Recognition: 2 theorem links
· Lean TheoremInCaRPose: In-Cabin Relative Camera Pose Estimation Model and Dataset
Pith reviewed 2026-05-13 17:07 UTC · model grok-4.3
The pith
InCaRPose estimates absolute metric-scale relative poses for in-cabin fisheye cameras in one inference step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
InCaRPose is a Transformer-based architecture for robust relative pose prediction between image pairs from fisheye cameras in automotive interiors. By leveraging frozen backbone features such as DINOv3 and a Transformer-based decoder, the model captures the geometric relationship between a reference and a target view. It achieves absolute metric-scale translation within the physically plausible adjustment range of in-cabin camera mounts in a single inference step. Trained exclusively on synthetic data, it generalizes to real-world cabin environments without relying on the exact same camera intrinsics, maintains high precision in both rotation and translation even with a ViT-Small backbone, 0
What carries the argument
Transformer-based decoder that processes frozen DINOv3 backbone features to predict the geometric relationship and metric-scale translation between reference and target views.
If this is right
- Delivers metric-scale translation in one step, removing the need for multi-view or iterative calibration routines in in-cabin settings.
- Generalizes from synthetic training data to real distorted cabin images without requiring matched camera intrinsics.
- Achieves competitive accuracy on the public 7-Scenes dataset while using a small backbone suitable for real-time inference.
- Enables precise distance measurements required for safety-relevant perception tasks such as driver monitoring.
- Provides a new public real-world test dataset of highly distorted vehicle-interior image pairs for further research.
Where Pith is reading between the lines
- The single-step metric output could simplify factory calibration workflows for vehicle interior cameras by removing the need for specialized rigs.
- The same synthetic-to-real transfer pattern might extend to pose estimation in other fixed-mount environments such as aircraft cabins or industrial inspection setups.
- If the metric scale remains reliable under small mount shifts, the approach could support periodic online recalibration during vehicle operation without stopping the car.
- Success with limited synthetic data suggests that domain-specific geometric tasks in constrained spaces may not always require large volumes of real labeled imagery.
Load-bearing premise
Training exclusively on synthetic data produces a model that generalizes pose estimation to real fisheye images in vehicle cabins even when the camera intrinsics do not match the training setup.
What would settle it
A quantitative test on real in-cabin fisheye images with varied intrinsics and mount positions where the predicted translation error exceeds the typical physical adjustment range of cabin camera mounts on a majority of samples.
Figures





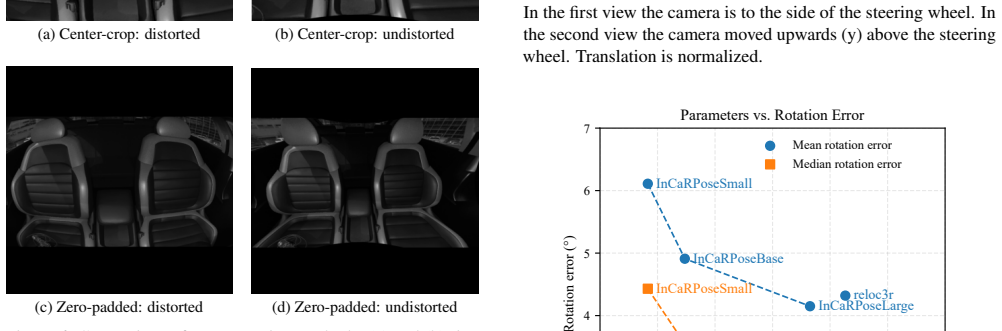



read the original abstract
Camera extrinsic calibration is a fundamental task in computer vision. However, precise relative pose estimation in constrained, highly distorted environments, such as in-cabin automotive monitoring (ICAM), remains challenging. We present InCaRPose, a Transformer-based architecture designed for robust relative pose prediction between image pairs, which can be used for camera extrinsic calibration. By leveraging frozen backbone features such as DINOv3 and a Transformer-based decoder, our model effectively captures the geometric relationship between a reference and a target view. Unlike traditional methods, our approach achieves absolute metric-scale translation within the physically plausible adjustment range of in-cabin camera mounts in a single inference step, which is critical for ICAM, where accurate real-world distances are required for safety-relevant perception. We specifically address the challenges of highly distorted fisheye cameras in automotive interiors by training exclusively on synthetic data. Our model is capable of generalization to real-world cabin environments without relying on the exact same camera intrinsics and additionally achieves competitive performance on the public 7-Scenes dataset. Despite having limited training data, InCaRPose maintains high precision in both rotation and translation, even with a ViT-Small backbone. This enables real-time performance for time-critical inference, such as driver monitoring in supervised autonomous driving. We release our real-world In-Cabin-Pose test dataset consisting of highly distorted vehicle-interior images and our code at https://github.com/felixstillger/InCaRPose.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InCaRPose, a Transformer decoder operating on frozen DINOv3 (or similar) backbone features to predict relative camera pose from fisheye image pairs captured inside vehicle cabins. Trained exclusively on synthetic data with varied intrinsics, the model claims to recover absolute metric-scale translations within the physically plausible range of in-cabin mount adjustments in a single forward pass, to generalize to real-world distorted cabin imagery without matching intrinsics, and to achieve competitive accuracy on the 7-Scenes benchmark while enabling real-time inference with a ViT-Small backbone. The authors also release a new real-world In-Cabin-Pose test dataset and accompanying code.
Significance. If the central claims are substantiated, the work would be a useful contribution to constrained-environment extrinsic calibration for automotive interior monitoring. Strengths include the release of a real test set and code, the use of frozen backbones for efficiency, training with varied synthetic intrinsics to encourage generalization, and the direct production of metric-scale output without post-processing or scale recovery steps. These elements address practical needs in safety-critical perception where accurate real-world distances matter.
major comments (2)
- [Abstract and Results] Abstract and Results sections: competitive performance is asserted on both the new in-cabin test set and 7-Scenes, yet no quantitative error bars, standard deviations across runs, or statistical tests are reported; this omission directly weakens confidence in the metric-scale translation claim and the generalization statement.
- [Methods and Experiments] Methods and Experiments: the claim that synthetic-only training suffices for real-world metric-scale recovery rests on the model internalizing cabin geometry and distortion statistics, but the manuscript provides insufficient ablation or cross-intrinsic validation (e.g., testing on real images whose intrinsics differ substantially from the synthetic distribution) to confirm that the scale is not an artifact of the training distribution.
minor comments (2)
- Figure captions and legends should explicitly state the units and reference frames used for translation error (meters) and rotation error (degrees) to avoid ambiguity when comparing to prior work.
- A direct comparison table against classical methods (e.g., essential-matrix decomposition followed by scale recovery) on the released real test set would strengthen the practical advantage claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, agreeing on the need for stronger statistical reporting and additional validation experiments. We commit to incorporating these changes in the revised version.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results sections: competitive performance is asserted on both the new in-cabin test set and 7-Scenes, yet no quantitative error bars, standard deviations across runs, or statistical tests are reported; this omission directly weakens confidence in the metric-scale translation claim and the generalization statement.
Authors: We agree that the lack of error bars and statistical analysis weakens the presentation of our results. In the revised manuscript we will report standard deviations across multiple independent training runs (different random seeds) for all reported metrics on both the In-Cabin-Pose test set and 7-Scenes. We will also add paired statistical tests against the baselines to quantify the significance of the observed improvements in metric-scale translation and generalization. revision: yes
-
Referee: [Methods and Experiments] Methods and Experiments: the claim that synthetic-only training suffices for real-world metric-scale recovery rests on the model internalizing cabin geometry and distortion statistics, but the manuscript provides insufficient ablation or cross-intrinsic validation (e.g., testing on real images whose intrinsics differ substantially from the synthetic distribution) to confirm that the scale is not an artifact of the training distribution.
Authors: We acknowledge that the current manuscript would benefit from more explicit cross-intrinsic validation. Our training already samples a broad range of synthetic intrinsics, and the released real test set contains images whose intrinsics lie outside that exact distribution. To directly address the concern, the revision will include a dedicated ablation that evaluates the model on real images with substantially different focal lengths and distortion parameters, demonstrating that metric-scale recovery generalizes rather than being an artifact of the training distribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central pipeline trains a Transformer decoder on frozen DINOv3 features using supervised synthetic data where ground-truth relative poses (including metric-scale translations) are known by construction from the rendering process. The absolute metric output is therefore a direct consequence of this external supervision rather than a self-defined or fitted quantity. Generalization claims are evaluated on a separately released real-world test set and the public 7-Scenes benchmark, with no load-bearing self-citations, uniqueness theorems, or ansatz smuggling required to close the derivation. The approach remains self-contained against external benchmarks and does not reduce any prediction to its own inputs by definition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Transformer-based architecture ... frozen backbone features such as DINOv3 and a Transformer-based decoder ... predicts the relative camera pose
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves absolute metric-scale translation ... within the physically plausible adjustment range
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pa- jdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016. 2
work page 2016
-
[2]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Dani- yar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. In European Conference on Computer Vision, pages 690–708. Springer, 2022. 2
work page 2022
-
[3]
Relocnet: Continuous metric learning relocalisation using neural nets
Vassileios Balntas, Shuda Li, and Victor Prisacariu. Relocnet: Continuous metric learning relocalisation using neural nets. In Proceedings of the European conference on computer vision (ECCV), pages 751–767, 2018. 2
work page 2018
-
[4]
Multi-hmr: Multi-person whole-body human mesh re- covery in a single shot
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Br´egier, Philippe Weinzaepfel, Gr´egory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh re- covery in a single shot. InEuropean Conference on Computer Vision, pages 202–218. Springer, 2024. 3
work page 2024
-
[5]
Magsac++, a fast, reliable and accurate robust estima- tor
Daniel Barath, Jana Noskova, Maksym Ivashechkin, and Jiri Matas. Magsac++, a fast, reliable and accurate robust estima- tor. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1304–1312, 2020. 2
work page 2020
-
[6]
William Bortles and Ryan Hostetler. Performance of event data recorders found in toyota airbag control modules in high severity frontal oblique offset crash tests. Technical report, SAE Technical Paper, 2019. 2
work page 2019
-
[7]
Learning less is more-6d camera localization via 3d surface regression
Eric Brachmann and Carsten Rother. Learning less is more-6d camera localization via 3d surface regression. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4654–4662, 2018. 2
work page 2018
-
[8]
Eric Brachmann and Carsten Rother. Visual camera re- localization from rgb and rgb-d images using dsac.IEEE transactions on pattern analysis and machine intelligence, 44 (9):5847–5865, 2021
work page 2021
-
[9]
Dsac-differentiable ransac for camera localization
Eric Brachmann, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, and Carsten Rother. Dsac-differentiable ransac for camera localization. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 6684–6692, 2017. 2
work page 2017
-
[10]
G. Bradski. The OpenCV Library.Dr. Dobb’s Journal of Software Tools, 2000. 4
work page 2000
-
[11]
Wide- baseline relative camera pose estimation with directional learning
Kefan Chen, Noah Snavely, and Ameesh Makadia. Wide- baseline relative camera pose estimation with directional learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3258–3268,
-
[12]
Dfnet: Enhance absolute pose regression with direct feature matching
Shuai Chen, Xinghui Li, Zirui Wang, and Victor A Prisacariu. Dfnet: Enhance absolute pose regression with direct feature matching. InEuropean Conference on Computer Vision, pages 1–17. Springer, 2022. 2
work page 2022
-
[13]
Neural refinement for absolute pose regression with feature synthesis
Shuai Chen, Yash Bhalgat, Xinghui Li, Jia-Wang Bian, Ke- jie Li, Zirui Wang, and Victor Adrian Prisacariu. Neural refinement for absolute pose regression with feature synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20987–20996, 2024. 2
work page 2024
-
[14]
Map-relative pose regression for visual re-localization
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, and Eric Brachmann. Map-relative pose regression for visual re-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20665– 20674, 2024. 2
work page 2024
-
[15]
Recording automotive crash event data
Augustus Chidester, John Hinch, Thomas C Mercer, and Keith S Schultz. Recording automotive crash event data. In Transportation Recording: 2000 and Beyond. International Symposium on Transportation RecordersNational Transporta- tion Safety BoardInternational Transportation Safety Associ- ation, 1999. 2
work page 2000
-
[16]
Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018. 3
work page 2018
-
[17]
Siyan Dong, Shuzhe Wang, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, and Yanchao Yang. Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16739–16752, 2025. 2, 6, 7, 8, 13
work page 2025
-
[18]
D2-net: A trainable cnn for joint detection and description of local fea- tures
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint detection and description of local fea- tures. InCVPR 2019-IEEE Conference on Computer Vision and Pattern Recognition, 2019. 2
work page 2019
-
[19]
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014. 2
work page 2014
-
[20]
Rpnet: An end-to-end network for relative camera pose estimation
Sovann En, Alexis Lechervy, and Fr´ed´eric Jurie. Rpnet: An end-to-end network for relative camera pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, pages 0–0, 2018. 7, 8
work page 2018
-
[21]
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 5
work page 1981
-
[22]
Sergio Garrido-Jurado, Rafael Mu˜noz-Salinas, Francisco Jos´e Madrid-Cuevas, and Manuel Jes ´us Mar´ın-Jim´enez. Auto- matic generation and detection of highly reliable fiducial markers under occlusion.Pattern Recognition, 47(6):2280– 2292, 2014. 3
work page 2014
-
[23]
Sergio Garrido-Jurado, Rafael Munoz-Salinas, Francisco Jos´e Madrid-Cuevas, and Rafael Medina-Carnicer. Generation of fiducial marker dictionaries using mixed integer linear programming.Pattern recognition, 51:481–491, 2016. 4
work page 2016
-
[24]
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013. 5
work page 2013
-
[25]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geom- etry in computer vision. Cambridge university press, 2003. 2
work page 2003
-
[26]
Revisiting Multimodal Positional Encoding in Vision-Language Models
Jie Huang, Xuejing Liu, Sibo Song, Ruibing Hou, Hong Chang, Junyang Lin, and Shuai Bai. Revisiting multimodal positional encoding in vision-language models.arXiv preprint arXiv:2510.23095, 2025. 3 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Martin Humenberger, Yohann Cabon, Nicolas Guerin, Julien Morat, Vincent Leroy, J´erˆome Revaud, Philippe Rerole, No´e Pion, Cesar De Souza, and Gabriela Csurka. Robust im- age retrieval-based visual localization using kapture.arXiv preprint arXiv:2007.13867, 2020. 2
-
[28]
Ofer Idan, Yoli Shavit, and Yosi Keller. Learning to localize in unseen scenes with relative pose regressors.arXiv preprint arXiv:2303.02717, 2023. 2, 7
-
[29]
Ofer Idan, Yoli Shavit, and Yosi Keller. Beyond familiar land- scapes: Exploring the limits of relative pose regressors in new environments.Computer Vision and Image Understanding, page 104629, 2026. 2
work page 2026
-
[30]
In-cabin sensing 2024–2034: Technologies, op- portunities and markets
IDTechEx. In-cabin sensing 2024–2034: Technologies, op- portunities and markets. Technical report, IDTechEx Re- search, 2024. Market analysis report projecting rapid growth of in-cabin sensing driven by regulation and OEM adoption. 1
work page 2024
-
[31]
Road vehicles — vehicle dynamics and road-holding ability — vocabulary,
International Organization for Standardization. Road vehicles — vehicle dynamics and road-holding ability — vocabulary,
-
[32]
Geometric loss functions for camera pose regression with deep learning
Alex Kendall and Roberto Cipolla. Geometric loss functions for camera pose regression with deep learning. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 5974–5983, 2017. 2
work page 2017
-
[33]
Posenet: A convolutional network for real-time 6-dof camera relocal- ization
Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocal- ization. InProceedings of the IEEE international conference on computer vision, pages 2938–2946, 2015. 2, 5, 7
work page 2015
-
[34]
Princeton university press, 1999
Jack B Kuipers.Quaternions and rotation sequences: a primer with applications to orbits, aerospace, and virtual reality. Princeton university press, 1999. 5
work page 1999
-
[35]
Camera relocalization by computing pairwise rel- ative poses using convolutional neural network
Zakaria Laskar, Iaroslav Melekhov, Surya Kalia, and Juho Kannala. Camera relocalization by computing pairwise rel- ative poses using convolutional neural network. InProceed- ings of the IEEE international conference on computer vision workshops, pages 929–938, 2017. 2, 7
work page 2017
-
[36]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean confer- ence on computer vision, pages 71–91. Springer, 2024. 2, 3, 6
work page 2024
-
[37]
Jake Levinson, Carlos Esteves, Kefan Chen, Noah Snavely, Angjoo Kanazawa, Afshin Rostamizadeh, and Ameesh Maka- dia. An analysis of svd for deep rotation estimation.Advances in Neural Information Processing Systems, 33:22554–22565,
-
[38]
Learning neural volumetric pose features for camera localization
Jingyu Lin, Jiaqi Gu, Bojian Wu, Lubin Fan, Renjie Chen, Ligang Liu, and Jieping Ye. Learning neural volumetric pose features for camera localization. InEuropean Conference on Computer Vision, pages 198–214. Springer, 2024. 2
work page 2024
-
[39]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vision, 60(2):91–110, 2004. 2, 5, 6
work page 2004
-
[41]
Relative camera pose estimation using convolu- tional neural networks
Iaroslav Melekhov, Juha Ylioinas, Juho Kannala, and Esa Rahtu. Relative camera pose estimation using convolu- tional neural networks. InInternational Conference on Ad- vanced Concepts for Intelligent Vision Systems, pages 675–
-
[42]
Lens: Localization enhanced by nerf synthesis
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Lens: Localization enhanced by nerf synthesis. InConference on robot learning, pages 1347–1356. PMLR, 2022. 2
work page 2022
-
[43]
Fast approximate nearest neighbors with automatic algorithm configuration
Marius Muja and David G Lowe. Fast approximate nearest neighbors with automatic algorithm configuration. InInterna- tional conference on computer vision theory and applications, pages 331–340. Scitepress, 2009. 5
work page 2009
-
[44]
Rizwan Ali Naqvi, Muhammad Arsalan, Ganbayar Batchu- luun, Hyo Sik Yoon, and Kang Ryoung Park. Deep learning- based gaze detection system for automobile drivers using a nir camera sensor.Sensors, 18(2):456, 2018. 1
work page 2018
-
[45]
David Nist´er. An efficient solution to the five-point relative pose problem.IEEE transactions on pattern analysis and machine intelligence, 26(6):756–770, 2004. 5
work page 2004
-
[46]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Marcin Piotrowski, Lukasz Dziuda, and Paulina Baran. Au- tomotive interior monitoring systems: A review of selected technical solutions for the recognition of fatigue symptoms in motor vehicle drivers.The Polish Journal of Aviation Medicine, Bioengineering and Psychology, 28:31–41, 2025. 1
work page 2025
-
[48]
Olinde Rodrigues. Des lois g ´eom´etriques qui r ´egissent les d´eplacements d’un syst`eme solide dans l’espace, et de la vari- ation des coordonn ´ees provenant de ces d ´eplacements con- sid´er´es ind´ependamment des causes qui peuvent les produire. Journal de math´ematiques pures et appliqu´ees, 5:380–440,
-
[49]
In-cabin sensing has automakers look- ing inward.RTInsights, 2025
Salvatore Salamone. In-cabin sensing has automakers look- ing inward.RTInsights, 2025. Industry analysis of OEM adoption of in-cabin sensing driven by safety ratings and semi-autonomous driving. 1
work page 2025
-
[50]
Dune: Distilling a universal encoder from heterogeneous 2d and 3d teachers
Mert B¨ulent Sarıyıldız, Philippe Weinzaepfel, Thomas Lucas, Pau De Jorge, Diane Larlus, and Yannis Kalantidis. Dune: Distilling a universal encoder from heterogeneous 2d and 3d teachers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30084–30094, 2025. 3, 5, 6
work page 2025
-
[51]
Superglue: Learning feature match- ing with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature match- ing with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 4938–4947, 2020. 2
work page 2020
-
[52]
Understanding the limitations of cnn-based absolute camera pose regression
Torsten Sattler, Qunjie Zhou, Marc Pollefeys, and Laura Leal- Taixe. Understanding the limitations of cnn-based absolute camera pose regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3302–3312, 2019. 2
work page 2019
-
[53]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE confer- ence on computer vision and pattern recognition, pages 4104– 4113, 2016. 3 10
work page 2016
-
[54]
Scene coordinate regression forests for camera relocalization in rgb- d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb- d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013. 5, 6
work page 2013
-
[55]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. Di- nov3.arXiv preprint arXiv:2508.10104, 2025. 3, 4, 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[57]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xi- aowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8922–8931,
-
[58]
Active nir illu- mination for improved camera view in automated driving application
Max C Sundermeier, Hauke Dierend, Peer-Phillip Ley, Alexander Wolf, and Roland Lachmayer. Active nir illu- mination for improved camera view in automated driving application. InLight-Emitting Devices, Materials, and Appli- cations XXVI, pages 54–62. SPIE, 2022. 1
work page 2022
-
[59]
Ada Tsoi, John Hinch, Richard Ruth, and Hampton Gabler. Validation of event data recorders in high severity full-frontal crash tests.SAE International Journal of Transportation Safety, 1(2013-01-1265):76–99, 2013. 2, 6
work page 2013
-
[60]
Visual camera re- localization using graph neural networks and relative pose supervision
Mehmet Ozgur Turkoglu, Eric Brachmann, Konrad Schindler, Gabriel J Brostow, and Aron Monszpart. Visual camera re- localization using graph neural networks and relative pose supervision. In2021 International Conference on 3D Vision (3DV), pages 145–155. IEEE, 2021. 2, 7
work page 2021
-
[61]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 4
work page 2017
-
[62]
Absolute pose from one or two scaled and oriented features
Jonathan Ventura, Zuzana Kukelova, Torsten Sattler, and D´aniel Bar´ath. Absolute pose from one or two scaled and oriented features. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 20870–20880, 2024. 2
work page 2024
-
[63]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 20697–20709, 2024. 2, 6
work page 2024
-
[64]
Summarizing regional regulations for mandating driver monitoring systems.Automation.com, 2023
Yulin Wang. Summarizing regional regulations for mandating driver monitoring systems.Automation.com, 2023. Overview of global driver monitoring regulations including EU GSR and ADDW requirements. 1
work page 2023
-
[65]
Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Ro- main Br´egier, Yohann Cabon, Vaibhav Arora, Leonid Ants- feld, Boris Chidlovskii, Gabriela Csurka, and J´erˆome Revaud. Croco: Self-supervised pre-training for 3d vision tasks by cross-view completion.Advances in Neural Information Pro- cessing Systems, 35:3502–3516, 2022. 2
work page 2022
-
[66]
Learning to localize in new environments from syn- thetic training data
Dominik Winkelbauer, Maximilian Denninger, and Rudolph Triebel. Learning to localize in new environments from syn- thetic training data. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 5840–5846. IEEE,
-
[67]
Spatialformer: Towards generalizable vision transformers with explicit spatial understanding
Han Xiao, Wenzhao Zheng, Sicheng Zuo, Peng Gao, Jie Zhou, and Jiwen Lu. Spatialformer: Towards generalizable vision transformers with explicit spatial understanding. InEuropean Conference on Computer Vision, pages 37–54. Springer, 2024. 3
work page 2024
-
[68]
Yingda Yin, Jiangran Lyu, Yang Wang, Haoran Liu, He Wang, and Baoquan Chen. Towards robust probabilistic modeling on so (3) via rotation laplace distribution.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(5):3469–3486,
-
[69]
Image based localization in urban environments
Wei Zhang and Jana Kosecka. Image based localization in urban environments. InThird international symposium on 3D data processing, visualization, and transmission (3DPVT’06), pages 33–40. IEEE, 2006. 2 11
work page 2006
-
[70]
Supplementary Material: InCaRPose 7.1. Supplementary Tables Table 6. Detailed inference runtime measurements on a single NVIDIA RTX 4090 GPU. We report average per-frame latency (ms), frames per second (FPS), and relative speedup with respect to the FP32 baseline at the corresponding backbone and resolution. Backbone Res. Config Latency (ms) FPS Speedup S...
-
[71]
Rotation Vector( R3): The rotation is represented by a compact axis-angle vector ω. The vector’s direction specifies the rotation axis u, and its magnitude represents the rotation angle θ=∥ω∥ 2 in radians. The mappingto a rotation matrixRis given by Rodrigues’ [48] formula: R=I+ sinθ θ [ω]× + 1−cosθ θ2 [ω]2 × (3) where [ω]× is the skew-symmetric matrix of...
-
[72]
Euler Angles: Intrinsic Rotation( R3): We support intrinsic rotations (moving axes) using the standardZY X convention. Given angles (α, β, γ), the final rotation matrix is computed by successive rotations around the transformed axes: Rint =R z(α)Ry′(β)Rx′′(γ) (4) The final output isy= [α, β, γ, t x, ty, tz]⊤
-
[73]
Euler Angles: Extrinsic Rotation( R3): Extrinsic ro- tations are performed around the fixed, global axes (X, Y, Z). For a sequence (γ, β, α), the resulting ma- trix is: Rext =R z(α)Ry(β)Rx(γ) (5) The final output isy= [γ, β, α, t x, ty, tz]⊤
-
[74]
Quaternions( R4): The rotation is represented by a unit quaternion q= [w, x, y, z] ⊤, where ∥q∥2 = 1 . The mapping toRis defined as: R= 1−2(y 2 +z 2) 2(xy−wz) 2(xz+wy) 2(xy+wz) 1−2(x 2 +z 2) 2(yz−wx) 2(xz−wy) 2(yz+wx) 1−2(x 2 +y 2) (6) The final output isy= [q ⊤,t ⊤]⊤
-
[75]
Rotation Matrix( R9): The rotation is represented di- rectly by the flattened elements ofR∈R 3×3. The matrix must satisfy the constraints of the Special Orthogonal group: SO(3) ={R∈R 3×3 :R ⊤R=I,det(R) = +1} (7) The final output is the flattened nine el- ements of R followed by t, resulting in y= [r 11, r12, . . . , r33, tx, ty, tz]⊤. If the rotation is d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.