Recognition: no theorem link
BridgeRAG: Training-Free Bridge-Conditioned Retrieval for Multi-Hop Question Answering
Pith reviewed 2026-05-13 18:19 UTC · model grok-4.3
The pith
BridgeRAG scores later-hop passages by their utility given a retrieved bridge passage, lifting training-free multi-hop retrieval accuracy without graphs or training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
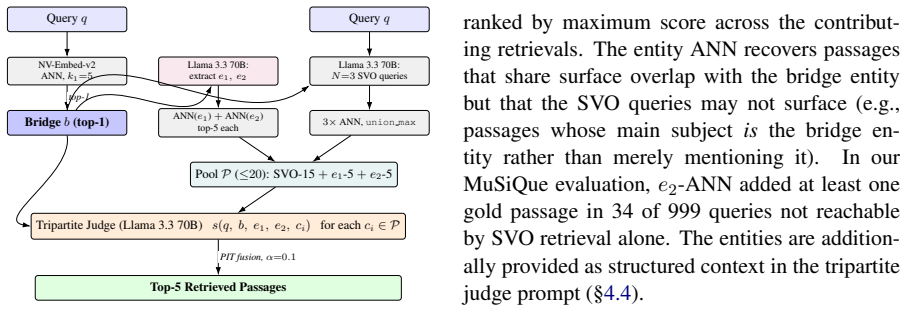
Multi-hop retrieval is not a single-step relevance problem: later-hop evidence should be ranked by its utility conditioned on retrieved bridge evidence, not by similarity to the original query alone. BridgeRAG operationalizes this view with a tripartite scorer s(q,b,c) over (question, bridge, candidate). It separates coverage from scoring via dual-entity ANN expansion for the second-hop pool and a bridge-conditioned LLM judge that identifies the active reasoning chain without any offline graph or proposition index.
What carries the argument
Tripartite scorer s(q,b,c) that ranks a candidate by its utility for the question given the bridge passage, realized as a bridge-conditioned LLM judge.
If this is right
- Selective gains appear only on parallel-chain queries (+2.55pp) while single-chain subtypes show near-zero improvement.
- The conditioning signal cannot be substituted by generated text; doing so drops R@5 below even weak baselines.
- Per-query gains correlate with the cosine similarity between bridge and generated second-hop text.
- Bridge conditioning produces productive re-rankings at 18.7% flip-win rate on parallel chains versus 0.6% on single chains.
Where Pith is reading between the lines
- The same conditioning idea could guide retrieval in other chained-reasoning settings such as multi-step planning or code completion where an intermediate state directs the next action.
- Pairing the LLM judge with a lightweight learned reranker might compound the gains while preserving the training-free property.
- Explicit bridge identification may become a reusable primitive in RAG systems whenever queries require sequential evidence synthesis.
Load-bearing premise
The LLM judge can reliably pick the correct next reasoning step from the bridge passage and question alone without task-specific training or calibration.
What would settle it
An ablation in which the LLM judge is replaced by random selection among the candidate pool and recall drops to the level of the lowest-SVO-similarity baseline on parallel-chain queries.
Figures

read the original abstract
Multi-hop retrieval is not a single-step relevance problem: later-hop evidence should be ranked by its utility conditioned on retrieved bridge evidence, not by similarity to the original query alone. We present BridgeRAG, a training-free, graph-free retrieval method for retrieval-augmented generation (RAG) over multi-hop questions that operationalizes this view with a tripartite scorer s(q,b,c) over (question, bridge, candidate). BridgeRAG separates coverage from scoring: dual-entity ANN expansion broadens the second-hop candidate pool, while a bridge-conditioned LLM judge identifies the active reasoning chain among competing candidates without any offline graph or proposition index. Across four controlled experiments we show that this conditioning signal is (i) selective: +2.55pp on parallel-chain queries (p<0.001) vs. ~0 on single-chain subtypes; (ii) irreplaceable: substituting the retrieved passage with generated SVO query text reduces R@5 by 2.1pp, performing worse than even the lowest-SVO-similarity pool passage; (iii) predictable: cos(b,g2) correlates with per-query gain (Spearman rho=0.104, p<0.001); and (iv) mechanistically precise: bridge conditioning causes productive re-rankings (18.7% flip-win rate on parallel-chain vs. 0.6% on single-chain), not merely more churn. Combined with lightweight coverage expansion and percentile-rank score fusion, BridgeRAG achieves the best published training-free R@5 under matched benchmark evaluation on all three standard MHQA benchmarks without a graph database or any training: 0.8146 on MuSiQue (+3.1pp vs. PropRAG, +6.8pp vs. HippoRAG2), 0.9527 on 2WikiMultiHopQA (+1.2pp vs. PropRAG), and 0.9875 on HotpotQA (+1.35pp vs. PropRAG).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BridgeRAG, a training-free retrieval method for multi-hop question answering that separates coverage (via dual-entity ANN expansion) from scoring via a tripartite bridge-conditioned LLM judge s(q,b,c). It claims this produces selective and productive re-rankings, yielding the best published training-free R@5 on MuSiQue (0.8146), 2WikiMultiHopQA (0.9527), and HotpotQA (0.9875) across four controlled experiments with statistical support.
Significance. If the bridge-conditioned judge reliably extracts reasoning utility, the approach offers a lightweight, graph-free, and training-free improvement to multi-hop retrieval that could be adopted in RAG pipelines. The mechanistic checks (selectivity on parallel-chain queries, SVO substitution drop, Spearman correlation with cos(b,g2), and flip-win differential) provide internal evidence beyond raw benchmark scores.
major comments (2)
- [Abstract and §4 (Experiments)] The central performance claims (e.g., +3.1pp R@5 on MuSiQue and +2.55pp selectivity on parallel-chain queries) rest on the LLM judge's decisions in s(q,b,c). The manuscript supplies no prompt text, no human validation of judge outputs, and no cross-model ablation, so it remains possible that the reported effects reflect model-specific surface cues rather than genuine bridge-conditioned reasoning utility.
- [§4 (Mechanistic Analysis)] All four mechanistic checks (parallel-chain selectivity, SVO substitution, cos(b,g2) correlation, and 18.7% flip-win rate) are generated by the same LLM judge on the same data distribution. This leaves open whether the observed conditioning effect is robust or could be an artifact of the judge itself, even though the method avoids fitted parameters from the target data.
minor comments (2)
- [Abstract] The abstract states 'best published training-free R@5 under matched benchmark evaluation' but does not list the exact prior scores or evaluation scripts used for PropRAG and HippoRAG2; adding a short comparison table would improve clarity.
- Reproducibility would be aided by releasing the exact prompt template and model identifier used for the bridge-conditioned judge.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and helpful comments on reproducibility and robustness. We address each major point below. The revised manuscript will include the exact prompt template and expanded discussion of the mechanistic checks.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The central performance claims (e.g., +3.1pp R@5 on MuSiQue and +2.55pp selectivity on parallel-chain queries) rest on the LLM judge's decisions in s(q,b,c). The manuscript supplies no prompt text, no human validation of judge outputs, and no cross-model ablation, so it remains possible that the reported effects reflect model-specific surface cues rather than genuine bridge-conditioned reasoning utility.
Authors: We agree that the prompt text should have been included for full reproducibility. The revised version will add the complete tripartite prompt template for s(q,b,c) as Appendix A. We did not perform a dedicated human validation study of judge outputs in this work, as the primary contribution is the training-free method and its benchmark gains; however, the four mechanistic analyses (differential selectivity on parallel vs. single-chain queries, SVO substitution drop, Spearman correlation with an independent cosine measure, and flip-win differential) serve as internal consistency checks that the judge decisions track reasoning utility rather than surface artifacts. A cross-model ablation was outside the scope of the current controlled experiments, which isolate the effect of bridge conditioning using a fixed strong judge; we note this limitation explicitly in the revision. revision: partial
-
Referee: [§4 (Mechanistic Analysis)] All four mechanistic checks (parallel-chain selectivity, SVO substitution, cos(b,g2) correlation, and 18.7% flip-win rate) are generated by the same LLM judge on the same data distribution. This leaves open whether the observed conditioning effect is robust or could be an artifact of the judge itself, even though the method avoids fitted parameters from the target data.
Authors: We acknowledge the shared-judge concern. The checks are deliberately designed to be differential and cross-validated against independent signals: selectivity appears only on parallel-chain queries (where conditioning is expected to matter) and is near-zero on single-chain subtypes; SVO substitution uses generated text independent of the judge to show content dependence; the cos(b,g2) correlation links judge-driven gains to a non-LLM similarity metric; and the flip-win rate quantifies productive (not random) re-rankings. These patterns would be improbable under a pure judge artifact. The revision will add a dedicated paragraph discussing this potential limitation and the mitigating design choices. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a training-free retrieval method relying on dual-entity ANN expansion for coverage and an external LLM judge for bridge-conditioned scoring s(q,b,c), followed by percentile-rank fusion. No equations or parameters are fitted to the target benchmark data; reported R@5 gains are empirical outcomes on MuSiQue, 2WikiMultiHopQA, and HotpotQA rather than quantities defined in terms of themselves. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify core components. The internal checks (selectivity, SVO substitution, cosine correlation, flip-win rates) are post-hoc analyses on the same LLM outputs but do not reduce the method's definition or predictions to its inputs by construction. The derivation remains self-contained against external retrieval and LLM components.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM prompted with question and bridge passage can identify which candidate completes the active reasoning chain.
Forward citations
Cited by 1 Pith paper
-
Regime-Conditional Retrieval: Theory and a Transferable Router for Two-Hop QA
Two-hop QA retrieval performance depends on whether the hop-2 entity is in the question or bridge passage, and a simple predicate-based router trained on one dataset transfers to improve R@5 on others.
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Andre Bacellar. 2026. Calibrated fusion for heterogeneous graph-vector retrieval in multi-hop QA . arXiv preprint arXiv:2603.28886
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Gordon V. Cormack, Charles L.A. Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms Condorcet and individual rank learning methods. In Proceedings of SIGIR, pages 758--759
work page 2009
-
[5]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Ghosh, and Meta AI . 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Bernal Jim \'e nez Guti \'e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. HippoRAG : Neurobiologically inspired long-term memory for large language models. In Proceedings of NeurIPS
work page 2024
- [8]
-
[9]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. In Proceedings of COLING, pages 6609--6625
work page 2020
-
[10]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research
work page 2022
-
[11]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. In Proceedings of EMNLP
work page 2023
-
[12]
Vladimir Karpukhin, Barlas O g uz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of EMNLP, pages 6769--6781
work page 2020
-
[13]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. NV-Embed : Improved techniques for training LLMs as generalist embedding models. arXiv preprint arXiv:2405.17428
work page internal anchor Pith review arXiv 2024
-
[14]
Sewon Min, Victor Zhong, Richard Socher, and Caiming Xiong. 2019. Multi-hop reading comprehension through question decomposition and rescoring. In Proceedings of ACL, pages 6097--6109
work page 2019
-
[15]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language models. In Findings of EMNLP
work page 2023
- [16]
-
[17]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR : Recursive abstractive processing for tree-organized retrieval. In Proceedings of ICLR
work page 2024
-
[18]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue : Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539--554
work page 2022
-
[19]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of ACL, pages 10014--10037
work page 2023
-
[20]
Jingjin Wang and Jiawei Han. 2025. PropRAG : Guiding retrieval with beam search over proposition paths. In Proceedings of EMNLP, pages 6212--6227
work page 2025
- [21]
-
[22]
Wenhan Xiong, Xiang Lorraine Li, Srinivasan Iyer, Jingfei Du, Patrick Lewis, William Yang Wang, Yashar Mehdad, Wen-tau Yih, Sebastian Riedel, Douwe Kiela, and Barlas O g uz. 2021. Answering complex open-domain questions with multi-hop dense retrieval. In Proceedings of ICLR
work page 2021
-
[23]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of EMNLP, pages 2369--2380
work page 2018
-
[24]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct : Synergizing reasoning and acting in language models. In Proceedings of ICLR
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.