Recognition: 2 theorem links
· Lean TheoremTesting the Limits of Truth Directions in LLMs
Pith reviewed 2026-05-13 17:06 UTC · model grok-4.3
The pith
Truth directions in LLMs are layer-dependent and shift with task type, difficulty, and instructions rather than being universal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
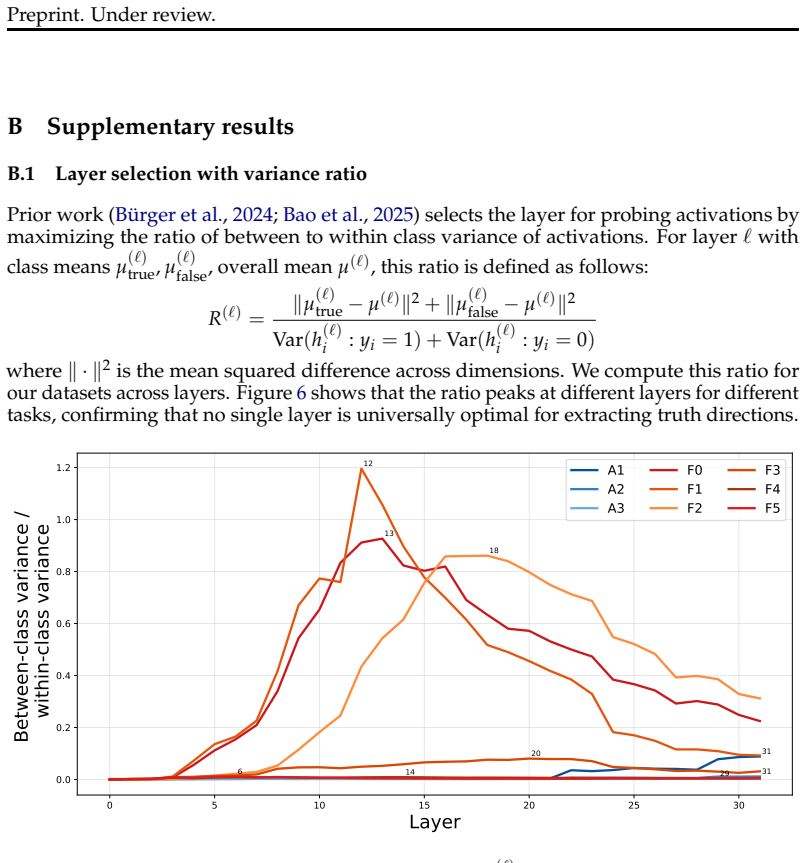
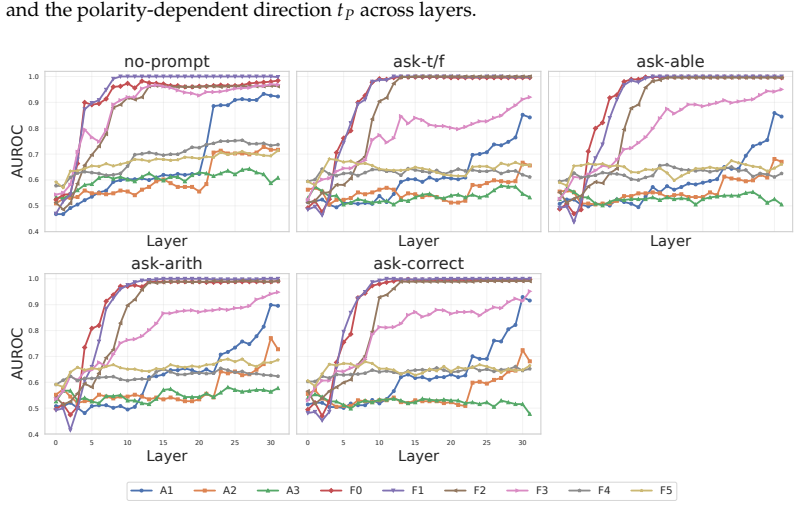
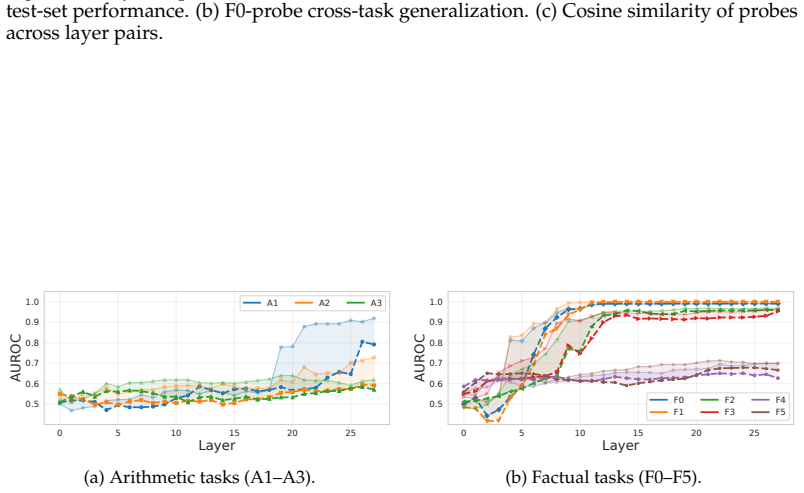
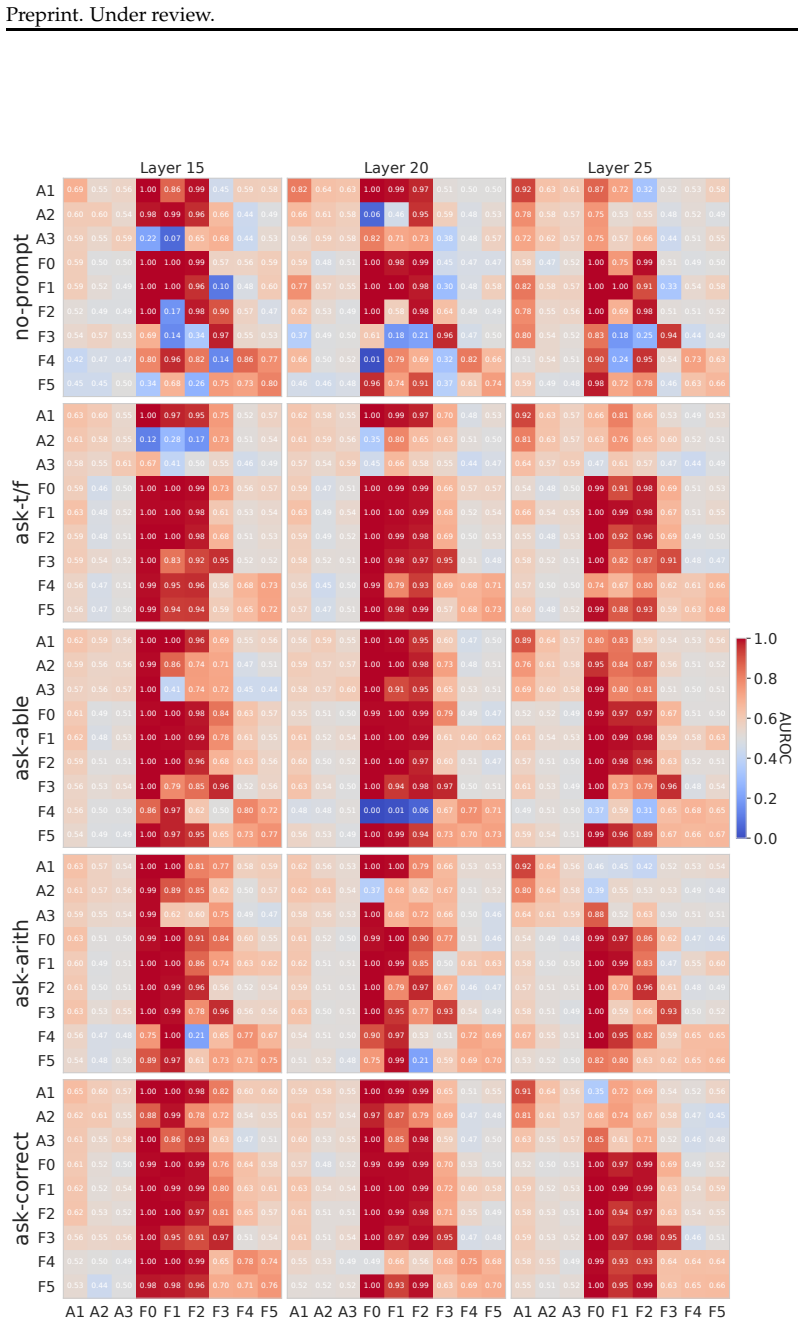
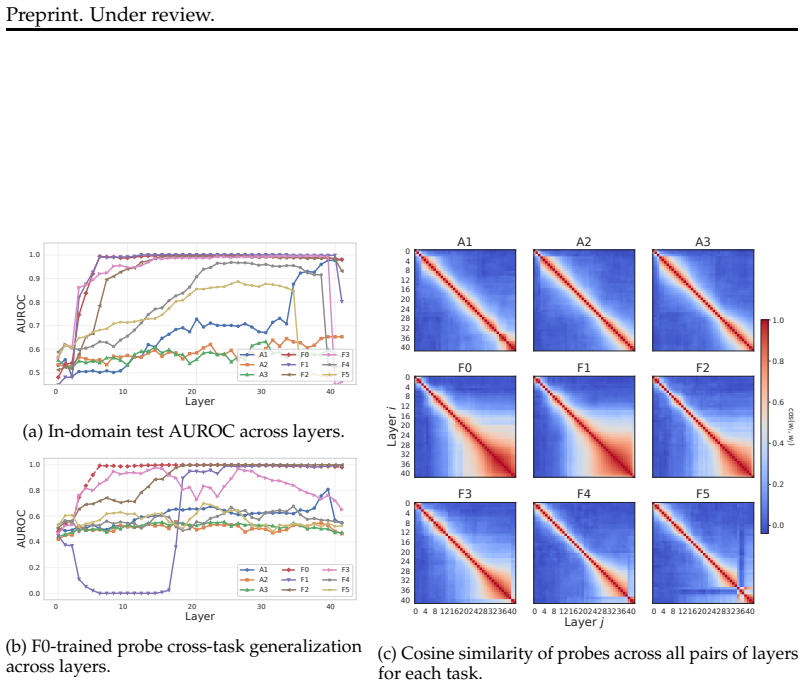
Truth directions extracted by linear probes from LLM activations are highly sensitive to the layer examined, the type of task (factual versus reasoning), the difficulty level of the task, and the exact prompt template supplied to the model. As a result, directions found in one setting often fail to generalize to others, showing that previous universality claims hold only under narrow conditions.
What carries the argument
The linear truth direction identified by probing model activations, which is used to classify statements as true or false.
If this is right
- Understanding truth directions requires probing many layers instead of one or two.
- Factual tasks produce usable directions in earlier layers than reasoning tasks.
- Probe accuracy declines as task complexity increases.
- Changing the model's instructions can reduce how well a truth probe generalizes to new prompts.
Where Pith is reading between the lines
- Truth information may be more entangled with task-specific computations than a single universal direction implies.
- Applications that rely on one fixed direction, such as real-time hallucination detection, may need layer- or task-specific probes.
- Future experiments could test whether averaging directions across several layers yields more stable performance.
Load-bearing premise
That the linear probes isolate a stable representation of truth rather than patterns tied to particular tasks or instructions.
What would settle it
A single direction trained on one layer and factual task that maintains high accuracy when tested on a later layer, a reasoning task, a harder variant, or a different instruction template would contradict the reported limits.
Figures

















read the original abstract
Large language models (LLMs) have been shown to encode truth of statements in their activation space along a linear truth direction. Previous studies have argued that these directions are universal in certain aspects, while more recent work has questioned this conclusion drawing on limited generalization across some settings. In this work, we identify a number of limits of truth-direction universality that have not been previously understood. We first show that truth directions are highly layer-dependent, and that a full understanding of universality requires probing at many layers in the model. We then show that truth directions depend heavily on task type, emerging in earlier layers for factual and later layers for reasoning tasks; they also vary in performance across levels of task complexity. Finally, we show that model instructions dramatically affect truth directions; simple correctness evaluation instructions significantly affect the generalization ability of truth probes. Our findings indicate that universality claims for truth directions are more limited than previously known, with significant differences observable for various model layers, task difficulties, task types, and prompt templates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that truth directions encoded in LLM activation spaces are not universal, demonstrating through experiments that they are highly layer-dependent, emerge at different depths for factual versus reasoning tasks, vary with task difficulty, and are strongly modulated by prompt templates and instructions, thereby limiting prior universality claims.
Significance. If the results hold after addressing probe validity concerns, the work would usefully constrain the scope of linear truth-direction methods in interpretability, encouraging more context-sensitive probing and reducing over-reliance on single-direction assumptions across models and tasks.
major comments (2)
- [Abstract and Experiments] The central claim that truth directions vary by task type and layer (abstract) rests on linear probes recovering stable directions. Without explicit controls such as label randomization, orthogonalization to task embeddings, or fixed-probe cross-task transfer tests, observed differences could reflect probe overfitting to lexical or instruction cues rather than genuine variation in truth encoding.
- [Abstract] The assertion of dramatic effects from model instructions on generalization (abstract) requires quantitative comparison of probe performance with and without instruction variation, including statistical tests for significance and effect sizes; current description leaves unclear whether instruction changes alter the underlying direction or merely the probe's ability to recover it.
minor comments (1)
- [Abstract] The abstract refers to 'various model layers, task difficulties, task types, and prompt templates' without naming the specific models, datasets, or exact metrics (e.g., accuracy, AUC) used to quantify differences.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our claims about the limits of truth-direction universality. We address each major comment below and will incorporate revisions to strengthen the evidence for our findings on layer- and task-dependent variations.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central claim that truth directions vary by task type and layer (abstract) rests on linear probes recovering stable directions. Without explicit controls such as label randomization, orthogonalization to task embeddings, or fixed-probe cross-task transfer tests, observed differences could reflect probe overfitting to lexical or instruction cues rather than genuine variation in truth encoding.
Authors: We agree that explicit controls are needed to rule out probe overfitting to lexical or instruction cues. In the revised manuscript, we will add label randomization experiments across layers and tasks to confirm that probe performance drops to chance when labels are shuffled, supporting that directions capture truth rather than surface features. We will also include fixed-probe cross-task transfer tests (training on factual tasks and testing on reasoning tasks at matched layers) and report results showing limited transfer, consistent with genuine task-type differences. These additions will be detailed in a new subsection on probe validity. revision: yes
-
Referee: [Abstract] The assertion of dramatic effects from model instructions on generalization (abstract) requires quantitative comparison of probe performance with and without instruction variation, including statistical tests for significance and effect sizes; current description leaves unclear whether instruction changes alter the underlying direction or merely the probe's ability to recover it.
Authors: We acknowledge the abstract's description is currently qualitative. In the revision, we will add quantitative comparisons of probe accuracy (and generalization to held-out statements) across instruction variants, including means, standard deviations, and paired t-tests for significance. We will also report effect sizes (Cohen's d) for the performance drops observed with altered instructions. To address whether directions themselves change, we will include cosine similarity measurements between directions recovered under different instructions at the same layers, showing substantial shifts beyond what probe recoverability alone would predict. These results will be summarized in the abstract and expanded in the experiments section. revision: yes
Circularity Check
Empirical probing study exhibits no circular derivation
full rationale
The paper performs direct empirical measurements of linear probe accuracy on LLM hidden states across layers, task types, difficulty levels, and prompt templates. No equations, fitted parameters, or predictions are introduced that reduce to the inputs by construction; results are reported as observed differences in generalization performance rather than derived from self-referential definitions or self-citations. The work tests prior universality claims against new experimental conditions without any load-bearing step that collapses to renaming or refitting the same quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Truth is linearly representable in the activation space of LLMs
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.findings-acl.38 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.