Recognition: 2 theorem links
· Lean TheoremBehavior-Constrained Reinforcement Learning with Receding-Horizon Credit Assignment for High-Performance Control
Pith reviewed 2026-05-13 19:26 UTC · model grok-4.3
The pith
A receding-horizon credit assignment mechanism lets reinforcement learning improve past expert demonstrations while keeping trajectory-level behavior consistent in high-dynamic control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that receding-horizon predictive modeling supplies look-ahead rewards that enforce trajectory-level consistency with expert behavior during RL training, while reference-trajectory conditioning allows the policy to represent a distribution of expert-consistent actions; this combination yields controllers that surpass demonstration performance yet remain aligned with human driving style in extreme-dynamics domains such as professional race-car control.
What carries the argument
The receding-horizon predictive mechanism that generates short-term future trajectories and converts them into look-ahead rewards for behavior consistency, paired with conditioning the policy on reference trajectories.
If this is right
- Policies can exceed expert data performance while preserving measurable alignment on full trajectories rather than single actions.
- The same framework applies to any dynamic control task where both optimality and human-like behavior matter, such as vehicle or robot control under disturbances.
- Conditioning on reference trajectories lets one policy represent the variability seen in expert demonstrations instead of collapsing to a single deterministic target.
- Human-grounded evaluations become feasible because the learned behavior already matches setup-dependent characteristics reported by professionals.
Where Pith is reading between the lines
- The approach could be tested on other high-speed or safety-critical domains such as autonomous highway driving where both speed and predictable style affect human acceptance.
- If the receding-horizon horizon length can be learned rather than fixed, the method might generalize across tasks with different time scales without additional hyperparameter search.
- Deploying these policies as human surrogates in simulation-to-real transfer would be more reliable than pure RL because behavioral deviation is explicitly bounded during training.
Load-bearing premise
The receding-horizon mechanism reliably supplies effective look-ahead rewards that maintain expert behavior consistency without causing training instability or demanding extensive domain-specific tuning.
What would settle it
Training identical policies without the receding-horizon component and observing either a sharp drop in lap-time performance or a large increase in trajectory deviation from expert data would show the mechanism is not delivering the claimed joint improvement.
Figures











read the original abstract
Learning high-performance control policies that remain consistent with expert behavior is a fundamental challenge in robotics. Reinforcement learning can discover high-performing strategies but often departs from desirable human behavior, whereas imitation learning is limited by demonstration quality and struggles to improve beyond expert data. We propose a behavior-constrained reinforcement learning framework that improves beyond demonstrations while explicitly controlling deviation from expert behavior. Because expert-consistent behavior in dynamic control is inherently trajectory-level, we introduce a receding-horizon predictive mechanism that models short-term future trajectories and provides look-ahead rewards during training. To account for the natural variability of human behavior under disturbances and changing conditions, we further condition the policy on reference trajectories, allowing it to represent a distribution of expert-consistent behaviors rather than a single deterministic target. Empirically, we evaluate the approach in high-fidelity race car simulation using data from professional drivers, a domain characterized by extreme dynamics and narrow performance margins. The learned policies achieve competitive lap times while maintaining close alignment with expert driving behavior, outperforming baseline methods in both performance and imitation quality. Beyond standard benchmarks, we conduct human-grounded evaluation in a driver-in-the-loop simulator and show that the learned policies reproduce setup-dependent driving characteristics consistent with the feedback of top-class professional race drivers. These results demonstrate that our method enables learning high-performance control policies that are both optimal and behavior-consistent, and can serve as reliable surrogates for human decision-making in complex control systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a behavior-constrained reinforcement learning framework that augments standard RL with a receding-horizon predictive mechanism to supply trajectory-level look-ahead rewards and conditions the policy on reference trajectories to capture variability in expert behavior. The central claim is that this enables policies that exceed demonstration performance while remaining aligned with expert driving, evaluated in high-fidelity race-car simulation with professional driver data and via human-grounded driver-in-the-loop tests.
Significance. If the empirical claims hold after addressing validation gaps, the work would offer a practical bridge between imitation and reinforcement learning for high-performance robotics, particularly in domains with narrow margins and extreme dynamics. The human-grounded evaluation and use of real professional driver data are strengths that could position the method as a reliable surrogate for human decision-making in control systems.
major comments (2)
- [§3.2] §3.2 (Receding-horizon predictive mechanism): The predictor is presented as supplying stable look-ahead rewards for behavior consistency, yet the manuscript provides no training procedure, accuracy metrics under extreme vehicle dynamics, or robustness checks against model mismatch and disturbances; this assumption is load-bearing for the credit-assignment claim and must be substantiated with targeted experiments.
- [§5] §5 (Empirical evaluation): The reported outperformance in lap times and imitation quality lacks quantitative metrics, explicit baseline definitions, statistical significance tests, and ablations on the behavior-constraint weight and horizon length; without these, the central performance and alignment claims remain only moderately supported despite the high-fidelity simulation setup.
minor comments (2)
- [§3] Notation for the conditioned policy and reference-trajectory input is introduced without a clear diagram or pseudocode; adding one would improve readability of the overall architecture.
- [Abstract] The abstract states that policies 'outperform baseline methods' but does not name the baselines; this detail should appear in the abstract for immediate clarity.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and constructive suggestions. We have revised the manuscript to address the major comments point by point as detailed below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Receding-horizon predictive mechanism): The predictor is presented as supplying stable look-ahead rewards for behavior consistency, yet the manuscript provides no training procedure, accuracy metrics under extreme vehicle dynamics, or robustness checks against model mismatch and disturbances; this assumption is load-bearing for the credit-assignment claim and must be substantiated with targeted experiments.
Authors: We concur that the receding-horizon predictive mechanism requires more detailed validation to support the credit assignment approach. In the revised manuscript, we have included the complete training procedure for the predictor, along with quantitative accuracy metrics assessed in extreme vehicle dynamics scenarios from our race car simulations. Additionally, we present robustness analyses under model mismatch and disturbances, which confirm the stability of the look-ahead rewards. These additions directly address the load-bearing assumption. revision: yes
-
Referee: [§5] §5 (Empirical evaluation): The reported outperformance in lap times and imitation quality lacks quantitative metrics, explicit baseline definitions, statistical significance tests, and ablations on the behavior-constraint weight and horizon length; without these, the central performance and alignment claims remain only moderately supported despite the high-fidelity simulation setup.
Authors: We agree that the empirical section would benefit from enhanced quantitative rigor. The updated manuscript now provides explicit definitions and implementations of the baseline methods, additional quantitative metrics beyond lap times (including trajectory deviation measures), results of statistical significance testing, and ablation studies varying the behavior-constraint weight and the horizon length. These revisions offer more robust evidence for the performance and alignment claims. revision: yes
Circularity Check
No circularity in derivation chain; empirical framework self-contained
full rationale
The paper proposes a behavior-constrained RL method with a receding-horizon predictive mechanism for trajectory-level credit assignment and policy conditioning on reference trajectories. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the central claims (competitive lap times with behavior alignment) to self-definitional inputs or prior author results by construction. Validation relies on external high-fidelity simulation benchmarks and human-grounded driver-in-the-loop evaluation, independent of internal definitions. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- behavior constraint weight and horizon length
axioms (1)
- domain assumption Expert behavior under disturbances is adequately represented by a conditional distribution over reference trajectories
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a lightweight receding-horizon trajectory predictor based on probabilistic Bézier curves, which provides both an auxiliary learning signal and look-ahead rewards
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formulate the problem as a constrained optimization task... E_π[rs_t] ≥ R̂
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Generating Personas for Games with Multimodal Adversarial Imitation Learn- ing, August 2023
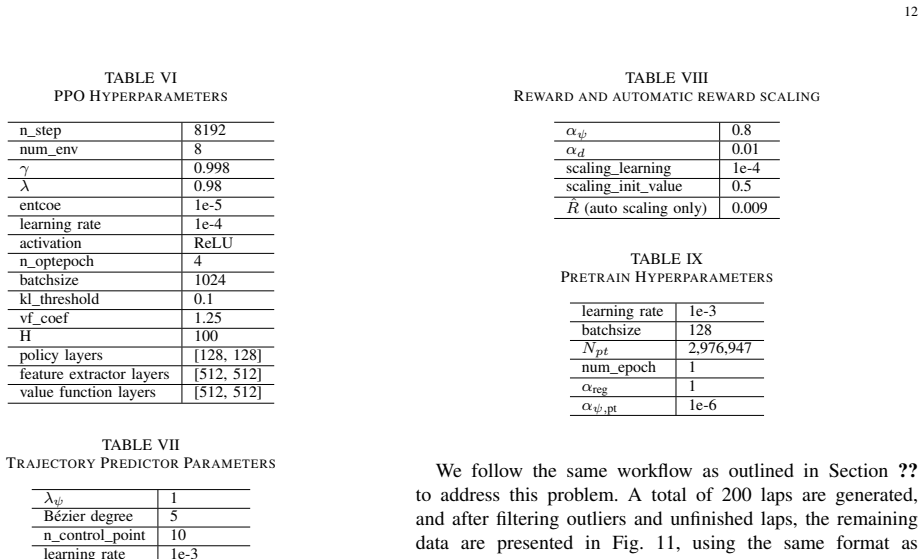
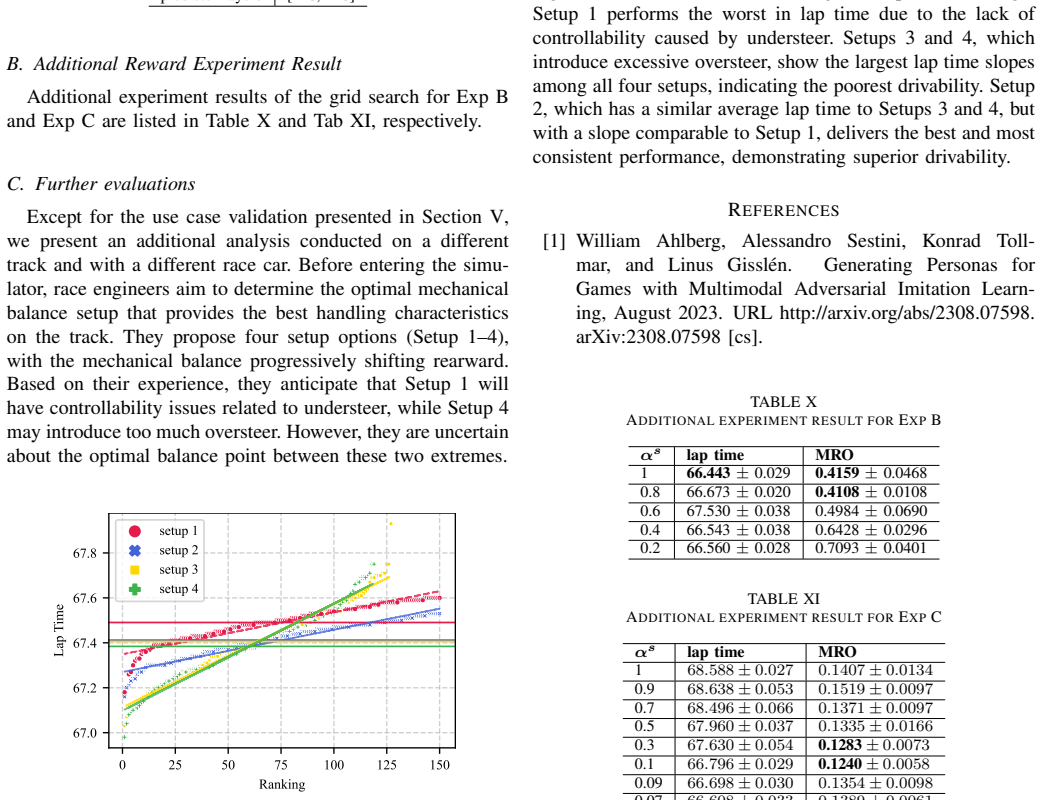
William Ahlberg, Alessandro Sestini, Konrad Toll- mar, and Linus Gisslén. Generating Personas for Games with Multimodal Adversarial Imitation Learn- ing, August 2023. URL http://arxiv.org/abs/2308.07598. arXiv:2308.07598 [cs]. TABLE X ADDITIONAL EXPERIMENT RESULT FOREXPB αs lap time MRO 1 66.443±0.029 0.4159±0.0468 0.8 66.673±0.020 0.4108±0.0108 0.6 67.53...
-
[2]
Guoxing Bai, Yu Meng, Li Liu, Weidong Luo, Qing Gu, and Li Liu. Review and Comparison of Path Tracking Based on Model Predictive Control.Elec- tronics, 8(10):1077, October 2019. ISSN 2079-9292. doi: 10.3390/electronics8101077. URL https://www. mdpi.com/2079-9292/8/10/1077. Number: 10 Publisher: Multidisciplinary Digital Publishing Institute
-
[3]
A framework for behavioural cloning
Michael Bain and Claude Sammut. A framework for behavioural cloning. InMachine Intelligence 15,
-
[4]
URL https://api.semanticscholar.org/CorpusID: 10738655
-
[5]
Johannes Betz, Hongrui Zheng, Alexander Liniger, Ugo Rosolia, Phillip Karle, Madhur Behl, Venkat Krovi, and Rahul Mangharam. Autonomous Vehicles on the Edge: A Survey on Autonomous Vehicle Racing.IEEE Open Journal of Intelligent Transportation Systems, 3: 458–488, 2022. ISSN 2687-7813. doi: 10.1109/ojits. 2022.3181510. URL http://arxiv.org/abs/2202.07008....
-
[6]
Raunak Bhattacharyya, Blake Wulfe, Derek Phillips, Alex Kuefler, Jeremy Morton, Ransalu Senanayake, and Mykel Kochenderfer. Modeling Human Driving Behavior through Generative Adversarial Imitation Learning.IEEE Transactions on Intelligent Transportation Systems, 24 (3):2874–2887, March 2023. ISSN 1524-9050, 1558-
work page 2023
-
[7]
URL http: //arxiv.org/abs/2006.06412
doi: 10.1109/TITS.2022.3227738. URL http: //arxiv.org/abs/2006.06412. arXiv:2006.06412 [cs]
-
[8]
Comparison of direct and indirect methods for minimum lap time optimal control problems
Nicola Dal Bianco, Enrico Bertolazzi, Francesco Biral, and Matteo Massaro. Comparison of direct and indirect methods for minimum lap time optimal control problems. Vehicle System Dynamics, 57(5):665–696, 2019. doi: 10. 1080/00423114.2018.1480048. URL https://doi.org/10. 1080/00423114.2018.1480048
-
[9]
A Study of Reinforcement Learning Techniques for Path Tracking in Autonomous Vehicles
Jason Chemin, Ashley Hill, Eric Lucet, and Aurélien Mayoue. A Study of Reinforcement Learning Techniques for Path Tracking in Autonomous Vehicles. In2024 IEEE Intelligent Vehicles Symposium (IV), pages 1442–1449, June 2024. doi: 10.1109/IV55156.2024.10588521. URL https://ieeexplore.ieee.org/document/10588521. ISSN: 2642-7214
-
[10]
Implementation of the Pure Pursuit Path Tracking Algorithm
Craig Coulter. Implementation of the Pure Pursuit Path Tracking Algorithm. 1992. URL https://www.semanticscholar.org/paper/ Implementation-of-the-Pure-Pursuit-Path-Tracking-Coulter/ ee756e53b6a68cb2e7a2e5d537a3eff43d793d70
work page 1992
-
[11]
A Divergence Minimization Perspective on Imitation Learning Methods
Seyed Kamyar Seyed Ghasemipour, Richard Zemel, and Shixiang Gu. A Divergence Minimization Perspective on Imitation Learning Methods. November 2019. doi: 10. 48550/arXiv.1911.02256. URL http://arxiv.org/abs/1911. 02256. arXiv:1911.02256 [cs]
-
[12]
David Ha and Jürgen Schmidhuber. World Models. March 2018. doi: 10.5281/zenodo.1207631. URL http: //arxiv.org/abs/1803.10122. arXiv:1803.10122 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.5281/zenodo.1207631 2018
-
[13]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mo- hammad Norouzi. Dream to Control: Learning Behaviors by Latent Imagination, March 2020. URL http://arxiv. org/abs/1912.01603. arXiv:1912.01603 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Con- textual Markov Decision Processes
Assaf Hallak, Dotan Di Castro, and Shie Mannor. Con- textual Markov Decision Processes. February 2015. doi: 10.48550/arXiv.1502.02259. URL http://arxiv.org/abs/ 1502.02259. arXiv:1502.02259 [stat]
-
[15]
Conor F. Hayes, Roxana R ˘adulescu, Eugenio Bargiacchi, Johan Källström, Matthew Macfarlane, Mathieu Rey- mond, Timothy Verstraeten, Luisa M. Zintgraf, Richard Dazeley, Fredrik Heintz, Enda Howley, Athirai A. Iris- sappane, Patrick Mannion, Ann Nowé, Gabriel Ramos, Marcello Restelli, Peter Vamplew, and Diederik M. Roi- jers. A Practical Guide to Multi-Obj...
-
[16]
Generative adversarial imitation learning,
Jonathan Ho and Stefano Ermon. Generative Adversarial Imitation Learning, June 2016. URL http://arxiv.org/abs/ 1606.03476. arXiv:1606.03476 [cs]
-
[17]
Gabriel Hoffmann, Claire Tomlin, Michael Montemerlo, and Sebastian Thrun. Autonomous Automobile Trajec- tory Tracking for Off-Road Driving: Controller Design, Experimental Validation and Racing. pages 2296–2301, August 2007. doi: 10.1109/ACC.2007.4282788
-
[18]
Ronny Hug, Wolfgang Hübner, and Michael Arens. Intro- ducing Probabilistic Bézier Curves for N-Step Sequence Prediction.Proceedings of the AAAI Conference on Artificial Intelligence, 34(06):10162–10169, April 2020. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v34i06
-
[19]
URL https://ojs.aaai.org/index.php/AAAI/article/ view/6576
-
[20]
Digital Twin of a Driver-in-the-Loop Race Car Simulation With Contextual Reinforcement Learning
Siwei Ju, Peter Van Vliet, Oleg Arenz, and Jan Pe- ters. Digital Twin of a Driver-in-the-Loop Race Car Simulation With Contextual Reinforcement Learning. IEEE Robotics and Automation Letters, 8(7):4107–4114, July 2023. ISSN 2377-3766, 2377-3774. doi: 10. 1109/LRA.2023.3279618. URL https://ieeexplore.ieee. org/document/10132573/
-
[21]
Style-biased reinforcement learning for quadruped loco- motion.Under review at ICRA, 2025
Siwei Ju, Oleg Arenz, Peter van Vliet, and Jan Peters. Style-biased reinforcement learning for quadruped loco- motion.Under review at ICRA, 2025
work page 2025
-
[22]
Juraj Kabzan, Lukas Hewing, Alexander Liniger, and Melanie N. Zeilinger. Learning-Based Model Predic- tive Control for Autonomous Racing.IEEE Robotics and Automation Letters, 4(4):3363–3370, October 2019. ISSN 2377-3766, 2377-3774. doi: 10.1109/LRA.2019. 2926677. URL https://ieeexplore.ieee.org/document/ 8754713/
-
[23]
Imitation Learning as $f$-Divergence Minimization, May 2020
Liyiming Ke, Sanjiban Choudhury, Matt Barnes, Wen Sun, Gilwoo Lee, and Siddhartha Srinivasa. Imitation Learning as $f$-Divergence Minimization, May 2020. arXiv:1905.12888
-
[24]
Stefan Löckel, André Kretschi, Peter Van Vliet, and Jan Peters. Identification and modelling of race driving styles.Vehicle System Dynamics, 60(8):2890–2918, Au- gust 2022. ISSN 0042-3114, 1744-5159. doi: 10.1080/ 00423114.2021.1930070. URL https://www.tandfonline. com/doi/full/10.1080/00423114.2021.1930070
-
[25]
Stefan Löckel, Siwei Ju, Maximilian Schaller, Peter Van Vliet, and Jan Peters. An Adaptive Human Driver 14 Model for Realistic Race Car Simulations.IEEE Trans- actions on Systems, Man, and Cybernetics: Systems, 53(11):6718–6730, November 2023. ISSN 2168-2216, 2168-2232. doi: 10.1109/TSMC.2023.3285588. URL https://ieeexplore.ieee.org/document/10173774/
-
[26]
William F. Milliken and Douglas L. Milliken.Race Car Vehicle Dynamics. Society of Automotive Engineers Warrendale, 1995
work page 1995
-
[27]
Dynamic pref- erences in multi-criteria reinforcement learning
Sriraam Natarajan and Prasad Tadepalli. Dynamic pref- erences in multi-criteria reinforcement learning. In Proceedings of the 22nd international conference on Machine learning, ICML ’05, pages 601–608, New York, NY , USA, August 2005. Association for Computing Machinery. ISBN 978-1-59593-180-1. doi: 10.1145/ 1102351.1102427. URL https://dl.acm.org/doi/10....
-
[28]
Bridging State and History Represen- tations: Understanding Self-Predictive RL, April 2024
Tianwei Ni, Benjamin Eysenbach, Erfan Seyedsalehi, Michel Ma, Clement Gehring, Aditya Mahajan, and Pierre-Luc Bacon. Bridging State and History Represen- tations: Understanding Self-Predictive RL, April 2024. URL http://arxiv.org/abs/2401.08898. arXiv:2401.08898 [cs]
-
[29]
Model-free probabilistic movement primitives for physical interaction
Alexandros Paraschos, Elmar Rueckert, Jan Peters, and Gerhard Neumann. Model-free probabilistic movement primitives for physical interaction. InIEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), pages 2860–2866. IEEE, 2015
work page 2015
-
[30]
Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills. ACM Trans. Graph., 37(4):143:1–143:14, July 2018. ISSN 0730-0301. doi: 10.1145/3197517.3201311. URL http://doi.acm.org/10.1145/3197517.3201311
-
[31]
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control.ACM Trans- actions on Graphics, 40(4):1–20, August 2021. ISSN 0730-0301, 1557-7368. doi: 10.1145/3450626.3459670. URL http://arxiv.org/abs/2104.02180. arXiv:2104.02180 [cs]
-
[32]
A survey of temporal credit assignment in deep reinforcement learning, 2024
Eduardo Pignatelli, Johan Ferret, Matthieu Geist, Thomas Mesnard, Hado van Hasselt, Olivier Pietquin, and Laura Toni. A Survey of Temporal Credit Assignment in Deep Reinforcement Learning, July 2024. URL http://arxiv. org/abs/2312.01072. arXiv:2312.01072 [cs]
-
[33]
Diederik Marijn Roijers, Peter Vamplew, Shimon White- son, and Richard Dazeley. A Survey of Multi-Objective Sequential Decision-Making.Journal of Artificial Intel- ligence Research, 48:67–113, October 2013. ISSN 1076-
work page 2013
-
[34]
URL http://arxiv.org/abs/ 1402.0590
doi: 10.1613/jair.3987. URL http://arxiv.org/abs/ 1402.0590. arXiv:1402.0590 [cs]
-
[35]
Efficient Reductions for Imitation Learning
Stephane Ross and Drew Bagnell. Efficient Reductions for Imitation Learning. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pages 661–668. JMLR Workshop and Confer- ence Proceedings, March 2010. URL https://proceedings. mlr.press/v9/ross10a.html. ISSN: 1938-7228
work page 2010
-
[36]
Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bag- nell. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. March 2011. doi: 10.48550/arXiv.1011.0686. URL http://arxiv.org/ abs/1011.0686. arXiv:1011.0686 [cs]
-
[37]
Roxana R ˘adulescu, Patrick Mannion, Diederik M. Roi- jers, and Ann Nowé. Multi-Objective Multi-Agent De- cision Making: A Utility-based Analysis and Survey. Autonomous Agents and Multi-Agent Systems, 34(1): 10, April 2020. ISSN 1387-2532, 1573-7454. doi: 10.1007/s10458-019-09433-x. URL http://arxiv.org/abs/ 1909.02964. arXiv:1909.02964 [cs]
-
[38]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms, August 2017. arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Data-efficient reinforcement learning with self-predictive representations
Max Schwarzer, Ankesh Anand, Rishab Goel, R. Devon Hjelm, Aaron Courville, and Philip Bachman. Data- Efficient Reinforcement Learning with Self-Predictive Representations, May 2021. URL http://arxiv.org/abs/ 2007.05929. arXiv:2007.05929 [cs]
-
[40]
A Benchmark Comparison of Imitation Learning-based Control Policies for Autonomous Racing
Xiatao Sun, Mingyan Zhou, Zhijun Zhuang, Shuo Yang, Johannes Betz, and Rahul Mangharam. A Benchmark Comparison of Imitation Learning-based Control Policies for Autonomous Racing. In2023 IEEE Intelligent Vehicles Symposium (IV), pages 1–5, June 2023. doi: 10. 1109/IV55152.2023.10186780. URL https://ieeexplore. ieee.org/abstract/document/10186780. ISSN: 2642-7214
-
[41]
MEGA-DAgger: Imitation Learning with Multiple Imperfect Experts, May 2024
Xiatao Sun, Shuo Yang, Mingyan Zhou, Kunpeng Liu, and Rahul Mangharam. MEGA-DAgger: Imitation Learning with Multiple Imperfect Experts, May 2024. URL http://arxiv.org/abs/2303.00638. arXiv:2303.00638 [cs]
-
[42]
Understanding Self-Predictive Learn- ing for Reinforcement Learning
Yunhao Tang, Zhaohan Daniel Guo, Pierre Harvey Richemond, Bernardo Ávila Pires, Yash Chandak, Rémi Munos, Mark Rowland, Mohammad Gheshlaghi Azar, Charline Le Lan, Clare Lyle, András György, Shantanu Thakoor, Will Dabney, Bilal Piot, Daniele Calandriello, and Michal Valko. Understanding Self-Predictive Learn- ing for Reinforcement Learning. December 2022. ...
-
[43]
Robust player imitation using multiobjective evolution
Niels van Hoorn, Julian Togelius, Daan Wierstra, and Jurgen Schmidhuber. Robust player imitation using multiobjective evolution. In2009 IEEE Congress on Evo- lutionary Computation, pages 652–659, May 2009. doi: 10.1109/CEC.2009.4983007. URL https://ieeexplore. ieee.org/document/4983007. ISSN: 1941-0026
-
[44]
When does Self-Prediction help? Understanding Auxiliary Tasks in Reinforcement Learning, June 2024
Claas V oelcker, Tyler Kastner, Igor Gilitschenski, and Amir-massoud Farahmand. When does Self-Prediction help? Understanding Auxiliary Tasks in Reinforcement Learning, June 2024. URL http://arxiv.org/abs/2406. 17718. arXiv:2406.17718 [cs]
-
[45]
Tsaipei Wang and Keng-Te Liaw. Driving style imita- tion in simulated car racing using style evaluators and multi-objective evolution of a fuzzy logic controller. In 2014 IEEE Conference on Norbert Wiener in the 21st Century (21CW), pages 1–7, June 2014. doi: 10.1109/ NORBERT.2014.6893872. URL https://ieeexplore.ieee. org/document/6893872. 15
-
[46]
BeTAIL: Behavior Transformer Adversarial Imitation Learning from Human Racing Gameplay, July 2024
Catherine Weaver, Chen Tang, Ce Hao, Kenta Kawamoto, Masayoshi Tomizuka, and Wei Zhan. BeTAIL: Behavior Transformer Adversarial Imitation Learning from Human Racing Gameplay, July 2024. URL http://arxiv.org/abs/2402.14194. arXiv:2402.14194 [cs]
-
[47]
DeepRacing: Parame- terized Trajectories for Autonomous Racing, May 2020
Trent Weiss and Madhur Behl. DeepRacing: Parame- terized Trajectories for Autonomous Racing, May 2020. URL http://arxiv.org/abs/2005.05178. arXiv:2005.05178 [cs]
-
[48]
Wurman, Samuel Barrett, Kenta Kawamoto, James MacGlashan, Kaushik Subramanian, Thomas J
Peter R. Wurman, Samuel Barrett, Kenta Kawamoto, James MacGlashan, Kaushik Subramanian, Thomas J. Walsh, Roberto Capobianco, Alisa Devlic, Franziska Eckert, Florian Fuchs, Leilani Gilpin, Piyush Khandel- wal, Varun Kompella, HaoChih Lin, Patrick MacAlpine, Declan Oller, Takuma Seno, Craig Sherstan, Michael D. Thomure, Houmehr Aghabozorgi, Leon Barrett, Ro...
-
[49]
doi: 10.1038/ s41586-021-04357-7
ISSN 0028-0836, 1476-4687. doi: 10.1038/ s41586-021-04357-7. URL https://www.nature.com/ articles/s41586-021-04357-7
-
[50]
Auxiliary Tasks Speed Up Learning PointGoal Navigation, November 2020
Joel Ye, Dhruv Batra, Erik Wijmans, and Abhishek Das. Auxiliary Tasks Speed Up Learning PointGoal Navigation, November 2020. URL http://arxiv.org/abs/ 2007.04561. arXiv:2007.04561 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.