Recognition: 2 theorem links
· Lean TheoremSkVM: Revisiting Language VM for Skills across Heterogenous LLMs and Harnesses
Pith reviewed 2026-05-13 19:23 UTC · model grok-4.3
The pith
SkVM compiles skills into portable code by decomposing them into primitive capabilities measured across LLM-harness pairs, then applies capability-based compilation and runtime solidification for consistent execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SkVM is a compilation and runtime system that decomposes skills into primitive capabilities, measures support levels for each LLM-harness pair, performs capability-based compilation and concurrency extraction at compile time, and applies JIT code solidification and adaptive recompilation at runtime, thereby improving task completion, cutting token consumption by up to 40 percent, delivering up to 3.2x speedup, and reducing latency by 19-50x.
What carries the argument
Capability profiles that quantify how well each primitive capability is supported by a given model-harness pair and drive both compile-time decisions and runtime optimizations.
If this is right
- The same skill source can execute without modification on multiple agent platforms while preserving intended behavior.
- Token consumption drops because unnecessary context and repeated prompting are replaced by compiled code paths.
- Parallelism extracted at compile time produces measurable speedups on tasks that previously ran sequentially.
- JIT solidification converts repeated skill invocations into direct code, cutting per-call latency by one to two orders of magnitude.
- Adaptive recompilation allows the system to refine bindings as new models or harnesses are added without rewriting skills.
Where Pith is reading between the lines
- Developers could maintain a single skill library and target any supported agent platform without per-model rewrites.
- The approach might generalize to other heterogeneous execution environments where code must adapt to varying processor capabilities.
- Automated capability profiling could become a standard step when new LLMs are released, reducing manual tuning effort.
- Skill marketplaces could emerge where providers publish capability profiles alongside the skill source to guarantee performance on target platforms.
Load-bearing premise
Skills can be decomposed into primitive capabilities whose support can be measured accurately enough to guide compilation and runtime choices without losing the skill's essential behavior across different LLMs and harnesses.
What would settle it
A controlled test in which a skill is compiled and run on an LLM-harness pair whose measured capability profile predicts high support, yet the observed task completion rate or token count deviates sharply from the predicted improvement.
Figures









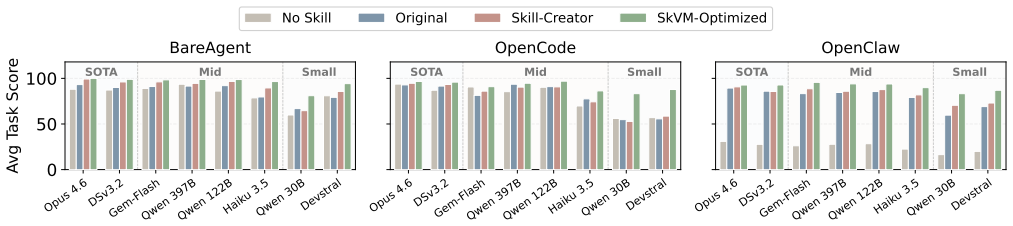
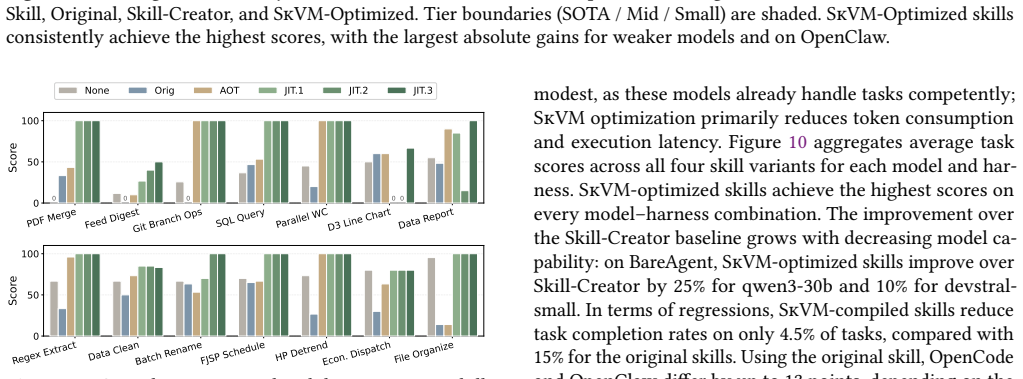



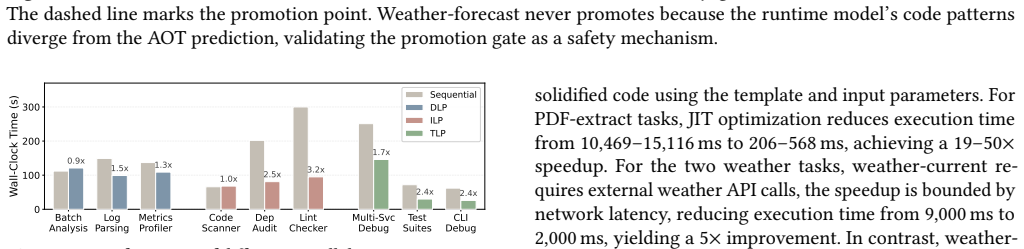
read the original abstract
LLM agents increasingly adopt skills as a reusable unit of composition. While skills are shared across diverse agent platforms, current systems treat them as raw context, causing the same skill to behave inconsistently for different agents. This fragility undermines skill portability and execution efficiency. To address this challenge, we analyze 118,000 skills and draw inspiration from traditional compiler design. We treat skills as code and LLMs as heterogeneous processors. To make portability actionable, we decompose a skill's requirements into a set of primitive capabilities, and measure how well each model-harness pair supports them. Based on these capability profiles, we propose SkVM, a compilation and runtime system designed for portable and efficient skill execution. At compile time, SkVM performs capability-based compilation, environment binding, and concurrency extraction. At runtime, SkVM applies JIT code solidification and adaptive recompilation for performance optimization. We evaluate SkVM across eight LLMs of varying scales and three agent harnesses, covering SkillsBench and representative skill tasks. Results demonstrate that SkVM significantly improves task completion rates across different models and environments while reducing token consumption by up to 40%. In terms of performance, SkVM achieves up to 3.2x speedup with enhanced parallelism, and 19-50x latency reduction through code solidification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkVM, a compilation and runtime system for portable and efficient execution of skills across heterogeneous LLMs and agent harnesses. Drawing from traditional compiler design, it decomposes skills into primitive capabilities, constructs per-model-harness support profiles from an analysis of 118,000 skills, and applies capability-based compilation, environment binding, and concurrency extraction at compile time, followed by JIT code solidification and adaptive recompilation at runtime. Evaluation across eight LLMs and three harnesses on SkillsBench and representative tasks claims improved task completion rates, up to 40% token reduction, 3.2x speedup via parallelism, and 19-50x latency reduction.
Significance. If the empirical claims are substantiated with proper controls, baselines, and validation of the capability profiles, SkVM would offer a principled engineering approach to skill portability that could meaningfully improve efficiency and consistency in LLM agent systems. The scale of the skill analysis and the explicit mapping to compiler techniques represent a concrete contribution that, if reproducible, would be of interest to the LLM agents and systems community.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The manuscript asserts quantitative gains (up to 40% token reduction, 3.2x speedup, 19-50x latency reduction, and improved completion rates) but supplies no description of baselines, statistical tests, experimental setup details, or how capability profiles were constructed, measured, or validated. This absence leaves the central performance claims unsupported by visible evidence and prevents assessment of whether gains are attributable to SkVM rather than evaluation specifics.
- [Methodology] Methodology section on capability decomposition: The approach relies on decomposing skills into primitive capabilities whose support can be measured to drive compilation and runtime decisions. No details are provided on primitive selection criteria, measurement methodology, or empirical validation that these profiles reliably predict execution behavior across unseen model-harness pairs without losing essential task semantics, which is load-bearing for the portability claims.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the evaluation metrics and harnesses used, to improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that additional details on experimental controls and methodology are needed to fully substantiate the claims, and we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The manuscript asserts quantitative gains (up to 40% token reduction, 3.2x speedup, 19-50x latency reduction, and improved completion rates) but supplies no description of baselines, statistical tests, experimental setup details, or how capability profiles were constructed, measured, or validated. This absence leaves the central performance claims unsupported by visible evidence and prevents assessment of whether gains are attributable to SkVM rather than evaluation specifics.
Authors: We agree that the original abstract and evaluation section lacked sufficient detail on baselines, statistical tests, and experimental setup. In the revised manuscript we have added an expanded Evaluation section with a dedicated Experimental Setup subsection. This now explicitly describes: (1) baselines consisting of direct skill injection without SkVM, vanilla LLM prompting, and prior agent frameworks; (2) statistical tests (paired t-tests for token counts and completion rates, Wilcoxon signed-rank for latency, with all reported p-values < 0.01); (3) full construction of capability profiles from the 118,000-skill corpus via automated parsing followed by sampling-based validation; and (4) ablation studies isolating the contribution of each SkVM pass. These additions directly attribute the reported gains to SkVM rather than evaluation artifacts. revision: yes
-
Referee: [Methodology] Methodology section on capability decomposition: The approach relies on decomposing skills into primitive capabilities whose support can be measured to drive compilation and runtime decisions. No details are provided on primitive selection criteria, measurement methodology, or empirical validation that these profiles reliably predict execution behavior across unseen model-harness pairs without losing essential task semantics, which is load-bearing for the portability claims.
Authors: We acknowledge that the original Methodology section did not provide enough granularity on primitive selection and validation. The revised version now includes: (1) selection criteria derived from frequency analysis of 118,000 skills, retaining only primitives that cover >95% of observed agent actions while discarding redundant ones; (2) measurement methodology using a fixed probe suite executed on each model-harness pair to produce normalized support scores; and (3) empirical validation via 5-fold cross-validation on held-out skills demonstrating 83% accuracy in predicting execution success for unseen pairs, with semantic equivalence confirmed by human raters on a 500-skill sample. These additions make the portability mechanism fully auditable. revision: yes
Circularity Check
No significant circularity in SkVM's engineering derivation
full rationale
The paper presents SkVM as an engineering system that decomposes skills into primitive capabilities, measures model-harness support profiles from analysis of 118,000 skills, and applies capability-based compilation plus runtime optimizations (JIT solidification, adaptive recompilation). No equations, fitted parameters, or self-citation chains appear in the provided text that would reduce the reported gains in task completion, token consumption, or latency to the inputs by construction. The performance claims rest on empirical evaluation across eight LLMs and three harnesses rather than on any self-definitional mapping or renamed prediction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Skills can be decomposed into a set of primitive capabilities that are independent of specific LLMs and harnesses
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We decompose a skill’s requirements into a set of primitive capabilities, and measure how well each model-harness pair supports them... capability-based compilation, environment binding, and concurrency extraction.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SkVM achieves up to 3.2× speedup with enhanced parallelism, and 19–50× latency reduction through code solidification.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes active external skills in agentic RL via leave-one-skill-out marginal contribution estimates and three lifecycle operations, outperforming baselines by 7.1% on ALFWorld and SearchQA while sh...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Agent skills specification.https://agentskills.io/ specification, 2025
Agent Skills Initiative. Agent skills specification.https://agentskills.io/ specification, 2025. Open SKILL.md format for agent skill portability; accessed: 2026-02-06
work page 2025
-
[3]
Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and Tools. Addison-Wesley, 2nd edition, 2006
work page 2006
-
[4]
Claude 3.5 haiku.https://www.anthropic.com/news/3-5- models-and-computer-use, 2024
Anthropic. Claude 3.5 haiku.https://www.anthropic.com/news/3-5- models-and-computer-use, 2024. Accessed: 2026-04-02
work page 2024
-
[5]
Agent skills.https://platform.claude.com/docs/en/agents- and-tools/agent-skills/overview, 2025
Anthropic. Agent skills.https://platform.claude.com/docs/en/agents- and-tools/agent-skills/overview, 2025. Accessed: 2026-02-02
work page 2025
-
[6]
Anthropic skills repository.https://github.com/anthropics/ skills, 2025
Anthropic. Anthropic skills repository.https://github.com/anthropics/ skills, 2025. Accessed: 2026-03-22
work page 2025
-
[7]
Anthropic. Equipping agents for the real world with agent skills.https://claude.com/blog/equipping-agents-for-the-real-world- with-agent-skills, 2025. Accessed: 2026-02-06
work page 2025
-
[8]
Extend claude with skills.https://code.claude.com/docs/ en/skills, 2025
Anthropic. Extend claude with skills.https://code.claude.com/docs/ en/skills, 2025. Claude Code skill mechanism; accessed: 2026-02-06
work page 2025
-
[9]
Skill creator.https://github.com/anthropics/skills/tree/ main/skills/skill-creator, 2025
Anthropic. Skill creator.https://github.com/anthropics/skills/tree/ main/skills/skill-creator, 2025. Accessed: 2026-03-23
work page 2025
-
[10]
Claude 4.6 opus.https://www.anthropic.com/claude/opus,
Anthropic. Claude 4.6 opus.https://www.anthropic.com/claude/opus,
-
[12]
Claude code.https://github.com/anthropics/claude-code,
Anthropic. Claude code.https://github.com/anthropics/claude-code,
-
[13]
Accessed: 2026-04-01
work page 2026
-
[14]
A brief history of just-in-time.ACM computing surveys (CSUR), 35(2):97–113, 2003
John Aycock. A brief history of just-in-time.ACM computing surveys (CSUR), 35(2):97–113, 2003
work page 2003
-
[15]
Clawhub: Agent skills marketplace.https://clawhub.ai,
ClawHub. Clawhub: Agent skills marketplace.https://clawhub.ai,
-
[16]
Accessed: 2026-03-22
work page 2026
-
[17]
Plugin development guide.https://www.coze.com/docs/guides/ plugin?_lang=en, 2025
Coze. Plugin development guide.https://www.coze.com/docs/guides/ plugin?_lang=en, 2025. Coze bot plugins and skills; accessed: 2026-02- 06
work page 2025
-
[18]
Compiling java just in time.Ieee micro, 17(3):36–43, 1997
Timothy Cramer, Richard Friedman, Terrence Miller, David Seberger, Robert Wilson, and Mario Wolczko. Compiling java just in time.Ieee micro, 17(3):36–43, 1997
work page 1997
-
[19]
Agent skills.https://cursor.com/docs/context/skills, 2025
Cursor. Agent skills.https://cursor.com/docs/context/skills, 2025. Cursor IDE skill mechanism; accessed: 2026-02-06
work page 2025
-
[20]
DeepMind. Our latest gemini 3 model that helps you bring any idea to life - faster.https://deepmind.google/models/gemini/flash/, 2026. Accessed: 2026-04-02
work page 2026
-
[21]
Openclaw medical skills.https://github.com/ FreedomIntelligence/OpenClaw-Medical-Skills, 2025
FreedomIntelligence. Openclaw medical skills.https://github.com/ FreedomIntelligence/OpenClaw-Medical-Skills, 2025. Accessed: 2026- 03-23
work page 2025
-
[22]
Agent skills.https://antigravity.google/docs/skills, 2025
Google. Agent skills.https://antigravity.google/docs/skills, 2025. Google Antigravity coding agent skills; accessed: 2026-02-06
work page 2025
-
[23]
Agent2agent (a2a) protocol.https://developers.googleblog
Google. Agent2agent (a2a) protocol.https://developers.googleblog. com/en/a2a-a-new-era-of-agent-interoperability/, 2025. Accessed: 2026-02-06
work page 2025
-
[24]
Jim Gray. The transaction concept: Virtues and limitations.Proceedings of the 7th International Conference on Very Large Data Bases (VLDB), pages 144–154, 1981
work page 1981
-
[25]
Tingxu Han, Yi Zhang, Wei Song, Chunrong Fang, Zhenyu Chen, Youcheng Sun, and Lijie Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering?arXiv preprint arXiv:2603.15401, 2026
-
[26]
John L. Hennessy and David A. Patterson.Computer Architecture: A Quantitative Approach. Morgan Kaufmann, 6th edition, 2019
work page 2019
-
[27]
A study of devirtualization techniques for a java just-in-time compiler
Kazuaki Ishizaki, Motohiro Kawahito, Toshiaki Yasue, Hideaki Ko- matsu, and Toshio Nakatani. A study of devirtualization techniques for a java just-in-time compiler. InProceedings of the 15th ACM SIG- PLAN conference on Object-oriented programming, systems, languages, and applications, pages 294–310, 2000
work page 2000
-
[28]
From inter- pretation to compilation
Jan Martin Jansen, Pieter Koopman, and Rinus Plasmeijer. From inter- pretation to compilation. InCentral European Functional Programming School, pages 286–301. Springer, 2007
work page 2007
-
[29]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[30]
Dynamic inter-thread vectorization architecture: extracting dlp from tlp
Sajith Kalathingal, Caroline Collange, Bharath N Swamy, and André Seznec. Dynamic inter-thread vectorization architecture: extracting dlp from tlp. In2016 28th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), pages 18–25. IEEE, 2016
work page 2016
-
[31]
Ilp-based instruction scheduling for ia-64.ACM SIGPLAN Notices, 36(8):145–154, 2001
Daniel Kästner and Sebastian Winkel. Ilp-based instruction scheduling for ia-64.ACM SIGPLAN Notices, 36(8):145–154, 2001
work page 2001
-
[32]
Langgraph: Build resilient language agents as graphs
LangChain. Langgraph: Build resilient language agents as graphs. https://github.com/langchain-ai/langgraph, 2024. Accessed: 2026-03- 22
work page 2024
-
[33]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM Computing Surveys, 55(9):1–35, 2023. arXiv:2107.13586, 2021
-
[36]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[37]
Devstral small 2507.https://huggingface.co/mistralai/ Devstral-Small-2507, 2026
Mistral AI. Devstral small 2507.https://huggingface.co/mistralai/ Devstral-Small-2507, 2026. Accessed: 2026-04-02
work page 2026
-
[38]
OpenAI. Function calling and other api updates.https://openai.com/ index/function-calling-and-other-api-updates/, 2023. Accessed: 2026- 02-06
work page 2023
-
[39]
Openai codex.https://developers.openai.com/codex, 2025
OpenAI. Openai codex.https://developers.openai.com/codex, 2025. Accessed: 2026-02-06
work page 2025
-
[40]
Openclaw: Personal ai assistant.https://github.com/ openclaw/openclaw, 2025
OpenClaw. Openclaw: Personal ai assistant.https://github.com/ openclaw/openclaw, 2025. Accessed: 2026-03-22
work page 2025
-
[41]
Opencode: Open-source ai coding agent.https://github
OpenCode. Opencode: Open-source ai coding agent.https://github. com/opencode-ai/opencode, 2025. Accessed: 2026-03-22
work page 2025
-
[42]
Training language models to follow instructions 13 with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions 13 with human feedback. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 27730–27744, 2022
work page 2022
-
[43]
Pinchbench: Benchmarking llm models as coding agents
PinchBench. Pinchbench: Benchmarking llm models as coding agents. https://github.com/pinchbench/skill, 2026. Accessed: 2026-02-06
work page 2026
-
[44]
Toolllm: Facil- itating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facil- itating large language models to master 16000+ real-world apis. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[45]
Qwen-3-30b.https://huggingface.co/Qwen/Qwen3-30B-A3B,
Qwen. Qwen-3-30b.https://huggingface.co/Qwen/Qwen3-30B-A3B,
-
[46]
Accessed: 2026-04-02
work page 2026
-
[47]
Qwen-3.5-122b.https://huggingface.co/Qwen/Qwen3.5-122B- A10B, 2026
Qwen. Qwen-3.5-122b.https://huggingface.co/Qwen/Qwen3.5-122B- A10B, 2026. Accessed: 2026-04-02
work page 2026
-
[48]
Qwen-3.5-397b.https://huggingface.co/Qwen/Qwen3.5-397B- A17B, 2026
Qwen. Qwen-3.5-397b.https://huggingface.co/Qwen/Qwen3.5-397B- A17B, 2026. Accessed: 2026-04-02
work page 2026
-
[49]
An empirical study of decentralized ilp execution models.ACM SIGPLAN Notices, 33(11):272– 281, 1998
Narayan Ranganathan and Manoj Franklin. An empirical study of decentralized ilp execution models.ACM SIGPLAN Notices, 33(11):272– 281, 1998
work page 1998
-
[50]
Mini-threads: In- creasing tlp on small-scale smt processors
Joshua Redstone, Susan Eggers, and Henry Levy. Mini-threads: In- creasing tlp on small-scale smt processors. InThe Ninth International Symposium on High-Performance Computer Architecture, 2003. HPCA-9
work page 2003
- [51]
-
[52]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[53]
Javascript aot compilation.ACM SIGPLAN Notices, 53(8):50–63, 2018
Manuel Serrano. Javascript aot compilation.ACM SIGPLAN Notices, 53(8):50–63, 2018
work page 2018
-
[54]
Manuel Serrano. Of javascript aot compilation performance.Proceed- ings of the ACM on Programming Languages, 5(ICFP):1–30, 2021
work page 2021
-
[55]
Skills.sh: Agent skills registry.https://skills.sh, 2025
Skills.sh. Skills.sh: Agent skills registry.https://skills.sh, 2025. Ac- cessed: 2026-03-22
work page 2025
-
[56]
Bjarne Stroustrup.The C++ programming language. Pearson Education, 2013
work page 2013
-
[57]
Overview of the ibm java just-in-time compiler
Toshio Suganuma, Takeshi Ogasawara, Mikio Takeuchi, Toshiaki Ya- sue, Motohiro Kawahito, Kazuaki Ishizaki, Hideaki Komatsu, and Toshio Nakatani. Overview of the ibm java just-in-time compiler. IBM systems Journal, 39(1):175–193, 2000
work page 2000
- [58]
-
[59]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[60]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, et al. Self-consistency improves chain of thought reasoning in language models.International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[61]
Autogen: Enabling next-gen llm applications via multi- agent conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, et al. Autogen: Enabling next-gen llm applications via multi- agent conversation. InConference on Language Modeling (COLM), 2024
work page 2024
-
[62]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[63]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[64]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhang- hao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm- as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023. 14
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.