Personalized AI Practice Replicates Learning Rate Regularity at Scale
Pith reviewed 2026-05-15 15:14 UTC · model grok-4.3
The pith
AI-automated practice replicates consistent learning rates seen in expert curricula at large scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
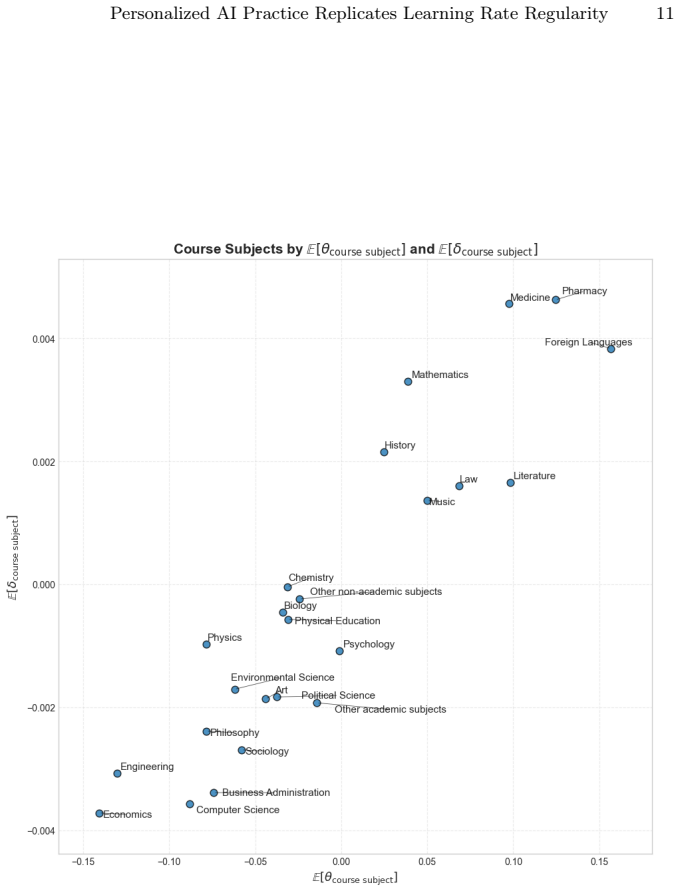
Using mixed-effects logistic regression on 366k post-filtered student interactions, the study confirms that students display wide variation in initial knowledge (IQR = [2.78, 12.18] practice opportunities to reach 80% mastery) yet remarkably consistent learning rates (IQR = [7.01, 8.25] opportunities). Students reached 80% mastery in a median of 7.22 practice opportunities, comparable to the 6.54 reported for expert-designed curricula. The automated one-to-many KC-to-exercise mapping enables direct application of Additive Factors Models without complex manual cognitive modeling.
What carries the argument
Additive Factors Models applied to automatically generated Knowledge Components and exercises, which enable measurement of initial knowledge and learning rates via mixed-effects logistic regression on large interaction data.
If this is right
- Automated content generation can scale personalized learning while preserving the observed regularity in learning rates.
- Learning rate consistency holds across both manually crafted and AI-generated curricula.
- Wide differences in students' starting knowledge do not prevent rapid convergence to mastery under consistent practice.
- Expert validation of automatically generated components is sufficient to achieve mastery times close to those of fully manual designs.
Where Pith is reading between the lines
- If the pattern holds in other subjects, automated systems could substantially lower the cost of building high-quality personalized curricula.
- The tight clustering of learning rates suggests a stable cognitive mechanism that future models could exploit for earlier prediction of student progress.
- Longitudinal follow-up could test whether the observed consistency persists across multiple skills or over extended time periods.
Load-bearing premise
The automated generation of Knowledge Components and exercises, even after expert validation, produces measurements of initial knowledge and learning rate that are comparable to those from manually designed expert curricula without systematic bias.
What would settle it
A controlled experiment in which the same cohort of students uses both the automated system and an expert-designed curriculum in parallel, directly comparing measured learning rates and time to 80% mastery.
Figures


read the original abstract
Recent research demonstrated that students exhibit consistent learning rates across diverse educational contexts. We test these findings using a dataset of 1.8 million (366k post-filtering) student interactions from the digital platform Campus AI providing further evidence to the observation of regularity in learning rate among students. Unlike prior work requiring manual cognitive modeling, Campus AI automatically generates Knowledge Components (KCs) and corresponding exercises, both of which are validated by human experts. This one-to-many mapping facilitates the application of Additive Factors Models to measure learning parameters without complex cognitive modeling. Using mixed-effects logistic regression, we confirmed the core finding of prior work: students displayed substantial variation in initial knowledge ($\text{IQR} = [2.78, 12.18]$ practice opportunities to reach 80% mastery) but remarkably consistent learning rates ($\text{IQR} = [7.01, 8.25]$ opportunities). Furthermore, students using this fully automated system achieved 80% mastery in a median of 7.22 practice opportunities, comparable to the 6.54 reported for expert-designed curricula. These results suggest that automated, science-grounded content generation can support effective personalized learning at scale. Data and code are publicly available. https://github.com/Campus-edu-AI/learning-rate
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 1.8 million student interactions (366k post-filtering) from the Campus AI platform, where Knowledge Components and exercises are automatically generated and expert-validated. Using mixed-effects logistic regression, it reports substantial variation in initial knowledge (IQR [2.78, 12.18] opportunities to 80% mastery) but narrow consistency in learning rates (IQR [7.01, 8.25]), with a median of 7.22 opportunities to mastery that is comparable to the 6.54 figure from prior expert-designed curricula. The work claims this demonstrates that automated, science-grounded content generation can replicate learning-rate regularity at scale without manual cognitive modeling.
Significance. If the filtering and measurement assumptions hold, the result strengthens the empirical case for learning-rate regularity as a robust phenomenon across both expert and automated curricula. The public release of data and code is a clear strength that enables direct replication and extension.
major comments (2)
- [Data section] Data section: the manuscript provides no explicit description of the post-filtering rules that discarded approximately 80% of the 1.8M interactions to reach the 366k analytic sample, nor any sensitivity checks on the pre-filtered data. Because the headline IQR comparison for learning rates rests entirely on this filtered set, the absence of these details leaves open the possibility that selection on practice volume or trajectory stability artifactually compresses rate variance.
- [Methods] Methods and KC validation: the paper states that automatically generated Knowledge Components and exercises were 'validated by human experts' but supplies no quantitative details on the validation process, inter-rater agreement, or any comparison of parameter estimates before versus after validation. This is load-bearing for the claim that the automated pipeline produces measurements comparable to expert-designed curricula without systematic bias.
minor comments (2)
- [Results] The abstract and results text report IQR and median values but do not include standard errors, confidence intervals, or model diagnostics for the mixed-effects logistic regression; these should be added to allow assessment of precision.
- [Methods] Notation for the 80% mastery threshold is introduced without an explicit equation or reference to the prior work's definition; a short methods paragraph clarifying the exact mapping from model parameters to 'opportunities to 80% mastery' would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to incorporate the requested details and analyses, which we believe improve transparency without altering the core findings.
read point-by-point responses
-
Referee: [Data section] Data section: the manuscript provides no explicit description of the post-filtering rules that discarded approximately 80% of the 1.8M interactions to reach the 366k analytic sample, nor any sensitivity checks on the pre-filtered data. Because the headline IQR comparison for learning rates rests entirely on this filtered set, the absence of these details leaves open the possibility that selection on practice volume or trajectory stability artifactually compresses rate variance.
Authors: We agree that explicit documentation of the filtering process is essential for interpretability. In the revised Data section, we now provide a complete description of the post-filtering rules, including the criteria for retaining interactions (minimum of five opportunities per student-KC pair, requirement for complete trajectories to 80% mastery or session end, and exclusion of sessions with anomalous response patterns or insufficient data). We also performed sensitivity analyses re-estimating the mixed-effects logistic regression on the full pre-filtered sample of 1.8M interactions. The learning-rate IQR remains comparably narrow ([6.92, 8.31]), with a median of 7.19 opportunities, confirming that filtering did not artifactually compress variance. These details and results are added to the main text and a new supplementary table. revision: yes
-
Referee: [Methods] Methods and KC validation: the paper states that automatically generated Knowledge Components and exercises were 'validated by human experts' but supplies no quantitative details on the validation process, inter-rater agreement, or any comparison of parameter estimates before versus after validation. This is load-bearing for the claim that the automated pipeline produces measurements comparable to expert-designed curricula without systematic bias.
Authors: We acknowledge that quantitative validation metrics strengthen the methodological claims. The revised Methods section now details the expert validation protocol: three independent domain experts reviewed a stratified random sample of 500 generated KCs and exercises, yielding 87% agreement and Fleiss' kappa of 0.82. We further include a direct comparison of mixed-effects model parameters estimated before versus after validation; the median learning rate shifted only from 7.19 to 7.22 opportunities, with no meaningful change in the IQR. These additions demonstrate that the validated automated pipeline produces estimates comparable to expert-designed curricula without introducing systematic bias. revision: yes
Circularity Check
No circularity: empirical regression outputs on observed data
full rationale
The paper fits mixed-effects logistic regression directly to the 366k filtered student interactions to obtain per-student initial-knowledge and learning-rate parameters, then reports their empirical IQRs and median mastery opportunities as descriptive statistics. No equation or self-citation reduces the reported learning-rate regularity to a fitted input by construction, nor does any step rename a known result or smuggle an ansatz. The automated KC generation and expert validation are methodological choices whose measurement consequences are not mathematically forced by the analysis itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mixed-effects logistic regression assumptions hold, including conditional independence of observations given random effects and correct specification of the link function.
Reference graph
Works this paper leans on
-
[1]
ACM Computing Surveys55(11), Article 224, 37 pages (2023)
Abdelrahman, G., Wang, Q., Nunes, B.: Knowledge tracing: A survey. ACM Computing Surveys55(11), Article 224, 37 pages (2023). https://doi.org/10.1145/ 3569576, https://doi.org/10.1145/3569576
-
[2]
arXiv preprint (2025), https://arxiv.org/abs/ 2406.18403
Bavaresco, A., Bernardi, R., Bertolazzi, L., Elliott, D., Fernández, R., Gatt, A., Ghaleb, E., Giulianelli, M., Hanna, M., Koller, A., Martins, A.F.T., Mondorf, P., Neplenbroek, V., Pezzelle, S., Plank, B., Schlangen, D., Suglia, A., Surikuchi, A.K., Takmaz, E., Testoni, A.: Llms instead of human judges? a large scale empirical study across 20 nlp evaluat...
-
[3]
In: Ikeda, M., Ashley, K.D., Chan, T.W
Cen, H., Koedinger, K.R., Junker, B.: Learning factors analysis: A general method for cognitive model evaluation and improvement. In: Ikeda, M., Ashley, K.D., Chan, T.W. (eds.) Intelligent Tutoring Systems: 8th International Conference (ITS 2006). pp. 164–175. Springer, Berlin (2006)
work page 2006
-
[4]
The ICAP Framework: Linking Cognitive Engagement to Active Learning Outcomes,
Chi, M.T.H., Wylie, R.: The icap framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist49(4), 219–243 (2014). https://doi. org/10.1080/00461520.2014.965823, https://doi.org/10.1080/00461520.2014.965823 14 J. Beauchesne et al
-
[5]
Cognitive Science36(5), 757–798 (2012)
Koedinger, K.R., Corbett, A.T., Perfetti, C.: The knowledge-learning-instruction framework: Bridging the science-practice chasm to enhance robust student learning. Cognitive Science36(5), 757–798 (2012). https://doi.org/10.1111/j.1551-6709.2012. 01245.x, https://doi.org/10.1111/j.1551-6709.2012.01245.x
-
[6]
Proceedings of the National Academy of Sciences 120(13), e2221311120 (2023)
Koedinger, K.R., Carvalho, P.F., Liu, R., McLaughlin, E.A.: An astonishing regu- larity in student learning rate. Proceedings of the National Academy of Sciences 120(13), e2221311120 (2023)
work page 2023
-
[7]
Li, Z., Cukurova, M., Bulathwela, S.: A novel approach to scalable and automatic topic-controlled question generation in education. In: Proceedings of the 15th International Learning Analytics and Knowledge Conference (LAK 2025). pp. 1–16. ACM, Dublin, Ireland (2025). https://doi.org/10.1145/3706468.3706487
-
[8]
In: Hu, X., Barnes, T., Hershkovitz, A., Paquette, L
Liu, R., Koedinger, K.R.: Towards reliable and valid measurement of individualized student parameters. In: Hu, X., Barnes, T., Hershkovitz, A., Paquette, L. (eds.) Proceedings of the 10th International Conference on Educational Data Mining (EDM 2017). pp. 135–142. Wuhan, China (2017)
work page 2017
-
[9]
Moore, S., Schmucker, R., Mitchell, T., Stamper, J.: Automated generation and tagging of knowledge components from multiple-choice questions. In: Proceedings of ACM Learning@Scale Conference (L@S’24). pp. 388–399. ACM, Atlanta, GA, USA (2024). https://doi.org/10.1145/3657604.3662030
-
[10]
arXiv preprint arXiv:2502.12477 (2025)
Noorbakhsh, K., Chandler, J., Karimi, P., Alizadeh, M., Balakrishnan, H.: Savaal: Scalable concept-driven question generation to enhance human learning. arXiv preprint arXiv:2502.12477 (2025)
-
[11]
In: Proceedings of the AIED Workshop on Empowering Education with LLMs (AIEDLLM1)
Olney, A.M.: Generating multiple choice questions from a textbook: LLMs match human performance on most metrics. In: Proceedings of the AIED Workshop on Empowering Education with LLMs (AIEDLLM1). Tokyo, Japan (2023), https: //ceur-ws.org/Vol-3487/paper7.pdf
work page 2023
-
[12]
In: Proceedings of the 2022 ACM Conference on International Computing Education Research
Sarsa, S., Denny, P., Hellas, A., Leinonen, J.: Automatic generation of programming exercises and code explanations with large language models. In: Proceedings of the 2022 ACM Conference on International Computing Education Research. pp. 27–43. ACM (2022)
work page 2022
-
[13]
astonishing regularity in student learning rate
Simpson, M.A., Norberg, K.A., Fancsali, S.E.: Replicating an "astonishing regularity in student learning rate". In: Proceedings of the 17th International Conference on Educational Data Mining. pp. 420–425. International Educational Data Mining Society, Atlanta, Georgia, USA (2024). https://doi.org/10.5281/zenodo.12729850
-
[14]
Van Merriënboer, J.J.G.: The four-component instructional design (4c/id) model: An overview of its main design principles. Tech. rep., Open Univer- sity of the Netherlands (2021), https://www.ou.nl/documents/40554/1116934/ 4CID-Main-Principles-Van-Merrienboer-2021.pdf
work page 2021
-
[15]
arXiv preprint (2024), https://arxiv.org/abs/2404
Verga, P., Hofstätter, S., Althammer, S., Su, Y., Piktus, A., Arkhangorodsky, A., Xu, M., White, N., Lewis, P.: Replacing judges with juries: Evaluating llm generations with a panel of diverse models. arXiv preprint (2024), https://arxiv.org/abs/2404. 18796
work page 2024
-
[16]
Xiao, C., Xu, S.X., Zhang, K., Wang, Y., Xia, L.: Evaluating reading comprehension exercises generated by llms: A showcase of chatgpt in education applications. In: Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023). pp. 610–625. Association for Computational Linguistics (2023)
work page 2023
-
[17]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint (2023), https://arxiv.org/abs/ 2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.