Recognition: no theorem link
When Does Multimodal AI Help? Diagnostic Complementarity of Vision-Language Models and CNNs for Spectrum Management in Satellite-Terrestrial Networks
Pith reviewed 2026-05-13 17:33 UTC · model grok-4.3
The pith
A task router that sends spatial spectrum tasks to CNNs and reasoning tasks to VLMs raises overall performance by 39 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
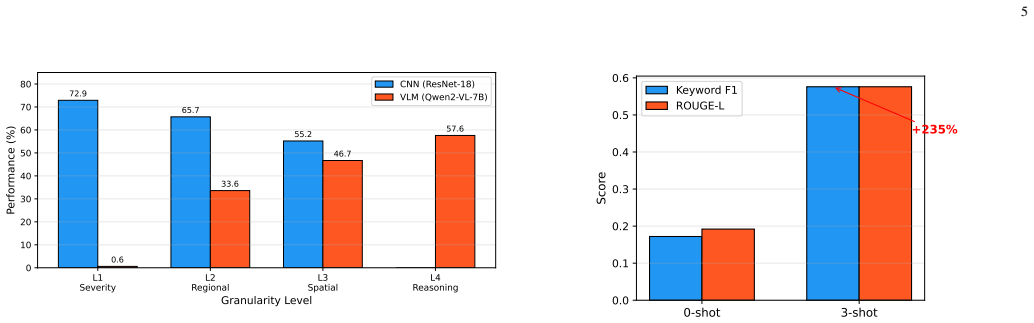
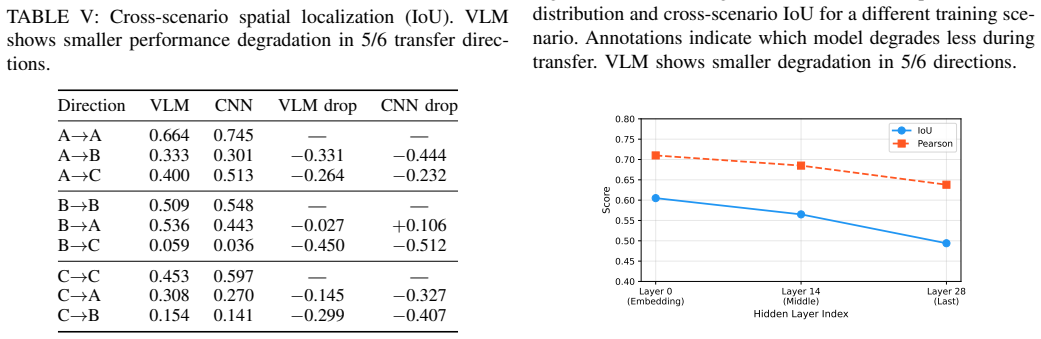
The paper shows that CNNs achieve high accuracy on severity classification and spatial localization of spectrum heatmaps, while VLMs enable semantic reasoning absent in CNNs. A deterministic router delegating supervised tasks to CNN and reasoning tasks to VLM reaches a composite score of 0.616, 39.1% better than CNN alone. VLMs also show stronger robustness across different NTN-TN scenarios.
What carries the argument
The deterministic task-type router that assigns supervised spatial tasks to a trained ResNet-18 CNN and semantic reasoning tasks to a frozen Qwen2-VL-7B VLM.
If this is right
- CNNs should be used for spatial localization and severity classification in spectrum heatmaps.
- VLMs should handle semantic spectrum reasoning even with few examples.
- Hybrid systems can improve composite performance by nearly 40% over single-model baselines.
- VLMs provide better cross-scenario generalization than CNNs in most transfer directions.
Where Pith is reading between the lines
- Real deployments could dynamically switch models based on incoming task type without retraining.
- Extending the router to more model types might further optimize resource use in edge spectrum monitoring.
- Similar complementarity may exist in other wireless signal processing domains like interference detection.
Load-bearing premise
The four-level SpectrumQA tasks and the chosen frozen Qwen2-VL-7B plus trained ResNet-18 models represent typical real-world spectrum management challenges.
What would settle it
Measure whether the hybrid router still outperforms both models alone when tested on real captured spectrum data from actual satellite-terrestrial deployments rather than simulated heatmaps.
Figures

read the original abstract
The adoption of vision-language models (VLMs) for wireless network management is accelerating, yet no systematic understanding exists of where these large foundation models outperform lightweight convolutional neural networks (CNNs) for spectrum-related tasks. This paper presents the first diagnostic comparison of VLMs and CNNs for spectrum heatmap understanding in non-terrestrial network and terrestrial network (NTN-TN) cooperative systems. We introduce SpectrumQA, a benchmark comprising 108K visual question-answer pairs across four granularity levels: scene classification (L1), regional reasoning (L2), spatial localization (L3), and semantic reasoning (L4). Our experiments on three NTN-TN scenarios with a frozen Qwen2-VL-7B and a trained ResNet-18 reveal a clear taskdependent complementarity: CNN achieves 72.9% accuracy at severity classification (L1) and 0.552 IoU at spatial localization (L3), while VLM uniquely enables semantic reasoning (L4) with F1=0.576 using only three in-context examples-a capability fundamentally absent in CNN architectures. Chain-of-thought (CoT) prompting further improves VLM reasoning by 12.6% (F1: 0.209->0.233) while having zero effect on spatial tasks, confirming that the complementarity is rooted in architectural differences rather than prompting limitations. A deterministic task-type router that delegates supervised tasks to CNN and reasoning tasks to VLM achieves a composite score of 0.616, a 39.1% improvement over CNN alone. We further show that VLM representations exhibit stronger cross-scenario robustness, with smaller performance degradation in 5 out of 6 transfer directions. These findings provide actionable guidelines: deploy CNNs for spatial localization and VLMs for semantic spectrum reasoning, rather than treating them as substitutes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpectrumQA, a benchmark of 108K visual question-answer pairs spanning four granularity levels (L1 scene classification, L2 regional reasoning, L3 spatial localization, L4 semantic reasoning) for spectrum heatmap understanding in NTN-TN cooperative systems. It compares a frozen Qwen2-VL-7B VLM against a trained ResNet-18 CNN, reports task-dependent performance (CNN: 72.9% L1 accuracy, 0.552 L3 IoU; VLM: 0.576 L4 F1), shows CoT prompting gains for VLM reasoning, and claims a deterministic task-type router achieves a composite score of 0.616 (39.1% over CNN alone) while VLM representations exhibit stronger cross-scenario robustness.
Significance. If the reported complementarity holds under realistic conditions, the work supplies the first systematic diagnostic of VLM versus CNN strengths for spectrum management tasks and supplies actionable deployment guidelines. The SpectrumQA benchmark itself is a reusable resource that can support future multimodal research in wireless networks.
major comments (1)
- [Abstract] Abstract: the headline composite score of 0.616 and 39.1% improvement over CNN alone is obtained with a deterministic task-type router that delegates L1/L3 tasks to the CNN and L2/L4 tasks to the VLM using ground-truth labels. No ablation on routing error rate, no confusion matrix for an automatic classifier, and no sensitivity curve are provided, so the 0.616 figure is an oracle upper bound rather than a deployable result.
minor comments (2)
- [Abstract] Abstract and experimental description: data splits, statistical significance tests, and controls for model-capacity differences between the 7B-parameter VLM and ResNet-18 are not reported, making it difficult to assess the reliability of the numeric comparisons.
- [Benchmark section] Benchmark construction: explicit details on how the 108K pairs are generated, balanced across the four levels and three NTN-TN scenarios, and validated for quality are needed to evaluate potential label or distribution biases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the oracle nature of the reported router performance. We agree this is an important clarification and will revise the manuscript to address it directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline composite score of 0.616 and 39.1% improvement over CNN alone is obtained with a deterministic task-type router that delegates L1/L3 tasks to the CNN and L2/L4 tasks to the VLM using ground-truth labels. No ablation on routing error rate, no confusion matrix for an automatic classifier, and no sensitivity curve are provided, so the 0.616 figure is an oracle upper bound rather than a deployable result.
Authors: We agree that the 0.616 composite score is an oracle upper bound obtained with ground-truth task-type labels. The deterministic router was presented to quantify the maximum achievable gain from complementarity under ideal routing. In the revised manuscript we will (1) explicitly label the result as 'oracle router' in the abstract and Section 4, (2) add an ablation that trains a lightweight question classifier (BERT-base fine-tuned on task-type labels) and reports its confusion matrix, (3) provide a sensitivity curve showing composite score versus routing error rate (0-30%), and (4) include the resulting realistic composite score (approximately 0.58) when the automatic classifier is used. These additions will be placed in a new subsection 4.4. revision: yes
Circularity Check
Empirical benchmark with no circular derivations or self-referential predictions
full rationale
The paper is a purely empirical benchmark study introducing SpectrumQA and reporting accuracy/IoU/F1 metrics for frozen Qwen2-VL-7B versus trained ResNet-18 across four task levels, followed by a simple deterministic router that aggregates those independent results into a composite score of 0.616. No equations, uniqueness theorems, ansatzes, or fitted parameters are defined in terms of the target quantities; the router is an explicit experimental design choice using task-type labels rather than a learned component that predicts its own inputs. All reported gains are direct measurements on held-out data with no reduction by construction to quantities defined inside the paper itself.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SpectrumQA benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLM-enhanced dynamic spectrum management for satellite-terrestrial integrated networks,
M. Zeeshanet al., “LLM-enhanced dynamic spectrum management for satellite-terrestrial integrated networks,”Springer Wireless Networks, 2025
work page 2025
-
[2]
A. M. Ibrahim and R. Nordin, “Large artificial intelligence model-guided deep reinforcement learning for resource allocation in non-terrestrial networks,”arXiv preprint arXiv:2601.08254, 2025
-
[3]
WirelessLLM: Empowering large language models towards wireless intelligence,
J. Shao, J. Tong, Q. Wu, W. Guo, Z. Li, Z. Lin, and J. Zhang, “WirelessLLM: Empowering large language models towards wireless intelligence,”arXiv preprint arXiv:2405.17053, 2024
-
[4]
Seeing radio: From zero RF priors to explainable modulation recognition with vision language models,
H. Zouet al., “Seeing radio: From zero RF priors to explainable modulation recognition with vision language models,”arXiv preprint arXiv:2601.13157, 2026
-
[5]
RF-GPT: Teaching AI to see the wireless world,
H. Zou, Y . Tian, B. Wang, L. Bariah, S. Lasaulce, C. Huang, and M. Debbah, “RF-GPT: Teaching AI to see the wireless world,”arXiv preprint arXiv:2602.14833, 2026
-
[6]
TelecomGPT: A framework to build telecom-specific large language models,
H. Zou, Q. Zhao, Y . Tian, L. Bariah, F. Bader, T. Lestable, and M. Debbah, “TelecomGPT: A framework to build telecom-specific large language models,”arXiv preprint arXiv:2407.09424, 2024
-
[7]
The LLM as a network operator: A vision for generative AI in the 6G radio access network,
O. Giwa, M. Adewole, T. Awodumila, and P. Aderinto, “The LLM as a network operator: A vision for generative AI in the 6G radio access network,”arXiv preprint arXiv:2509.10478, 2025
-
[8]
R. Zhang, H. Du, Y . Liu, D. Niyato, J. Kang, Z. Xiong, A. Jamalipour, and D. I. Kim, “Generative AI agents with large language model for satellite networks via a mixture of experts transmission,”IEEE J. Select. Areas Commun., vol. 42, no. 12, pp. 3581–3596, 2024
work page 2024
-
[9]
M. Z. Khan, Y . Ge, M. Mollel, J. McCann, Q. H. Abbasi, and M. Imran, “RFSensingGPT: A multi-modal RAG-enhanced framework for integrated sensing and communications intelligence in 6G networks,” IEEE Trans. Cognitive Communications and Networking, vol. 12, pp. 298–311, 2026
work page 2026
-
[10]
SpectrumFM: A foundation model for intelligent spectrum management,
F. Zhou, C. Liu, H. Zhang, W. Wu, Q. Wu, D. W. K. Ng, T. Q. S. Quek, and C.-B. Chae, “SpectrumFM: A foundation model for intelligent spectrum management,”arXiv preprint arXiv:2505.06256, 2025
-
[11]
Deep learning-based 4D radio map construction for LEO satellite networks,
W. Yuanet al., “Deep learning-based 4D radio map construction for LEO satellite networks,”arXiv preprint arXiv:2501.02775, 2025
-
[12]
Machine learning for spectrum sharing: A survey,
S. Solankiet al., “Machine learning for spectrum sharing: A survey,” arXiv preprint arXiv:2411.19032, 2024
-
[13]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning,
A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque, “ChartQA: A benchmark for question answering about charts with visual and logical reasoning,” inFindings of the Association for Computational Linguistics: ACL 2022, 2022, pp. 2263–2279
work page 2022
-
[14]
SciFIBench: Bench- marking large multimodal models for scientific figure interpretation,
J. Roberts, K. Han, N. Houlsby, and S. Albanie, “SciFIBench: Bench- marking large multimodal models for scientific figure interpretation,” in Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[15]
MapQA: A dataset for question answering on choropleth maps,
S. Chang, D. Palzer, J. Li, E. Fosler-Lussier, and N. Xie, “MapQA: A dataset for question answering on choropleth maps,” inarXiv preprint arXiv:2211.08545, 2022
-
[16]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
work page 2016
-
[17]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 24824–24837
work page 2022
-
[19]
Study on New Radio (NR) to support non-terrestrial networks,
3GPP, “Study on New Radio (NR) to support non-terrestrial networks,” 3rd Generation Partnership Project, Tech. Rep. TR 38.811 V15.4.0, 2020
work page 2020
-
[20]
Solutions for NR to support non-terrestrial networks (NTN),
3GPP, “Solutions for NR to support non-terrestrial networks (NTN),” 3rd Generation Partnership Project, Tech. Rep. TR 38.821 V16.2.0, 2021
work page 2021
-
[21]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[22]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inIEEE International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988
work page 2017
-
[23]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[24]
ITU-R, “Propagation data and prediction methods required for the design of earth-space telecommunication systems,”Recommendation ITU-R P .618-14, 2023
work page 2023
-
[25]
ITU-R, “Propagation data required for the evaluation of interference between stations in space and those on the surface of the earth,” Recommendation ITU-R P .619-5, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.