Recognition: 1 theorem link
· Lean TheoremToward Executable Repository-Level Code Generation via Environment Alignment
Pith reviewed 2026-05-13 17:32 UTC · model grok-4.3
The pith
EnvGraph improves repository-level code generation by treating executability as an environment alignment problem solved through iterative revision based on execution evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
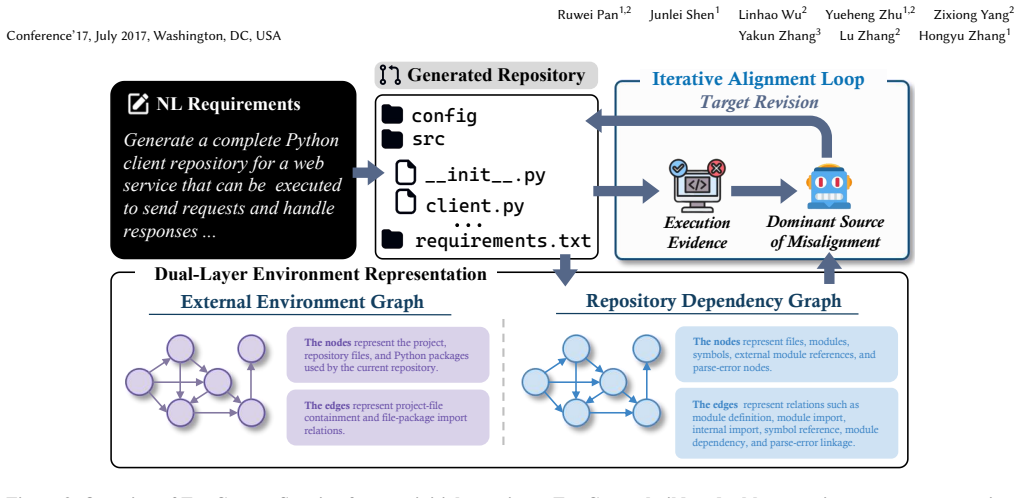
The paper claims that repository executability reduces to an environment alignment task that simultaneously satisfies external dependency conditions and resolves repository-internal references. EnvGraph implements this via a dual-layer representation, execution-evidence-based attribution of issues, and a unified targeted revision mechanism inside an iterative loop. When tested with three backbone LLMs on repository-level benchmarks, the method delivers absolute gains of 5.72-5.87 percentage points in functional correctness and 4.58-8.66 percentage points in non-functional quality over the strongest non-EnvGraph baselines.
What carries the argument
EnvGraph's dual-layer environment representation together with its execution-evidence-based attribution step, which identifies concrete code problems from partial runs and feeds them into the iterative revision loop.
Load-bearing premise
Partial execution runs supply reliable signals that can be accurately attributed to specific code defects without the alignment process diverging or becoming prohibitively expensive.
What would settle it
A new repository-level benchmark in which EnvGraph produces no gain or a loss in functional correctness compared with the strongest baseline would show the alignment loop does not deliver a general advantage.
Figures




read the original abstract
Large language models (LLMs) have achieved strong performance on code generation, but existing methods still struggle with repository-level code generation under executable validation. Under this evaluation setting, success is determined not by the plausibility of isolated code fragments, but by whether a generated multi-file repository can be successfully installed, have its dependencies and internal references resolved, be launched, and be validated in a real execution environment. To address this challenge, we propose EnvGraph, a framework for repository-level code generation that formulates repository executability as an environment alignment problem. EnvGraph jointly models two coupled conditions for successful repository execution, namely external dependency satisfaction and repository-internal reference resolution. It maintains a dual-layer environment representation, uses execution evidence to perform execution-evidence-based attribution, and guides repository generation through a unified targeted revision mechanism within an iterative alignment loop. We evaluate EnvGraph on repository-level code generation with three representative backbone LLMs and compare it against representative environment-aware and repository-level baselines. Experimental results show that EnvGraph consistently achieves the best performance on these repository-level benchmarks. In particular, it outperforms the strongest non-EnvGraph baseline by an absolute margin of 5.72--5.87 percentage points in Functional Correctness and 4.58--8.66 percentage points in Non-Functional Quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EnvGraph, a framework for repository-level code generation that models executability as an environment alignment problem. It introduces a dual-layer environment representation, execution-evidence-based attribution of failures, and a unified targeted revision mechanism inside an iterative alignment loop. Experiments using three backbone LLMs on repository-level benchmarks report that EnvGraph outperforms the strongest non-EnvGraph baseline by 5.72–5.87 percentage points in Functional Correctness and 4.58–8.66 percentage points in Non-Functional Quality.
Significance. If the attribution mechanism can be shown to reliably identify root causes in interdependent multi-file repositories, the work would meaningfully advance practical LLM-based repository generation by directly addressing installability, reference resolution, and executability rather than isolated snippet plausibility.
major comments (2)
- [Experimental Results] Experimental evaluation: The abstract and results summary report absolute performance margins of 5.72–5.87 pp in Functional Correctness without any mention of statistical significance tests, standard deviations across runs, or exact baseline re-implementations, leaving open the possibility that observed gains reflect evaluation confounds rather than the proposed alignment loop.
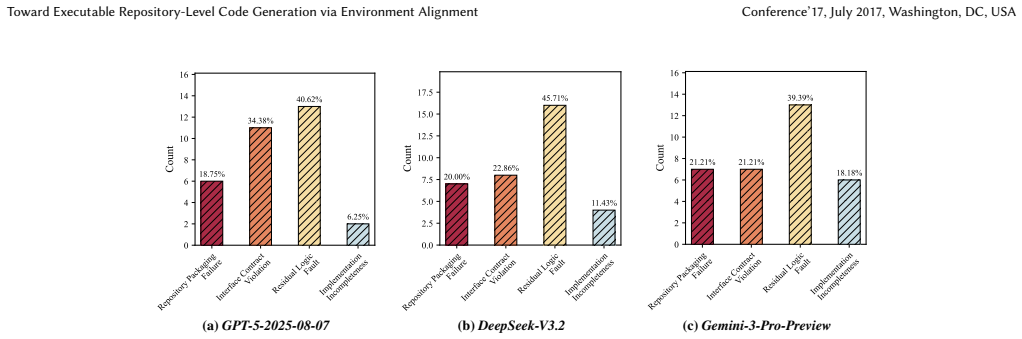
- [Method (iterative alignment loop)] Execution-evidence-based attribution and iterative loop: The central claim that the dual-layer representation plus targeted revision produces the reported gains rests on the attribution step correctly mapping partial-run failures (install errors, import failures, runtime exceptions) to the precise files or references responsible; no ablation isolating attribution accuracy or measuring divergence rate on the hardest repositories is described, so it remains possible that gains arise from extra iterations rather than precise attribution.
minor comments (2)
- [Abstract] Abstract: The phrase 'three representative backbone LLMs' and 'representative environment-aware and repository-level baselines' should be expanded with the concrete model names and baseline citations for immediate clarity.
- [Method] Notation: The dual-layer environment representation is introduced without a compact formal definition or accompanying diagram; adding either would improve readability of the environment alignment formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental rigor and the need to better isolate the attribution mechanism. We address each major comment below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Experimental Results] Experimental evaluation: The abstract and results summary report absolute performance margins of 5.72–5.87 pp in Functional Correctness without any mention of statistical significance tests, standard deviations across runs, or exact baseline re-implementations, leaving open the possibility that observed gains reflect evaluation confounds rather than the proposed alignment loop.
Authors: We acknowledge the need for greater statistical rigor. In the revised manuscript, we will add statistical significance tests (e.g., paired t-tests across multiple seeds) on the reported margins, include standard deviations from repeated runs, and provide detailed descriptions of baseline re-implementations including exact prompts, hyperparameters, and environment configurations. These additions will be reflected in both the results section and an updated abstract. revision: yes
-
Referee: [Method (iterative alignment loop)] Execution-evidence-based attribution and iterative loop: The central claim that the dual-layer representation plus targeted revision produces the reported gains rests on the attribution step correctly mapping partial-run failures (install errors, import failures, runtime exceptions) to the precise files or references responsible; no ablation isolating attribution accuracy or measuring divergence rate on the hardest repositories is described, so it remains possible that gains arise from extra iterations rather than precise attribution.
Authors: We agree that an ablation isolating attribution accuracy is necessary to support the central claim. We will add an ablation experiment comparing the full EnvGraph against a variant that replaces evidence-based attribution with random or uniform file revision. We will also report attribution accuracy metrics and divergence rates (incorrect attributions leading to failed revisions) specifically on the hardest repositories. This will clarify the contribution of precise attribution versus iteration count alone. revision: yes
Circularity Check
No significant circularity in framework definition or empirical claims
full rationale
The paper introduces EnvGraph as a new framework that models repository executability via dual-layer environment representation, execution-evidence attribution, and an iterative targeted revision loop. Performance gains (5.72–5.87 pp Functional Correctness, 4.58–8.66 pp Non-Functional Quality) are reported from direct comparisons against external baselines on independent repository-level benchmarks. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or description that would make the central claims reduce to their own inputs by construction. The evaluation relies on external benchmarks and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Execution feedback from partial repository runs provides sufficient signal for targeted code revision
invented entities (1)
-
EnvGraph dual-layer environment representation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EnvGraph maintains a dual-layer environment representation... external environment graph G_ext... repository dependency graph G_int... execution-evidence-based attribution... iterative alignment loop
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D C, Arun Iyer, Suresh Parthasarathy, Sriram Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2024. Codeplan: Repository-level coding using llms and planning.Proceed- ings of the ACM on Software Engineering1, FSE (2024), 675–698. Toward Executable Repository-Level Code Generation via Environment...
work page 2024
-
[2]
MarkChen,JerryTworek,HeewooJun,QimingYuan,HenriquePondeDeOliveira Pinto,JaredKaplan,HarriEdwards,YuriBurda,NicholasJoseph,GregBrockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Codemenv: Benchmarking large language models on code migration
Keyuan Cheng, Xudong Shen, Yihao Yang, TengyueWang TengyueWang, Yang Cao,MuhammadAsifAli,HanbinWang,LijieHu,andDiWang.2025. Codemenv: Benchmarking large language models on code migration. InFindings of the Association for Computational Linguistics: ACL 2025. 2719–2744
work page 2025
- [4]
-
[5]
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, et al. 2023. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion.Advances in Neural Information Processing Systems36 (2023), 46701–46723
work page 2023
-
[6]
John Estdale and Elli Georgiadou. 2018. Applying the ISO/IEC 25010 qual- ity models to software product. InEuropean Conference on Software Process Improvement. Springer, 492–503
work page 2018
- [7]
- [8]
-
[9]
Xing Hu, Feifei Niu, Junkai Chen, Xin Zhou, Junwei Zhang, Junda He, Xin Xia, and David Lo. 2025. Assessing and advancing benchmarks for evaluating large language models in software engineering tasks.ACM Transactions on Software Engineering and Methodology(2025)
work page 2025
- [10]
-
[11]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology35, 2 (2026), 1–72
work page 2026
-
[12]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Sathvik Joel, Jie Wu, and Fatemeh Fard. 2024. A survey on llm-based code generation for low-resource and domain-specific programming languages.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
-
[14]
Li Kuang, Qi Xie, HaiYang Yang, Yang Yang, Xiang Wei, HaoYue Kang, and YingJie Xia. 2025. APIMig: A Project-Level Cross-Multi-Version API Migration Framework Based on Evolution Knowledge Graph. InProceedings of the Thirty- Fourth International Joint Conference on Artificial Intelligence. 7455–7463
work page 2025
-
[15]
Sachit Kuhar, Wasi Ahmad, Zijian Wang, Nihal Jain, Haifeng Qian, Baishakhi Ray, Murali Krishna Ramanathan, Xiaofei Ma, and Anoop Deoras. 2025. Libevo- lutioneval: A benchmark and study for version-specific code generation. InPro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human ...
work page 2025
-
[16]
Nam Le Hai, Dung Manh Nguyen, and Nghi DQ Bui. 2025. On the impacts of contexts on repository-level code generation. InFindings of the Association for Computational Linguistics: NAACL 2025. 1496–1524
work page 2025
-
[17]
InFindings of the Association for Computational Linguistics: ACL 2024
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, KaiboLiu,ZhengFang,LanshenWang,etal .2024.Deveval:Amanually-annotated code generation benchmark aligned with real-world code repositories. InFindings of the Association for Computational Linguistics: ACL 2024. 3603–3614
work page 2024
- [18]
- [19]
-
[20]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[21]
Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems36 (2023), 46534–46594
work page 2023
-
[22]
MetricsforAssessingaSoftwareSystem’s Maintainability
PaulOmanandJackHagemeister.1992. MetricsforAssessingaSoftwareSystem’s Maintainability. InProceedings of the Conference on Software Maintenance. 337– 344
work page 1992
-
[23]
Paul Oman and Jack Hagemeister. 1994. Construction and Testing of Polynomials PredictingSoftwareMaintainability.JournalofSystemsandSoftware24,3(1994), 251–266
work page 1994
- [24]
- [25]
- [26]
-
[27]
Jishnu Sen. 2025. Large Language Models for Code: A Focused Survey of Ten Recent Studies on Methods, Evaluation, and Robustness. (2025)
work page 2025
-
[28]
Umama,KamaluddeenUsmanDanyaro,MagedNasser,AbubakarZakari,Shamsu Abdullahi, Atika Khanzada, Muhammad Muntasir Yakubu, and Sara Shoaib
-
[29]
doi:10.1109/ACCESS.2025.3631952
LLM-Based Code Generation: A Systematic Literature Review With Technical and Demographic Insights.IEEE Access13 (2025), 194915–194939. doi:10.1109/ACCESS.2025.3631952
-
[30]
Llmsmeetlibraryevolution:Evaluatingdeprecatedapiusage in llm-based code completion
Chong Wang, Kaifeng Huang, Jian Zhang, Yebo Feng, Lyuye Zhang, Yang Liu, andXinPeng.2025. Llmsmeetlibraryevolution:Evaluatingdeprecatedapiusage in llm-based code completion. In2025 ieee/acm 47th international conference on software engineering (icse). IEEE, 885–897
work page 2025
- [31]
- [32]
-
[33]
YixiWu,PengfeiHe,ZehaoWang,ShaoweiWang,YuanTian,andTse-HsunChen
- [34]
-
[35]
Dayu Yang, Tianyang Liu, Daoan Zhang, Antoine Simoulin, Xiaoyi Liu, Yuwei Cao, Zhaopu Teng, Xin Qian, Grey Yang, Jiebo Luo, et al.2025. Code to think, think to code: A survey on code-enhanced reasoning and reasoning-driven code intelligence in llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2586–2616
work page 2025
- [36]
-
[37]
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Qianxiang Wang, and Tao Xie. 2024. Codereval: A benchmark of pragmatic code generation with generative pre-trained models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
work page 2024
-
[38]
Repocoder:Repository-levelcode completion through iterative retrieval and generation
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao,Jian-GuangLou,andWeizhuChen.2023. Repocoder:Repository-levelcode completion through iterative retrieval and generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2471–2484
work page 2023
-
[39]
QuanjunZhang,ChunrongFang,YangXie,YuXiangMa,WeisongSun,YunYang, and Zhenyu Chen. 2024. A systematic literature review on large language models for automated program repair.ACM Transactions on Software Engineering and Methodology(2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.