Recognition: no theorem link
Structured Multi-Criteria Evaluation of Large Language Models with Fuzzy Analytic Hierarchy Process and DualJudge
Pith reviewed 2026-05-13 17:08 UTC · model grok-4.3
The pith
Fuzzy AHP with confidence-modulated uncertainty and a DualJudge hybrid produces more consistent LLM evaluations than direct scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
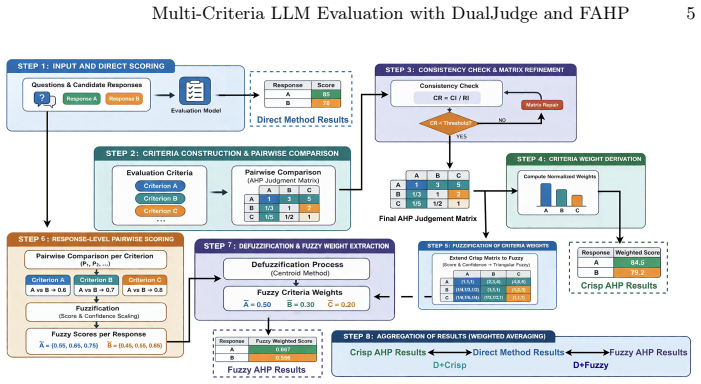
By representing pairwise comparisons as triangular fuzzy numbers whose spread is scaled by LLM-generated confidence, the Fuzzy AHP decomposes evaluation into explicit criteria, checks consistency, and aggregates via uncertainty-aware operators; when these outputs are fused with direct holistic scores inside DualJudge through a consistency-weighted mechanism, the resulting judgments outperform both pure direct scoring and standalone AHP on JudgeBench.
What carries the argument
Confidence-aware Fuzzy Analytic Hierarchy Process (FAHP) that modulates triangular fuzzy numbers with LLM-generated confidence scores to aggregate multi-criteria judgments while tracking epistemic uncertainty.
If this is right
- Evaluations remain more stable when comparison pairs contain high uncertainty.
- Explicit criteria make the sources of disagreement between judges traceable.
- Hybrid fusion improves performance on both easy and hard items in JudgeBench splits.
- The same decomposition can be applied to new criteria without retraining the underlying LLM.
Where Pith is reading between the lines
- The method could be ported to non-LLM decision tasks where raters have varying confidence.
- If criteria weights were learned from data rather than set by experts, calibration might improve further.
- Extending the fuzzy aggregation to larger hierarchies might reveal which criteria drive most of the uncertainty.
Load-bearing premise
LLM confidence scores reliably reflect epistemic uncertainty and that breaking evaluations into AHP criteria adds accuracy without injecting new systematic biases.
What would settle it
A human-labeled test set in which direct scoring matches human preferences more closely than either AHP or DualJudge, or in which FAHP judgments become less stable precisely when confidence scores are low.
Figures

read the original abstract
Effective evaluation of large language models (LLMs) remains a critical bottleneck, as conventional direct scoring often yields inconsistent and opaque judgments. In this work, we adapt the Analytic Hierarchy Process (AHP) to LLM-based evaluation and, more importantly, propose a confidence-aware Fuzzy AHP (FAHP) extension that models epistemic uncertainty via triangular fuzzy numbers modulated by LLM-generated confidence scores. Systematically validated on JudgeBench, our structured approach decomposes assessments into explicit criteria and incorporates uncertainty-aware aggregation, producing more calibrated judgments. Extensive experiments demonstrate that both crisp and fuzzy AHP consistently outperform direct scoring across model scales and dataset splits, with FAHP showing superior stability in uncertain comparison scenarios. Building on these insights, we propose \textbf{DualJudge}, a hybrid framework inspired by Dual-Process Theory that adaptively fuses holistic direct scores with structured AHP outputs via consistency-aware weighting. DualJudge achieves state-of-the-art performance, underscoring the complementary strengths of intuitive and deliberative evaluation paradigms. These results establish uncertainty-aware structured reasoning as a principled pathway toward more reliable LLM assessment. Code is available at https://github.com/hreyulog/AHP_llm_judge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript adapts the Analytic Hierarchy Process (AHP) and its fuzzy extension (FAHP) to LLM evaluation by decomposing judgments into explicit criteria and modeling uncertainty via triangular fuzzy numbers modulated by LLM-generated confidence scores. It introduces DualJudge, a hybrid framework that fuses direct holistic scores with structured AHP outputs through consistency-aware weighting, and reports that both crisp and fuzzy variants outperform direct scoring on JudgeBench, with DualJudge achieving state-of-the-art results.
Significance. If the results hold, the work supplies a structured, uncertainty-aware alternative to direct scoring that could improve consistency and interpretability in LLM assessment. The open-source code at the provided GitHub link is a clear strength that aids reproducibility.
major comments (2)
- Methods section on FAHP: the central claim that modulating triangular fuzzy numbers with LLM confidence scores improves calibration and stability rests on the untested assumption that these scores track epistemic uncertainty rather than overconfidence or bias; no Brier score, expected calibration error, or correlation with judgment accuracy on JudgeBench is reported to support this modulation step.
- Experiments section: the abstract states consistent outperformance across model scales and dataset splits with FAHP showing superior stability, yet provides no details on statistical significance tests, exact train/test splits, or controls for post-hoc hyperparameter choices, undermining verification of the SOTA claim for DualJudge.
minor comments (1)
- Abstract: the description of 'consistency-aware fusion weights' should explicitly state whether these are derived solely from the AHP consistency ratio or involve additional fitting.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address the major comments point by point below, and we plan to incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: Methods section on FAHP: the central claim that modulating triangular fuzzy numbers with LLM confidence scores improves calibration and stability rests on the untested assumption that these scores track epistemic uncertainty rather than overconfidence or bias; no Brier score, expected calibration error, or correlation with judgment accuracy on JudgeBench is reported to support this modulation step.
Authors: We agree that direct validation of the confidence scores as measures of epistemic uncertainty would strengthen the methodological justification. Although the original manuscript did not include Brier scores or expected calibration error, the superior performance of FAHP on JudgeBench provides indirect support for the approach. In the revision, we will add a correlation analysis between the LLM confidence scores and judgment accuracy on the benchmark to better substantiate the modulation step. revision: yes
-
Referee: Experiments section: the abstract states consistent outperformance across model scales and dataset splits with FAHP showing superior stability, yet provides no details on statistical significance tests, exact train/test splits, or controls for post-hoc hyperparameter choices, undermining verification of the SOTA claim for DualJudge.
Authors: We acknowledge the need for more rigorous experimental details to support the claims. The experiments utilized fixed dataset splits from JudgeBench without post-hoc hyperparameter optimization. We will include statistical significance testing (such as Wilcoxon signed-rank tests) and precise descriptions of the train/test splits and hyperparameter settings in the revised manuscript to allow for better verification of the results and the SOTA performance of DualJudge. revision: yes
Circularity Check
Minor risk from AHP weight derivation but no equations reduce to fitted parameters by construction
full rationale
The paper's central claims rest on empirical validation against the external JudgeBench dataset rather than any self-referential derivation. Standard AHP pairwise comparison matrices and triangular fuzzy number modulation are applied without the modulation step being fitted to the target judgments or renamed as a prediction. No self-citation chain is load-bearing for the uniqueness of the DualJudge fusion rule, and the consistency-aware weighting follows directly from the stated Dual-Process inspiration without reducing to prior author results by definition. The only minor elevation above zero arises from the conventional derivation of AHP criterion weights, which is not shown to be circular in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- AHP criteria weights
- consistency-aware fusion weights
axioms (1)
- domain assumption Standard AHP consistency ratio assumptions hold when applied to LLM judgments
Reference graph
Works this paper leans on
-
[1]
Buckley, J.: Fuzzy hierarchical analysis. Fuzzy Sets and Systems17(3), 233–247 (1985).https://doi.org/https://doi.org/10.1016/0165-0114(85)90090-9, https://www.sciencedirect.com/science/article/pii/0165011485900909
-
[2]
In: Bouamor, H., Pino, J., Bali, K
Chiang, C.H., Lee, H.y.: A closer look into using large language models for automatic evaluation. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 8928–8942. Association for Computational Linguistics, Singapore (Dec 2023).https:// doi.org/10.18653/v1/2023.findings-emnlp.599,https://aclan...
-
[3]
Journal of Mathematical Psychology29(4), 387–405 (1985)
Crawford, G., Williams, C.: A note on the analysis of subjective judg- ment matrices. Journal of Mathematical Psychology29(4), 387–405 (1985). https://doi.org/https://doi.org/10.1016/0022-2496(85)90002-1,https:// www.sciencedirect.com/science/article/pii/0022249685900021
-
[4]
Dubois, D.: Fuzzy Sets and Systems: Theory and Applications. Mathematics in Sci- ence and Engineering, Academic Press (1980),https://books.google.ru/books? id=JmjfHUUtMkMC
work page 1980
-
[5]
Emirtekin, E.: Large language model-powered automated assessment: A systematic review. Applied Sciences15(10) (2025).https://doi.org/10.3390/app15105683, https://www.mdpi.com/2076-3417/15/10/5683
-
[6]
José,A.S.,Alonso,Mª,T.,Lamata:Consistencyintheanalytichierarchyprocess:a new approach. Int. J. Uncertain. Fuzziness Knowl. Based Syst.14, 445–459 (2006), https://api.semanticscholar.org/CorpusID:18104088 Multi-Criteria LLM Evaluation with DualJudge and FAHP 15
work page 2006
- [7]
-
[8]
Kampourakis, V., Kavallieratos, G., Spathoulas, G., Gkioulos, V., Katsikas, S.: Llm-assisted ahp for explainable cyber range evaluation (2025),https://arxiv. org/abs/2512.10487
- [9]
-
[10]
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-eval: Nlg evaluation using gpt-4 with better human alignment (2023),https://arxiv.org/abs/2303.16634
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Lu, X., Li, J., Takeuchi, K., Kashima, H.: AHP-powered LLM reasoning for multi-criteria evaluation of open-ended responses. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Findings of the Association for Computational Lin- guistics: EMNLP 2024. pp. 1847–1856. Association for Computational Linguis- tics, Miami, Florida, USA (Nov 2024).https://doi.org/10....
-
[12]
OpenAI: gpt-oss-120b & gpt-oss-20b model card (2025),https://arxiv.org/abs/ 2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026),https: //qwen.ai/blog?id=qwen3.5
work page 2026
-
[14]
Saaty, R.: The analytic hierarchy process—what it is and how it is used. Mathematical Modelling9(3), 161–176 (1987).https://doi.org/https: //doi.org/10.1016/0270-0255(87)90473-8,https://www.sciencedirect.com/ science/article/pii/0270025587904738
-
[15]
Saaty, T.: The Analytic Hierarchy Process: Planning, Priority Setting, Resource Allocation. Advanced book program, McGraw-Hill International Book Company (1980),https://books.google.ru/books?id=Xxi7AAAAIAAJ
work page 1980
-
[16]
Saaty, T., Vargas, L.: Models, Methods, Concepts & Applications of the Analytic Hierarchy Process. International Series in Operations Research & Management Science, Springer (2012),https://books.google.ru/books?id=6J9XI8I1qjwC
work page 2012
-
[17]
Tan, S., Zhuang, S., Montgomery, K., Tang, W.Y., Cuadron, A., Wang, C., Popa, R., Stoica, I.: Judgebench: A benchmark for evaluating LLM-based judges. In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=G0dksFayVq
work page 2025
- [18]
-
[19]
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang, K., Zhuang, A., Fan, R., Yue, X., Chen, W.: Mmlu-pro: A more robust and challenging multi-task language understanding benchmark (2024),https://arxiv.org/abs/2406.01574
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
White, C., Dooley, S., Roberts, M., Pal, A., Feuer, B., Jain, S., Shwartz-Ziv, R., Jain, N., Saifullah, K., Dey, S., Shubh-Agrawal, Sandha, S.S., Naidu, S., Hegde, C., LeCun, Y., Goldstein, T., Neiswanger, W., Goldblum, M.: Livebench: A challeng- ing, contamination-limited llm benchmark (2025),https://arxiv.org/abs/2406. 19314
work page 2025
- [21]
-
[22]
Xie, J., Li, Y., Yin, X., Wan, X.: Dsgram: dynamic weighting sub-metrics for grammatical error correction in the era of large language models. In: Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intel- ligence and Fifteenth Symposium on Educational Advances i...
-
[23]
Zadeh, L.: Fuzzy sets. Information and Control8(3), 338–353 (1965). https://doi.org/https://doi.org/10.1016/S0019-9958(65)90241-X, https://www.sciencedirect.com/science/article/pii/S001999586590241X
-
[24]
European Journal of Operational Research116(2), 443–449 (1999)
Zeshui, X., Cuiping, W.: A consistency improving method in the an- alytic hierarchy process1research supported by nsf of china and shan- dong.1. European Journal of Operational Research116(2), 443–449 (1999). https://doi.org/https://doi.org/10.1016/S0377-2217(98)00109-X, https://www.sciencedirect.com/science/article/pii/S037722179800109X Multi-Criteria LL...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.