Recognition: 2 theorem links
· Lean TheoremComposer Vector: Style-steering Symbolic Music Generation in a Latent Space
Pith reviewed 2026-05-13 18:49 UTC · model grok-4.3
The pith
Composer Vector steers symbolic music generation toward target composer styles by adding a scaled direction vector in the latent space at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Composer Vector is an inference-time steering method that operates directly in the model's latent space to control composer style without retraining. Through experiments on multiple symbolic music generation models, it guides generations toward target composer styles with smooth and interpretable control via a continuous steering coefficient and enables seamless fusion of multiple styles within a unified latent space framework.
What carries the argument
Composer Vector, a direction vector in the latent space computed from differences between composer-conditioned representations, that is added to the model's hidden states scaled by a steering coefficient to shift output style.
If this is right
- Single-composer conditioning and multi-style fusion become possible with the same pre-trained model.
- Style control is continuous and interpretable through adjustment of one scalar coefficient.
- The approach generalizes to multiple existing symbolic music generators without model-specific changes.
- Creative workflows gain flexibility because style can be changed interactively during generation.
Where Pith is reading between the lines
- The same linear steering idea may apply to other musical attributes such as genre or mood if they occupy similar directions in the latent space.
- Real-time composition interfaces could expose the steering coefficient as a live control for blending historical styles.
- If the method succeeds broadly it implies that many high-level musical traits are already disentangled enough in current models to be manipulated with simple vector arithmetic.
Load-bearing premise
Composer style is already linearly encoded in the latent space of pre-trained symbolic music models so that a fixed direction vector steers generations effectively across different models.
What would settle it
If adding the Composer Vector produces no measurable shift in composer style as judged by either a trained style classifier or human listeners comparing steered and baseline generations, the steering method fails.
Figures






read the original abstract
Symbolic music generation has made significant progress, yet achieving fine-grained and flexible control over composer style remains challenging. Existing training-based methods for composer style conditioning depend on large labeled datasets. Besides, these methods typically support only single-composer generation at a time, limiting their applicability to more creative or blended scenarios. In this work, we propose Composer Vector, an inference-time steering method that operates directly in the model's latent space to control composer style without retraining. Through experiments on multiple symbolic music generation models, we show that Composer Vector effectively guides generations toward target composer styles, enabling smooth and interpretable control through a continuous steering coefficient. It also enables seamless fusion of multiple styles within a unified latent space framework. Overall, our work demonstrates that simple latent space steering provides a practical and general mechanism for controllable symbolic music generation, enabling more flexible and interactive creative workflows. Code and Demo are available here: https://github.com/JiangXunyi/Composer-Vector and https://jiangxunyi.github.io/composervector.github.io/
Editorial analysis
A structured set of objections, weighed in public.
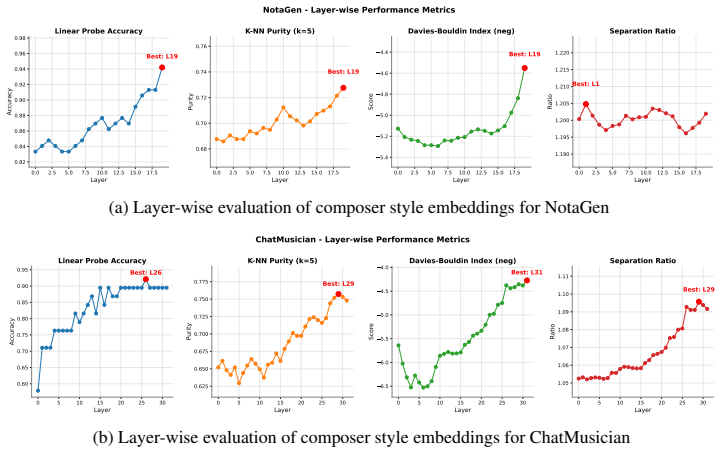
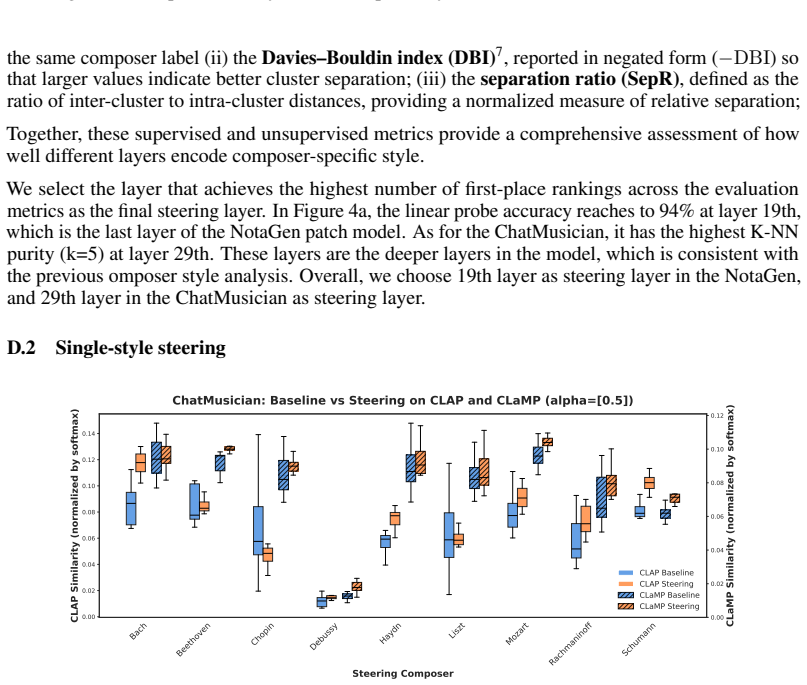
Referee Report
Summary. The paper proposes Composer Vector, an inference-time technique that computes a steering direction in the latent space of pre-trained symbolic music models to control composer style via a scalar coefficient. It claims this enables smooth, interpretable single-style guidance and seamless multi-style fusion without retraining or large labeled datasets, with experiments reported across multiple models.
Significance. If the central claims hold, the work would provide a lightweight, general mechanism for style control that sidesteps the data and compute costs of training-based conditioning, potentially enabling more interactive creative tools for symbolic music generation.
major comments (3)
- [§3] §3 (Method): The precise procedure for obtaining the Composer Vector (e.g., averaging or differencing of latent representations from composer-specific generations) is not specified, nor is any step to enforce orthogonality to content directions; without this, the linear-steerability assumption cannot be evaluated.
- [§4] §4 (Experiments): No quantitative metrics (style classification accuracy, Fréchet distance on style features, or attribute-preservation scores), baselines (fine-tuned conditioning models or random directions), or statistical tests are reported, leaving the effectiveness and smoothness claims supported only by qualitative description.
- [§4.2–4.3] §4.2–4.3: No ablations measure invariance of non-style attributes (note density, interval histograms, phrase length, harmonic consistency) across steering coefficients; this directly undermines the disentanglement premise required for the interpretability and fusion claims.
minor comments (2)
- [Abstract] The abstract and §1 cite the GitHub/demo links but do not list the specific pre-trained models or datasets used in the reported experiments.
- [Figures] Figure captions lack detail on the exact steering coefficients shown and the musical excerpts' provenance.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each of the major comments below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method): The precise procedure for obtaining the Composer Vector (e.g., averaging or differencing of latent representations from composer-specific generations) is not specified, nor is any step to enforce orthogonality to content directions; without this, the linear-steerability assumption cannot be evaluated.
Authors: We agree that the method section would benefit from greater precision. In the revised manuscript, we will expand Section 3 to explicitly describe the computation of the Composer Vector as the difference between the mean latent vectors of generations conditioned on the target composer style and a baseline (e.g., random or neutral prompts). We will also clarify that while no explicit orthogonality enforcement is applied during computation, our qualitative results demonstrate that style steering primarily affects stylistic attributes while preserving content-related features such as structure and harmony. We will add a brief analysis of this in the discussion. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative metrics (style classification accuracy, Fréchet distance on style features, or attribute-preservation scores), baselines (fine-tuned conditioning models or random directions), or statistical tests are reported, leaving the effectiveness and smoothness claims supported only by qualitative description.
Authors: This is a valid point regarding the evaluation. While our focus was on demonstrating the generality of the inference-time approach across models through qualitative examples, we recognize the value of quantitative support. In the revision, we will introduce quantitative metrics including style classification accuracy using a trained classifier on symbolic music, Fréchet distances on extracted style features, and attribute-preservation scores. We will also include baselines such as random steering directions and comparisons to fine-tuned models where applicable, along with statistical tests (e.g., t-tests) on the results to validate the smoothness and effectiveness claims. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3: No ablations measure invariance of non-style attributes (note density, interval histograms, phrase length, harmonic consistency) across steering coefficients; this directly undermines the disentanglement premise required for the interpretability and fusion claims.
Authors: We acknowledge that additional ablations would provide stronger evidence for the disentanglement of style from other musical attributes. In the revised Sections 4.2 and 4.3, we will include ablations that track the invariance of non-style attributes such as note density, interval histograms, phrase length, and harmonic consistency as the steering coefficient varies. These will be presented with quantitative measures to support the claims of interpretability and seamless multi-style fusion. revision: yes
Circularity Check
No significant circularity; method is direct latent manipulation validated experimentally
full rationale
The paper defines Composer Vector as an inference-time operation that computes a direction in the latent space of a pre-trained symbolic music model (via averaging or differencing of latents from composer-specific generations) and then applies a scalar multiple of that direction during generation. No equations reduce the claimed steering effect, smoothness, or multi-style fusion to a fitted parameter defined in terms of the target result itself. The central claims rest on experimental demonstrations across multiple models rather than self-definitional loops, fitted-input predictions, or load-bearing self-citations. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Composer style information is encoded in a steerable linear direction within the latent space of pre-trained symbolic music models.
invented entities (1)
-
Composer Vector
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Composer Vector ... defined as the mean embedding ... sc = 1/Nc Σ h(l*)(xc_i ⊕ pc_i) ... bh = h + α sc ... norm-rescaled
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
linear combination sCk = Σ wci sci ... continuous steering coefficient α
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lukasz Bartoszcze, Sarthak Munshi, Bryan Sukidi, Jennifer Yen, Zejia Yang, David Williams- King, Linh Le, Kosi Asuzu, and Carsten Maple. Representation engineering for large-language models: Survey and research challenges.ArXiv, abs/2502.17601,
-
[2]
semanticscholar.org/CorpusID:276580063
URL https://api. semanticscholar.org/CorpusID:276580063. Keshav Bhandari, Abhinaba Roy, Kyra Wang, Geeta Puri, Simon Colton, and Dorien Herremans. Text2midi: Generating symbolic music from captions. In Toby Walsh, Julie Shah, and Zico Kolter, editors,AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March ...
work page 2025
-
[3]
URLhttps://doi.org/10.1609/aaai.v39i22.34516
doi: 10.1609/AAAI.V39I22.34516. URLhttps://doi.org/10.1609/aaai.v39i22.34516. Runjin Chen, Zhenyu Zhang, Junyuan Hong, Souvik Kundu, and Zhangyang Wang. SEAL: steerable reasoning calibration of large language models for free.CoRR, abs/2504.07986,
-
[5]
ASAP: a dataset of aligned scores and performances for piano transcription
Francesco Foscarin, Andrew McLeod, Philippe Rigaux, Florent Jacquemard, and Masahiko Sakai. ASAP: a dataset of aligned scores and performances for piano transcription. In Julie Cumming, Jin Ha Lee, Brian McFee, Markus Schedl, Johanna Devaney, Cory McKay, Eva Zangerle, and Timothy de Reuse, editors,Proceedings of the 21th International Society for Music In...
work page 2020
-
[6]
Yu-Siang Huang and Yi-Hsuan Yang
URLhttp://archives.ismir.net/ismir2020/paper/000127.pdf. Yu-Siang Huang and Yi-Hsuan Yang. Pop music transformer: Beat-based modeling and generation of expressive pop piano compositions. In Chang Wen Chen, Rita Cucchiara, Xian-Sheng Hua, Guo-Jun Qi, Elisa Ricci, Zhengyou Zhang, and Roger Zimmermann, editors,MM ’20: The 28th ACM International Conference on...
work page 2020
-
[7]
URL https: //doi.org/10.1145/3394171.3413671
doi: 10.1145/3394171.3413671. URL https: //doi.org/10.1145/3394171.3413671. Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. What does BERT learn about the structure of language? In Anna Korhonen, David R. Traum, and Lluís Màrquez, editors,Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 2...
-
[8]
Scaling Laws for Neural Language Models
doi: 10.18653/V1/P19-1356. URLhttps://doi.org/10.18653/v1/p19-1356. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. CoRR, abs/2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p19-1356 2001
-
[9]
Scaling Laws for Neural Language Models
URLhttps://arxiv.org/abs/2001.08361. Dinh-Viet-Toan Le and Yi-Hsuan Yang. METEOR: melody-aware texture-controllable symbolic orchestral music generation.CoRR, abs/2409.11753,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
URL https://doi.org/ 10.24963/ijcai.2025/1125
doi: 10.24963/IJCAI.2025/1125. URL https://doi.org/ 10.24963/ijcai.2025/1125. Dinh-Viet-Toan Le, Louis Bigo, Dorien Herremans, and Mikaela Keller. Natural Language Processing Methods for Symbolic Music Generation and Information Retrieval: A Survey.ACM Computing Surveys, 57(7):1–40, July
-
[12]
ISSN 0360-0300, 1557-7341. doi: 10.1145/3714457. Xun Liang, Hanyu Wang, Yezhaohui Wang, Shichao Song, Jiawei Yang, Simin Niu, Jie Hu, Dan Liu, Shunyu Yao, Feiyu Xiong, and Zhiyu Li. Controllable text generation for large language models: A survey.CoRR, abs/2408.12599,
-
[15]
Zoom in: An introduction to circuits
doi: 10.23915/distill.00024.001. https://distill.pub/2020/circuits/zoom-in. Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mechanistic interpretability for transformer-based language models.CoRR, abs/2407.02646,
-
[18]
Association for Computing Machinery. ISBN 9798400720604. doi: 10.1145/3746278.3759392. URL https://doi.org/10.1145/3746278.3759392. Sida Tian, Can Zhang, Wei Yuan, Wei Tan, and Wenjie Zhu. Xmusic: Towards a generalized and controllable symbolic music generation framework.IEEE Trans. Multim., 27:6857–6871,
-
[19]
URLhttps://doi.org/10.1109/TMM.2025.3590912
doi: 10.1109/TMM.2025.3590912. URLhttps://doi.org/10.1109/TMM.2025.3590912. Dimitri von Rütte, Luca Biggio, Yannic Kilcher, and Thomas Hoffman. FIGARO: generating symbolic music with fine-grained artistic control.CoRR, abs/2201.10936,
-
[20]
URL https: //arxiv.org/abs/2201.10936. Yashan Wang, Shangda Wu, Jianhuai Hu, Xingjian Du, Yueqi Peng, Yongxin Huang, Shuai Fan, Xiaobing Li, Feng Yu, and Maosong Sun. Notagen: Advancing musicality in symbolic music generation with large language model training paradigms. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intel...
-
[21]
URL https: //doi.org/10.24963/ijcai.2025/1134
doi: 10.24963/IJCAI.2025/1134. URL https: //doi.org/10.24963/ijcai.2025/1134. Shangda Wu, Dingyao Yu, Xu Tan, and Maosong Sun. Clamp: Contrastive language-music pre- training for cross-modal symbolic music information retrieval. In Augusto Sarti, Fabio Antonacci, Mark Sandler, Paolo Bestagini, Simon Dixon, Beici Liang, Gaël Richard, and Johan Pauwels, edi...
-
[23]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
doi: 10.48550/ARXIV .2506.17497. URLhttps://doi.org/10.48550/arXiv.2506.17497. Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[24]
URL https://aclanthology. org/2025.acl-long.1126/. Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, Liumeng Xue, Ziyang Ma, Qin Liu, Tianyu Zheng, Yizhi Li, Yinghao Ma, Yiming Liang, Xiaowei Chi, Ruibo Liu, Zili Wang, Chenghua Lin, Qifeng Liu, Tao Jiang, Wenhao Huang, Wenhu Chen, Jie Fu, Em...
work page 2025
-
[25]
doi: 10.18653/V1/2024. FINDINGS-ACL.373. URLhttps://doi.org/10.18653/v1/2024.findings-acl.373. Jincheng Zhang, György Fazekas, and Charalampos Saitis. Composer style-specific symbolic music generation using vector quantized discrete diffusion models. In2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6,
-
[26]
doi: 10.1109/ MLSP58920.2024.10734713. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Troy Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, Zico Kolter, and Dan Hendrycks. Representat...
-
[27]
dog” activating concepts such as “animal
URL https://api.semanticscholar.org/CorpusID: 263605618. 7 A Related work Symbolic music generation.Symbolic music generation has long been an active area of research [Le et al., 2025]. By representing compositions through abstract notations, symbolic music allows researchers and creators to directly manipulate musical elements, and it enables the analysi...
work page 2025
-
[28]
Several key observations emerge: (i) Distinct clusters corresponding to different composers are clearly visible in the latent space, indicating that stylistic cues are represented internally. (ii) The separation is weak in lower layers but becomes progressively sharper in deeper ones, with the final layer exhibiting the most pronounced clustering. This al...
work page 2019
-
[29]
We separate the dataset into 70%, 10%, 20%, training, validation, and testing set. The test accuracy is 89.38% over 11 catagories. Table 2: ASAP dataset summary: 1,067 performances and 236 distinct scores spanning 15 Western classical piano composers. Composer MIDI Perf. Audio Perf. MIDI/XML Scores Bach 169 152 59 Balakirev 10 3 1 Beethoven 271 120 57 Bra...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.