Recognition: 2 theorem links
· Lean TheoremCharacterization of Gaussian Universality Breakdown in High-Dimensional Empirical Risk Minimization
Pith reviewed 2026-05-13 18:25 UTC · model grok-4.3
The pith
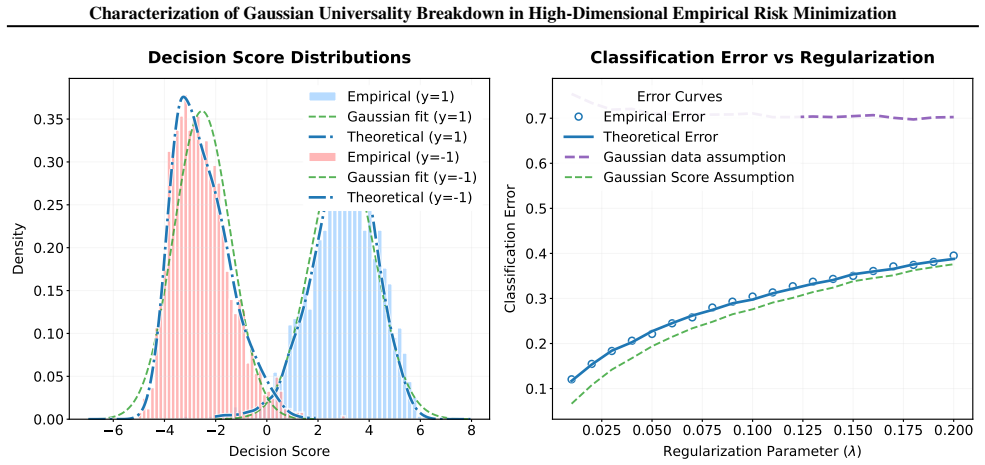
In high-dimensional ERM with non-Gaussian data, the estimator's projection on a test point follows the convolution of a generally non-Gaussian distribution with an independent Gaussian whose variance is set by the trace of the estimator's 2
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a concentration assumption on the data matrix and standard regularity conditions on the loss and regularizer, for a test covariate x independent of the training data, the projection θ̂⊤x approximately follows the convolution of the (generally non-Gaussian) distribution of μ_θ̂⊤x with an independent centered Gaussian variable of variance Tr(C_θ̂ E[xx⊤]). This is obtained by heuristically extending the CGMT to non-Gaussian settings.
What carries the argument
The heuristic extension of the Convex Gaussian Min-Max Theorem to non-Gaussian data designs, which produces an asymptotic min-max characterization of the ERM estimator statistics including its mean and covariance.
If this is right
- Approximations for the mean μ_θ̂ and covariance C_θ̂ of the ERM estimator become available even for non-Gaussian designs.
- Any C² regularizer is asymptotically equivalent to a quadratic form determined solely by its Hessian at zero and gradient at μ_θ̂.
- The result specifies the exact form in which Gaussian universality holds or breaks for projections in ERM.
Where Pith is reading between the lines
- This characterization could guide the design of better uncertainty estimates for models trained on non-Gaussian data such as images or sensor readings.
- Future work might extend the same heuristic to other performance measures like generalization error or to non-convex losses.
- Finite-sample corrections or concentration rates could be derived to make the asymptotic result more practical for moderate dimensions.
Load-bearing premise
The heuristic extension of the Convex Gaussian Min-Max Theorem applies to non-Gaussian data under the stated concentration assumption on the data matrix.
What would settle it
Empirical histograms of θ̂⊤x from simulations with non-Gaussian data that deviate significantly from the predicted convolution distribution would falsify the approximation.
Figures



read the original abstract
We study high-dimensional convex empirical risk minimization (ERM) under general non-Gaussian data designs. By heuristically extending the Convex Gaussian Min-Max Theorem (CGMT) to non-Gaussian settings, we derive an asymptotic min-max characterization of key statistics, enabling approximation of the mean $\mu_{\hat{\theta}}$ and covariance $C_{\hat{\theta}}$ of the ERM estimator $\hat{\theta}$. Specifically, under a concentration assumption on the data matrix and standard regularity conditions on the loss and regularizer, we show that for a test covariate $x$ independent of the training data, the projection $\hat{\theta}^\top x$ approximately follows the convolution of the (generally non-Gaussian) distribution of $\mu_{\hat{\theta}}^\top x$ with an independent centered Gaussian variable of variance $\text{Tr}(C_{\hat{\theta}}\mathbb{E}[xx^\top])$. This result clarifies the scope and limits of Gaussian universality for ERMs. Additionally, we prove that any $\mathcal{C}^2$ regularizer is asymptotically equivalent to a quadratic form determined solely by its Hessian at zero and gradient at $\mu_{\hat{\theta}}$. Numerical simulations across diverse losses and models are provided to validate our theoretical predictions and qualitative insights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that under a concentration assumption on the data matrix and standard regularity conditions on the loss and regularizer, a heuristic extension of the Convex Gaussian Min-Max Theorem (CGMT) to non-Gaussian designs yields an asymptotic min-max characterization of high-dimensional convex ERM. This enables approximation of the mean μ_θ̂ and covariance C_θ̂ of the estimator θ̂. Specifically, for a test covariate x independent of training data, θ̂^T x approximately follows the convolution of the (generally non-Gaussian) distribution of μ_θ̂^T x with an independent centered Gaussian of variance Tr(C_θ̂ E[xx^T]). The paper additionally proves that any C² regularizer is asymptotically equivalent to a quadratic form determined by its Hessian at zero and gradient at μ_θ̂, with numerical simulations provided for validation.
Significance. If the heuristic CGMT extension can be justified with controllable error, the work would clarify the scope and limits of Gaussian universality for ERMs by supplying explicit distributional approximations in non-Gaussian settings. The regularizer equivalence result is a clean simplification that could streamline future analyses. The simulations offer qualitative support, though the absence of quantitative error metrics limits the strength of the empirical backing.
major comments (3)
- [Abstract] Abstract and main derivation: the asymptotic min-max characterization and the convolution form for θ̂^T x rest on a heuristic extension of the CGMT under the stated concentration assumption; no proof, concentration inequalities, or remainder terms are supplied to control the non-Gaussian fluctuation terms that the original CGMT exploits, making this step load-bearing for the central claim.
- [Abstract] Abstract: the claim that the projection follows the stated convolution is presented as approximate, yet the manuscript invokes only standard regularity conditions on the loss and regularizer without deriving explicit error bounds or rates for the non-Gaussian case; this leaves the approximation's validity range unquantified.
- [Numerical simulations] Numerical simulations section: the validation of the theoretical predictions is cited, but no error bars, explicit approximation-error metrics, or details on the number of trials are reported, weakening the empirical support for the key non-Gaussian characterization.
minor comments (2)
- [Notation] Notation: ensure uniform definition of the concentration assumption on the data matrix and consistent use of symbols for μ_θ̂ and C_θ̂ across the derivation and statements.
- [References] References: include additional citations to recent results on non-Gaussian high-dimensional statistics to better situate the heuristic extension relative to existing literature.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We clarify below that the core results rely on a heuristic extension of the CGMT, and we address each major point directly while agreeing to strengthen the empirical section.
read point-by-point responses
-
Referee: [Abstract] Abstract and main derivation: the asymptotic min-max characterization and the convolution form for θ̂^T x rest on a heuristic extension of the CGMT under the stated concentration assumption; no proof, concentration inequalities, or remainder terms are supplied to control the non-Gaussian fluctuation terms that the original CGMT exploits, making this step load-bearing for the central claim.
Authors: We agree that the extension is heuristic and that the manuscript supplies no proof, concentration inequalities, or remainder terms controlling the non-Gaussian fluctuations. The concentration assumption on the data matrix is invoked to justify replacing the design with an effective Gaussian one inside the min-max problem, but we do not derive explicit error control. This is an acknowledged limitation of the present analysis; the heuristic is used to obtain the min-max characterization and the convolution form. We will revise the abstract and introduction to state the heuristic character more explicitly and to discuss the role of the concentration assumption. revision: partial
-
Referee: [Abstract] Abstract: the claim that the projection follows the stated convolution is presented as approximate, yet the manuscript invokes only standard regularity conditions on the loss and regularizer without deriving explicit error bounds or rates for the non-Gaussian case; this leaves the approximation's validity range unquantified.
Authors: The convolution is presented as an asymptotic approximation without explicit error bounds or rates. Deriving quantitative rates for the non-Gaussian case would require a substantially more technical analysis of the CGMT extension, which lies outside the scope of this work. The standard regularity conditions on the loss and regularizer are used only to guarantee existence and uniqueness of the min-max problem. We will revise the abstract to qualify the approximation more clearly and to note the absence of explicit rates. revision: partial
-
Referee: [Numerical simulations] Numerical simulations section: the validation of the theoretical predictions is cited, but no error bars, explicit approximation-error metrics, or details on the number of trials are reported, weakening the empirical support for the key non-Gaussian characterization.
Authors: We accept this criticism. In the revised manuscript we will specify the number of Monte Carlo trials (typically 100), add error bars to all plots, and report quantitative approximation-error metrics such as the Kolmogorov-Smirnov statistic and mean absolute deviation between the empirical distribution of θ̂^T x and the predicted convolution. revision: yes
- The absence of a rigorous proof or explicit error bounds for the heuristic CGMT extension under non-Gaussian designs; supplying such a proof would require a major technical development beyond the scope of the present manuscript.
Circularity Check
No circularity: derivation rests on external heuristic assumption rather than self-reduction
full rationale
The paper derives its asymptotic min-max characterization and the convolution form for θ̂⊤x explicitly from a stated heuristic extension of the CGMT together with a concentration assumption on the data matrix and standard regularity conditions. No equation in the provided text reduces the target result to a fitted parameter, a self-citation chain, or a quantity defined in terms of itself. The central claim is not obtained by renaming a known empirical pattern or by smuggling an ansatz through prior self-work; it is presented as following from the heuristic step. Because the load-bearing step is an external modeling assumption rather than an internal tautology, the derivation chain does not exhibit any of the enumerated circularity patterns and receives the default non-circularity score.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption concentration assumption on the data matrix
- domain assumption standard regularity conditions on the loss and regularizer
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By heuristically extending the Convex Gaussian Min-Max Theorem (CGMT) to non-Gaussian settings, we derive an asymptotic min-max characterization... J(μ, α, κ;β, ν) = β²κ/2 + E[eLy(μ⊤x+αz;κ)] + ρ(μ) − να²/2 − β²/2n tr(Cx(νCx+Hρ)⁻¹)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
any C² regularizer is asymptotically equivalent to a quadratic form determined solely by its Hessian at zero and gradient at μ̂θ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A note on the hanson–wright inequality for random vectors with dependencies
Adamczak, R. A note on the hanson–wright inequality for random vectors with dependencies. Electronic Communications in Probability, 20: 0 72:1--72:13, 2015. doi:10.1214/ECP.v20-3829. Electron.\ Commun.\ Probab.\ 20 (2015), no.\ 72
-
[2]
High-dimensional robust regression under heavy-tailed data: Asymptotics and universality
Adomaityte, U., Defilippis, L., Loureiro, B., and Sicuro, G. High-dimensional robust regression under heavy-tailed data: Asymptotics and universality. Journal of Statistical Mechanics: Theory and Experiment, 2024 0 (11): 0 114002, 2024
work page 2024
-
[3]
Akhtiamov, D., Ghane, R., Varma, N. K., Hassibi, B., and Bosch, D. A novel gaussian min-max theorem and its applications. arXiv preprint arXiv:2402.07356, 2024
-
[4]
Bayati, M. and Montanari, A. The dynamics of message passing on dense graphs, with applications to compressed sensing. IEEE Transactions on Information Theory, 57 0 (2): 0 764--785, 2011. doi:10.1109/TIT.2010.2094817
-
[5]
Bean, D., Bickel, P. J., Karoui, N. E., and Yu, B. Optimal m-estimation in high-dimensional regression. Proceedings of the National Academy of Sciences, 110 0 (36): 0 14563--14568, 2013. doi:10.1073/pnas.1307845110
-
[6]
Bosch, D. and Panahi, A. A novel convex gaussian min max theorem for repeated features. In Li, Y., Mandt, S., Agrawal, S., and Khan, E. (eds.), Proceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258 of Proceedings of Machine Learning Research, pp.\ 3673--3681. PMLR, 03--05 May 2025
work page 2025
-
[7]
A generalization of the Lindeberg principle , volume=
Chatterjee, S. A generalization of the lindeberg principle. Annals of Probability, 34 0 (6): 0 2061--2076, 2006. doi:10.1214/009117906000000575
-
[8]
Couillet, R. and Liao, Z. Random Matrix Methods for Machine Learning. Cambridge University Press, 2022. ISBN 978-1-009-12323-5. doi:10.1017/cbo9781009128490
-
[9]
Classification asymptotics in the random matrix regime
Couillet, R., Liao, Z., and Mai, X. Classification asymptotics in the random matrix regime. In 2018 26th European Signal Processing Conference (EUSIPCO), pp.\ 1760--1764, 2018. doi:10.23919/EUSIPCO.2018.8553034
-
[10]
Universality laws for gaussian mixtures in generalized linear models
Dandi, Y., Stephan, L., Krzakala, F., Loureiro, B., and Zdeborov \'a , L. Universality laws for gaussian mixtures in generalized linear models. Advances in Neural Information Processing Systems, 36: 0 54754--54768, 2023
work page 2023
-
[11]
Dobriban, E. and Wager, S. High-dimensional asymptotics of prediction: Ridge regression and classification. The Annals of Statistics, 46 0 (1): 0 247--279, 2018. doi:10.1214/17-AOS1549
-
[12]
Donoho, D. L. and Montanari, A. High dimensional robust m-estimation: Asymptotic variance via approximate message passing. Probability Theory and Related Fields, 166 0 (3-4): 0 935--969, 2016. doi:10.1007/s00440-015-0675-z
-
[13]
Gaussian universality of perceptrons with random labels
Gerace, F., Krzakala, F., Loureiro, B., Stephan, L., and Zdeborov\'a, L. Gaussian universality of perceptrons with random labels. arXiv preprint arXiv:2205.13303, 2022
-
[14]
The gaussian equivalence of generative models for learning with shallow neural networks
Goldt, S., Loureiro, B., Reeves, G., Krzakala, F., Mezard, M., and Zdeborova, L. The gaussian equivalence of generative models for learning with shallow neural networks. In Bruna, J., Hesthaven, J., and Zdeborova, L. (eds.), Proceedings of the 2nd Mathematical and Scientific Machine Learning Conference, volume 145 of Proceedings of Machine Learning Resear...
work page 2022
-
[15]
On milman's inequality and random subspaces which escape through a mesh in R ^n
Gordon, Y. On milman's inequality and random subspaces which escape through a mesh in R ^n . In Geometric Aspects of Functional Analysis, pp.\ 84--106. Springer, 1988
work page 1988
-
[16]
Han, Q. and Shen, Y. Universality of regularized regression estimators in high dimensions. Annals of Statistics, 50 0 (2): 0 1459--1498, 2022. doi:10.1214/21-AOS2153
- [17]
-
[18]
Karoui, N. E. On the impact of predictor geometry on the performance of high-dimensional ridge-regularized generalized robust regression estimators. Probability Theory and Related Fields, 170 0 (1): 0 95--175, 2018. doi:10.1007/s00440-016-0754-9
-
[19]
Karoui, N. E., Bean, D., Bickel, P. J., Lim, C., and Yu, B. On robust regression with high-dimensional predictors. Proceedings of the National Academy of Sciences, 110 0 (36): 0 14557--14562, 2013. doi:10.1073/pnas.1307842110
-
[20]
Korada, S. B. and Montanari, A. Applications of the lindeberg principle in communications and statistical learning. IEEE transactions on information theory, 57 0 (4): 0 2440--2450, 2011
work page 2011
-
[21]
The concentration of measure phenomenon
Ledoux, M. The concentration of measure phenomenon. Number 89. American Mathematical Soc., 2005
work page 2005
-
[22]
Louart, C. Random matrix theory and concentration of the measure theory for the study of high dimension data processing. PhD thesis, Universit \'e Grenoble Alpes, 2023. PhD thesis
work page 2023
-
[23]
Operation with concentration inequalities
Louart, C. Operation with concentration inequalities. arXiv preprint arXiv:2402.08206, 2024
-
[24]
A random matrix approach to neural networks
Louart, C., Liao, Z., and Couillet, R. A random matrix approach to neural networks. Annals of Applied Probability, 28 0 (2): 0 1190--1248, 2018. doi:10.1214/17-AAP1328
-
[25]
Learning curves of generic features maps for realistic datasets with a teacher-student model
Loureiro, B., Gerbelot, C., Cui, H., Goldt, S., Krzakala, F., M \'e zard, M., and Zdeborov \'a , L. Learning curves of generic features maps for realistic datasets with a teacher-student model. In Advances in Neural Information Processing Systems, volume 34. Curran Associates, Inc., 2021 a
work page 2021
-
[26]
Learning gaussian mixtures with generalized linear models: Precise asymptotics in high-dimensions
Loureiro, B., Sicuro, G., Gerbelot, C., Pacco, A., Krzakala, F., and Zdeborov \'a , L. Learning gaussian mixtures with generalized linear models: Precise asymptotics in high-dimensions. In Ranzato, M., Beygelzimer, A., Dauphin, Y. N., Liang, P., and Vaughan, J. W. (eds.), Advances in Neural Information Processing Systems 34: Annual Conference on Neural In...
work page 2021
-
[27]
Mai, X. and Liao, Z. High Dimensional Classification via Regularized and Unregularized Empirical Risk Minimization : Precise Error and Optimal Loss , November 2020
work page 2020
-
[28]
Mai, X. and Liao, Z. The breakdown of gaussian universality in classification of high-dimensional linear factor mixtures. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[29]
Mallory, M. E., Huang, K. H., and Austern, M. Universality of high-dimensional logistic regression and a novel cgmt under block dependence with applications to data augmentation. In Proceedings of the 38th Conference on Learning Theory, volume 291 of Proceedings of Machine Learning Research, pp.\ 1799--1918. PMLR, 2025
work page 1918
-
[30]
Montanari, A. and Saeed, B. N. Universality of empirical risk minimization. In Proceedings of the 35th Conference on Learning Theory, volume 178 of Proceedings of Machine Learning Research, pp.\ 4310--4312. PMLR, 2022
work page 2022
-
[31]
Oymak, S. and Tropp, J. A. Universality laws for randomized dimension reduction, with applications. Information and Inference: A Journal of the IMA, 7 0 (3): 0 337--446, 2018. doi:10.1093/imaiai/iax015
-
[32]
Panahi, A. and Hassibi, B. A universal analysis of large-scale regularized least squares solutions. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[33]
Pesce, L., Krzakala, F., Loureiro, B., and Stephan, L. Are Gaussian data all you need? the extents and limits of universality in high-dimensional generalized linear estimation. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 28138--28175. PMLR, 2023
work page 2023
-
[34]
Generalized approximate message passing for estimation with random linear mixing
Rangan, S. Generalized approximate message passing for estimation with random linear mixing. In 2011 IEEE International Symposium on Information Theory Proceedings (ISIT), pp.\ 2168--2172, St. Petersburg, Russia, 2011. doi:10.1109/ISIT.2011.6033942
-
[35]
Rockafellar, R. T. and Wets, R. J.-B. Variational Analysis, volume 317 of Grundlehren der mathematischen Wissenschaften. Springer, Berlin, Heidelberg, 1998. ISBN 978-3-642-02431-3. doi:10.1007/978-3-642-02431-3
-
[36]
Seddik, M. E. A., Louart, C., Tamaazousti, M., and Couillet, R. Random matrix theory proves that deep learning representations of GAN -data behave as Gaussian mixtures. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp.\ 8573--8582. PMLR, 2020
work page 2020
-
[37]
Silverstein, J. W. and Bai, Z. D. On the empirical distribution of eigenvalues of a class of large dimensional random matrices. Journal of Multivariate Analysis, 54 0 (2): 0 175--192, 1995
work page 1995
-
[38]
A framework to characterize performance of lasso algorithms
Stojnic, M. A framework to characterize performance of lasso algorithms. CoRR, abs/1303.7291, 2013
-
[39]
The Gaussian min--max theorem in the presence of convexity, 2014
Thrampoulidis, C., Oymak, S., and Hassibi, B. The Gaussian min--max theorem in the presence of convexity, 2014. URL https://arxiv.org/abs/1408.4837. arXiv preprint
-
[40]
Regularized linear regression: A precise analysis of the estimation error
Thrampoulidis, C., Oymak, S., and Hassibi, B. Regularized linear regression: A precise analysis of the estimation error. In Conference on Learning Theory (COLT), volume 40 of Proceedings of Machine Learning Research, pp.\ 1683--1709, 2015
work page 2015
-
[41]
Precise error analysis of regularized m -estimators in high dimensions
Thrampoulidis, C., Abbasi, E., and Hassibi, B. Precise error analysis of regularized m -estimators in high dimensions. IEEE Transactions on Information Theory, 64 0 (8): 0 5592--5628, 2018
work page 2018
-
[42]
Introduction to the non-asymptotic analysis of random matrices
Vershynin, R. Introduction to the non-asymptotic analysis of random matrices. In Eldar, Y. C. and Kutyniok, G. (eds.), Compressed Sensing: Theory and Applications, pp.\ 210--268. Cambridge University Press, Cambridge, 2012
work page 2012
-
[43]
arXiv preprint arXiv:2512.03325 , year=
Wen, G. G., Hu, H., Lu, Y. M., Fan, Z., and Misiakiewicz, T. When does gaussian equivalence fail and how to fix it: Non-universal behavior of random features with quadratic scaling. arXiv preprint arXiv:2512.03325, 2025
-
[44]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.