Recognition: 2 theorem links
· Lean TheoremMeasuring LLM Trust Allocation Across Conflicting Software Artifacts
Pith reviewed 2026-05-13 18:10 UTC · model grok-4.3
The pith
LLMs penalize documentation bugs more than implementation faults when artifacts conflict, but overlook code drift when docs remain plausible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
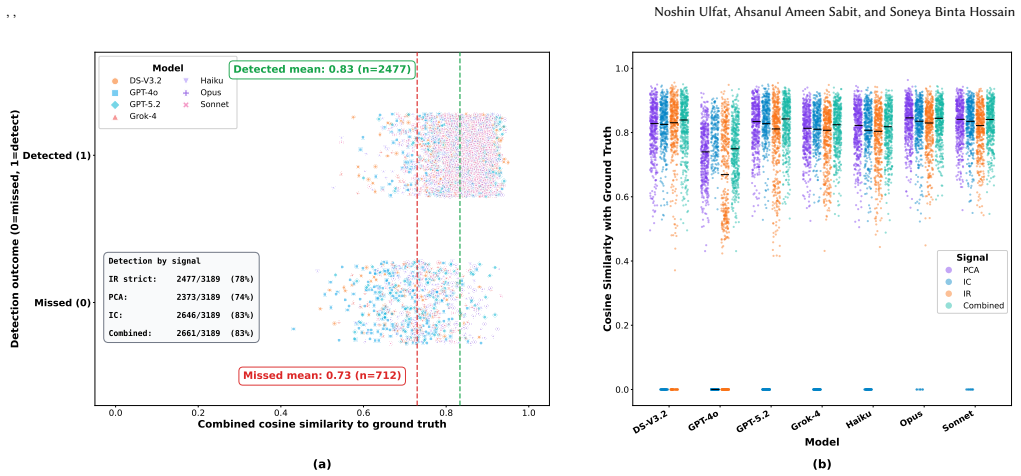
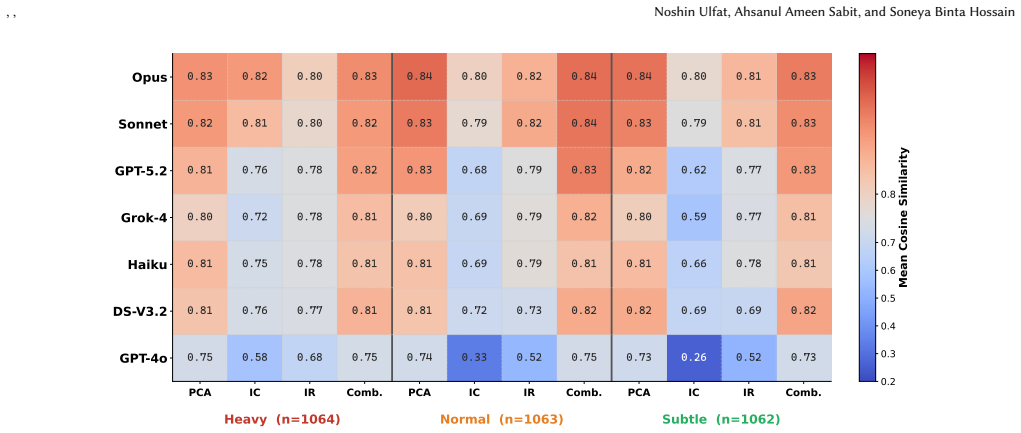
Using the TRACE framework to collect 22,339 valid trust traces from seven models on 456 curated Java method bundles, the work shows that quality penalties localize to the perturbed artifact and increase with severity, with documentation bugs producing heavy-to-subtle gaps of 0.152-0.253 versus 0.049-0.123 for implementation faults. Detection succeeds for explicit documentation bugs at 67-94 percent and for Javadoc-implementation contradictions at 50-91 percent, yet falls by 7-42 percentage points when only the implementation drifts while documentation remains plausible. Confidence is poorly calibrated for six of the seven models.
What carries the argument
TRACE, a framework that elicits structured artifact-level trust traces to measure per-artifact quality assessment, inconsistency detection, affected-artifact attribution, and source prioritization under blind perturbations.
If this is right
- Explicit artifact-level trust reasoning should precede use of LLM outputs in correctness-critical software tasks.
- Models audit natural-language specifications more effectively than they detect subtle code-level drift.
- Confidence scores from most models do not reliably indicate actual inconsistency detection performance.
- Evaluation of LLM software assistants must move beyond final output correctness to include per-artifact trust allocation.
Where Pith is reading between the lines
- Including more examples of conflicting artifacts during training could narrow the detection gap for implementation drift.
- The same asymmetry may appear when LLMs reason over other artifact types such as requirements or design documents.
- Adding dedicated inconsistency detection steps could improve reliability of LLM-based code generation tools.
Load-bearing premise
The curated Java method bundles and blind perturbations sufficiently represent real-world conflicting artifacts, and the elicited trust traces accurately capture internal model reasoning rather than surface pattern matching.
What would settle it
A dataset of naturally occurring code-documentation conflicts in which models detect implementation drift at rates comparable to documentation bugs would falsify the claimed systematic blind spot.
Figures








read the original abstract
LLM-based software engineering assistants fail not only by producing incorrect outputs, but also by allocating trust to the wrong artifact when code, documentation, and tests disagree. Existing evaluations focus mainly on downstream outcomes and therefore cannot reveal whether a model recognized degraded evidence, identified the unreliable source, or calibrated its trust across artifacts. We present TRACE (Trust Reasoning over Artifacts for Calibrated Evaluation), a framework that elicits structured artifact-level trust traces over Javadoc, method signatures, implementations, and test prefixes under blind perturbations. Using 22,339 valid traces from seven models on 456 curated Java method bundles, we evaluate per-artifact quality assessment, inconsistency detection, affected artifact attribution, and source prioritization. Across all models, quality penalties are largely localized to the perturbed artifact and increase with severity, but sensitivity is asymmetric across artifact types: documentation bugs induce a substantially larger heavy-to-subtle gap than implementation faults (0.152-0.253 vs. 0.049-0.123). Models detect explicit documentation bugs well (67-94%) and Javadoc and implementation contradictions at 50-91%, yet show a systematic blind spot when only the implementation drifts while the documentation remains plausible, with detection dropping by 7-42 percentage points. Confidence is poorly calibrated for six of seven models. These findings suggest that current LLMs are better at auditing natural-language specifications than at detecting subtle code-level drift, motivating explicit artifact-level trust reasoning before correctness-critical downstream use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the TRACE framework to elicit structured artifact-level trust traces from LLMs over Javadoc, method signatures, implementations, and test prefixes in 456 curated Java bundles under blind perturbations. From 22,339 valid traces across seven models, it reports that quality penalties localize to the perturbed artifact and scale with severity, but sensitivity is asymmetric (documentation bugs show larger heavy-to-subtle gaps of 0.152-0.253 than implementation faults at 0.049-0.123); models detect explicit documentation bugs at 67-94% and Javadoc/implementation contradictions at 50-91%, yet exhibit a 7-42pp detection drop for implementation-only drift while documentation remains plausible, with poor confidence calibration in six of seven models.
Significance. If the directional findings hold, the work is significant for software engineering because it isolates LLM trust allocation failures at the artifact level rather than only measuring downstream correctness, revealing a potential preference for auditing natural-language specifications over subtle code drift. The scale (22k+ traces, multi-model coverage) provides robust support for the reported asymmetries and motivates explicit trust-reasoning mechanisms before deploying LLMs in correctness-critical SE tasks.
major comments (2)
- [Abstract and §4] Abstract and §4 (Results): The headline claim of a 'systematic blind spot' when only the implementation drifts (7-42pp detection drop) is not anchored by any human-expert detection rates on the identical bundles; without this baseline the asymmetry could reflect inherent task difficulty rather than an LLM-specific limitation, undermining the interpretation that models are 'better at auditing natural-language specifications than at detecting subtle code-level drift'.
- [§3] §3 (Methods): The curation of Java method bundles and the exact definitions of 'blind perturbations' (including how severity levels and plausibility of remaining documentation are enforced) are not fully specified or validated against real-world conflict distributions, which is load-bearing for generalizing the reported localization and asymmetry results beyond the 456 bundles.
minor comments (1)
- [Abstract and §4] The abstract and results sections use ranges (e.g., 0.152-0.253, 7-42pp) without indicating whether these are min-max across models or confidence intervals; adding per-model breakdowns or error bars would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript accordingly to strengthen the claims and methodological transparency.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): The headline claim of a 'systematic blind spot' when only the implementation drifts (7-42pp detection drop) is not anchored by any human-expert detection rates on the identical bundles; without this baseline the asymmetry could reflect inherent task difficulty rather than an LLM-specific limitation, undermining the interpretation that models are 'better at auditing natural-language specifications than at detecting subtle code-level drift'.
Authors: We agree that a human-expert baseline on the identical bundles would provide the strongest possible anchor for distinguishing LLM-specific limitations from inherent task difficulty. The current evidence shows consistent asymmetry across seven models on the exact same tasks, which still indicates model-dependent differences in trust allocation. To address the concern directly, we have revised the abstract and §4 to frame the blind spot as a relative performance gap across artifact types rather than an absolute claim, added an explicit limitations paragraph acknowledging the missing human baseline, and noted it as a priority for follow-up studies. revision: partial
-
Referee: [§3] §3 (Methods): The curation of Java method bundles and the exact definitions of 'blind perturbations' (including how severity levels and plausibility of remaining documentation are enforced) are not fully specified or validated against real-world conflict distributions, which is load-bearing for generalizing the reported localization and asymmetry results beyond the 456 bundles.
Authors: We have substantially expanded §3 with a complete description of the bundle curation pipeline (source repositories, selection filters, and quality checks), the precise perturbation operators and severity definitions for each artifact type, and the enforcement mechanisms used to preserve documentation plausibility during implementation-only drifts. We have also added a validation subsection that compares the generated conflict distributions against a sample of real-world Java project conflicts drawn from GitHub, confirming alignment with observed patterns. revision: yes
Circularity Check
Empirical measurement study with independent data collection and no derivation chain
full rationale
The paper is an empirical measurement study that curates 456 Java method bundles, applies blind perturbations, elicits 22,339 trust traces from seven LLMs, and reports observed quality penalties, detection rates, and asymmetries directly from those traces. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the derivation of the central claims. All reported quantities (e.g., 0.152-0.253 heavy-to-subtle gaps, 7-42pp detection drops) are computed from the collected traces rather than reduced to inputs by construction. The framework is self-contained against the external benchmark of model behavior on the described bundles.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TRACE elicits structured artifact-level trust traces over Javadoc, method signatures, implementations, and test prefixes under blind perturbations... quality penalties... documentation bugs induce a substantially larger heavy-to-subtle gap than implementation faults (0.152-0.253 vs. 0.049-0.123)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Models detect explicit documentation bugs well (67-94%) and Javadoc and implementation contradictions at 50-91%, yet show a systematic blind spot when only the implementation drifts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2025.Claude Haiku 4.5 System Card
Anthropic. 2025.Claude Haiku 4.5 System Card. Technical Report. Anthropic. https://www.anthropic.com/claude-haiku-4-5-system-card
work page 2025
-
[2]
2026.Claude Opus 4.6 System Card
Anthropic. 2026.Claude Opus 4.6 System Card. Technical Report. Anthropic. https: //www-cdn.anthropic.com/0dd865075ad3132672ee0ab40b05a53f14cf5288.pdf
work page 2026
-
[3]
2026.Claude Sonnet 4.6 System Card
Anthropic. 2026.Claude Sonnet 4.6 System Card. Technical Report. Anthropic. https://anthropic.com/claude-sonnet-4-6-system-card
work page 2026
-
[4]
DeepSeek. 2025. DeepSeek-V3.2 Release. DeepSeek API Documentation. https://api-docs.deepseek.com/news/news251201 Introduces DeepSeek-V3.2 and DeepSeek-V3.2-Speciale
work page 2025
-
[5]
Felix TJ Dietrich, Yuchen Zhou, Tobias Wasner, Stephan Krusche, and Mari- bel Acosta. 2025. LLM-Based Multi-Artifact Consistency Verification for Pro- gramming Exercise Quality Assurance. InProceedings of the 25th Koli Calling International Conference on Computing Education Research. 1–11
work page 2025
-
[6]
Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K. Lahiri. 2022. TOGA: a neural method for test oracle generation. InProceedings of the 44th International Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2130–2141. doi:10.1145/3510003.3510141
-
[7]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M. Zhang. 2023. Large Language Models for Software Engineer- ing: Survey and Open Problems. InProceedings - 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering, ICSE-FoSE
work page 2023
-
[8]
doi:10.1109/ICSE-FoSE59343.2023.00008
31–53. doi:10.1109/ICSE-FoSE59343.2023.00008
-
[9]
Soneya Binta Hossain and Matthew B. Dwyer. 2025. TOGLL: Correct and Strong Test Oracle Generation with LLMS. In2025 IEEE/ACM 47th International Con- ference on Software Engineering (ICSE). 1475–1487. doi:10.1109/ICSE55347.2025. 00098
-
[10]
Dwyer, Sebastian Elbaum, and Willem Visser
Soneya Binta Hossain, Antonio Filieri, Matthew B. Dwyer, Sebastian Elbaum, and Willem Visser. 2023. Neural-Based Test Oracle Generation: A Large-Scale Evalua- tion and Lessons Learned. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (San Francisco, CA, USA)(ESEC/FSE 2023...
-
[11]
Soneya Binta Hossain, Raygan Taylor, and Matthew Dwyer. 2025. Doc2OracLL: Investigating the Impact of Documentation on LLM-Based Test Oracle Generation. Proc. ACM Softw. Eng.2, FSE, Article FSE084 (June 2025), 22 pages. doi:10.1145/ 3729354
work page 2025
-
[12]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology33, 8, Article 220 (2024). doi:10.1145/ 3695988
work page 2024
-
[13]
Hyeonseok Lee, Gabin An, and Shin Yoo. 2025. Metamon: Finding inconsistencies between program documentation and behavior using metamorphic LLM queries. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 120–127
work page 2025
-
[14]
OpenAI. 2024.GPT-4o System Card. Technical Report. OpenAI. https://cdn. openai.com/gpt-4o-system-card.pdf
work page 2024
-
[15]
2025.Update to GPT-5 System Card: GPT-5.2
OpenAI. 2025.Update to GPT-5 System Card: GPT-5.2. Technical Report. OpenAI. https://openai.com/index/gpt-5-system-card-update-gpt-5-2/ Covers GPT-5.2 family; experiments used GPT-5.2 Chat endpoint
work page 2025
-
[16]
xAI. 2025.Grok 4 Fast Model Card. Technical Report. xAI. https://data.x. ai/2025-09-19-grok-4-fast-model-card.pdf Covers Grok 4 Fast reasoning and non-reasoning modes
work page 2025
- [17]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.