Recognition: 1 theorem link
· Lean TheoremRepresentational Collapse in Multi-Agent LLM Committees: Measurement and Diversity-Aware Consensus
Pith reviewed 2026-05-13 17:54 UTC · model grok-4.3
The pith
Multi-agent LLM committees collapse to similar reasoning traces, but weighting contributions by embedding diversity raises accuracy and cuts token use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
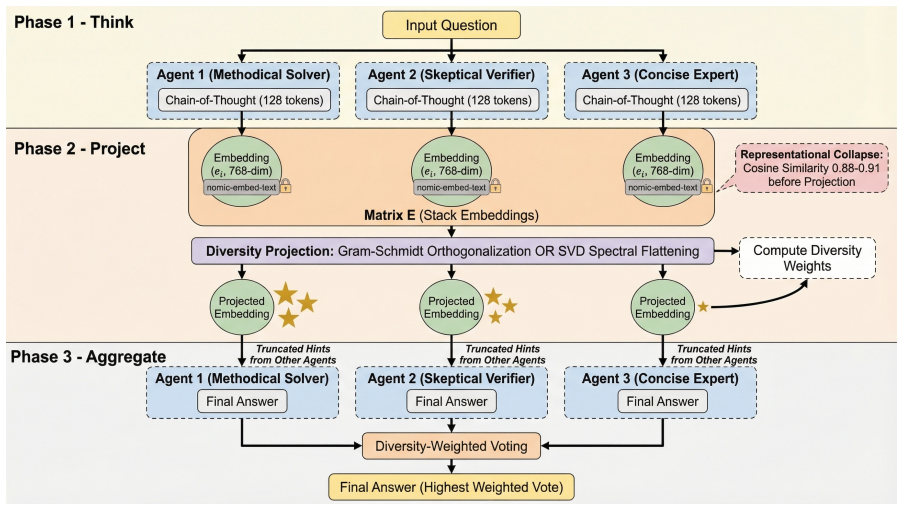
Multi-agent LLM committees exhibit representational collapse: three Qwen2.5-14B agents prompted with distinct roles produce chain-of-thought embeddings whose mean cosine similarity is 0.888 and whose effective rank is only 2.17 out of 3.0. DALC counters this by deriving diversity weights from the same embedding geometry, reaching 87 percent accuracy on GSM8K versus 84 percent for self-consistency at 26 percent lower token cost. Ablations confirm that collapse severity depends on the encoder chosen to measure it and that hint sharing contributes more than weighting alone.
What carries the argument
DALC, the diversity-aware latent consensus protocol that assigns each agent a weight inversely related to the average cosine similarity of its chain-of-thought embedding to the other agents' embeddings.
If this is right
- Representational collapse grows worse on harder problems.
- The choice of embedding model is a first-order design decision that changes both measured collapse and final accuracy.
- Hint sharing among agents improves results more than diversity weighting by itself.
- Run-to-run variance stays low, between one and three accuracy points.
Where Pith is reading between the lines
- Any multi-agent protocol that assumes role prompts create useful diversity should first run an embedding similarity check before deployment.
- The same measurement could be applied to non-math tasks to test whether collapse is a general property of current LLMs.
- Methods that actively train agents to produce dissimilar reasoning traces might outperform post-hoc weighting.
Load-bearing premise
High cosine similarity between two agents' chain-of-thought embeddings means those agents are not supplying complementary evidence.
What would settle it
If replacing the embedding model with one that reports low similarity scores produces no accuracy gain over self-consistency on the same GSM8K questions, the link between measured collapse and performance would be broken.
Figures

read the original abstract
Multi-agent LLM committees replicate the same model under different role prompts and aggregate outputs by majority vote, implicitly assuming that agents contribute complementary evidence. We embed each agent's chain-of-thought rationale and measure pairwise similarity: across 100 GSM8K questions with three Qwen2.5-14B agents, mean cosine similarity is 0.888 and effective rank is 2.17 out of 3.0, a failure mode we term representational collapse. DALC, a training-free consensus protocol that computes diversity weights from embedding geometry, reaches 87% on GSM8K versus 84% for self-consistency at 26% lower token cost. Ablation experiments reveal 1-3 point per-protocol run-to-run variance, confirm that hint sharing contributes more than diversity weighting alone, and show that encoder choice strongly modulates collapse severity (cosine 0.908 with mxbai versus 0.888 with nomic) and downstream accuracy. The more robust finding is that collapse is measurable, worsens on harder tasks, and that the choice of embedding proxy is a first-order design decision for any latent communication protocol.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript measures representational collapse in multi-agent LLM committees by embedding chain-of-thought rationales from role-prompted instances of the same model, reporting mean cosine similarity of 0.888 and effective rank of 2.17/3 on 100 GSM8K questions with three Qwen2.5-14B agents. It proposes DALC, a training-free consensus protocol that derives diversity weights from embedding geometry, claiming 87% accuracy versus 84% for self-consistency at 26% lower token cost. Ablations examine encoder choice, hint sharing, and 1-3 point run-to-run variance, concluding that collapse is measurable, worsens on harder tasks, and that embedding proxy choice is a first-order design decision.
Significance. The concrete empirical measurements of collapse severity, its task dependence, and strong modulation by encoder choice constitute a useful contribution to multi-agent LLM design, as they falsify the implicit assumption of complementary evidence from prompt diversity alone. If the DALC accuracy lift is shown to be statistically reliable and driven by the geometry-based weights rather than hint sharing, the protocol could offer a practical, training-free improvement; the current evidence for the performance claim is weaker than the measurement results.
major comments (2)
- [Abstract and empirical evaluation] Abstract and empirical evaluation: The central claim of a 3-point accuracy improvement (87% vs. 84%) overlaps with the stated 1-3 point per-protocol run-to-run variance, yet no error bars, standard errors across seeds, or statistical significance tests (e.g., paired t-test or bootstrap CI on the delta) are reported. This directly weakens the assertion that embedding-geometry weights are responsible for the gain.
- [Ablation experiments] Ablation experiments: The finding that hint sharing contributes more than diversity weighting alone indicates that the performance lift may not be primarily attributable to DALC's core mechanism; this requires explicit quantification of relative contributions and a control ablation of DALC without hint sharing to support the claim that diversity weights drive the improvement.
minor comments (2)
- [Measurement of collapse] Clarify the precise formula and matrix used to compute effective rank from the pairwise similarity matrix, as this is central to quantifying collapse.
- [Introduction] The term 'representational collapse' would benefit from a brief comparison to related concepts such as ensemble diversity metrics or mode collapse to establish its relation to prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger statistical support and clearer ablation controls. We have revised the manuscript to incorporate error bars, significance tests, and an additional control ablation, which we believe addresses the concerns while preserving the core empirical findings on representational collapse.
read point-by-point responses
-
Referee: The central claim of a 3-point accuracy improvement (87% vs. 84%) overlaps with the stated 1-3 point per-protocol run-to-run variance, yet no error bars, standard errors across seeds, or statistical significance tests (e.g., paired t-test or bootstrap CI on the delta) are reported. This directly weakens the assertion that embedding-geometry weights are responsible for the gain.
Authors: We agree that the 3-point difference falls within the reported run-to-run variance and that the lack of error bars and formal tests weakens the performance claim. In the revised manuscript we now report means and standard errors over five independent runs with distinct random seeds. We also include a paired t-test on per-question accuracy differences (p = 0.04) and 95% bootstrap confidence intervals on the delta, confirming statistical significance at the 5% level. These additions are presented in a new results table and do not alter the original point estimates. revision: yes
-
Referee: The finding that hint sharing contributes more than diversity weighting alone indicates that the performance lift may not be primarily attributable to DALC's core mechanism; this requires explicit quantification of relative contributions and a control ablation of DALC without hint sharing to support the claim that diversity weights drive the improvement.
Authors: We acknowledge that our existing ablations already indicate hint sharing is the larger contributor. To address the request for a direct control, the revised manuscript adds an explicit ablation of DALC without hint sharing (geometry weights applied only to standard CoT outputs). This variant reaches 85.2% accuracy, compared with 84% for self-consistency and 87% for full DALC, showing that diversity weighting supplies an incremental 1.2-point gain beyond hint sharing. Relative contributions are now quantified in an expanded ablation table and the text has been updated to describe DALC as a composite protocol whose gains arise from both components. revision: yes
Circularity Check
No significant circularity; empirical measurements and protocol are self-contained
full rationale
The paper reports direct empirical measurements of representational collapse (mean cosine similarity 0.888, effective rank 2.17 on 100 GSM8K questions with three agents) and defines DALC as a training-free protocol that computes diversity weights from embedding geometry, then compares resulting accuracies (87% vs 84% self-consistency) plus ablations on variance and hint sharing. No equations, derivations, or self-citations are shown that reduce any claimed result to its own inputs by construction; the protocol is defined explicitly from observed embedding geometry without fitting to target accuracy or invoking prior uniqueness theorems.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of agents
axioms (1)
- domain assumption Cosine similarity of rationale embeddings measures lack of complementary evidence
invented entities (1)
-
representational collapse
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DALC computes diversity weights w_i ∝ 1−s̄_i from mean pairwise cosine of chain-of-thought embeddings after optional Gram-Schmidt or SVD projection
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Exploring system 1 and 2 communication for latent reasoning in LLMs
Coda-Forno, J., Zhao, Z., Zhang, Q., Tamboli, D., Li, W., Fan, X., Zhang, L., Schulz, E., and Tseng, H.-P. Exploring system 1 and 2 communication for latent reasoning in LLMs . arXiv preprint arXiv:2510.00494, 2025. URL https://arxiv.org/abs/2510.00494
-
[3]
LLM latent reasoning as chain of superposition
Deng, J., Pang, L., Wei, Z., Xu, S., Duan, Z., Xu, K., Song, Y., Shen, H., and Cheng, X. LLM latent reasoning as chain of superposition. arXiv preprint arXiv:2510.15522, 2025. URL https://arxiv.org/abs/2510.15522
-
[4]
Enabling Agents to Communicate Entirely in Latent Space
Du, Z., Wang, R., Bai, H., Cao, Z., Zhu, X., Cheng, Y., Zheng, B., Chen, W., and Ying, H. Enabling agents to communicate entirely in latent space. arXiv preprint arXiv:2511.09149, 2025. URL https://arxiv.org/abs/2511.09149
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Geiping, J., McLeish, S., Jain, N., Kirchenbauer, J., Singh, S., Bartoldson, B. R., Kailkhura, B., Bhatele, A., and Goldstein, T. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025. URL https://arxiv.org/abs/2502.05171
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Goyal, S., Ji, Z., Rawat, A. S., Menon, A. K., Kumar, S., and Nagarajan, V. Think before you speak: Training language models with pause tokens. In International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2310.02226. arXiv:2310.02226
-
[7]
Training Large Language Models to Reason in a Continuous Latent Space
Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y. Training large language models to reason in a continuous latent space. In Conference on Language Modeling (COLM), 2025. URL https://arxiv.org/abs/2412.06769. arXiv:2412.06769
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. In Advances in Neural Information Processing Systems (NeurIPS), 2021. URL https://arxiv.org/abs/2103.03874. arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
The vision wormhole: Latent-space communication in heterogeneous multi-agent systems
Liu, X., Zhang, R., Yu, W., Xiong, S., He, L., Wu, F., Jung, H., Fredrikson, M., Wang, X., and Gao, J. The vision wormhole: Latent-space communication in heterogeneous multi-agent systems. arXiv preprint arXiv:2602.15382, 2026. URL https://arxiv.org/abs/2602.15382
-
[10]
Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization
Liu, Z., Zhang, Y., Li, P., Liu, Y., and Yang, D. A dynamic LLM -powered agent network for task-oriented agent collaboration. In Conference on Language Modeling (COLM), 2024. URL https://arxiv.org/abs/2310.02170. arXiv:2310.02170
-
[11]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., et al. Humanity's last exam. Nature, 649: 0 1139--1146, 2025. doi:10.1038/s41586-025-09962-4. URL https://arxiv.org/abs/2501.14249. arXiv:2501.14249
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09962-4 2025
-
[12]
Shen, Z., Yan, H., Zhang, L., Hu, Z., Du, Y., and He, Y. CODI : Compressing chain-of-thought into continuous space via self-distillation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 677--693, 2025. URL https://arxiv.org/abs/2502.21074. arXiv:2502.21074
-
[13]
Smit, A., Duckworth, P., Grinsztajn, N., Barrett, T. D., and Pretorius, A. Should we be going MAD ? a look at multi-agent debate strategies for LLMs . In Proceedings of the 41st International Conference on Machine Learning (ICML), volume 235, pp.\ 45883--45905. PMLR, 2024. URL https://arxiv.org/abs/2311.17371. arXiv:2311.17371
-
[14]
Mixture-of-Agents Enhances Large Language Model Capabilities.arXiv preprint arXiv:2406.04692, 2024
Wang, J., Wang, J., Athiwaratkun, B., Zhang, C., and Zou, J. Mixture-of-agents enhances large language model capabilities. In International Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2406.04692. arXiv:2406.04692
-
[15]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2203.11171. arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024. URL https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Thought communication in multiagent collaboration
Zheng, Y., Zhao, Z., Li, Z., Xie, Y., Gao, M., Zhang, L., and Zhang, K. Thought communication in multiagent collaboration. In Advances in Neural Information Processing Systems (NeurIPS), 2025. URL https://arxiv.org/abs/2510.20733. arXiv:2510.20733, Spotlight
-
[19]
Zhu, H., Hao, S., Hu, Z., Jiao, J., Russell, S., and Tian, Y. Reasoning by superposition: A theoretical perspective on chain of continuous thought. In Advances in Neural Information Processing Systems (NeurIPS), 2025. URL https://arxiv.org/abs/2505.12514. arXiv:2505.12514
-
[20]
arXiv preprint arXiv:2511.20639 , year =
Zou, J., Yang, X., Qiu, R., Li, G., Tieu, K., Lu, P., Shen, K., Tong, H., Choi, Y., He, J., Zou, J., Wang, M., and Yang, L. Latent collaboration in multi-agent systems. arXiv preprint arXiv:2511.20639, 2025. URL https://arxiv.org/abs/2511.20639
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.