Recognition: no theorem link
Domain-Adapted Retrieval for In-Context Annotation of Pedagogical Dialogue Acts
Pith reviewed 2026-05-13 20:25 UTC · model grok-4.3
The pith
Domain-adapted retrieval with utterance-level indexing lets frozen LLMs annotate pedagogical dialogues at expert agreement levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
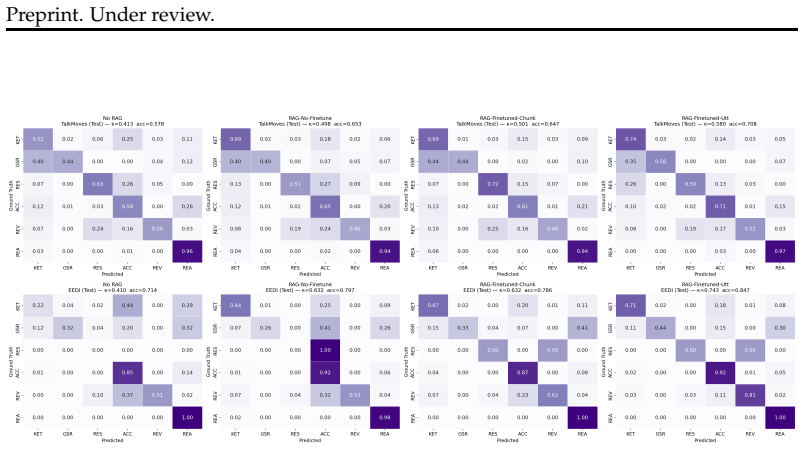
The domain-adapted RAG pipeline, using a fine-tuned lightweight embedding model on tutoring corpora and utterance-level indexing to retrieve labeled demonstrations, achieves Cohen's κ of 0.526-0.580 on TalkMoves and 0.659-0.743 on Eedi with three different LLMs, outperforming no-retrieval baselines while correcting label biases and improving rare labels, with utterance-level indexing driving the gains.
What carries the argument
Domain-adapted retrieval pipeline that fine-tunes a lightweight embedding model and indexes dialogues at the utterance level to provide in-context labeled examples to a frozen generative LLM.
If this is right
- Utterance-level indexing improves top-1 label match rates from 39.7% to 62.0% on TalkMoves and 52.9% to 73.1% on Eedi.
- Retrieval corrects systematic label biases in zero-shot prompting.
- Largest gains are seen for rare and context-dependent labels.
- The generative model can remain frozen while still reaching higher annotation quality.
Where Pith is reading between the lines
- Similar retrieval adaptation could scale annotation to much larger tutoring corpora where manual labeling is prohibitive.
- The dominance of indexing strategy over embedding quality suggests prioritizing dialogue segmentation in future retrieval designs.
- Applying this to other specialized dialogue domains like medical or legal conversations may yield comparable efficiency gains.
- Testing on additional datasets would confirm if the method generalizes to varied tutoring styles.
Load-bearing premise
That the gains from utterance-level domain-adapted retrieval will persist when applied to new tutoring datasets or different large language models not tested in the study.
What would settle it
Running the pipeline on a new independent set of tutoring dialogues with a fourth LLM and observing kappa scores no higher than the no-retrieval baseline.
Figures



read the original abstract
Automated annotation of pedagogical dialogue is a high-stakes task where LLMs often fail without sufficient domain grounding. We present a domain-adapted RAG pipeline for tutoring move annotation. Rather than fine-tuning the generative model, we adapt retrieval by fine-tuning a lightweight embedding model on tutoring corpora and indexing dialogues at the utterance level to retrieve labeled few-shot demonstrations. Evaluated across two real tutoring dialogue datasets (TalkMoves and Eedi) and three LLM backbones (GPT-5.2, Claude Sonnet 4.6, Qwen3-32b), our best configuration achieves Cohen's $\kappa$ of 0.526-0.580 on TalkMoves and 0.659-0.743 on Eedi, substantially outperforming no-retrieval baselines ($\kappa = 0.275$-$0.413$ and $0.160$-$0.410$). An ablation study reveals that utterance-level indexing, rather than embedding quality alone, is the primary driver of these gains, with top-1 label match rates improving from 39.7\% to 62.0\% on TalkMoves and 52.9\% to 73.1\% on Eedi under domain-adapted retrieval. Retrieval also corrects systematic label biases present in zero-shot prompting and yields the largest improvements for rare and context-dependent labels. These findings suggest that adapting the retrieval component alone is a practical and effective path toward expert-level pedagogical dialogue annotation while keeping the generative model frozen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a domain-adapted RAG pipeline for annotating pedagogical dialogue acts: a lightweight embedding model is fine-tuned on tutoring corpora, dialogues are indexed at the utterance level, and the resulting labeled demonstrations are retrieved as few-shot context for frozen LLMs. Evaluated on TalkMoves and Eedi with GPT-5.2, Claude Sonnet 4.6 and Qwen3-32b, the best configuration reports Cohen’s κ of 0.526–0.580 and 0.659–0.743 respectively, outperforming no-retrieval baselines; an ablation attributes the gains primarily to utterance-level indexing rather than embedding quality alone.
Significance. If the retrieval index is strictly disjoint from the test sets, the work supplies concrete evidence that retrieval adaptation alone can lift annotation quality on two real tutoring corpora without touching the generative model, together with an ablation that isolates the contribution of utterance-level indexing. The reported top-1 label match rates (62–73 %) and bias-correction effects on rare labels constitute useful, falsifiable benchmarks for future in-context annotation systems.
major comments (2)
- [§4] §4 (Experimental Setup) and the abstract: it is not stated whether the TalkMoves and Eedi test utterances (or their labels) were excluded from the tutoring corpora used to fine-tune the embedding model and to build the retrieval index. If any test utterance is retrievable, the reported κ gains (0.526–0.743 vs. 0.160–0.413) and the utterance-level vs. embedding-quality ablation become unreliable due to label leakage.
- [§5.2] §5.2 (Ablation Study): the contrast between “utterance-level indexing” and “embedding quality alone” presupposes that both conditions operate on identical held-out data; without an explicit statement that the index for the embedding-only condition also excludes test utterances, the claim that indexing is the primary driver cannot be evaluated.
minor comments (2)
- [§5] The abstract and §5 omit statistical significance tests (e.g., paired t-tests or bootstrap CIs) for the κ differences; adding these would strengthen the performance claims.
- [§4] Data-split sizes, exact number of utterances per corpus, and the precise train/validation/test partitioning are not reported in §4; these details are needed to reproduce the index construction.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for explicit statements on data partitioning. We address each major comment below and will revise the manuscript to add the requested clarifications.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup) and the abstract: it is not stated whether the TalkMoves and Eedi test utterances (or their labels) were excluded from the tutoring corpora used to fine-tune the embedding model and to build the retrieval index. If any test utterance is retrievable, the reported κ gains (0.526–0.743 vs. 0.160–0.413) and the utterance-level vs. embedding-quality ablation become unreliable due to label leakage.
Authors: We confirm that the test utterances (and their labels) from both TalkMoves and Eedi were strictly excluded from the corpora used to fine-tune the embedding model and to construct the retrieval index. Only the designated training splits were used for domain adaptation. We will add an explicit statement to this effect in the revised §4 and abstract. revision: yes
-
Referee: [§5.2] §5.2 (Ablation Study): the contrast between “utterance-level indexing” and “embedding quality alone” presupposes that both conditions operate on identical held-out data; without an explicit statement that the index for the embedding-only condition also excludes test utterances, the claim that indexing is the primary driver cannot be evaluated.
Authors: All ablation conditions, including the embedding-only baseline, were evaluated on the same held-out test sets and used an index built exclusively from the training splits (i.e., test utterances were excluded in every condition). We will insert a clarifying sentence in §5.2 stating that index construction with respect to test-set exclusion is identical across the compared conditions. revision: yes
Circularity Check
No circularity: purely empirical evaluation on held-out data
full rationale
The paper reports an empirical RAG pipeline for dialogue act annotation, with performance measured via Cohen's κ and top-1 match rates on two fixed tutoring datasets (TalkMoves, Eedi) using held-out test splits and three LLM backbones. All claims rest on direct experimental comparisons to no-retrieval baselines and ablations (utterance-level indexing vs. embedding quality). No derivations, equations, or predictions are present that reduce to fitted parameters by construction, self-definitional loops, or load-bearing self-citations. The work is self-contained against external benchmarks and contains no mathematical chain or uniqueness theorem that collapses to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, and Hugo Larochelle
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, and Hugo Larochelle. Many-shot in-context learning. In Advances in Neural Information Processing Systems, 2024
work page 2024
- [3]
-
[4]
Human and llm-based assessment of teaching acts in expert-led explanatory dialogues
Aliki Anagnostopoulou, Nils Feldhus, Yi-Sheng Hsu, Milad Alshomary, Henning Wachsmuth, and Daniel Sonntag. Human and llm-based assessment of teaching acts in expert-led explanatory dialogues. In Proceedings of the 6th Workshop on Computational Approaches to Discourse, pp.\ 166--181, 2025
work page 2025
-
[5]
Llm2vec: Large language models are secretly powerful text encoders
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. Llm2vec: Large language models are secretly powerful text encoders. In Proceedings of the 1st Conference on Language Modeling, 2024
work page 2024
-
[6]
Rethinking chunk size for long-document retrieval: A multi-dataset analysis
Sinchana Ramakanth Bhat, Max Rudat, Jannis Spiekermann, and Nicolas Flores-Herr. Rethinking chunk size for long-document retrieval: A multi-dataset analysis. arXiv preprint arXiv:2505.21700, 2025
-
[7]
Retrieval-style in-context learning for few-shot hierarchical text classification, 2024
Huiyao Chen, Yu Zhao, Zulong Chen, Mengjia Wang, Liangyue Li, Meishan Zhang, and Min Zhang. Retrieval-style in-context learning for few-shot hierarchical text classification, 2024. URL https://arxiv.org/abs/2406.17534
-
[8]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 15607--15631, Toronto, Canada, July 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.acl-long.870. URL https://acla...
-
[9]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A survey on in-context learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[10]
Annollm: Making large language models to be better crowdsourced annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, and Weizhu Chen. Annollm: Making large language models to be better crowdsourced annotators. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: ...
work page 2024
-
[11]
Efficient natural language response suggestion for smart reply
Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun-Hsuan Sung, L \'a szl \'o Luk \'a cs, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. Efficient natural language response suggestion for smart reply. 2017. URL https://arxiv.org/abs/1705.00652
-
[12]
Emily Jensen, Samuel L. Pugh, and Sidney K. D'Mello. A deep transfer learning approach to modeling teacher discourse in the classroom. In Proceedings of the 11th International Learning Analytics and Knowledge Conference, pp.\ 302--312, 2021
work page 2021
-
[13]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Herv \'e J \'e gou. Billion-scale similarity search with GPUs . IEEE Transactions on Big Data, 7 0 (3): 0 535--547, 2021
work page 2021
-
[14]
Unraveling chatgpt: A critical analysis of ai-generated goal-oriented dialogues and annotations
Tiziano Labruna, Sofia Brenna, Andrea Zaninello, and Bernardo Magnini. Unraveling chatgpt: A critical analysis of ai-generated goal-oriented dialogues and annotations. In International Conference of the Italian Association for Artificial Intelligence, pp.\ 151--171. Springer, 2023
work page 2023
-
[15]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K\" u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt\" a schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, volume 33, pp.\ 9459--9474, 2020
work page 2020
-
[16]
Llama2vec: Unsupervised adaptation of large language models for dense retrieval
Chaofan Li, Zheng Liu, Shitao Xiao, Yingxia Shao, and Defu Lian. Llama2vec: Unsupervised adaptation of large language models for dense retrieval. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024 a
work page 2024
-
[17]
On the role of long-tail knowledge in retrieval augmented large language models
Dongyang Li, Junbing Yan, Taolin Zhang, Cheng Wang, Xiaofeng He, Longtao Huang, Hui Xue, and Jun Huang. On the role of long-tail knowledge in retrieval augmented large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Short Papers), 2024 b
work page 2024
-
[18]
Correlating student acoustic-prosodic profiles with student learning in spoken tutoring dialogues
Diane Litman and Kate Forbes-Riley. Correlating student acoustic-prosodic profiles with student learning in spoken tutoring dialogues. In Proceedings of the 12th International Conference on Artificial Intelligence in Education, pp.\ 1--8, 2005
work page 2005
-
[19]
S. Michaels and C. O'Connor. Conceptualizing talk moves as tools: Professional development approaches for academically productive discussions. In Lauren B. Resnick, Christa Asterhan, and Sherice N. Clarke (eds.), Socializing Intelligence through Talk and Dialogue, pp.\ 333--347. American Educational Research Association, Washington DC, 2015
work page 2015
-
[20]
Sarah Michaels, Catherine O'Connor, and Lauren B. Resnick. Deliberative discourse idealized and realized: Accountable talk in the classroom and in civic life. Studies in Philosophy and Education, 27 0 (4): 0 283--297, 2008. doi:10.1007/s11217-007-9071-1
-
[21]
Ying Na and Shihui Feng. Llm-assisted automated deductive coding of dialogue data: leveraging dialogue-specific characteristics to enhance contextual understanding. In International Conference on Artificial Intelligence in Education, pp.\ 248--262. Springer, 2025
work page 2025
-
[22]
Jannatun Naim, Jie Cao, Fareen Tasneem, Jennifer Jacobs, Brent Milne, James Martin, and Tamara Sumner. Towards actionable pedagogical feedback: A multi-perspective analysis of mathematics teaching and tutoring dialogue. In Proceedings of the 18th International Conference on Educational Data Mining, 2025
work page 2025
-
[23]
Lidiia Ostyakova, Veronika Smilga, Kseniia Petukhova, Maria Molchanova, and Daniel Kornev. Chatgpt vs. crowdsourcing vs. experts: Annotating open-domain conversations with speech functions. In Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pp.\ 242--254, 2023
work page 2023
-
[24]
Do LLM s understand dialogues? a case study on dialogue acts
Ayesha Qamar, Jonathan Tong, and Ruihong Huang. Do LLM s understand dialogues? a case study on dialogue acts. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 26219--26237, Vienna, Austria, jul 2025. Association for Computational Linguistics. doi:10.18653/v1/2025.acl-long.1271. URL ht...
-
[25]
Changyong Qi, Longwei Zheng, Yuang Wei, Haoxin Xu, Peiji Chen, and Xiaoqing Gu. Edudcm: a novel framework for automatic educational dialogue classification dataset construction via distant supervision and large language models. Applied Sciences, 15 0 (1): 0 154, 2024
work page 2024
-
[26]
Alexander Scarlatos, Ryan S. Baker, and Andrew Lan. Exploring knowledge tracing in tutor-student dialogues using llms. In Proceedings of the 15th International Learning Analytics and Knowledge Conference, pp.\ 1--10, 2025
work page 2025
-
[27]
Using large language models to generate, validate, and apply user intent taxonomies
Chirag Shah, Ryen White, Reid Andersen, Georg Buscher, Scott Counts, Sarkar Das, Ali Montazer, Sathish Manivannan, Jennifer Neville, Nagu Rangan, et al. Using large language models to generate, validate, and apply user intent taxonomies. ACM Transactions on the Web, 19 0 (3): 0 1--29, 2025
work page 2025
-
[28]
Annotating educational dialog act with data augmentation in online one-on-one tutoring
Dou Shan, Dong Wang, Chen Zhang, Kimberly Britt Kao, and Carol Ka Yuk Chan. Annotating educational dialog act with data augmentation in online one-on-one tutoring. In Proceedings of the 24th International Conference on Artificial Intelligence in Education, pp.\ 473--486, 2023
work page 2023
-
[29]
Hang Su and Jun Ye. Large language models for automating fine-grained speech act annotation: A critical evaluation of gpt-4o and deepseek. Corpus Pragmatics, pp.\ 1--20, 2025
work page 2025
-
[30]
Abhijit Suresh, Jennifer Jacobs, Charis Harty, Margaret Perkoff, James H. Martin, and Tamara Sumner. The talkmoves dataset: K-12 mathematics lesson transcripts annotated for teacher and student discursive moves. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pp.\ 4654--4662, Marseille, France, June 2022. European Language R...
work page 2022
-
[31]
Does informativeness matter? active learning for educational dialogue act classification
Wei Tan et al. Does informativeness matter? active learning for educational dialogue act classification. In Proceedings of the 24th International Conference on Artificial Intelligence in Education, pp.\ 115--127, 2023
work page 2023
-
[32]
Reliable annotations with less effort: Evaluating llm-human collaboration in search clarifications
Leila Tavakoli and Hamed Zamani. Reliable annotations with less effort: Evaluating llm-human collaboration in search clarifications. In Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR), ICTIR '25, pp.\ 92--102. Association for Computing Machinery, 2025. doi:10.1145/3731120.3744574
-
[33]
Vail and Kristy Elizabeth Boyer
Andrew K. Vail and Kristy Elizabeth Boyer. Identifying effective moves in tutoring: On the refinement of dialogue act annotation schemes. In Proceedings of the 12th International Conference on Intelligent Tutoring Systems, pp.\ 199--209, 2014
work page 2014
-
[34]
Document segmentation matters for retrieval-augmented generation
Zhitong Wang, Cheng Gao, Chaojun Xiao, et al. Document segmentation matters for retrieval-augmented generation. In Findings of the Association for Computational Linguistics: ACL 2025, 2025
work page 2025
-
[35]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Ran Xu, Hui Liu, Sreyashi Nag, Zhenwei Dai, Yaochen Xie, Xianfeng Tang, Chen Luo, Yang Li, Joyce C. Ho, Carl Yang, and Qi He. Simrag: Self-improving retrieval-augmented generation for adapting large language models to specialized domains. In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics, 2025
work page 2025
-
[37]
Robust educational dialogue act classifiers with low-resource and imbalanced datasets
Linjuan Yang, Philipp Christmann, and Dragan Gasevic. Robust educational dialogue act classifiers with low-resource and imbalanced datasets. In Proceedings of the 24th International Conference on Artificial Intelligence in Education, pp.\ 114--126, 2023
work page 2023
-
[38]
Danni Yu, Luyang Li, Hang Su, and Matteo Fuoli. Assessing the potential of llm-assisted annotation for corpus-based pragmatics and discourse analysis: The case of apology. International Journal of Corpus Linguistics, 29 0 (4): 0 534--561, 2024
work page 2024
-
[39]
Question-anchored tutoring dialogues
Matthew Zent, Digory Smith, and Simon Woodhead. Question-anchored tutoring dialogues. https://huggingface.co/datasets/Eedi/Question-Anchored-Tutoring-Dialogues-2k, 2025. Eedi dataset. Accessed: 2026-03-29
work page 2025
-
[40]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[41]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[42]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.