vision-language pre-training via embodied chain of thought
Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought. InNeurIPS, 2023. 2
work page 2023
-
[69]
Mental imagery.The Stanford Encyclopedia of Philosophy, 2021
Bence Nanay. Mental imagery.The Stanford Encyclopedia of Philosophy, 2021. 1
work page 2021
-
[70]
Embodied arena: A comprehensive, unified, and evolving evaluation platform for embodied ai
Fei Ni, Min Zhang, Pengyi Li, Yifu Yuan, Lingfeng Zhang, Yuecheng Liu, Peilong Han, Longxin Kou, Shaojin Ma, Jinbin Qiao, et al. Embodied arena: A comprehensive, unified, and evolving evaluation platform for embodied ai. arXiv preprint arXiv:2509.15273, 2025. 3
-
[71]
Dinov2: Learningrobustvisualfeatureswithoutsupervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learningrobustvisualfeatureswithoutsupervision. TMLR, 2023. 3
work page 2023
-
[72]
Spacer: Rein- forcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcingmllmsinvideospatialreasoning.arXivpreprint arXiv:2504.01805, 2025. 2, 15, 16
-
[73]
Paivio.Imagery and Verbal Processes (1st ed.)
A. Paivio.Imagery and Verbal Processes (1st ed.). Psychol- ogy Press, 1979. 1
work page 1979
-
[74]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 3
work page 2023
-
[75]
What the mind’s eye tells the mind’s brain: A critique of mental imagery.Psychological bulletin,
Zenon W Pylyshyn. What the mind’s eye tells the mind’s brain: A critique of mental imagery.Psychological bulletin,
-
[76]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
ZhangyangQi,ZhixiongZhang,YizhouYu,JiaqiWang,and Hengshuang Zhao. Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
-
[77]
Gpt4scene: Understand 3d scenes from videos with vision-language models
Zhangyang Qi, Zhixiong Zhang, Ye Fang, Jiaqi Wang, and Hengshuang Zhao. Gpt4scene: Understand 3d scenes from videos with vision-language models. InICLR, 2026. 2
work page 2026
-
[78]
Tokenflow: Unified image tokenizer for multimodal understanding and generation
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K Du, Zehuan Yuan, and Xinglong Wu. Tokenflow: Unified image tokenizer for multimodal understanding and generation. InCVPR, 2025. 3
work page 2025
-
[79]
Vision language models are blind
PooyanRahmanzadehgervi,LoganBolton,MohammadReza Taesiri, and Anh Totti Nguyen. Vision language models are blind. InACCV, 2024. 2
work page 2024
-
[80]
Does spatial cognition emerge in frontier models? InICLR, 2025
Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Kraehenbuehl, and Vladlen Koltun. Does spatial cognition emerge in frontier models? InICLR, 2025. 1, 2
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.