Recognition: 2 theorem links
· Lean TheoremAlign then Train: Efficient Retrieval Adapter Learning
Pith reviewed 2026-05-13 18:11 UTC · model grok-4.3
The pith
ERA aligns large query embedders with lightweight document ones via self-supervised pre-alignment then limited-label adaptation to close both representation and semantic gaps without re-indexing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ERA first aligns the embedding spaces of a large query embedder and a lightweight document embedder through self-supervised training, then uses limited labeled examples to adapt only the query-side representation; this combination closes both the representation mismatch between the two models and the semantic mismatch between complex queries and simple documents, all without re-indexing the corpus.
What carries the argument
Two-stage adapter training: self-supervised alignment of query and document embedding spaces followed by supervised query-side adaptation.
If this is right
- ERA improves retrieval accuracy in low-label regimes across 126 tasks and 6 domains.
- ERA outperforms methods that require substantially more labeled data.
- ERA allows pairing a stronger query embedder with a weaker document embedder without sacrificing performance.
- The document index remains unchanged, avoiding costly re-encoding of the corpus.
Where Pith is reading between the lines
- The same align-then-adapt pattern could be applied to other retrieval settings where query complexity exceeds document complexity, such as multi-turn conversational search.
- Because adaptation is query-only, the method may scale to new domains by collecting only a few hundred query-document pairs rather than full model retraining.
- If alignment quality can be verified with synthetic data, the supervised stage could be reduced further or removed in some domains.
Load-bearing premise
Self-supervised alignment of the query and document embedding spaces is enough to bridge both the model representation gap and the semantic gap between complex queries and simple documents.
What would settle it
On the MAIR benchmark, ERA trained with the same small label budget performs no better than a baseline that fine-tunes only the document embedder or that uses the same labels without the alignment stage.
Figures




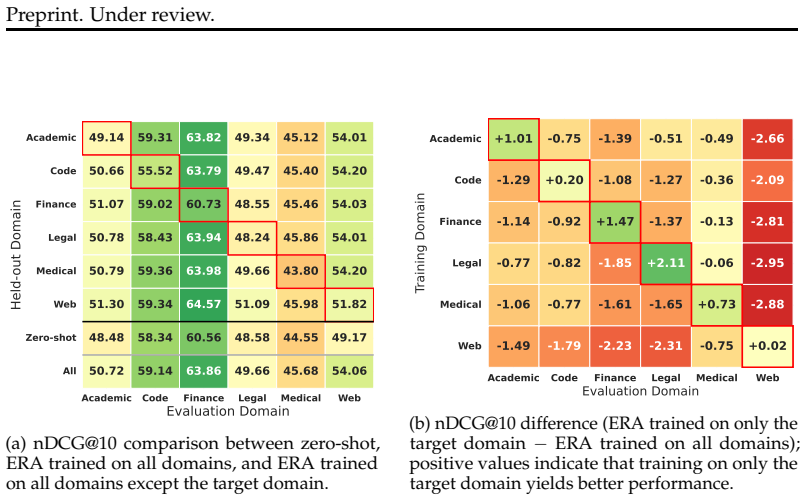


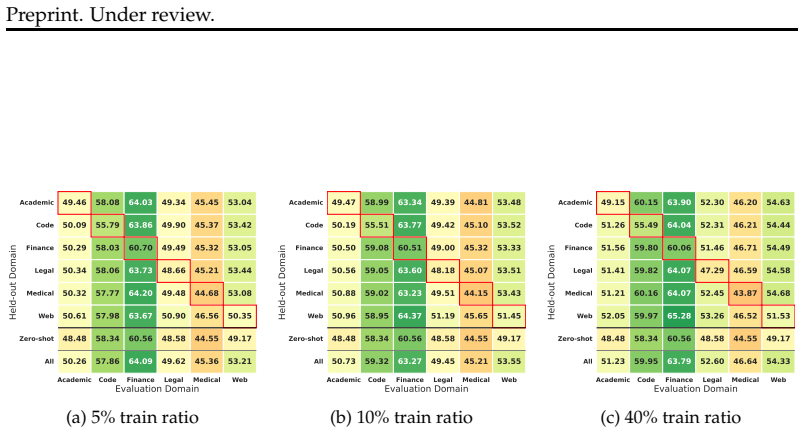
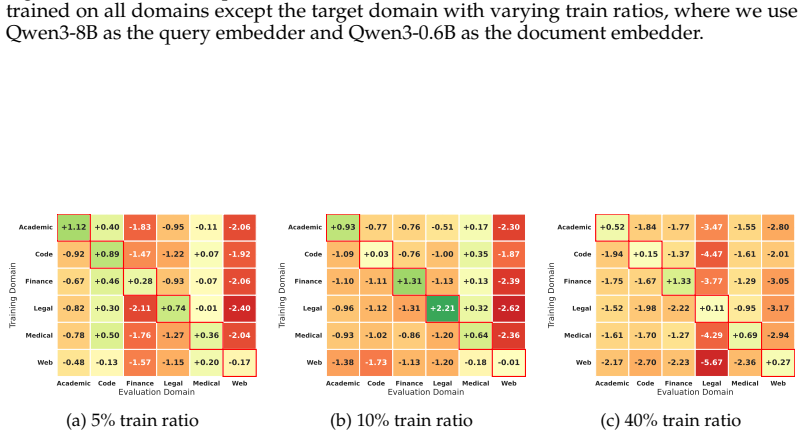
read the original abstract
Dense retrieval systems increasingly need to handle complex queries. In many realistic settings, users express intent through long instructions or task-specific descriptions, while target documents remain relatively simple and static. This asymmetry creates a retrieval mismatch: understanding queries may require strong reasoning and instruction-following, whereas efficient document indexing favors lightweight encoders. Existing retrieval systems often address this mismatch by directly improving the embedding model, but fine-tuning large embedding models to better follow such instructions is computationally expensive, memory-intensive, and operationally burdensome. To address this challenge, we propose Efficient Retrieval Adapter (ERA), a label-efficient framework that trains retrieval adapters in two stages: self-supervised alignment and supervised adaptation. Inspired by the pre-training and supervised fine-tuning stages of LLMs, ERA first aligns the embedding spaces of a large query embedder and a lightweight document embedder, and then uses limited labeled data to adapt the query-side representation, bridging both the representation gap between embedding models and the semantic gap between complex queries and simple documents without re-indexing the corpus. Experiments on the MAIR benchmark, spanning 126 retrieval tasks across 6 domains, show that ERA improves retrieval in low-label settings, outperforms methods that rely on larger amounts of labeled data, and effectively combines stronger query embedders with weaker document embedders across domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Efficient Retrieval Adapter (ERA), a two-stage label-efficient framework for dense retrieval with complex queries and simple documents. Stage 1 performs self-supervised alignment of embedding spaces between a large query embedder and a lightweight document embedder; Stage 2 applies supervised adaptation on limited labeled data to adapt the query-side representation. The approach is claimed to bridge both representation and semantic gaps without corpus re-indexing. Experiments on the MAIR benchmark (126 tasks across 6 domains) report improvements in low-label regimes, outperformance of higher-label baselines, and effective mixing of stronger query embedders with weaker document embedders.
Significance. If the empirical claims hold under rigorous verification, the work offers a practical route to deploy strong instruction-following query encoders with memory-efficient document encoders, lowering both annotation and indexing costs in realistic retrieval settings. The two-stage design, modeled on LLM pre-training/fine-tuning, could generalize to other asymmetric encoder scenarios and reduce reliance on full-model fine-tuning.
major comments (2)
- [Abstract and §4] Abstract and §4: The reported gains on MAIR are presented without any description of baselines, statistical significance tests, error bars, or train/test splits. Because the central claim is that ERA outperforms methods using more labeled data, the absence of these details makes the experimental support unverifiable and load-bearing for the contribution.
- [§3.1] §3.1: The self-supervised alignment is described as operating on embedding spaces to close both representation and semantic gaps, yet the text does not specify whether the alignment loss uses paired query-document examples or only marginal (unpaired) distributions. If the latter, the subsequent low-label adaptation step cannot be guaranteed to map complex instructions onto simple document semantics, directly weakening the claim that limited labels suffice.
minor comments (2)
- [Abstract] Abstract: The acronym ERA is introduced without parenthetical expansion on first use.
- [§4] §4: Tables reporting MAIR results should include the number of labeled examples used by each baseline for direct comparison of label efficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns about experimental verifiability and methodological clarity. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: The reported gains on MAIR are presented without any description of baselines, statistical significance tests, error bars, or train/test splits. Because the central claim is that ERA outperforms methods using more labeled data, the absence of these details makes the experimental support unverifiable and load-bearing for the contribution.
Authors: We agree these details are necessary for rigorous verification. In the revised §4 we now include: full descriptions of all baselines together with their label budgets and training protocols; explicit documentation of the MAIR train/test splits per domain; results averaged over five random seeds with standard-error bars; and paired t-tests (p < 0.05) confirming statistical significance of ERA improvements over higher-label baselines. These additions render the central empirical claims fully verifiable while leaving the reported gains unchanged. revision: yes
-
Referee: [§3.1] §3.1: The self-supervised alignment is described as operating on embedding spaces to close both representation and semantic gaps, yet the text does not specify whether the alignment loss uses paired query-document examples or only marginal (unpaired) distributions. If the latter, the subsequent low-label adaptation step cannot be guaranteed to map complex instructions onto simple document semantics, directly weakening the claim that limited labels suffice.
Authors: We appreciate the request for precision. The alignment stage (§3.1) uses only unpaired marginal distributions: queries and documents are sampled independently and aligned via a contrastive loss (InfoNCE on separate batches) that matches the two embedding spaces without any paired examples. This step closes the representation gap caused by differing model capacities and pre-training objectives. The semantic gap between complex instructions and simple documents is then addressed in the supervised adaptation stage, where the now-aligned spaces allow a lightweight query adapter to map instructions effectively with very few paired labels. We have updated §3.1 with the exact loss formulation, an explicit statement that alignment is unpaired, and a new ablation showing that the two-stage procedure outperforms direct supervised fine-tuning without the alignment step. The MAIR results continue to support the label-efficiency claim under this clarified design. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents ERA as a two-stage process of self-supervised alignment of embedding spaces between a large query embedder and lightweight document embedder, followed by supervised adaptation on limited labels. No equations are shown that reduce any claimed prediction or result to fitted parameters or inputs by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing justifications. The approach draws inspiration from LLM pre-training stages but treats them as high-level motivation rather than a formal derivation that collapses to the inputs. Empirical evaluation on the MAIR benchmark across 126 tasks supplies independent validation, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-supervised alignment can bridge representation gaps between query and document embedders
- domain assumption Limited labeled data is sufficient for query-side adaptation after alignment
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ERA first aligns the embedding spaces of a large query embedder and a lightweight document embedder, and then uses limited labeled data to adapt the query-side representation, bridging both the representation gap between embedding models and the semantic gap between complex queries and simple documents
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
self-supervised alignment stage that bridges the representation gap between different embedding models, and a supervised adaptation stage that captures the semantic nuances between complex queries and simple documents
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Transferring linear features across language models with model stitching
Alan Chen, Jack Merullo, Alessandro Stolfo, and Ellie Pavlick. Transferring linear features across language models with model stitching. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=Qvvy0X63Fv
work page 2025
-
[3]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M 3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 2318--2335, Bangkok, Tha...
-
[4]
Promptagator: Few-shot dense retrieval from 8 examples
Zhuyun Dai, Vincent Y Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith Hall, and Ming-Wei Chang. Promptagator: Few-shot dense retrieval from 8 examples. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=gmL46YMpu2J
work page 2023
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT : Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.), Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol...
-
[6]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=BH8TYy0r6u
work page 2024
-
[7]
Harnessing the universal geometry of embeddings
Rishi Dev Jha, Collin Zhang, Vitaly Shmatikov, and John Xavier Morris. Harnessing the universal geometry of embeddings. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=jiCLUPq5xv
work page 2025
-
[8]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 6769--6781, Online, ...
-
[9]
Syntriever: How to train your retriever with synthetic data from LLM s
Minsang Kim and Seung Jun Baek. Syntriever: How to train your retriever with synthetic data from LLM s. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Findings of the Association for Computational Linguistics: NAACL 2025, pp.\ 2523--2539, Albuquerque, New Mexico, April 2025. Association for Computational Linguistics. ISBN 979-8-89176-195-7. doi:10.186...
-
[10]
NV -embed: Improved techniques for training LLM s as generalist embedding models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. NV -embed: Improved techniques for training LLM s as generalist embedding models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=lgsyLSsDRe
work page 2025
-
[11]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[12]
Seiji Maekawa, Hayate Iso, Sairam Gurajada, and Nikita Bhutani. Retrieval helps or hurts? a deeper dive into the efficacy of retrieval augmentation to language models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech...
-
[13]
Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge
Gabriel de Souza P. Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge. Improving text embedding models with positive-aware hard-negative mining. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM '25, pp.\ 2169–2178, New York, NY, USA, 2025. Association for Computing Ma...
-
[14]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018. URL https://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
New embedding models and api updates
OpenAI. New embedding models and api updates. Technical report, 2024. URL https://openai.com/index/new-embedding-models-and-api-updates/
work page 2024
-
[16]
KILT : a benchmark for knowledge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rockt \"a schel, and Sebastian Riedel. KILT : a benchmark for knowledge intensive language tasks. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz...
-
[17]
In: Inui, K., Jiang, J., Ng, V., Wan, X
Nils Reimers and Iryna Gurevych. Sentence- BERT : Sentence embeddings using S iamese BERT -networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 3982--399...
-
[18]
Suvansh Sanjeev and Anton Troynikov. Embedding adapters. Chroma Technical Report, 2024. URL https://research.trychroma.com/embedding-adapters
work page 2024
-
[19]
Rank-distillm: Closing the effectiveness gap between cross-encoders and llms for passage re-ranking
Ferdinand Schlatt, Maik Fr\" o be, Harrisen Scells, Shengyao Zhuang, Bevan Koopman, Guido Zuccon, Benno Stein, Martin Potthast, and Matthias Hagen. Rank-distillm: Closing the effectiveness gap between cross-encoders and llms for passage re-ranking. In Advances in Information Retrieval: 47th European Conference on Information Retrieval, ECIR 2025, Lucca, I...
-
[20]
MAIR : A massive benchmark for evaluating instructed retrieval
Weiwei Sun, Zhengliang Shi, Wu Jiu Long, Lingyong Yan, Xinyu Ma, Yiding Liu, Min Cao, Dawei Yin, and Zhaochun Ren. MAIR : A massive benchmark for evaluating instructed retrieval. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 14044--14067, Miami, Flo...
-
[21]
Efficient context selection for long-context QA : No tuning, no iteration, just adaptive - k
Chihiro Taguchi, Seiji Maekawa, and Nikita Bhutani. Efficient context selection for long-context QA : No tuning, no iteration, just adaptive - k . In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 20105--20130, Suzhou, China...
-
[22]
BEIR : A heterogeneous benchmark for zero-shot evaluation of information retrieval models
Nandan Thakur, Nils Reimers, Andreas R \"u ckl \'e , Abhishek Srivastava, and Iryna Gurevych. BEIR : A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum?id=wCu6T5xFjeJ
work page 2021
-
[23]
Reproducing nevir: Negation in neural information retrieval
Coen van den Elsen, Francien Barkhof, Thijmen Nijdam, Simon Lupart, and Mohammad Aliannejadi. Reproducing nevir: Negation in neural information retrieval. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '25, pp.\ 3346–3356, New York, NY, USA, 2025. Association for Computing Machiner...
-
[24]
Harshil Vejendla. Drift-adapter: A practical approach to near zero-downtime embedding model upgrades in vector databases. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 15938--15949, Suzhou, China, November 2025. Associat...
-
[25]
F ollow IR : Evaluating and teaching information retrieval models to follow instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, and Luca Soldaini. F ollow IR : Evaluating and teaching information retrieval models to follow instructions. In Luis Chiruzzo, Alan Ritter, and Lu Wang (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for...
-
[26]
Search-adaptor: Embedding customization for information retrieval
Jinsung Yoon, Yanfei Chen, Sercan Arik, and Tomas Pfister. Search-adaptor: Embedding customization for information retrieval. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 12230--12247, Bangkok, Thailand, August 2024. Associatio...
-
[27]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025. URL https://arxiv.org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[29]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[30]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.