Recognition: 2 theorem links
· Lean TheoremCoME-VL: Scaling Complementary Multi-Encoder Vision-Language Learning
Pith reviewed 2026-05-13 20:24 UTC · model grok-4.3
The pith
Fusing a contrastive vision encoder with a self-supervised DINO encoder via targeted aggregation and cross-attention produces better visual tokens for decoder-only language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
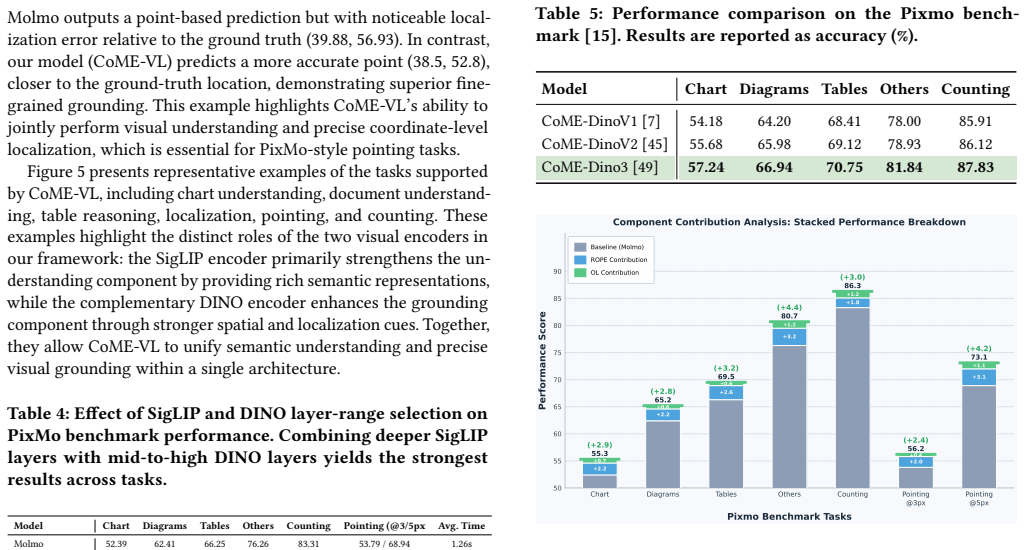
CoME-VL performs representation-level fusion of a contrastively pretrained vision encoder and a self-supervised DINO encoder by applying entropy-guided multi-layer aggregation with orthogonality-constrained projections to reduce redundancy, followed by RoPE-enhanced cross-attention to align heterogeneous token grids and generate compact fused visual tokens that can be injected into a decoder-only LLM.
What carries the argument
The modular fusion framework that integrates contrastive and self-supervised vision encoders through entropy-guided multi-layer aggregation, orthogonality-constrained projections, and RoPE-enhanced cross-attention to produce compact, non-redundant visual tokens.
If this is right
- The fused visual tokens improve visual understanding tasks by an average of 4.9 percent over single-encoder baselines.
- Grounding performance rises by an average of 5.4 percent, with state-of-the-art results on RefCOCO detection.
- The method requires only minimal changes to standard decoder-only VLM pipelines.
- Ablation studies confirm that both the entropy-guided merging and the non-redundant mixing steps contribute to the observed gains.
- Complementary contrastive and self-supervised signals together produce stronger representations than either signal alone.
Where Pith is reading between the lines
- The same fusion recipe could be tested on other pairs of specialized encoders beyond CLIP-style and DINO encoders.
- If the orthogonality constraint proves robust across scales, it may allow stacking more than two encoders without rapid growth in token redundancy.
- The approach suggests that future VLMs could leverage off-the-shelf pretrained encoders rather than training ever-larger single vision backbones from scratch.
Load-bearing premise
That entropy-guided aggregation plus orthogonality constraints and RoPE cross-attention will reliably remove redundancy between the two encoders while keeping their complementary information intact.
What would settle it
Running the same benchmarks with the fused tokens replaced by either encoder alone and observing no consistent gain in accuracy or grounding metrics would falsify the claim that the fusion step is responsible for the reported improvements.
Figures








read the original abstract
Recent vision-language models (VLMs) typically rely on a single vision encoder trained with contrastive image-text objectives, such as CLIP-style pretraining. While contrastive encoders are effective for cross-modal alignment and retrieval, self-supervised visual encoders often capture richer dense semantics and exhibit stronger robustness on recognition and understanding tasks. In this work, we investigate how to scale the fusion of these complementary visual representations for vision-language modeling. We propose CoME-VL: Complementary Multi-Encoder Vision-Language, a modular fusion framework that integrates a contrastively trained vision encoder with a self-supervised DINO encoder. Our approach performs representation-level fusion by (i) entropy-guided multi-layer aggregation with orthogonality-constrained projections to reduce redundancy, and (ii) RoPE-enhanced cross-attention to align heterogeneous token grids and produce compact fused visual tokens. The fused tokens can be injected into a decoder-only LLM with minimal changes to standard VLM pipelines. Extensive experiments across diverse vision-language benchmarks demonstrate that CoME-VL consistently outperforms single-encoder baselines. In particular, we observe an average improvement of 4.9% on visual understanding tasks and 5.4% on grounding tasks. Our method achieves state-of-the-art performance on RefCOCO for detection while improving over the baseline by a large margin. Finally, we conduct ablation studies on layer merging, non-redundant feature mixing, and fusion capacity to evaluate how complementary contrastive and self-supervised signals affect VLM performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoME-VL, a modular fusion framework that integrates a contrastively trained vision encoder with a self-supervised DINO encoder for vision-language models. It performs representation-level fusion via entropy-guided multi-layer aggregation with orthogonality-constrained projections to reduce redundancy, followed by RoPE-enhanced cross-attention to align heterogeneous token grids. The central claim is that this yields consistent outperformance over single-encoder baselines, with average gains of 4.9% on visual understanding tasks and 5.4% on grounding tasks, plus SOTA results on RefCOCO detection.
Significance. If the gains can be isolated to the entropy-guided aggregation and RoPE fusion rather than dual-encoder capacity, the work would provide a practical, modular route to exploit complementary contrastive and self-supervised visual signals in decoder-only VLMs, with potential benefits for robustness on dense understanding and grounding benchmarks.
major comments (2)
- [Ablation studies] Ablation studies section: The reported ablations on layer merging, non-redundant feature mixing, and fusion capacity do not include a control that simply concatenates or averages the two encoder outputs (under identical LLM backbone, training regime, and token budget). Without this baseline, the 4.9% / 5.4% margins cannot be attributed to the entropy-guided aggregation or RoPE cross-attention rather than the mere addition of a second visual encoder.
- [Method] Method section on orthogonality-constrained projections: The paper does not provide the explicit loss term or projection matrix formulation used to enforce orthogonality (e.g., no equation analogous to a Frobenius-norm penalty on off-diagonal elements). This detail is load-bearing for the claim that redundancy is reduced while preserving complementary information.
minor comments (2)
- [Abstract] Abstract: The phrase 'state-of-the-art performance on RefCOCO for detection' should specify the exact metric (e.g., Acc@0.5) and the prior SOTA reference for direct comparison.
- [Figures] Figure captions: Several figures comparing token visualizations lack quantitative metrics (e.g., cosine similarity or entropy values) that would allow readers to verify the claimed reduction in redundancy.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the feedback on the ablation studies and the method description. We will revise the manuscript to address these points by adding the requested baseline and providing the explicit formulation for the orthogonality constraint.
read point-by-point responses
-
Referee: Ablation studies section: The reported ablations on layer merging, non-redundant feature mixing, and fusion capacity do not include a control that simply concatenates or averages the two encoder outputs (under identical LLM backbone, training regime, and token budget). Without this baseline, the 4.9% / 5.4% margins cannot be attributed to the entropy-guided aggregation or RoPE cross-attention rather than the mere addition of a second visual encoder.
Authors: We agree that including a simple concatenation or averaging baseline is crucial to isolate the contributions of our proposed entropy-guided aggregation and RoPE cross-attention. In the revised manuscript, we will add this control experiment, maintaining identical LLM backbone, training regime, and token budget. This will allow us to better attribute the observed performance gains to the specific fusion mechanisms. revision: yes
-
Referee: Method section on orthogonality-constrained projections: The paper does not provide the explicit loss term or projection matrix formulation used to enforce orthogonality (e.g., no equation analogous to a Frobenius-norm penalty on off-diagonal elements). This detail is load-bearing for the claim that redundancy is reduced while preserving complementary information.
Authors: We thank the referee for pointing this out. The orthogonality constraint is implemented using a Frobenius norm penalty on the off-diagonal elements of the projection matrix product, specifically L_ortho = ||W^T W - I||_F^2, where W is the projection matrix. We will include this explicit loss term and the full formulation in the revised Method section to clarify how redundancy is reduced. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an empirical modular fusion framework for integrating contrastive and self-supervised vision encoders into VLMs, using components such as entropy-guided multi-layer aggregation, orthogonality-constrained projections, and RoPE-enhanced cross-attention. All central claims rest on experimental results and ablations measured against external benchmarks (e.g., 4.9% average gain on visual understanding tasks, RefCOCO SOTA), with no mathematical derivation, first-principles prediction, or fitted parameter that reduces to its own inputs by construction. The architecture is presented as a practical design choice validated externally rather than a self-referential theorem or renamed empirical pattern.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entropy-guided multi-layer aggregation with orthogonality-constrained projections and RoPE-enhanced cross-attention
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive experiments across diverse vision-language benchmarks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Pravesh Agrawal, Szymon Antoniak, Emma Bou Hanna, Baptiste Bout, Devendra Chaplot, Jessica Chudnovsky, Diogo Costa, Baudouin De Monicault, Saurabh Garg, Theophile Gervet, et al. 2024. Pixtral 12B.arXiv preprint arXiv:2410.07073 (2024)
work page internal anchor Pith review arXiv 2024
-
[3]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al
-
[4]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems35 (2022), 23716–23736
work page 2022
-
[5]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, K. Marathe, Yonatan Bitton, S. Gadre, and Shiori Sagawa. 2023. Open- Flamingo: An Open-Source Framework for Training Large Autoregressive Vision- Language Models.arXiv.org(2023). doi:10.48550/arXiv.2308.01390
work page internal anchor Pith review doi:10.48550/arxiv.2308.01390 2023
-
[6]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Frontier Large Vision- Language Model with Versatile Abilities.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschan- nen, Emanuele Bugliarello, et al. 2024. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision. 9650–9660
work page 2021
-
[9]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas J. Guibas, and Fei Xia. 2024. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities.Computer Vision and Pattern Recognition(2024). doi:10.1109/CVPR52733.2024.01370
-
[10]
Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, and Benyou Wang. 2024. ALLaVA: Harnessing GPT4V-Synthesized Data for Lite Vision-Language Models. (2024)
work page 2024
-
[11]
Jiuhai Chen, Jianwei Yang, Haiping Wu, Dianqi Li, Jianfeng Gao, Tianyi Zhou, and Bin Xiao. 2025. Florence-vl: Enhancing vision-language models with generative vision encoder and depth-breadth fusion. InProceedings of the Computer Vision and Pattern Recognition Conference. 24928–24938
work page 2025
-
[12]
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao
-
[13]
Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic.arXiv preprint arXiv:2306.15195(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
WL Chiang, Z Li, Z Lin, Y Sheng, Z Wu, H Zhang, L Zheng, S Zhuang, Y Zhuang, JE Gonzalez, et al. [n. d.]. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, Mar. 2023
work page 2023
-
[15]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Wenliang Dai, Junnan Li, Dongxu Li, A. Tiong, Junqi Zhao, Weisheng Wang, Boyang Albert Li, Pascale Fung, and Steven C. H. Hoi. 2023. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. Neural Information Processing Systems(2023). doi:10.48550/arXiv.2305.06500
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.06500 2023
-
[16]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.arXiv preprint arXiv:2305.06500(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al
-
[18]
InProceedings of the Computer Vision and Pattern Recognition Conference
Molmo and pixmo: Open weights and open data for state-of-the-art vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference. 91–104
-
[19]
Ankan Deria, Komal Kumar, Snehashis Chakraborty, Dwarikanath Mahapatra, and Sudipta Roy. 2024. Inverge: Intelligent visual encoder for bridging modalities in report generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2028–2038
work page 2024
- [20]
-
[21]
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdh- ery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. 2023. PaLM-E: An embodied multimodal language model.arXiv preprint arXiv:2303.03378(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Mengfei Du, Binhao Wu, Jiwen Zhang, Zhihao Fan, Zejun Li, Ruipu Luo, Xuan- Jing Huang, and Zhongyu Wei. 2024. Delan: Dual-level alignment for vision- and-language navigation by cross-modal contrastive learning. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 4605–4616
work page 2024
- [23]
-
[24]
Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, and Xiaopeng Zhang. 2025. Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision.Information Fusion(2025). doi:10.1016/j.inffus.2025.103652
-
[25]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. 2025. GLM-4.1 V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning. arXiv preprint arXiv:2507.01006(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Fiaz, Al- ham Fikri Aji, and Hisham Cholakkal
Mohamed Fazli Mohamed Imam, Rufael Marew, Jameel Hassan, M. Fiaz, Al- ham Fikri Aji, and Hisham Cholakkal. 2024. CLIP meets DINO for Tun- ing Zero-Shot Classifier using Unlabeled Image Collections.arXiv.org(2024). doi:10.48550/arXiv.2411.19346
- [27]
-
[28]
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. 2024. Prismatic vlms: Investigating the design space of visually-conditioned language models. InForty-first International Conference on Machine Learning
work page 2024
-
[29]
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. 2014. Referitgame: Referring to objects in photographs of natural scenes. 787–798
work page 2014
-
[30]
Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. 2023. Grounding Language Models to Images for Multimodal Inputs and Outputs. (2023)
work page 2023
-
[31]
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip HS Torr, Fa- had Shahbaz Khan, and Salman Khan. 2025. Llm post-training: A deep dive into reasoning large language models.arXiv preprint arXiv:2502.21321(2025)
-
[32]
Hugo Laurençon, Léo Tronchon, Matthieu Cord, and Victor Sanh. 2024. What matters when building vision-language models?Neural Information Processing Systems(2024). doi:10.48550/arXiv.2405.02246
-
[33]
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. 2023. Otter: A multi-modal model with in-context instruction tuning.arXiv preprint arXiv:2305.03726(2023)
work page internal anchor Pith review arXiv 2023
- [34]
-
[35]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.arXiv preprint arXiv:2301.12597(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. (2022), 12888–12900
work page 2022
-
[37]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen
-
[38]
Evaluating Object Hallucination in Large Vision-Language Models.arXiv preprint arXiv:2305.10355(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [39]
- [40]
-
[41]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.arXiv preprint arXiv:2304.08485(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Jingyu Liu, Liang Wang, and Ming-Hsuan Yang. 2017. Referring expression gen- eration and comprehension via attributes. InProceedings of the IEEE International Conference on Computer Vision. 4856–4864
work page 2017
-
[43]
Yiming Liu, Yuhui Zhang, D. Ghosh, Ludwig Schmidt, and S. Yeung-Levy. 2025. Data or Language Supervision: What Makes CLIP Better than DINO?Conference on Empirical Methods in Natural Language Processing(2025). doi:10.18653/v1/20 25.findings-emnlp.98
- [44]
- [45]
-
[46]
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. 2016. Generation and comprehension of unambiguous object descriptions. 11–20
work page 2016
-
[47]
2023.ChatGPT: A Language Model for Conversational AI
OpenAI. 2023.ChatGPT: A Language Model for Conversational AI. Technical Report. OpenAI
work page 2023
-
[48]
OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. 2023. Kosmos-2: Grounding Multimodal Large Language Models to the World.arXiv:2306.14824(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[52]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763
- [53]
-
[54]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Rama- monjisoa, et al. 2025. Dinov3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Woj- ciech Galuba, Marcus Rohrbach, and Douwe Kiela. 2022. Flava: A foundational language and vision alignment model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15638–15650
work page 2022
-
[57]
Quan Sun, Yuxin Fang, Ledell Yu Wu, Xinlong Wang, and Yue Cao. 2023. EVA- CLIP: Improved Training Techniques for CLIP at Scale.arXiv.org(2023). doi:10.4 8550/arXiv.2303.15389
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. 2024. EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters. arXiv.org(2024). doi:10.48550/arXiv.2402.04252
-
[59]
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023. Stanford alpaca: An instruction-following llama model
work page 2023
-
[60]
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Veda- giri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. 2024. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems37 (2024), 87310–87356
work page 2024
-
[61]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al . 2023. Llama: Open and efficient foundation language models. arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony H...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [64]
-
[65]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. Self-instruct: Aligning language model with self generated instructions.arXiv preprint arXiv:2212.10560(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[67]
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[68]
Monika Wysocza’nska, Oriane Siméoni, Michael Ramamonjisoa, Andrei Bursuc, Tomasz Trzci’nski, and Patrick P’erez. 2023. CLIP-DINOiser: Teaching CLIP a few DINO tricks.European Conference on Computer Vision(2023). doi:10.48550/a rXiv.2312.12359
work page doi:10.48550/a 2023
- [69]
-
[70]
Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiaohua Xie. 2024. MMA: Multi-Modal Adapter for Vision-Language Models.Computer Vision and Pattern Recognition(2024). doi:10.1109/CVPR52733.2024.02249
-
[71]
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. 2023. mplug-owl: Modular- ization empowers large language models with multimodality.arXiv:2304.14178 (2023)
work page Pith review arXiv 2023
- [72]
-
[73]
Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. From recognition to cognition: Visual commonsense reasoning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6720–6731
work page 2019
-
[74]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision. 11975–11986
work page 2023
- [75]
-
[76]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-llama: An instruction- tuned audio-visual language model for video understanding.arXiv preprint arXiv:2306.02858(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [77]
-
[78]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large lan- guage models.arXiv:2304.10592(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models.International Conference on Learning Representations(2023). doi:10.48550/arXiv.2304.10592 10 A Methods Details Given an image 𝐼 and a referring text query 𝑇 , our goal is to pre- dict the boundin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.10592 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.