Recognition: no theorem link
STEAR: Layer-Aware Spatiotemporal Evidence Intervention for Hallucination Mitigation in Video Large Language Models
Pith reviewed 2026-05-13 20:12 UTC · model grok-4.3
The pith
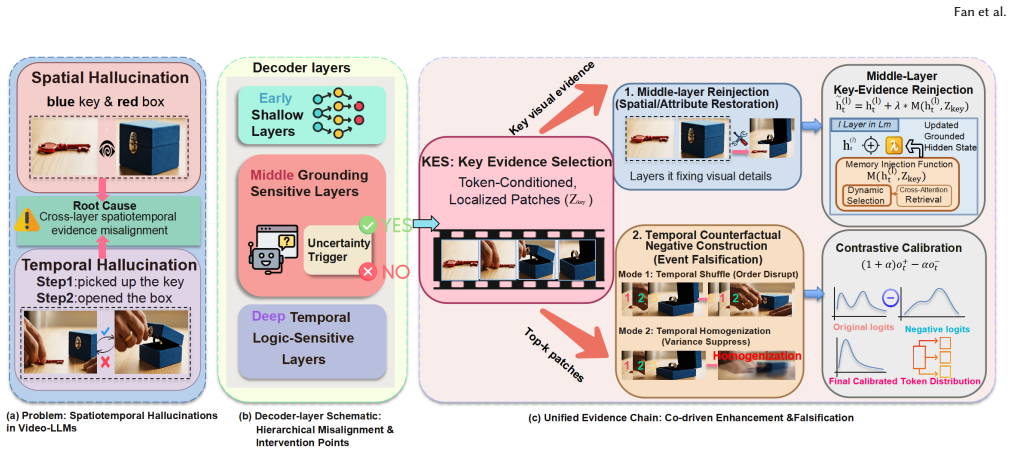
STEAR mitigates spatial and temporal hallucinations in Video-LLMs by selecting visual evidence from middle decoder layers for targeted restoration and counterfactual checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STEAR identifies high-risk decoding steps and selects token-conditioned visual evidence from grounding-sensitive middle layers. It reuses this shared evidence both to restore missing local grounding inside those middle layers and to build temporally perturbed patch-level counterfactuals that falsify inconsistent late-layer reasoning, thereby reducing both spatial and temporal hallucinations in a single-encode inference pass.
What carries the argument
Layer-aware spatiotemporal evidence intervention, which selects visual evidence from middle decoder layers and reuses it for both local grounding restoration and temporal counterfactual construction.
If this is right
- Hallucination rates drop consistently across multiple Video-LLM backbones and standard benchmarks.
- Faithfulness, temporal consistency, and robustness all improve at once.
- The method runs in a single encoding pass, avoiding the cost of repeated forward passes.
- Precise evidence at the right layer outperforms any global penalty applied uniformly across layers.
Where Pith is reading between the lines
- The same middle-layer selection idea might reduce hallucinations in image-only or audio-language models where layer roles also differ.
- Longer videos could test whether the chosen middle layers remain stable as sequence length grows.
- Model training that explicitly strengthens middle-layer visual grounding might amplify STEAR's gains without changing inference.
Load-bearing premise
Different decoder layers handle visual grounding and language composition separately enough that evidence chosen from the middle layers can fix both local details and later reasoning errors.
What would settle it
Run the same Video-LLM benchmarks with middle-layer evidence replaced by random patches or late-layer features; if hallucination rates stay the same or rise, the benefit of layer-specific selection disappears.
Figures



read the original abstract
Video Large Language Models (Video-LLMs) remain prone to spatiotemporal hallucinations, often generating visually unsupported details or incorrect temporal relations. Existing mitigation methods typically treat hallucination as a uniform decoding failure, applying globally shared correction rules. We instead observe that decoder layers contribute differently to visual grounding and later linguistic composition, indicating that intervention must be layer-aware. Based on this insight, we propose STEAR, a layer-aware spatiotemporal evidence intervention framework. STEAR identifies high-risk decoding steps and selects token-conditioned visual evidence from grounding-sensitive middle layers. It uses this shared evidence for two coupled purposes: restoring missing local grounding in middle layers, and constructing temporally perturbed patch-level counterfactuals to falsify inconsistent reasoning during late-layer decoding. Consequently, STEAR mitigates both spatial and temporal hallucinations within an efficient single-encode inference framework. Experiments across representative Video-LLM backbones and challenging benchmarks demonstrate that STEAR consistently reduces hallucinations while improving faithfulness, temporal consistency, and robustness. Our results confirm that reliable video decoding relies on intervening on precise evidence at the right layer, rather than enforcing a global penalty. The code is provided in the Supplementary Material.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STEAR, a layer-aware spatiotemporal evidence intervention framework for mitigating hallucinations in Video-LLMs. It observes that decoder layers contribute differently to visual grounding versus linguistic composition, selects token-conditioned visual evidence from grounding-sensitive middle layers, and reuses this evidence both to restore local grounding and to construct temporally perturbed patch-level counterfactuals that falsify inconsistent late-layer reasoning. The method operates within an efficient single-encode inference pipeline and reports consistent hallucination reductions plus gains in faithfulness and temporal consistency across backbones and benchmarks.
Significance. If the empirical results and layer-separation assumptions hold, the work supplies a targeted, low-overhead alternative to global penalty-based hallucination mitigation in video-language models. The dual-use of middle-layer evidence for both restoration and counterfactual falsification offers a concrete mechanism that could improve reliability without retraining. Code release supports reproducibility.
major comments (3)
- [§3.2] §3.2: the selection of grounding-sensitive middle layers is justified only by an informal observation of layer-wise differences; no quantitative metric (e.g., grounding accuracy per layer or mutual-information score) or ablation against early/late alternatives is supplied, leaving the precise layer range load-bearing yet unvalidated.
- [§4.1] §4.1 and §4.3: the claim that middle-layer token-conditioned evidence is sufficiently pure for both grounding restoration and temporally perturbed counterfactual construction is not tested; in decoder-only transformers, prior-token linguistic context commonly contaminates these activations, which would render the shared evidence internally inconsistent for the two stated purposes.
- [Table 2] Table 2 and §5: reported hallucination reductions are presented without error bars, statistical significance tests, or run counts, so the assertion of 'consistent' improvements across backbones rests on unverified experimental support and cannot yet be treated as load-bearing evidence.
minor comments (2)
- [§2] §2: the related-work discussion omits several recent layer-wise interpretability studies on decoder-only models that would strengthen the motivation.
- [Figure 2] Figure 2: the flowchart of evidence extraction and counterfactual injection would benefit from explicit arrows indicating the single-encode path versus the intervention branch.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below, providing the strongest honest defense based on the work as submitted while committing to revisions that strengthen the claims without misrepresentation.
read point-by-point responses
-
Referee: [§3.2] §3.2: the selection of grounding-sensitive middle layers is justified only by an informal observation of layer-wise differences; no quantitative metric (e.g., grounding accuracy per layer or mutual-information score) or ablation against early/late alternatives is supplied, leaving the precise layer range load-bearing yet unvalidated.
Authors: The layer selection in §3.2 is grounded in our empirical observation that decoder layers exhibit distinct roles in visual grounding versus linguistic composition, as evidenced by the differential impact on hallucination metrics when intervening at different depths. While the original text relies on this qualitative pattern rather than explicit per-layer scores, we agree a quantitative metric would strengthen the argument. We will add grounding accuracy per layer (computed via a held-out visual grounding probe) and an ablation comparing middle-layer intervention against early- and late-layer alternatives in the revised §3.2. revision: yes
-
Referee: [§4.1] §4.1 and §4.3: the claim that middle-layer token-conditioned evidence is sufficiently pure for both grounding restoration and temporally perturbed counterfactual construction is not tested; in decoder-only transformers, prior-token linguistic context commonly contaminates these activations, which would render the shared evidence internally inconsistent for the two stated purposes.
Authors: Our design in §4.1 extracts evidence conditioned strictly on the current visual token at the identified middle layers, and the dual-use mechanism (restoration plus counterfactual perturbation) is constructed to operate on the same visual patch representations. We acknowledge that decoder-only attention can introduce prior linguistic context, and the original submission does not include an explicit purity test. To address this directly, we will add an analysis measuring activation similarity with and without preceding linguistic tokens, plus a controlled experiment showing that the shared evidence remains effective for both restoration and falsification tasks. revision: yes
-
Referee: [Table 2] Table 2 and §5: reported hallucination reductions are presented without error bars, statistical significance tests, or run counts, so the assertion of 'consistent' improvements across backbones rests on unverified experimental support and cannot yet be treated as load-bearing evidence.
Authors: The results in Table 2 and §5 were obtained from single runs with fixed random seeds to ensure exact reproducibility across the reported backbones. We recognize that this does not yet provide statistical robustness. In the revision we will rerun the primary experiments over five independent seeds, report means with standard deviations as error bars, and include paired statistical significance tests (e.g., Wilcoxon signed-rank) to support the claim of consistent gains. revision: yes
Circularity Check
No significant circularity; empirical layer observation drives intervention without self-referential reduction
full rationale
The paper's derivation begins from an empirical observation that decoder layers differ in their contribution to visual grounding versus linguistic composition. STEAR is then constructed as a practical intervention that reuses middle-layer token-conditioned evidence for both grounding restoration and counterfactual construction. No equations, fitted parameters, or self-citations are invoked such that any core claim reduces to its own inputs by definition. The method is presented as an empirical framework whose validity is assessed via benchmark experiments rather than by algebraic identity or prior self-citation chains. This is the common case of a self-contained engineering contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoder layers contribute differently to visual grounding and later linguistic composition
Reference graph
Works this paper leans on
-
[1]
Saketh Bachu, Erfan Shayegani, Rohit Lal, Trishna Chakraborty, Arindam Dutta, Chengyu Song, Yue Dong, Nael Abu-Ghazaleh, and Amit K Roy-Chowdhury
- [2]
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning. 2019. What does BERT look at? an analysis of BERT’s attention. InProceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP. 276–286
work page 2019
- [9]
-
[10]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems36 (2023), 49250–49267
work page 2023
-
[11]
Yifei Gao, Jiaqi Wang, Zhiyu Lin, and Jitao Sang. 2024. AIGCs confuse AI too: Investigating and explaining synthetic image-induced hallucinations in large vision-language models. InProceedings of the 32nd ACM International Conference on Multimedia. 9010–9018
work page 2024
-
[12]
Bin Huang, Feng He, Qi Wang, Hong Chen, Guohao Li, Zhifan Feng, Xin Wang, and Wenwu Zhu. 2024. Neighbor does matter: Curriculum global positive- negative sampling for vision-language pre-training. InProceedings of the 32nd ACM International Conference on Multimedia. 8005–8014
work page 2024
-
[13]
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. 2024. Vtimellm: Empower llm to grasp video moments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14271–14280
work page 2024
-
[14]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. Opera: Alleviating hal- lucination in multi-modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13418–13427
work page 2024
-
[15]
Yiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiao-Yong Wei, Chang Wen Chen, and Qing Li. 2024. Prior knowledge integration via llm encoding and pseudo event regulation for video moment retrieval. InProceedings of the 32nd ACM International Conference on Multimedia. 7249–7258
work page 2024
-
[16]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang
-
[17]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 25004– 25014
- [18]
-
[19]
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. 2025. Why language models hallucinate.arXiv preprint arXiv:2509.04664(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13872–13882
work page 2024
-
[21]
Chaoyu Li, Eun Woo Im, and Pooyan Fazli. 2025. Vidhalluc: Evaluating temporal hallucinations in multimodal large language models for video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 13723–13733
work page 2025
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
work page 2023
-
[23]
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2025. Videochat: Chat-centric video understanding. Science China Information Sciences68, 10 (2025), 200102
work page 2025
-
[24]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. 2024. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22195–22206
work page 2024
-
[25]
Qian Li, Yucheng Zhou, Cheng Ji, Feihong Lu, Jianian Gong, Shangguang Wang, and Jianxin Li. 2024. Multi-modal inductive framework for text-video retrieval. In Proceedings of the 32nd ACM International Conference on Multimedia. 2389–2398
work page 2024
-
[26]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023. Contrastive decoding: Open-ended text generation as optimization. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers). 12286–12312
work page 2023
-
[27]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 292–305
work page 2023
-
[28]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-llava: Learning united visual representation by alignment before pro- jection. InProceedings of the 2024 conference on empirical methods in natural language processing. 5971–5984
work page 2024
- [29]
-
[30]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
work page 2023
-
[31]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-chatgpt: Towards detailed video understanding via large vision and lan- guage models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 12585–12602
work page 2024
- [32]
-
[33]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt.Advances in neural information processing systems35 (2022), 17359–17372
work page 2022
- [34]
-
[35]
Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez
- [36]
-
[37]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[38]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[39]
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al . 2024. Moviechat: From dense token to sparse memory for long video understand- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18221–18232
work page 2024
-
[40]
Jingran Su, Jingfan Chen, Hongxin Li, Yuntao Chen, Li Qing, and Zhaoxiang Zhang. 2025. Activation steering decoding: Mitigating hallucination in large vision-language models through bidirectional hidden state intervention. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers). 12964–12974
work page 2025
-
[41]
Yiming Sun, Mi Zhang, Feifei Li, Geng Hong, and Min Yang. 2026. Smartsight: Mitigating hallucination in video-llms without compromising video understand- ing via temporal attention collapse. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 9251–9259
work page 2026
-
[42]
Mingxu Tao, Quzhe Huang, Kun Xu, Liwei Chen, Yansong Feng, and Dongyan Zhao. 2024. Probing multimodal large language models for global and local semantic representations. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 13050–13056
work page 2024
-
[43]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. 2024. Mitigating hallucinations in large vision-language models with instruction contrastive decoding. InFindings of the Association for Computational Linguistics: ACL 2024. 15840–15853
work page 2024
-
[44]
Xiyao Wang, Yuhang Zhou, Xiaoyu Liu, Hongjin Lu, Yuancheng Xu, Feihong He, Jaehong Yoon, Taixi Lu, Fuxiao Liu, Gedas Bertasius, et al. 2024. Mementos: A comprehensive benchmark for multimodal large language model reasoning over image sequences. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
work page 2024
-
[45]
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. 2021. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9777–9786
work page 2021
- [46]
- [47]
-
[48]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. 2024. Woodpecker: Hallucination correction for multimodal large language models.Science China Information Sciences67, 12 (2024), 220105
work page 2024
- [49]
-
[50]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2024. Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [51]
-
[52]
Yuechi Zhou, Chuyue Zhou, Jianxin Zhang, Juntao Li, and Min Zhang. 2025. ALW: Adaptive Layer-Wise contrastive decoding enhancing reasoning ability in Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2025. 8506–8524
work page 2025
-
[53]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al
-
[54]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Xin Zou, Yizhou Wang, Yibo Yan, Yuanhuiyi Lyu, Kening Zheng, Sirui Huang, Junkai Chen, Peijie Jiang, Jia Liu, Chang Tang, et al . 2024. Look twice before you answer: Memory-space visual retracing for hallucination mitigation in mul- timodal large language models.arXiv preprint arXiv:2410.03577(2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.