Recognition: 2 theorem links
· Lean TheoremStochastic Generative Plug-and-Play Priors
Pith reviewed 2026-05-13 18:16 UTC · model grok-4.3
The pith
Noise injection in plug-and-play methods lets pretrained diffusion denoisers serve directly as generative priors by optimizing a Gaussian-smoothed objective and escaping saddle points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
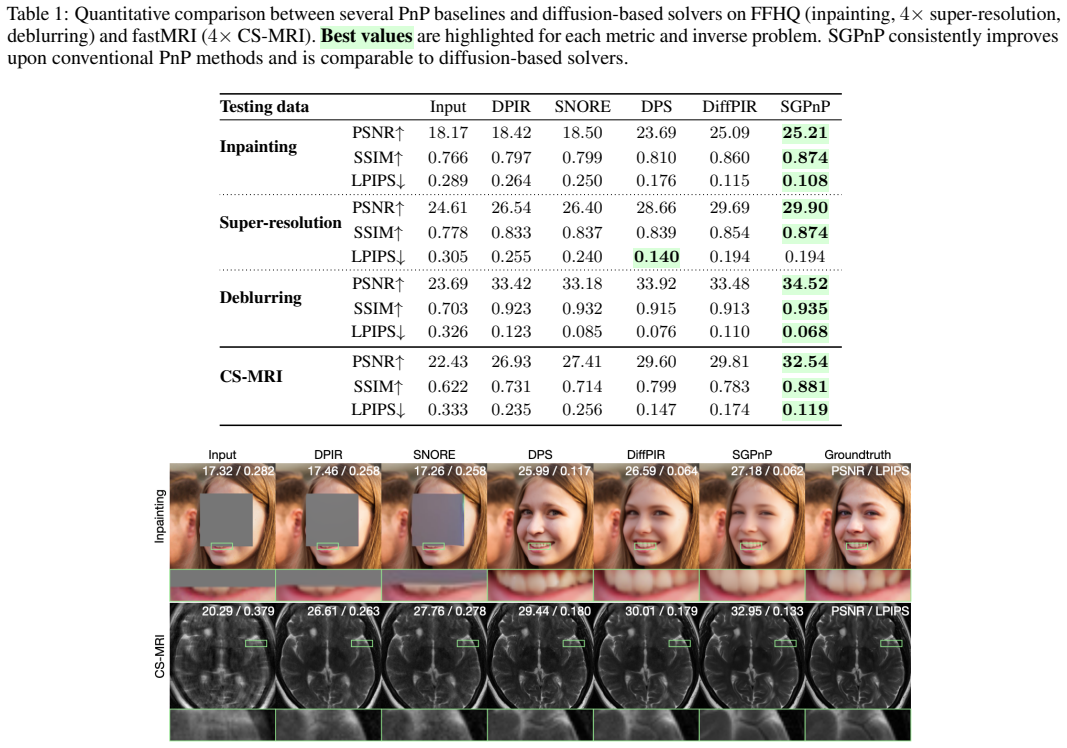
A score-based reading of PnP permits direct use of pretrained SBDM denoisers inside PnP iterations. Injecting noise inside these iterations produces the SGPnP algorithm, which the authors prove performs optimization on a Gaussian-smoothed objective and promotes escape from strict saddle points. This yields measurable robustness gains on severely ill-posed tasks such as multi-coil MRI reconstruction and large-mask natural-image inpainting, reaching performance competitive with dedicated diffusion solvers.
What carries the argument
The stochastic generative PnP (SGPnP) framework, which inserts Gaussian noise into each PnP iteration that employs an SBDM denoiser, thereby turning the iteration into minimization of a Gaussian-smoothed objective.
If this is right
- Pretrained SBDM denoisers can be dropped into existing PnP solvers without reverse diffusion sampling or task-specific fine-tuning.
- The resulting iterates converge to solutions of a Gaussian-smoothed objective rather than the original non-smooth one.
- Strict saddle points that trap conventional PnP become easier to escape, raising success rates on severely ill-posed problems.
- Performance on multi-coil MRI and large-mask inpainting becomes competitive with full diffusion-based reconstruction pipelines.
Where Pith is reading between the lines
- The Gaussian-smoothing view may extend to other noise-based or stochastic regularization schemes used inside iterative solvers.
- Similar noise-injection tricks could be tested on non-diffusion generative models that supply approximate scores or gradients.
- The approach suggests a route for combining classical optimization guarantees with modern generative priors across additional imaging modalities.
Load-bearing premise
The pretrained SBDM denoiser continues to approximate the score of the target data distribution even after the extra noise is added inside the PnP loop, without any retraining or adaptation.
What would settle it
Run the same inverse problems with and without the noise-injection step; if the version without noise injection matches or exceeds the stochastic version in both final error and frequency of saddle-point trapping, the claimed benefit of smoothing and escape does not hold.
Figures



read the original abstract
Plug-and-play (PnP) methods are widely used for solving imaging inverse problems by incorporating a denoiser into optimization algorithms. Score-based diffusion models (SBDMs) have recently demonstrated strong generative performance through a denoiser trained across a wide range of noise levels. Despite their shared reliance on denoisers, it remains unclear how to systematically use SBDMs as priors within the PnP framework without relying on reverse diffusion sampling. In this paper, we establish a score-based interpretation of PnP that justifies using pretrained SBDMs directly within PnP algorithms. Building on this connection, we introduce a stochastic generative PnP (SGPnP) framework that injects noise to better leverage the expressive generative SBDM priors, thereby improving robustness in severely ill-posed inverse problems. We provide a new theory showing that this noise injection induces optimization on a Gaussian-smoothed objective and promotes escape from strict saddle points. Experiments on challenging inverse tasks, such as multi-coil MRI reconstruction and large-mask natural image inpainting, demonstrate consistent improvement over conventional PnP methods and achieve performance competitive with diffusion-based solvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a score-based interpretation of plug-and-play (PnP) methods that allows pretrained score-based diffusion models (SBDMs) to be used directly as priors in PnP algorithms for solving imaging inverse problems. It proposes the stochastic generative PnP (SGPnP) framework, which injects noise into the iterations to leverage the generative capabilities of SBDMs. A new theory is presented showing that this noise injection corresponds to optimization over a Gaussian-smoothed objective and facilitates escape from strict saddle points. Experimental results on multi-coil MRI reconstruction and large-mask image inpainting show consistent improvements over conventional PnP approaches and competitiveness with diffusion-based solvers.
Significance. If the theoretical foundations hold, this work bridges PnP optimization with generative diffusion priors in a principled manner, enabling direct use of pretrained SBDMs without retraining or full reverse sampling. The Gaussian-smoothing and saddle-escape properties could have broader impact on non-convex optimization for ill-posed inverse problems, while the reported gains on MRI and inpainting tasks indicate practical relevance for severely underdetermined imaging applications.
major comments (1)
- [Theory on Gaussian smoothing and saddle escape] The score-based interpretation and the claim that noise injection induces optimization on a Gaussian-smoothed objective (and promotes escape from strict saddle points) rest on the assumption that a pretrained SBDM denoiser continues to approximate the relevant score function when noise is injected inside the PnP iteration loop. SBDMs are trained only along a specific forward-process noise schedule; the manuscript provides neither explicit bounds on the resulting score approximation error nor empirical checks (e.g., score-error plots or ablation on injection levels) confirming that the approximation remains controlled. This is load-bearing for both the theoretical justification and the claimed robustness benefits.
minor comments (1)
- The abstract and text refer to an 'exact noise schedule' and 'quantitative error analysis,' yet these details are not supplied in the provided manuscript; including them would improve verifiability of the experimental protocol.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work's significance and for the detailed feedback on the theoretical aspects. We have carefully considered the major comment and provide our response below. We believe the concerns can be addressed through additional empirical analysis in the revision.
read point-by-point responses
-
Referee: [Theory on Gaussian smoothing and saddle escape] The score-based interpretation and the claim that noise injection induces optimization on a Gaussian-smoothed objective (and promotes escape from strict saddle points) rest on the assumption that a pretrained SBDM denoiser continues to approximate the relevant score function when noise is injected inside the PnP iteration loop. SBDMs are trained only along a specific forward-process noise schedule; the manuscript provides neither explicit bounds on the resulting score approximation error nor empirical checks (e.g., score-error plots or ablation on injection levels) confirming that the approximation remains controlled. This is load-bearing for both the theoretical justification and the claimed robustness benefits.
Authors: We appreciate the referee highlighting this important assumption in our theoretical development. The score-based interpretation relies on the pretrained SBDM providing a good approximation to the score function at the noise levels encountered during the PnP iterations. Since SBDMs are trained on a continuous noise schedule covering a wide range of noise levels, and our noise injection is chosen within this range, we believe the approximation holds reasonably well. However, we acknowledge that explicit error bounds are not derived in the manuscript, as deriving tight bounds for general pretrained models is challenging without additional assumptions on the data distribution. To address this, we will include empirical validations such as score-error plots for the denoiser at various injection levels and ablations showing performance sensitivity to the noise injection schedule in the revised manuscript. This will help confirm that the approximation remains controlled in practice. revision: partial
- Deriving explicit theoretical bounds on the score approximation error for arbitrary pretrained SBDMs without further assumptions on the data distribution
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper derives its score-based interpretation of PnP and the Gaussian-smoothing theory directly from the stochastic update rules and score-function properties, without reducing any central claim to a fitted parameter, self-citation chain, or definitional equivalence. The noise-injection analysis follows from the explicit stochastic dynamics presented, and the saddle-escape result is obtained from the resulting smoothed objective rather than being presupposed. No load-bearing step collapses to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pretrained score-based diffusion denoiser approximates the score of the data distribution at multiple noise levels.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclearh_σ(x) := -E[log p_σ(x+σn)], U_σ(x,n):=σ^{-2}(x-D_θ(x+σn)), noise injection induces optimization on Gaussian-smoothed objective and escape from strict saddle points (Thm 1, Assump 2-3, Tweedie formula)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration (higher-derivative calibration to J) unclearSGPnP iteration x_{k+1}=x_k - γ_k (∇g + U_σk), annealed σ_k→0 yields convergence to critical point of un-smoothed f_0 (Thm 2, Assump 4)
Reference graph
Works this paper leans on
-
[1]
Plug-and-play priors for model based reconstruction,
S. V . Venkatakrishnan, C. A. Bouman, and B. Wohlberg, “Plug-and-play priors for model based reconstruction,” in 2013 IEEE Global Conference on Signal and Information Processing. IEEE, 2013, pp. 945–948
work page 2013
-
[2]
M. Renaud, J. Prost, A. Leclaire, and N. Papadakis, “Plug- and-play image restoration with stochastic denoising regu- Figure 5: Additional box inpainting results on more measure- ments. For this challenging task, DPIR and SNORE often produce incomplete reconstructions. SDPnP-PGM improves the result but still remains incomplete in some cases, whereas SGPnP...
work page 2024
-
[3]
Plug-and-play image restoration with deep denoiser prior,
K. Zhang, Y . Li, W. Zuo, L. Zhang, L. Van Gool, and R. Timofte, “Plug-and-play image restoration with deep denoiser prior,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6360–6376, 2021
work page 2021
-
[4]
Denoising diffusion proba- bilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion proba- bilistic models,” inAdvances in Neural Information Pro- cessing Systems, vol. 33, 2020, pp. 6840–6851
work page 2020
-
[5]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Er- mon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[6]
Random walks with Tweedie: A unified view of score-based diffusion models [in the spotlight],
C. Y . Park, M. T. McCann, C. Garcia-Cardona, B. Wohlberg, and U. S. Kamilov, “Random walks with Tweedie: A unified view of score-based diffusion models [in the spotlight],”IEEE Signal Processing Magazine, vol. 42, no. 3, pp. 40–51, 2025. [Online]. Available: https://doi.org/10.1109/MSP.2025.3590608
-
[7]
The little engine that could: regularization by denoising (RED),
Y . Romano, M. Elad, and P. Milanfar, “The little engine that could: regularization by denoising (RED),”SIAM Journal on Imaging Sciences, vol. 10, no. 4, pp. 1804–1844, 2017
work page 2017
-
[8]
Bayesian imaging using plug & play priors: when Langevin meets Tweedie,
R. Laumont, V . De Bortoli, A. Almansa, J. Delon, A. Dur- mus, and M. Pereyra, “Bayesian imaging using plug & play priors: when Langevin meets Tweedie,”SIAM Journal on Imaging Sciences, vol. 15, no. 2, pp. 701–737, 2022
work page 2022
-
[9]
Generative plug and play: Posterior sampling for inverse problems,
C. A. Bouman and G. T. Buzzard, “Generative plug and play: Posterior sampling for inverse problems,” in2023 59th Annual Allerton Conference on Communication, Con- trol, and Computing (Allerton). IEEE, 2023, pp. 1–7. 11
work page 2023
-
[10]
Denoising diffusion models for plug-and- play image restoration,
Y . Zhu, K. Zhang, J. Liang, J. Cao, B. Wen, R. Timofte, and L. Van Gool, “Denoising diffusion models for plug-and- play image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1219–1229
work page 2023
-
[11]
Denoising dif- fusion restoration models,
B. Kawar, M. Elad, S. Ermon, and J. Song, “Denoising dif- fusion restoration models,” inAdvances in Neural Informa- tion Processing Systems, vol. 35, 2022, pp. 23 593–23 606
work page 2022
-
[12]
Diffusion posterior sampling for general noisy inverse problems,
H. Chung, J. Kim, M. T. McCann, M. L. Klasky, and J. C. Ye, “Diffusion posterior sampling for general noisy inverse problems,” inProc. ICLR, 2023
work page 2023
-
[13]
Score-based diffusion models for Bayesian image recon- struction,
M. T. McCann, H. Chung, J. C. Ye, and M. L. Klasky, “Score-based diffusion models for Bayesian image recon- struction,” in2023 IEEE International Conference on Im- age Processing (ICIP), Kuala Lumpur, Malaysia, 2023, pp. 111–115
work page 2023
-
[14]
Provable probabilistic imaging using score-based genera- tive priors,
Y . Sun, Z. Wu, Y . Chen, B. T. Feng, and K. L. Bouman, “Provable probabilistic imaging using score-based genera- tive priors,”IEEE Transactions on Computational Imaging, 2024
work page 2024
-
[15]
Principled probabilistic imaging using diffusion models as plug-and-play priors,
Z. Wu, Y . Sun, Y . Chen, B. Zhang, Y . Yue, and K. L. Bouman, “Principled probabilistic imaging using diffusion models as plug-and-play priors,” inProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[16]
Provably robust score-based diffusion posterior sampling for plug-and-play image reconstruction,
X. Xu and Y . Chi, “Provably robust score-based diffusion posterior sampling for plug-and-play image reconstruction,” arXiv:2403.17042, 2024
-
[17]
Plug-and- play split Gibbs sampler: Embedding deep generative pri- ors in bayesian inference,
F. Coeurdoux, N. Dobigeon, and P. Chainais, “Plug-and- play split Gibbs sampler: Embedding deep generative pri- ors in bayesian inference,”IEEE Transactions on Image Processing, 2024
work page 2024
-
[18]
Regularization by denoising: Bayesian model and Langevin-within-split Gibbs sampling,
E. C. Faye, M. D. Fall, and N. Dobigeon, “Regularization by denoising: Bayesian model and Langevin-within-split Gibbs sampling,”arXiv:2402.12292, 2024
-
[19]
PnP-CM: Consistency Models as Plug-and-Play Priors for Inverse Problems
M. Gülle, J. Yun, Y . U. Alçalar, and M. Akçakaya, “Consis- tency models as plug-and-play priors for inverse problems,” arXiv:2509.22736, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
arXiv preprint arXiv:2410.00083 , year=
G. Daras, H. Chung, C.-H. Lai, Y . Mitsufuji, J. C. Ye, P. Milanfar, A. G. Dimakis, and M. Delbracio, “A survey on diffusion models for inverse problems,”arXiv:2410.00083, 2024
-
[21]
Plug-and-play priors as a score-based method,
C. Y . Park, Y . Hu, M. T. McCann, C. Garcia-Cardona, B. Wohlberg, and U. S. Kamilov, “Plug-and-play priors as a score-based method,” inIEEE International Conference on Image Processing, Anchorage, Alaska, 2025
work page 2025
-
[22]
N. Parikh and S. Boyd, “Proximal algorithms,”Foundations and Trends® in Optimization, vol. 1, no. 3, pp. 127–239, 2014
work page 2014
-
[23]
Plug-and-play ADMM for image restoration: Fixed-point convergence and applications,
S. H. Chan, X. Wang, and O. A. Elgendy, “Plug-and-play ADMM for image restoration: Fixed-point convergence and applications,”IEEE Transactions on Computational Imaging, vol. 3, no. 1, pp. 84–98, 2016
work page 2016
-
[24]
A fast stochastic plug-and-play ADMM for imaging inverse problems,
J. Tang and M. Davies, “A fast stochastic plug-and-play ADMM for imaging inverse problems,”arXiv:2006.11630, 2020
-
[25]
Scalable plug-and-play ADMM with convergence guar- antees,
Y . Sun, Z. Wu, X. Xu, B. Wohlberg, and U. S. Kamilov, “Scalable plug-and-play ADMM with convergence guar- antees,”IEEE Transactions on Computational Imaging, vol. 7, pp. 849–863, 2021
work page 2021
-
[26]
Online regular- ization by denoising with applications to phase retrieval,
Z. Wu, Y . Sun, J. Liu, and U. S. Kamilov, “Online regular- ization by denoising with applications to phase retrieval,” inProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019
work page 2019
-
[27]
Y . Sun, J. Liu, Y . Sun, B. Wohlberg, and U. S. Kamilov, “Async-RED: A provably convergent asynchronous block parallel stochastic method using deep denoising priors,” arXiv:2010.01446, 2020
-
[28]
SGD-Net: Efficient model-based deep learn- ing with theoretical guarantees,
J. Liu, Y . Sun, W. Gan, X. Xu, B. Wohlberg, and U. S. Kamilov, “SGD-Net: Efficient model-based deep learn- ing with theoretical guarantees,”IEEE Transactions on Computational Imaging, vol. 7, pp. 598–610, 2021
work page 2021
-
[29]
Plug-in stochas- tic gradient method,
Y . Sun, B. Wohlberg, and U. S. Kamilov, “Plug-in stochas- tic gradient method,”arXiv:1811.03659, 2018
-
[30]
An online plug-and-play algorithm for regularized image reconstruction,
——, “An online plug-and-play algorithm for regularized image reconstruction,”IEEE Transactions on Computa- tional Imaging, vol. 5, no. 3, pp. 395–408, 2019
work page 2019
-
[31]
Tweedie’s formula and selection bias,
B. Efron, “Tweedie’s formula and selection bias,”Journal of the American Statistical Association, vol. 106, no. 496, pp. 1602–1614, 2011
work page 2011
-
[32]
Escaping saddles with stochastic gradients,
H. Daneshmand, J. Kohler, A. Lucchi, and T. Hofmann, “Escaping saddles with stochastic gradients,” inProceed- ings of the International Conference on Machine Learning. PMLR, 2018, pp. 1155–1164
work page 2018
-
[33]
Nonconvergence to unstable points in Urn models and stochastic approximations,
R. Pemantle, “Nonconvergence to unstable points in Urn models and stochastic approximations,”The Annals of Probability, vol. 18, no. 2, pp. 698–712, 1990
work page 1990
-
[34]
Y . Carmon, J. C. Duchi, O. Hinder, and A. Sidford, ““Con- vex until proven guilty”: Dimension-free acceleration of gradient descent on non-convex functions,” inProceedings of the 34th International Conference on Machine Learning. PMLR, 2017, pp. 654–663
work page 2017
-
[35]
Finding approximate local minima faster than gradient descent,
N. Agarwal, Z. Allen-Zhu, B. Bullins, E. Hazan, and T. Ma, “Finding approximate local minima faster than gradient descent,” inProceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing, 2017, pp. 1195–1199
work page 2017
-
[36]
Parameter-free accelerated gradient descent for nonconvex minimization,
N. Marumo and A. Takeda, “Parameter-free accelerated gradient descent for nonconvex minimization,”SIAM Jour- nal on Optimization, vol. 34, no. 2, pp. 2093–2120, 2024
work page 2093
-
[37]
H. Li and Z. Lin, “Restarted nonconvex accelerated gra- dient descent: No more polylogarithmic factor in the O(ϵ−7/4) complexity,”Journal of Machine Learning Re- search, vol. 24, no. 157, pp. 1–37, 2023
work page 2023
-
[38]
A connection between score matching and de- noising autoencoders,
P. Vincent, “A connection between score matching and de- noising autoencoders,”Neural computation, vol. 23, no. 7, pp. 1661–1674, 2011
work page 2011
-
[39]
A style-based generator architecture for generative adversarial networks,
T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410
work page 2019
-
[40]
J. Zbontar, F. Knoll, A. Sriram, T. Murrell, Z. Huang, M. J. Muckley, A. Defazio, R. Stern, P. Johnson, M. Bruno, 12 M. Parente, K. J. Geras, J. Katsnelson, H. Chandarana, Z. Zhang, M. Drozdzal, A. Romero, M. Rabbat, P. Vin- cent, N. Yakubova, J. Pinkerton, D. Wang, E. Owens, C. L. Zitnick, M. P. Recht, D. K. Sodickson, and Y . W. Lui, “fastMRI: An open d...
-
[41]
F. Knoll, J. Zbontar, A. Sriram, M. J. Muckley, M. Bruno, A. Defazio, M. Parente, K. J. Geras, J. Katsnelson, H. Chan- darana, Z. Zhang, M. Drozdzal, A. Romero, M. Rabbat, P. Vincent, J. Pinkerton, D. Wang, N. Yakubova, E. Owens, C. L. Zitnick, M. P. Recht, D. K. Sodickson, and Y . W. Lui, “fastMRI: A publicly available raw k-space and dicom dataset of kn...
work page 2020
-
[42]
Mea- surement score-based diffusion model,
C. Y . Park, S. Shoushtari, H. An, and U. S. Kamilov, “Mea- surement score-based diffusion model,” inInternational Conference on Learning Representations, 2026
work page 2026
-
[43]
Proximal splitting methods in signal processing,
P. L. Combettes and J.-C. Pesquet, “Proximal splitting methods in signal processing,” inFixed-Point Algorithms for Inverse Problems in Science and Engineering. New York, NY: Springer New York, 2011, pp. 185–212
work page 2011
-
[44]
DeepInverse: A deep learning framework for inverse prob- lems in imaging,
J. Tachella, D. Chen, S. Hurault, M. Terris, and A. Wang, “DeepInverse: A deep learning framework for inverse prob- lems in imaging,” 2023, date released: 2023-06-30
work page 2023
-
[45]
The unreasonable effectiveness of deep features as a per- ceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a per- ceptual metric,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2018, pp. 586–595. 13
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.