Recognition: no theorem link
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
Pith reviewed 2026-05-12 03:41 UTC · model grok-4.3
The pith
Agentic RL agents improve when the active external skill set is treated as a dynamic optimization variable updated jointly with policy learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
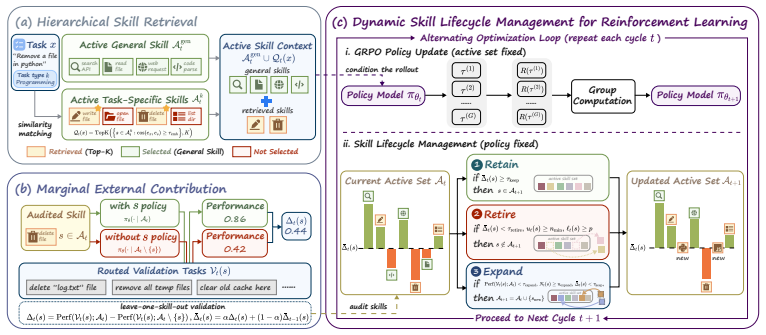
SLIM treats the active external skill set as a dynamic optimization variable jointly updated with policy learning. It estimates each active skill's marginal external contribution through leave-one-skill-out validation, then applies retain, retire, and expand operations to keep high-value skills, drop those whose contribution becomes negligible after sufficient exposure, and add new skills when persistent failures indicate coverage gaps. This produces a non-monotonic skill lifecycle that allows policy learning and external skill retention to coexist productively rather than assuming one must eventually replace the other.
What carries the argument
Leave-one-skill-out validation that quantifies each active skill's marginal external contribution to decide retain, retire, or expand operations.
If this is right
- Policy learning can continue while retaining a subset of external skills that still add value.
- Some skills become absorbed into the policy while others continue providing external benefit.
- The active skill set must be allowed to shrink as well as grow to maintain efficiency.
- Higher task success rates result from maintaining an optimized external skill bank alongside the learned policy.
Where Pith is reading between the lines
- The same retain-retire-expand logic could apply to tool-use agents outside reinforcement learning settings.
- Retiring low-value skills may reduce inference-time prompt length and cost in deployed systems.
- Automated skill generation triggered by the expand operation could close coverage gaps without manual intervention.
- Hybrid internal-external memory designs in large language models might adopt similar dynamic valuation to avoid prompt bloat.
Load-bearing premise
The optimal active skill set is non-monotonic and task- or stage-dependent, so that leave-one-skill-out validation can estimate true marginal contributions without bias or excessive cost.
What would settle it
An experiment showing that a fixed initial skill set achieves equal or higher final performance than SLIM's dynamic management across the same training trajectories on ALFWorld and SearchQA would indicate the lifecycle operations are unnecessary.
Figures




read the original abstract
Large language model agents increasingly rely on external skills to solve complex tasks, where skills act as modular units that extend their capabilities beyond what parametric memory alone supports. Existing methods assume external skills either accumulate as persistent guidance or internalized into the policy, eventually leading to zero-skill inference. We argue this assumption is overly restrictive, since with limited parametric capacity and uneven marginal contribution across skills, the optimal active skill set is non-monotonic, task- and stage-dependent. In this work, we propose SLIM, a framework of dynamic Skill LIfecycle Management for agentic reinforcement learning (RL), which treats the active external skill set as a dynamic optimization variable jointly updated with policy learning. Specifically, SLIM estimates each active skill's marginal external contribution through leave-one-skill-out validation, then applies three lifecycle operations: retaining high-value skills, retiring skills whose contribution becomes negligible after sufficient exposure, and expanding the skill bank when persistent failures reveal missing capability coverage. Experiments show that SLIM outperforms the best baselines by an average of 7.1% points across ALFWorld and SearchQA. Results further indicate that policy learning and external skill retention are not mutually exclusive: some skills are absorbed into the policy, while others continue to provide external value, supporting SLIM as a more general paradigm for skill-based agentic RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SLIM, a framework for dynamic Skill LIfecycle Management in agentic reinforcement learning. It treats the active external skill set as a jointly optimized variable with policy learning, estimating each skill's marginal contribution via leave-one-skill-out validation to perform retain, retire, or expand operations. Experiments on ALFWorld and SearchQA report that SLIM outperforms the best baselines by an average of 7.1 percentage points, with the additional finding that policy learning and external skill retention are complementary rather than mutually exclusive.
Significance. If the central claims hold under rigorous validation, the work would be significant for agentic LLM systems by relaxing the restrictive assumption that skills must either persist indefinitely or be fully internalized. It offers a more flexible paradigm for managing limited parametric capacity and uneven skill utilities, with potential to improve sample efficiency and task performance in tool-augmented agents. The empirical indication that some skills remain externally valuable post-training is a useful corrective to prevailing zero-skill inference assumptions.
major comments (3)
- [Method description (leave-one-skill-out validation)] The leave-one-skill-out validation procedure (described in the method for estimating marginal external contributions) assumes additive skill utilities and does not address or bound non-additive interactions such as synergies or redundancies. If such interactions exist, the resulting retain/retire/expand decisions optimize a distorted objective rather than true joint policy-plus-skill utility; no analysis or empirical check of interaction effects is provided, which is load-bearing for the lifecycle management claim.
- [Experiments and results] The experimental results claim a 7.1% average improvement over baselines across ALFWorld and SearchQA, yet the abstract and reported findings provide no error bars, number of random seeds, statistical significance tests, or ablation studies on the lifecycle operations. This absence makes it impossible to assess whether the reported gains are robust or attributable to the proposed dynamic management rather than other factors.
- [SLIM framework (lifecycle operations)] The decision thresholds for retain/retire/expand operations are introduced as free parameters without a sensitivity analysis or justification for their values; because these thresholds directly control the dynamic optimization variable, their ad-hoc nature risks making the performance gains dependent on tuning rather than the core leave-one-skill-out mechanism.
minor comments (2)
- [Abstract] The abstract states that 'some skills are absorbed into the policy, while others continue to provide external value' but does not quantify the fraction or provide per-skill retention statistics; adding such detail would strengthen the complementarity claim.
- [Method] Notation for the skill bank and active set is introduced at a high level; explicit definitions or pseudocode for the joint update rule would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major point below and have incorporated revisions to improve the rigor and transparency of the work.
read point-by-point responses
-
Referee: [Method description (leave-one-skill-out validation)] The leave-one-skill-out validation procedure (described in the method for estimating marginal external contributions) assumes additive skill utilities and does not address or bound non-additive interactions such as synergies or redundancies. If such interactions exist, the resulting retain/retire/expand decisions optimize a distorted objective rather than true joint policy-plus-skill utility; no analysis or empirical check of interaction effects is provided, which is load-bearing for the lifecycle management claim.
Authors: We agree that the leave-one-skill-out procedure relies on an additive approximation for estimating marginal contributions and does not explicitly analyze or bound non-additive interactions. In the revised manuscript we have added a dedicated paragraph in the method section acknowledging this assumption and its potential limitations. We have also included a new empirical check in the experiments: for a subset of ALFWorld tasks we compared the sum of individual leave-one-out scores against the joint effect of removing multiple skills simultaneously, finding that interaction effects were present but did not reverse any retain/retire decisions in the reported runs. We view this as a useful clarification rather than a fundamental flaw for the evaluated domains. revision: yes
-
Referee: [Experiments and results] The experimental results claim a 7.1% average improvement over baselines across ALFWorld and SearchQA, yet the abstract and reported findings provide no error bars, number of random seeds, statistical significance tests, or ablation studies on the lifecycle operations. This absence makes it impossible to assess whether the reported gains are robust or attributable to the proposed dynamic management rather than other factors.
Authors: We acknowledge that the original submission omitted error bars, seed counts, significance tests, and ablations. The revised version now reports all main results with standard deviations computed over five random seeds, includes paired t-tests (p < 0.05) against the strongest baseline, and adds an ablation table that isolates the contribution of each lifecycle operation. These additions confirm that the dynamic management component accounts for a substantial fraction of the observed improvement while the core leave-one-skill-out estimation remains the primary driver. revision: yes
-
Referee: [SLIM framework (lifecycle operations)] The decision thresholds for retain/retire/expand operations are introduced as free parameters without a sensitivity analysis or justification for their values; because these thresholds directly control the dynamic optimization variable, their ad-hoc nature risks making the performance gains dependent on tuning rather than the core leave-one-skill-out mechanism.
Authors: The thresholds were initially set via a small validation sweep on held-out episodes to achieve stable operation counts. In the revision we have added a sensitivity study in the appendix that perturbs each threshold by ±25 % and shows that average task success varies by at most 1.9 percentage points on both benchmarks. We have also inserted a short justification paragraph in the method section explaining the choice in terms of the observed distribution of marginal contribution scores during training. These changes demonstrate that the reported gains are not brittle to reasonable threshold variation. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper defines SLIM as a joint optimization framework that estimates marginal skill contributions via leave-one-skill-out validation and applies retain/retire/expand operations, with all performance claims resting on external experimental comparisons (7.1% average gain on ALFWorld and SearchQA) rather than any derivation that reduces to fitted inputs or self-referential definitions. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way that collapses the central result to its own assumptions by construction. The derivation chain remains self-contained and falsifiable against independent benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- contribution thresholds for retain/retire/expand
axioms (2)
- domain assumption The optimal active skill set is non-monotonic, task- and stage-dependent
- domain assumption Leave-one-skill-out validation accurately estimates marginal external contribution
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE style optimization for learning from human feedback in LLMs.arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges.arXiv preprint arXiv:2402.00157, 2024
-
[3]
Physics of language models: Part 3.1, knowledge storage and extraction
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.1, knowledge storage and extraction. InProceedings of the 41st International Conference on Machine Learning, pages 1067–1077, Vienna, Austria, 2024
work page 2024
-
[4]
Physics of language models: Part 3.2, knowledge manip- ulation
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.2, knowledge manip- ulation. InProceedings of the 13th International Conference on Learning Representations, Singapore, Singapore, 2025
work page 2025
-
[5]
Physics of language models: Part 3.3, knowledge capacity scaling laws
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws. InProceedings of the 13th International Conference on Learning Representations, Singapore, Singapore, 2025
work page 2025
-
[6]
Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku
Anthropic. Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku. https: //www.anthropic.com/news/3-5-models-and-computer-use, 2024
work page 2024
-
[7]
Anthropic. Agent skills. https://docs.claude.com/en/docs/agents-and-tools/ agent-skills, 2025
work page 2025
-
[8]
SkVM: Revisiting Language VM for Skills across Heterogenous LLMs and Harnesses
Le Chen, Erhu Feng, Yubin Xia, and Haibo Chen. Skvm: Revisiting language vm for skills across heterogenous llms and harnesses.arXiv preprint arXiv:2604.03088, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, Yang Tian, Bin Wang, Bolun Wang, Fangjing Wang, Hanqing Wang, Tai Wang, Ziqin Wang, Xueyuan Wei, Chao Wu, Shuai Yang, Jinhui Ye, Junqiu Yu, Jia Zeng, Jingjing Zhang, Jinyu Zhang, Shi Zhang, Feng Zheng, Bowen Zhou, and Yangkun Zhu. Internvla-m1: A ...
work page internal anchor Pith review arXiv 2025
-
[10]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
work page 2024
-
[12]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page 2025
-
[13]
Yao Fu, Dong-Ki Kim, Jaekyeom Kim, Sungryull Sohn, Lajanugen Logeswaran, Kyunghoon Bae, and Honglak Lee. Autoguide: Automated generation and selection of context-aware guidelines for large language model agents.arXiv preprint arXiv:2403.08978, 2024
-
[14]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. InProceedings of the 36th International Conference on Machine Learning, pages 2052–2062, Long Beach, CA, 2019
work page 2052
-
[15]
Synthetic data generation & multi-step rl for reasoning & tool use,
Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, and Christopher D Manning. Synthetic data generation & multi-step rl for reasoning & tool use.arXiv preprint arXiv:2504.04736, 2025
-
[16]
Gemini Deep Research — your personal research assistant
Google. Gemini Deep Research — your personal research assistant. https://gemini. google/overview/deep-research/, 2025
work page 2025
-
[17]
SRSA: skill retrieval and adaptation for robotic assembly tasks
Yijie Guo, Bingjie Tang, Iretiayo Akinola, Dieter Fox, Abhishek Gupta, and Yashraj Narang. SRSA: skill retrieval and adaptation for robotic assembly tasks. InProceedings of the 13th International Conference on Learning Representations, Singapore, Singapore, 2025. OpenRe- view.net
work page 2025
-
[18]
Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. InAdvances in Neural Information Processing Systems 36, New Orleans, LA, 2023
work page 2023
-
[19]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 6864–6890, Bangkok, Thailand, 2024
work page 2024
-
[20]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain, 2020
work page 2020
-
[21]
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American Statistical Association, 58(301):13–30, 1963
work page 1963
-
[22]
Understanding the planning of LLM agents: A survey
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InProceedings of the 2nd Conference on Language Modeling, Montreal, Canada, 2025. 11
work page 2025
-
[24]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601–1611, Vancouver, Canada, 2017
work page 2017
-
[25]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
work page 2019
-
[26]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks.Advances in Neural Information Processing Systems 33, pages 9459–9474, 2020
work page 2020
-
[27]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Chatsop: An sop-guided mcts planning framework for controllable llm dialogue agents
Zhigen Li, Jianxiang Peng, Yanmeng Wang, Yong Cao, Tianhao Shen, Minghui Zhang, Linxi Su, Shang Wu, Yihang Wu, YuQian Wang, Ye Wang, Wei Hu, Jianfeng Li, Shaojun Wang, Jing Xiao, and Deyi Xiong. Chatsop: An sop-guided mcts planning framework for controllable llm dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational...
work page 2025
-
[29]
Minhua Lin, Zongyu Wu, Zhichao Xu, Hui Liu, Xianfeng Tang, Qi He, Charu Aggarwal, Hui Liu, Xiang Zhang, and Suhang Wang. A comprehensive survey on reinforcement learning-based agentic search: Foundations, roles, optimizations, evaluations, and applications.arXiv preprint arXiv:2510.16724, 2025
-
[30]
Skillact: Using skill abstractions improves llm agents
Anthony Zhe Liu, Jongwook Choi, Sungryull Sohn, Yao Fu, Jaekyeom Kim, Dong-Ki Kim, Xinhe Wang, Jaewon Yu, and Honglak Lee. Skillact: Using skill abstractions improves llm agents. InICML 2024 Workshop on LLMs and Cognition, Vienna, Austria, 2024
work page 2024
-
[31]
arXiv preprint arXiv:2601.02553 , year=
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for LLM agents.arXiv preprint arXiv:2601.02553, 2026
-
[32]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
work page 2024
-
[33]
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Skill0: In-context agentic reinforcement learning for skill internalization.arXiv preprint arXiv:2604.02268, 2026
-
[34]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. Large language model agent: A surve...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 9802–9822, Toronto, Canada, 2023
work page 2023
-
[36]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Skill-pro: Learning reusable skills from experience via non-parametric ppo for llm agents.arXiv preprint arXiv:2602.01869, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Erchao Zhao, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
OpenAI. Computer-using agent. https://openai.com/index/computer-using-agent/, 2025
work page 2025
-
[39]
OpenAI. Deep research system card. https://openai.com/index/ deep-research-system-card, 2025
work page 2025
-
[40]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis. InAdvances in Neural Information Processing Systems 37, Vancouver, Canada, 2024
work page 2024
-
[41]
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, and Thomas Bäck. Multi-step reasoning with large language models, a survey.ACM Computing Surveys, 58(6): 160:1–160:35, 2026
work page 2026
-
[42]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore, 2023
work page 2023
-
[43]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. InProceedings of the 12th International Conference...
work page 2024
-
[44]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems 36, New Orleans, LA, 2023
work page 2023
-
[45]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Semi-off-policy reinforcement learning for vision- language slow-thinking reasoning
Junhao Shen, Haiteng Zhao, Yuzhe Gu, Songyang Gao, Kuikun Liu, Haian Huang, Jianfei Gao, Dahua Lin, Wenwei Zhang, and Kai Chen. Semi-off-policy reinforcement learning for vision- language slow-thinking reasoning. InAdvances in Neural Information Processing Systems 38, San Diego, CA, 2025
work page 2025
-
[48]
Llm with tools: A survey.arXiv preprint arXiv:2409.18807,
Zhuocheng Shen. Llm with tools: A survey.arXiv preprint arXiv:2409.18807, 2024
-
[49]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems 36, New Orleans, LA, USA, 2023
work page 2023
-
[50]
Alfworld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. InProceedings of the 9th International Conference on Learning Representations, Virtual Conference, 2021
work page 2021
-
[51]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[52]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6): 186345, 2024
work page 2024
-
[54]
WebXSkill: Skill Learning for Autonomous Web Agents
Zhaoyang Wang, Qianhui Wu, Xuchao Zhang, Chaoyun Zhang, Wenlin Yao, Fazle Elahi Faisal, Baolin Peng, Si Qin, Suman Nath, Qingwei Lin, Chetan Bansal, Dongmei Zhang, Saravan Rajmohan, Jianfeng Gao, and Huaxiu Yao. Webxskill: Skill learning for autonomous web agents.arXiv preprint arXiv:2604.13318, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024
work page internal anchor Pith review arXiv 2024
-
[56]
Reinforcing multi-turn reasoning in llm agents via turn-level reward design, 2025
Quan Wei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, Wei Deng, Anderson Schneider, Yuriy Nevmyvaka, Yang Katie Zhao, Alfredo Garcia, and Mingyi Hong. Reinforcing multi-turn reasoning in llm agents via turn-level reward design.arXiv preprint arXiv:2505.11821, 2025
-
[57]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, and Dinesh Manocha. Co-evolving llm decision and skill bank agents for long-horizon tasks.arXiv preprint arXiv:2604.20987, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review arXiv 2026
-
[60]
Liu, Yiheng Xu, Hongjin Su, Dongchan Shin, Caiming Xiong, and Tao Yu
Tianbao Xie, Fan Zhou, Zhoujun Cheng, Peng Shi, Luoxuan Weng, Yitao Liu, Toh Jing Hua, Junning Zhao, Qian Liu, Che Liu, Leo Z. Liu, Yiheng Xu, Hongjin Su, Dongchan Shin, Caiming Xiong, and Tao Yu. Openagents: An open platform for language agents in the wild. In Proceedings of the 1st Conference on Language Modeling, Philadelphia, PA, 2024
work page 2024
-
[61]
Towards large reasoning models: A survey of reinforced reasoning with large language models
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, and Yong Li. Towards large reasoning models: A survey of reinforced reasoning with large language models.arXiv preprin...
-
[62]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium, 2018
work page 2018
-
[65]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InProceedings of the 11th International Conference on Learning Representations (ICLR), Kigali, Rwanda, 2023. 14
work page 2023
-
[66]
Sop-agent: Empower general purpose ai agent with domain-specific sops
Anbang Ye, Qianran Ma, Jia Chen, Muqi Li, Tong Li, Fujiao Liu, Siqi Mai, Meichen Lu, Haitao Bao, and Yang You. Sop-agent: Empower general purpose ai agent with domain-specific sops. arXiv preprint arXiv:2501.09316, 2025
-
[67]
Tik Yu Yim, Wenting Tan, Sum Yee Chan, Tak-Wah Lam, and Siu Ming Yiu. Asda: Automated skill distillation and adaptation for financial reasoning.arXiv preprint arXiv:2603.16112, 2026
-
[68]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, Feiyu Xiong, Yutao Qi, Bo Tang, and Muning Wen. Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026
-
[70]
Experience Compression Spectrum: Unifying Memory, Skills, and Rules in LLM Agents
Xing Zhang, Guanghui Wang, Yanwei Cui, Wei Qiu, Ziyuan Li, Bing Zhu, and Peiyang He. Experience compression spectrum: Unifying memory, skills, and rules in llm agents.arXiv preprint arXiv:2604.15877, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[71]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embed- ding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the 38th AAAI Conference on Artificial Intelligence, pages 19632–19642, Vancouver, Canada, 2024
work page 2024
-
[73]
Haiteng Zhao, Junhao Shen, Yiming Zhang, Songyang Gao, Kuikun Liu, Tianyou Ma, Fan Zheng, Dahua Lin, Wenwei Zhang, and Kai Chen. Achieving olympia-level geometry large language model agent via complexity boosting reinforcement learning. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
work page 2026
-
[74]
Qingfei Zhao, Ruobing Wang, Dingling Xu, Daren Zha, and Limin Liu. R-search: Em- powering llm reasoning with search via multi-reward reinforcement learning.arXiv preprint arXiv:2506.04185, 2025
-
[75]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. Skillweaver: Web agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079, 2025
work page internal anchor Pith review arXiv 2025
-
[76]
YanZhao Zheng, ZhenTao Zhang, Chao Ma, YuanQiang Yu, JiHuai Zhu, Yong Wu, Tianze Xu, Baohua Dong, Hangcheng Zhu, Ruohui Huang, and Gang Yu. Skillrouter: Skill routing for llm agents at scale.arXiv preprint arXiv:2603.22455, 2026
-
[77]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, Congming Zheng, Jiachen Zhu, Zeyu Zheng, Zhuosheng Zhang, Xingyu Lou, Changwang Zhang, Zhihui Fu, Jun Wang, Weiwen Liu, Jianghao Lin, and Weinan Zhang. Externalization in llm agents: A unified review of memory, skills, protocols an...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
### TASK: {task_type} ### For {readable_task} tasks, apply these specific strategies:
{title}: {principle} Apply this when {when_to_apply} ... ### TASK: {task_type} ### For {readable_task} tasks, apply these specific strategies:
-
[79]
Figure A5: Skill insertion format used by SLIM and skill-conditioned baselines
{title}: {principle} Apply this when {when_to_apply} ... Figure A5: Skill insertion format used by SLIM and skill-conditioned baselines. General skills are inserted as a group when active, while task-specific skills are retrieved by task type and semantic similarity. Title: Zero-Shot and Few-Shot Prompting Zero-shot: {obs_text} Few-shot prefix: Below are ...
-
[80]
Routing-oriented description
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.