Recognition: no theorem link
Decomposing Communication Gain and Delay Cost Under Cross-Timestep Delays in Cooperative Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-13 16:59 UTC · model grok-4.3
The pith
In cooperative multi-agent RL with cross-timestep communication delays, messages can be decomposed into communication gain and delay cost so agents request them only when the net value is positive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the DeComm-POMG setting, a message's effect decomposes into communication gain and delay cost; the resulting value-loss is provably bounded by a discounted sum of the information gap between the action distributions induced by timely messages and those induced by delayed ones. An actor-critic algorithm that requests messages only when predicted CGDC is positive, predicts future observations to reduce misalignment, and fuses messages with CGDC-guided attention recovers most of the lost performance.
What carries the argument
The CGDC metric that subtracts delay cost from communication gain for each message, together with the CDCMA actor-critic that conditions message requests and attention fusion on predicted positive CGDC.
If this is right
- Agents transmit fewer messages while preserving coordination because requests occur only when CGDC exceeds zero.
- The value-loss bound supplies a quantitative certificate that delayed communication cannot degrade return beyond a known discounted gap.
- Predicting future observations and using CGDC-guided attention become necessary components for any method that consumes cross-timestep messages.
- Performance remains stable across multiple discrete delay levels once the decomposition and prediction modules are present.
Where Pith is reading between the lines
- The same gain-cost split could be applied to single-agent settings with delayed observations or to non-cooperative games where agents must decide whether to share private information.
- Real-world multi-robot teams could adopt the CGDC threshold as an explicit energy or bandwidth budget, turning the metric into a direct resource allocator.
- If the information-gap term in the bound can be estimated from experience alone, the method might extend to continuous delay distributions without requiring a fixed discrete schedule.
Load-bearing premise
Future observations can be predicted accurately enough to realign delayed messages at consumption time and that the CGDC value itself can be estimated without introducing new errors that outweigh the communication benefit.
What would settle it
A controlled trial in which the observation predictor is replaced by a deliberately inaccurate model and the resulting policy performs measurably worse than a no-communication baseline under the same delay schedule.
Figures







read the original abstract
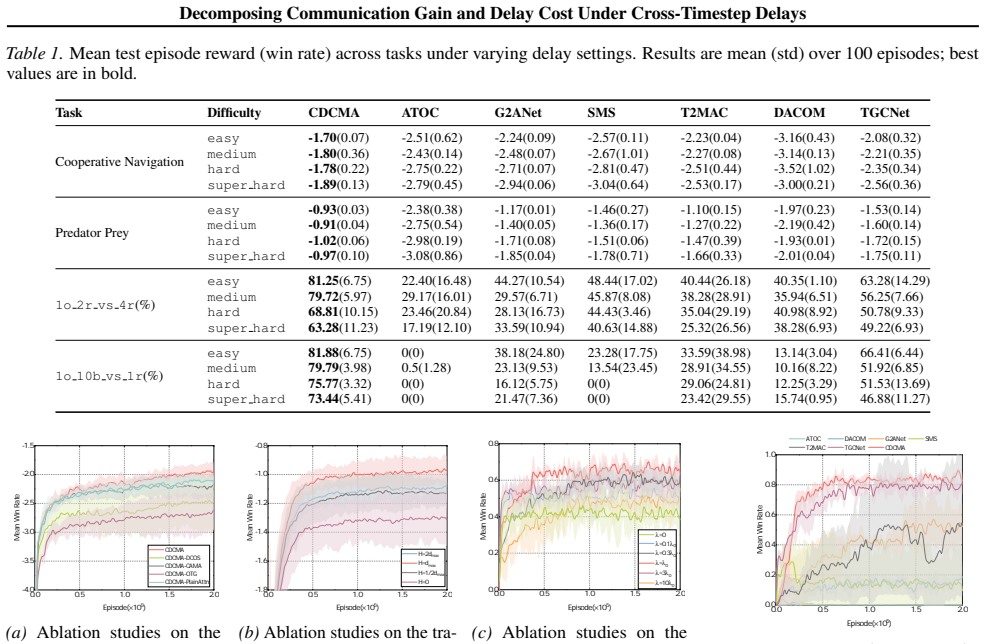
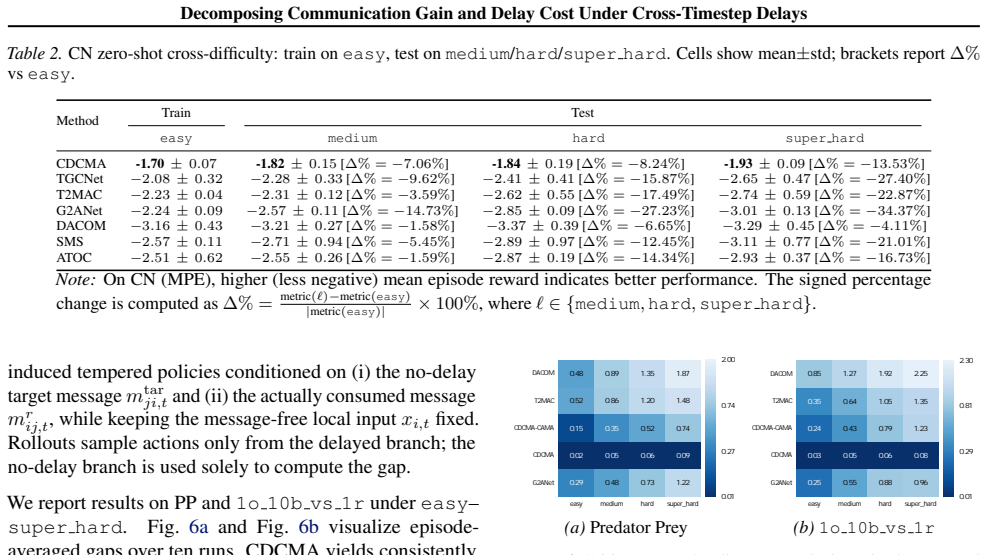
Communication is essential for coordination in \emph{cooperative} multi-agent reinforcement learning under partial observability, yet \emph{cross-timestep} delays cause messages to arrive multiple timesteps after generation, inducing temporal misalignment and making information stale when consumed. We formalize this setting as a delayed-communication partially observable Markov game (DeComm-POMG) and decompose a message's effect into \emph{communication gain} and \emph{delay cost}, yielding the Communication Gain and Delay Cost (CGDC) metric. We further establish a value-loss bound showing that the degradation induced by delayed messages is upper-bounded by a discounted accumulation of an information gap between the action distributions induced by timely versus delayed messages. Guided by CGDC, we propose \textbf{CDCMA}, an actor--critic framework that requests messages only when predicted CGDC is positive, predicts future observations to reduce misalignment at consumption, and fuses delayed messages via CGDC-guided attention. Experiments on no-teammate-vision variants of Cooperative Navigation and Predator Prey, and on SMAC maps across multiple delay levels show consistent improvements in performance, robustness, and generalization, with ablations validating each component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address cross-timestep delays in cooperative multi-agent reinforcement learning by formalizing the setting as DeComm-POMG, introducing the CGDC metric to decompose communication effects into gain and delay cost, establishing a value-loss bound showing degradation upper-bounded by a discounted accumulation of the information gap between timely and delayed action distributions, and proposing the CDCMA actor-critic framework that requests messages only when predicted CGDC is positive, predicts future observations to reduce misalignment, and fuses delayed messages via CGDC-guided attention. Experiments on no-teammate-vision variants of Cooperative Navigation and Predator Prey plus SMAC maps across delay levels report consistent performance, robustness, and generalization improvements, with ablations validating components.
Significance. If the value-loss bound derivation is sound and the empirical gains are reproducible with proper controls, the work offers a principled decomposition and practical method for mitigating temporal misalignment in delayed MARL communication. The formalization of DeComm-POMG and the CGDC-guided prediction mechanism provide a concrete way to quantify when communication is beneficial under delays, which could influence future algorithm design in partially observable cooperative settings. The multi-environment evaluation across delay levels is a positive aspect.
major comments (2)
- [Value-loss bound] Value-loss bound section: The central claim that degradation is upper-bounded by a discounted accumulation of the information gap between timely versus delayed action distributions is load-bearing, yet the derivation steps are not visible and the bound implicitly requires the future-observation predictor to keep the induced action distributions sufficiently close to the timely case; no analysis shows the bound remains valid when predictor error exceeds a threshold.
- [Experiments] Experimental evaluation: The reported consistent gains and ablations validating each component (prediction, CGDC gating, attention) are central to supporting the framework, but the lack of baseline details, statistical significance tests, and precise description of how delay levels were controlled prevents verification of the data-to-claim link.
minor comments (2)
- [Abstract] Abstract: The phrase 'no-teammate-vision variants' should be briefly defined or referenced to a standard environment description for clarity.
- [Notation] Notation: Ensure DeComm-POMG, CGDC, and CDCMA are introduced with explicit definitions before first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Value-loss bound] Value-loss bound section: The central claim that degradation is upper-bounded by a discounted accumulation of the information gap between timely versus delayed action distributions is load-bearing, yet the derivation steps are not visible and the bound implicitly requires the future-observation predictor to keep the induced action distributions sufficiently close to the timely case; no analysis shows the bound remains valid when predictor error exceeds a threshold.
Authors: We agree the derivation steps should be more visible. In the revision we will expand the main-text presentation of the value-loss bound (currently summarized in Section 4.2) to include the full sequence of inequalities, starting from the total-variation distance between timely and delayed action distributions, through the application of the Bellman operator, and arriving at the discounted accumulation. The bound itself is stated for the actual induced distributions after any prediction step; it therefore holds for any predictor quality, with larger predictor error simply widening the information gap term. To address the referee’s concern directly we will add a short subsection that (i) makes this dependence explicit and (ii) supplies a sufficient condition on predictor error (in terms of total-variation distance) under which the bound remains non-vacuous, together with a brief empirical check on the navigation domain. revision: yes
-
Referee: [Experiments] Experimental evaluation: The reported consistent gains and ablations validating each component (prediction, CGDC gating, attention) are central to supporting the framework, but the lack of baseline details, statistical significance tests, and precise description of how delay levels were controlled prevents verification of the data-to-claim link.
Authors: We will revise the experimental section to supply the missing information. Specifically: (1) we will list every baseline together with its network architecture, optimizer settings, and hyper-parameter values; (2) we will report paired t-test p-values (or Wilcoxon signed-rank where appropriate) for all performance comparisons and include them in the result tables; (3) we will add an explicit paragraph describing the delay model—delays are drawn independently for each message from a uniform distribution over {1, …, D} and applied at the receiver’s buffer. These additions will allow direct reproduction and verification of the reported gains and ablations. revision: yes
Circularity Check
No significant circularity; new formalisms and bound are introduced independently
full rationale
The paper defines DeComm-POMG as a new formalization of the delayed-communication POMG setting and introduces CGDC as a decomposition of message effects into gain and cost components. The value-loss bound is then stated in terms of a discounted accumulation of the information gap between timely and delayed action distributions. These steps rely on the paper's own definitions and standard information-theoretic or RL bounding techniques rather than reducing by construction to fitted parameters, prior self-citations, or renamed known results. The CDCMA framework applies the new metric and bound for decision-making and attention, but the derivation chain does not exhibit self-definitional loops or load-bearing self-citations that force the central claims. The analysis remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The environment can be modeled as a delayed-communication partially observable Markov game.
invented entities (2)
-
DeComm-POMG
no independent evidence
-
CGDC metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Guan, C., Chen, F., Yuan, L., Wang, C., Yin, H., Zhang, Z., and Yu, Y
doi: 10.1109/TSMC.2025.3604230. Guan, C., Chen, F., Yuan, L., Wang, C., Yin, H., Zhang, Z., and Yu, Y . Efficient multi-agent communication via self-supervised information aggregation. InAdvances in Neural Information Processing Systems, volume 35, pp. 1020–1033,
- [2]
-
[3]
URL https:// arxiv.org/abs/1703.10069. arXiv:1703.10069. Pu, Z., Wang, H., Liu, Z., Yi, J., and Wu, S. Atten- tion enhanced reinforcement learning for multi agent cooperation.IEEE Transactions on Neural Networks and Learning Systems, 34(11):8235–8249,
-
[4]
Samvelyan, M., Rashid, T., Schroeder de Witt, C., Farquhar, G., Nardelli, N., Rudner, T
doi: 10.1109/TNNLS.2021.3116128. Samvelyan, M., Rashid, T., Schroeder de Witt, C., Farquhar, G., Nardelli, N., Rudner, T. G. J., Hung, C.-M., Torr, P. H. S., Foerster, J., and Whiteson, S. The StarCraft multi- agent challenge. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Sys- tems, pp. 2186–2188,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.