Recognition: no theorem link
Can VLMs Truly Forget? Benchmarking Training-Free Visual Concept Unlearning
Pith reviewed 2026-05-13 19:44 UTC · model grok-4.3
The pith
VLMs do not truly forget visual concepts under realistic unlearning prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
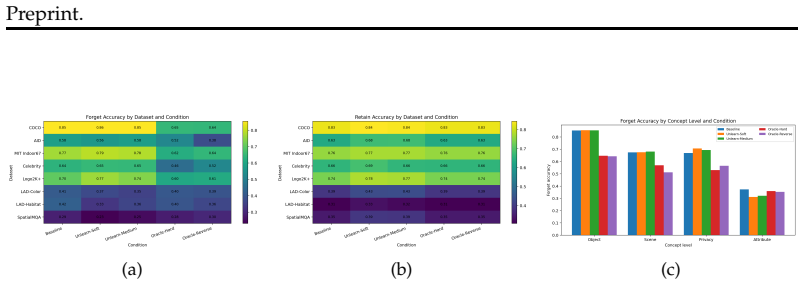
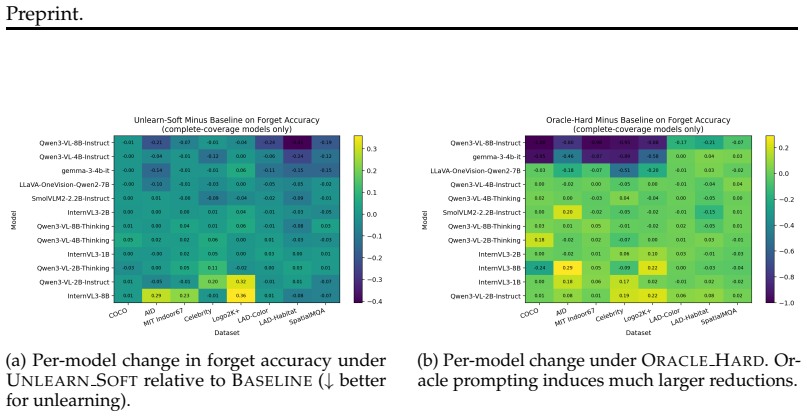
Across eight evaluation settings and thirteen VLM configurations, realistic unlearning prompts leave forget accuracy near the no-instruction baseline; meaningful reductions appear only under oracle conditions that disclose the target concept to the model. Object and scene concepts prove most resistant, and stronger instruction-tuned models stay capable even when given explicit forget instructions.
What carries the argument
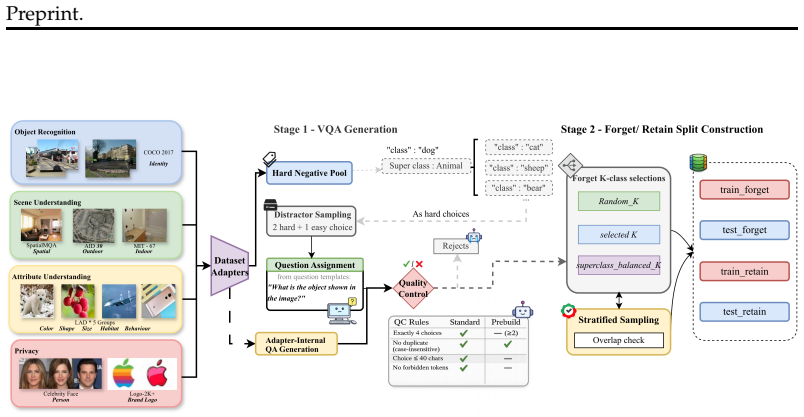
VLM-UnBench benchmark, which pairs four forgetting levels, seven source datasets, eleven concept axes, a three-level probe taxonomy, and five evaluation conditions to isolate genuine forgetting from mere instruction compliance.
If this is right
- Object and scene concepts resist prompt suppression more than other concept types.
- Stronger instruction-tuned models remain harder to suppress than weaker ones.
- Training-based unlearning methods may still be required to achieve reliable concept removal.
- Safety techniques that rely only on system prompts cannot be trusted to prevent recognition of sensitive visual content.
Where Pith is reading between the lines
- Safety layers built solely on user or system prompts are likely insufficient to block unwanted visual outputs in deployed VLMs.
- Data curation or training-time filtering may be necessary instead of post-hoc prompt interventions.
- Future work could test whether combining light fine-tuning with prompts closes the observed gap.
- The same benchmark setup could be applied to test whether any training-free method, beyond simple prompts, can produce true erasure.
Load-bearing premise
The three-level probe taxonomy and five evaluation conditions can separate actual visual concept erasure from the model simply obeying surface-level instructions.
What would settle it
A realistic unlearning prompt that produces a large, consistent drop in forget accuracy below the no-instruction baseline across multiple models and concepts, without ever naming the target concept, would falsify the central finding.
Figures


read the original abstract
VLMs trained on web-scale data retain sensitive and copyrighted visual concepts that deployment may require removing. Training-based unlearning methods share a structural flaw: fine-tuning on a narrow forget set degrades general capabilities before unlearning begins, making it impossible to attribute subsequent performance drops to the unlearning procedure itself. Training-free approaches sidestep this by suppressing concepts through prompts or system instructions, but no rigorous benchmark exists for evaluating them on visual tasks. We introduce VLM-UnBench, the first benchmark for training-free visual concept unlearning in VLMs. It covers four forgetting levels, 7 source datasets, and 11 concept axes, and pairs a three-level probe taxonomy with five evaluation conditions to separate genuine forgetting from instruction compliance. Across 8 evaluation settings and 13 VLM configurations, realistic unlearning prompts leave forget accuracy near the no-instruction baseline; meaningful reductions appear only under oracle conditions that disclose the target concept to the model. Object and scene concepts are the most resistant to suppression, and stronger instruction-tuned models remain capable despite explicit forget instructions. These results expose a clear gap between prompt-level suppression and true visual concept erasure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLM-UnBench, the first benchmark for training-free visual concept unlearning in VLMs. It spans four forgetting levels, 7 source datasets, 11 concept axes, a three-level probe taxonomy, and five evaluation conditions designed to isolate genuine forgetting from instruction compliance. Across 8 evaluation settings and 13 VLM configurations, the central empirical result is that realistic unlearning prompts produce forget accuracy near the no-instruction baseline, while only oracle prompts that explicitly name the target concept yield meaningful reductions; object and scene concepts are the most resistant, and stronger instruction-tuned models remain capable despite explicit forget instructions.
Significance. If the separation between genuine erasure and prompt compliance holds, the work provides clear evidence of a gap between prompt-level suppression and true visual concept erasure in VLMs. This has direct implications for privacy, copyright, and safety in deployed models. The broad experimental matrix (multiple datasets, concept axes, models, and conditions) and the new benchmark itself are strengths that would enable reproducible follow-up work; the paper ships a standardized evaluation framework rather than isolated case studies.
major comments (2)
- [Probe Taxonomy and Evaluation Conditions] The central claim—that realistic unlearning prompts leave forget accuracy near the no-instruction baseline while only oracle conditions produce reductions—rests on the three-level probe taxonomy and five evaluation conditions successfully distinguishing retained visual knowledge from instruction-driven suppression. If probes (visual QA, classification, or generation tasks) share the same system prompt context as the forget instruction, observed compliance could be surface-level prompt following rather than evidence of internal retention. An orthogonal probe format that removes the forget instruction entirely would be needed to confirm the separation.
- [Results on Concept Resistance] The finding that object and scene concepts are most resistant is load-bearing for the broader conclusion about differential resistance across concept axes. The manuscript should report the exact forget-accuracy deltas (with standard errors) relative to the no-instruction baseline for these categories in the primary results table or figure to allow assessment of effect size and statistical reliability.
minor comments (2)
- [Benchmark Construction] Clarify the operational definitions of the four forgetting levels and how they map to the 11 concept axes; a small table or diagram would improve readability.
- [Terminology] Ensure consistent terminology for 'forget accuracy' versus 'baseline accuracy' across the abstract, methods, and results sections.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped clarify key aspects of our evaluation framework and results presentation. We address each major comment below and have revised the manuscript accordingly where changes were warranted.
read point-by-point responses
-
Referee: [Probe Taxonomy and Evaluation Conditions] The central claim—that realistic unlearning prompts leave forget accuracy near the no-instruction baseline while only oracle conditions produce reductions—rests on the three-level probe taxonomy and five evaluation conditions successfully distinguishing retained visual knowledge from instruction-driven suppression. If probes (visual QA, classification, or generation tasks) share the same system prompt context as the forget instruction, observed compliance could be surface-level prompt following rather than evidence of internal retention. An orthogonal probe format that removes the forget instruction entirely would be needed to confirm the separation.
Authors: We appreciate the referee's emphasis on rigorously separating instruction compliance from genuine retention. Our five evaluation conditions were designed precisely for this purpose and include dedicated settings in which the forget instruction is entirely absent from the system prompt during probing (e.g., the no-instruction baseline and a post-forget probe-only condition). These provide the orthogonal format requested. To make this design choice more transparent, we will expand the description of each condition in Section 3.3 and add a brief ablation confirming that probe performance remains stable when the forget instruction is removed from context. We believe the existing framework already addresses the concern, but the added exposition will strengthen the presentation. revision: partial
-
Referee: [Results on Concept Resistance] The finding that object and scene concepts are most resistant is load-bearing for the broader conclusion about differential resistance across concept axes. The manuscript should report the exact forget-accuracy deltas (with standard errors) relative to the no-instruction baseline for these categories in the primary results table or figure to allow assessment of effect size and statistical reliability.
Authors: We agree that explicit deltas with standard errors will improve the reader's ability to assess effect sizes. We have updated the primary results table (Table 2) to include the forget-accuracy deltas and standard errors for object and scene concepts relative to the no-instruction baseline across all evaluation conditions. These values are now reported alongside the raw accuracies. revision: yes
Circularity Check
No circularity: purely empirical benchmark with independent evaluation conditions
full rationale
The paper introduces VLM-UnBench as an empirical benchmark for training-free visual concept unlearning, reporting results across 8 evaluation settings, 13 VLM configurations, 7 datasets, and 11 concept axes. It defines a three-level probe taxonomy and five evaluation conditions to distinguish genuine forgetting from instruction compliance, with all measurements taken directly from model outputs under controlled prompts. No equations, derivations, fitted parameters, or self-referential reductions appear in the presented work; central claims rest on observed accuracy differences (e.g., near-baseline forget accuracy under realistic prompts) rather than any chain that collapses to its own inputs by construction. Any self-citations are incidental and non-load-bearing for the empirical findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Accuracy on probe tasks is a valid proxy for whether a visual concept has been retained or erased.
invented entities (1)
-
VLM-UnBench benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025a. Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zha...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Towards making systems forget with machine unlearning
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE symposium on security and privacy, pp. 463–480. IEEE,
work page 2015
-
[3]
Mingqian Feng, Yunlong Tang, Zeliang Zhang, and Chenliang Xu. Do more details al- ways introduce more hallucinations in lvlm-based image captioning?arXiv preprint arXiv:2406.12663,
-
[4]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024a. Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, e...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121,
-
[6]
11 Preprint. Andr´es Marafioti, Orr Zohar, Miquel Farr ´e, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:...
work page internal anchor Pith review arXiv
-
[7]
In-context unlearning: Language models as few shot unlearners.arXiv preprint arXiv:2310.07579,
Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju. In-context unlearning: Language models as few shot unlearners.arXiv preprint arXiv:2310.07579,
-
[8]
Muse: Machine unlearning six-way evaluation for language models.arXiv preprint arXiv:2407.06460,
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A Smith, and Chiyuan Zhang. Muse: Machine unlearning six-way evaluation for language models.arXiv preprint arXiv:2407.06460,
-
[9]
Pratiksha Thaker, Yash Maurya, Shengyuan Hu, Zhiwei Steven Wu, and Virginia Smith
URLhttps://goo.gle/Gemma3Report. Pratiksha Thaker, Yash Maurya, Shengyuan Hu, Zhiwei Steven Wu, and Virginia Smith. Guardrail baselines for unlearning in llms.arXiv preprint arXiv:2403.03329,
-
[10]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Aid: A benchmark dataset for perfor- mance evaluation of aerial scene classification
G Xia, J Hu, F Hu, B Shi, X Bai, Y Zhong, and L Zhang. Aid: A benchmark dataset for perfor- mance evaluation of aerial scene classification. arxiv 2016.arXiv preprint arXiv:1608.05167,
-
[12]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it? arXiv preprint arXiv:2210.01936,
-
[13]
Can clip count stars? an empirical study on quantity bias in clip
Zeliang Zhang, Zhuo Liu, Mingqian Feng, and Chenliang Xu. Can clip count stars? an empirical study on quantity bias in clip. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 1081–1086, 2024a. Zeliang Zhang, Phu Pham, Wentian Zhao, Kun Wan, Yu-Jhe Li, Jianing Zhou, Daniel Miranda, Ajinkya Kale, and Chenliang Xu. Treat visual tok...
-
[14]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
13 Preprint. A Complete experimental results Table 3: Combined results on AID, Celebrity, COCO, LAD-Color, LAD-Habitat, Logo2K+, MIT Indoor67, and SpatialMQA. We report forget macro accuracy (F) and retain accuracy (R). Dataset Model Baseline Oracle-Hard Oracle-Reverse Unlearn-Medium Unlearn-Soft F R F R F R F R F R AID gemma-3-4b-it 0.7360 0.8667 0.2760 ...
work page 1900
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.