Recognition: unknown
Regime-Conditional Retrieval: Theory and a Transferable Router for Two-Hop QA
Pith reviewed 2026-05-10 17:11 UTC · model grok-4.3
The pith
Two surface-text predicates split two-hop QA into regimes that a lightweight router can detect to choose the right retrieval path.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Queries in two-hop QA divide into Q-dominant regimes where the hop-2 entity is named in the question and B-dominant regimes where it is only in the bridge passage. Three theorems show that retrieval AUC tracks the cosine separation margin with high R-squared, that two surface predicates determine the regime across encoders and datasets, and that the relation sentence itself—not the entity name—is required for the bridge advantage. RegimeRouter implements a zero-shot transferable router from these predicates and records recall gains on held-out benchmarks.
What carries the argument
RegimeRouter, a binary router that uses five features derived from two surface-text predicates to decide between direct question retrieval and retrieval augmented with the relation-bearing sentence.
If this is right
- Conditioning retrieval on the detected regime improves recall at 5.
- The router trained on one dataset transfers zero-shot to others and yields positive or neutral gains.
- The bridge advantage disappears when the relation-bearing sentence is removed, dropping performance 8.6-14.1 points.
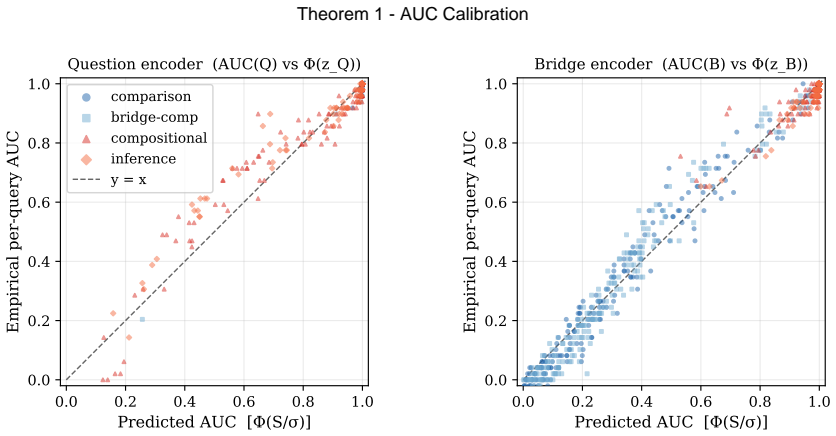
- Per-query AUC is a monotone function of cosine separation margin with R-squared at or above 0.90 in most encoder-type pairs.
Where Pith is reading between the lines
- The same surface predicates could be used to diagnose retrieval failures in longer multi-hop chains.
- Embedding the router inside existing dense retrievers might reduce reliance on full multi-hop architectures.
- The predicates offer a lightweight way to audit whether current retrievers already handle B-dominant cases implicitly.
Load-bearing premise
The two surface-text predicates remain stable and sufficient for routing across encoders, datasets, and future models without needing retraining or extra features.
What would settle it
If the router produces no recall gain or the AUC-cosine correlation falls on a new two-hop QA dataset or encoder, the claim that the predicates are sufficient and transferable would be refuted.
Figures


read the original abstract
Two-hop QA retrieval splits queries into two regimes determined by whether the hop-2 entity is explicitly named in the question (Q-dominant) or only in the bridge passage (B-dominant). We formalize this split with three theorems: (T1) per-query AUC is a monotone function of the cosine separation margin, with R^2 >= 0.90 for six of eight type-encoder pairs; (T2) regime is characterized by two surface-text predicates, with P1 decisive for routing and P2 qualifying the B-dominant case, holding across three encoders and three datasets; and (T3) bridge advantage requires the relation-bearing sentence, not entity name alone, with removal causing an 8.6-14.1 pp performance drop (p < 0.001). Building on this theory, we propose RegimeRouter, a lightweight binary router that selects between question-only and question-plus-relation-sentence retrieval using five text features derived directly from the predicate definitions. Trained on 2WikiMultiHopQA (n = 881, 5-fold cross-fitted) and applied zero-shot to MuSiQue and HotpotQA, RegimeRouter achieves +5.6 pp (p < 0.001), +5.3 pp (p = 0.002), and +1.1 pp (non-significant, no-regret) R@5 improvement, respectively, with artifact-driven.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that two-hop QA retrieval queries fall into two regimes (Q-dominant vs. B-dominant) based on whether the hop-2 entity appears explicitly in the question or only in the bridge passage. It supports this with three theorems—T1 relating per-query AUC to cosine separation margin (R² ≥ 0.90 for six of eight type-encoder pairs), T2 asserting that two surface-text predicates characterize the regimes across encoders and datasets, and T3 showing that bridge advantage requires the full relation-bearing sentence (8.6–14.1 pp drop on removal)—and introduces RegimeRouter, a lightweight binary classifier using five text features derived from those predicates. Trained on 2WikiMultiHopQA (n=881, 5-fold cross-validation) and applied zero-shot, it reports R@5 gains of +5.6 pp (p<0.001), +5.3 pp (p=0.002), and +1.1 pp (non-significant) on 2WikiMultiHopQA, MuSiQue, and HotpotQA respectively.
Significance. If the theorems are robust and the router transfers without retraining, the work supplies a low-overhead, interpretable mechanism for regime-conditional retrieval that improves multi-hop QA without additional model training or heavy inference cost. The cross-dataset zero-shot evaluation and statistical reporting are positive elements that make the contribution testable and potentially extensible to other retrieval-augmented settings.
major comments (3)
- [Abstract / RegimeRouter description] Abstract and RegimeRouter section: the five text features are derived directly from the two surface-text predicates (P1 decisive for routing, P2 qualifying B-dominant) used to define the regimes in T2. This creates a risk that reported gains partly reflect the quality of the regime definition itself rather than independent router performance; without feature-ablation results or tests on paraphrased queries, the contribution of the router versus the predicates cannot be isolated.
- [T2 / Results] T2 and zero-shot transfer results: T2 asserts predicate stability across three encoders and three datasets, yet the router is trained only on 2WikiMultiHopQA (n=881) and evaluated zero-shot on MuSiQue and HotpotQA. No checks are reported that (a) feature importances or decision boundaries remain invariant, (b) routing accuracy on the target datasets matches the predicate-derived labels, or (c) gains disappear under ablation of the predicate-derived features.
- [T1] T1: the claim of R² ≥ 0.90 holds for only six of eight type-encoder pairs. The two failing pairs are not identified, nor is any analysis provided of why the monotone relationship between AUC and cosine margin breaks in those cases; this weakens the generality of the separation-margin theorem that underpins the regime split.
minor comments (2)
- [Abstract] The abstract ends mid-sentence with 'with artifact-driven.'; this appears to be a truncation and should be completed or removed.
- [RegimeRouter] The manuscript should clarify the exact definition of the five text features (e.g., which predicates map to which features) and provide the trained router weights or decision thresholds so that the zero-shot transfer can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments raise valid points about isolating the router's contribution from the underlying predicates, validating the zero-shot transfer more thoroughly, and providing fuller details on T1. We address each major comment point-by-point below, indicating where we will revise the manuscript to improve clarity, transparency, and robustness.
read point-by-point responses
-
Referee: [Abstract / RegimeRouter description] Abstract and RegimeRouter section: the five text features are derived directly from the two surface-text predicates (P1 decisive for routing, P2 qualifying B-dominant) used to define the regimes in T2. This creates a risk that reported gains partly reflect the quality of the regime definition itself rather than independent router performance; without feature-ablation results or tests on paraphrased queries, the contribution of the router versus the predicates cannot be isolated.
Authors: We acknowledge that the five features are derived from the predicates identified in T2. The predicates emerged from a global, post-hoc analysis of the full datasets to characterize the regimes, while the router uses only local, query-level text features to make a prediction at inference time without access to dataset-wide statistics or ground-truth regime labels. This distinction allows the router to serve as a practical, low-cost component. To better isolate its contribution, we will add feature-ablation results (removing one feature at a time) to the revised RegimeRouter section, reporting effects on both routing accuracy and downstream R@5. We agree that experiments on paraphrased queries would provide stronger evidence of independence from exact predicate phrasing; however, this requires generating a new set of paraphrased queries and re-running full retrieval evaluations, which is substantial new work. We will instead add an explicit discussion of this as a limitation and direction for future work. revision: partial
-
Referee: [T2 / Results] T2 and zero-shot transfer results: T2 asserts predicate stability across three encoders and three datasets, yet the router is trained only on 2WikiMultiHopQA (n=881) and evaluated zero-shot on MuSiQue and HotpotQA. No checks are reported that (a) feature importances or decision boundaries remain invariant, (b) routing accuracy on the target datasets matches the predicate-derived labels, or (c) gains disappear under ablation of the predicate-derived features.
Authors: T2 demonstrates that the two predicates reliably characterize the regimes across encoders and datasets, providing the theoretical foundation for selecting the five text features. The router is trained on 2WikiMultiHopQA precisely to learn a generalizable mapping from those features to regime labels, then transferred zero-shot. For (a), we will report the learned feature importances and decision boundary statistics from the 5-fold cross-validation on 2WikiMultiHopQA in the revision. Direct invariance checks on target datasets are not feasible without oracle regime labels, but the statistically significant R@5 gains on MuSiQue (and no-regret result on HotpotQA) provide empirical support for transfer. For (b), computing routing accuracy against predicate-derived labels on targets would require manually applying the predicates to those datasets, which the router is designed to avoid; we will clarify this distinction in the text. For (c), the feature-ablation experiments mentioned above will directly address whether gains depend on the predicate-derived features. revision: yes
-
Referee: [T1] T1: the claim of R² ≥ 0.90 holds for only six of eight type-encoder pairs. The two failing pairs are not identified, nor is any analysis provided of why the monotone relationship between AUC and cosine margin breaks in those cases; this weakens the generality of the separation-margin theorem that underpins the regime split.
Authors: The manuscript already states that R² ≥ 0.90 holds for six of eight type-encoder pairs. We will revise the T1 section to explicitly name the two failing pairs and include a short analysis of possible reasons for the weaker relationship (e.g., lower margin variance or encoder-specific embedding characteristics in those combinations). This addition will increase transparency without changing the core theorem or the regime split it supports. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained with external zero-shot validation
full rationale
The regimes are defined by explicit hop-2 entity presence in the question versus bridge passage, with T1-T3 providing empirical characterizations (monotone AUC-margin relation with reported R^2, surface predicates holding across encoders/datasets, and bridge-sentence ablation results) that are verified on multiple data sources rather than assumed. RegimeRouter is trained on regime labels from 2WikiMultiHopQA using five features derived from those predicates but is evaluated zero-shot on MuSiQue and HotpotQA for an independent retrieval metric (R@5), supplying an external benchmark. No equations reduce by construction to inputs, no fitted parameters are relabeled as predictions, and no self-citation chains or uniqueness theorems are load-bearing; the performance deltas are measured outcomes on held-out data rather than definitional artifacts.
Axiom & Free-Parameter Ledger
free parameters (1)
- router feature weights
axioms (2)
- domain assumption Per-query AUC is a monotone function of cosine separation margin
- domain assumption Surface-text predicates P1 and P2 fully characterize the regime across encoders and datasets
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Andre Bacellar. 2024. BridgeRAG : T raining- F ree B ridge- C onditioned R etrieval for M ulti- H op Q uestion A nswering. arXiv preprint arXiv:2604.03384
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1):37--46
1960
- [5]
-
[6]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A multi-hop QA dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics (COLING)
2020
-
[7]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2024. NV-Embed : I mproved T echniques for training LLM s as G eneralist E mbedding M odels. arXiv preprint arXiv:2405.17428
work page internal anchor Pith review arXiv 2024
-
[8]
Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153--157
1947
-
[9]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. M u S i Q ue: M ultihop Q uestions via S ingle-hop Q uestion C omposition. Transactions of the Association for Computational Linguistics, 10:539--554
2022
-
[10]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. I nterleaving R etrieval with C hain-of- T hought R easoning for K nowledge- I ntensive M ulti- S tep Q uestions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
2023
-
[11]
Jingjin Wang and Jiawei Han. 2025. P rop RAG : G uiding R etrieval with B eam S earch over P roposition P aths. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
2025
- [12]
-
[13]
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-Pack : P ackaged R esources to A dvance G eneral C hinese E mbedding. arXiv preprint arXiv:2309.07597
work page internal anchor Pith review arXiv 2023
-
[14]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. H otpot QA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.