Recognition: no theorem link
GPU-Accelerated Quantum Simulation: Empirical Backend Selection, Gate Fusion, and Adaptive Precision
Pith reviewed 2026-05-13 17:09 UTC · model grok-4.3
The pith
A GPU framework for quantum circuit simulation achieves 64x to 146x speedups over CPU through runtime backend selection and DAG-based gate fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Runtime empirical selection among GPU execution backends, paired with DAG-based gate fusion and adaptive precision, produces state-vector simulations that run between 64x and 146x faster than NumPy on CPU for circuits with 20 to 28 qubits, with circuit depth reductions such as 42 to 14 gates and hardware-validated fidelities of 0.939 for Bell states and 0.853 for five-qubit GHZ states.
What carries the argument
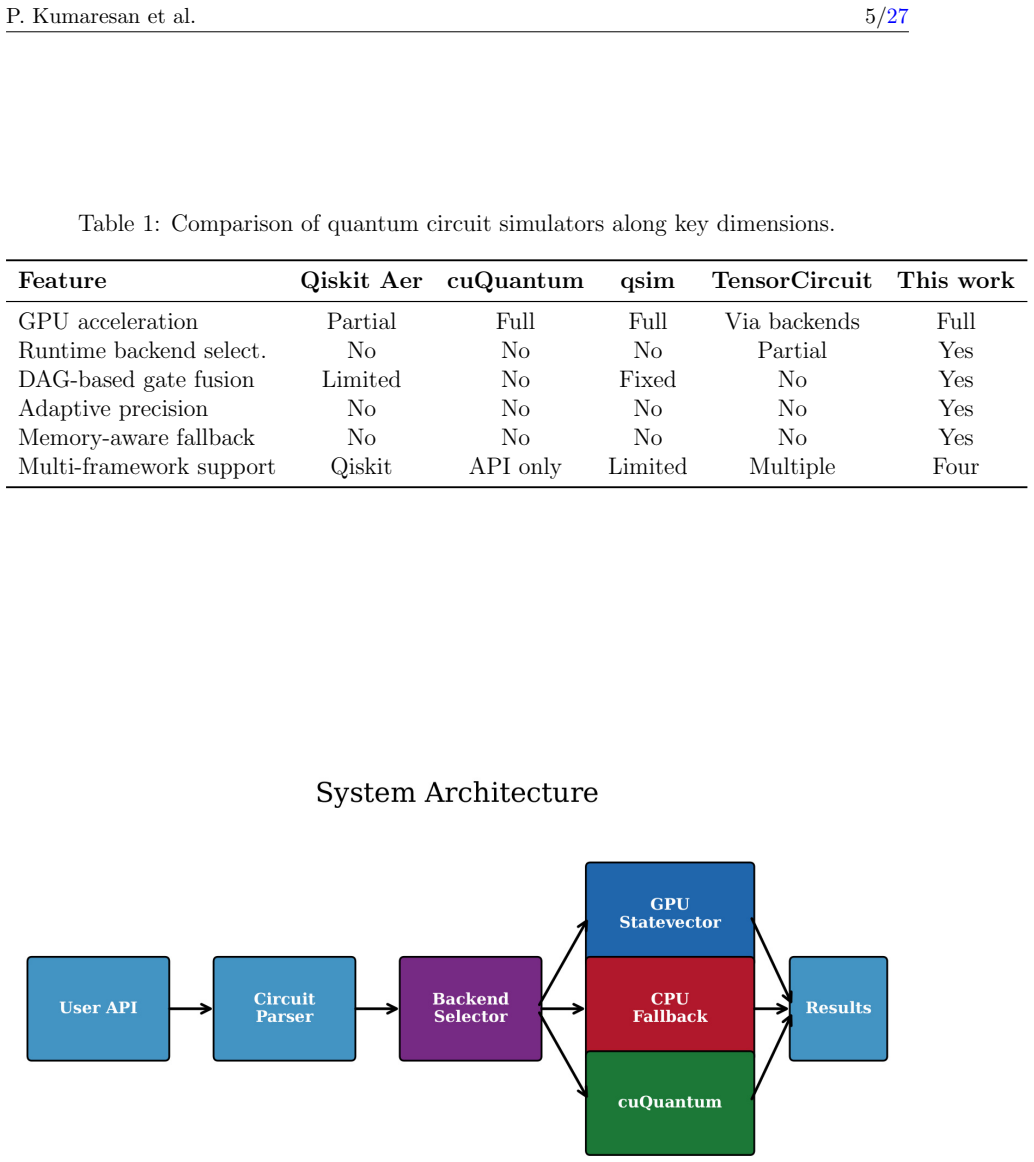
An empirical backend selection algorithm that measures throughput of CuPy, PyTorch-CUDA, and NumPy-CPU at runtime to choose the optimal execution path, together with a DAG-based gate fusion engine that identifies and merges fusible gate sequences.
If this is right
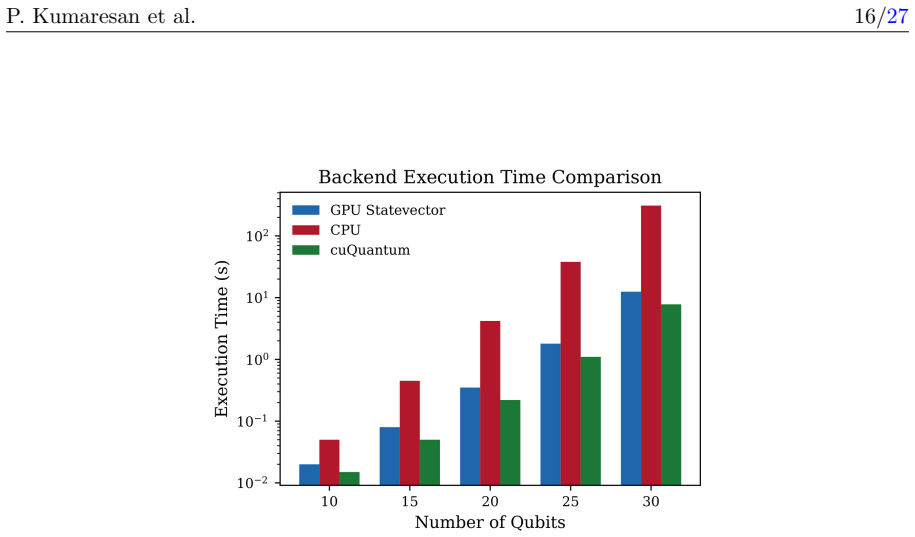
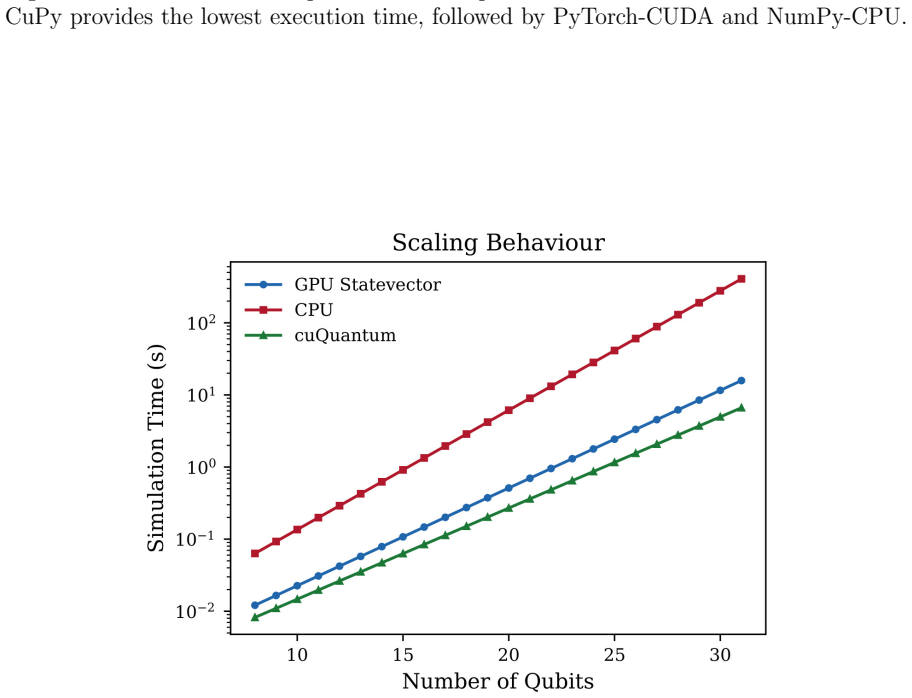
- Speedups exceed 5x starting at 16 qubits and reach 64x-146x at 20-28 qubits.
- Automated fusion reduces circuit depth, for example from 42 gates to 14 gates.
- The framework supports direct integration with Qiskit, Cirq, PennyLane, and Amazon Braket.
- Memory monitoring triggers a seamless switch to CPU execution when GPU capacity is exceeded.
Where Pith is reading between the lines
- Runtime adaptation of this form could be extended to multi-GPU or TPU environments to push simulation limits higher.
- Lower gate counts from fusion may simplify the design of quantum algorithms that target reduced error rates.
- The reported hardware fidelities indicate the simulator can serve as a practical pre-check for small entangled states before QPU runs.
Load-bearing premise
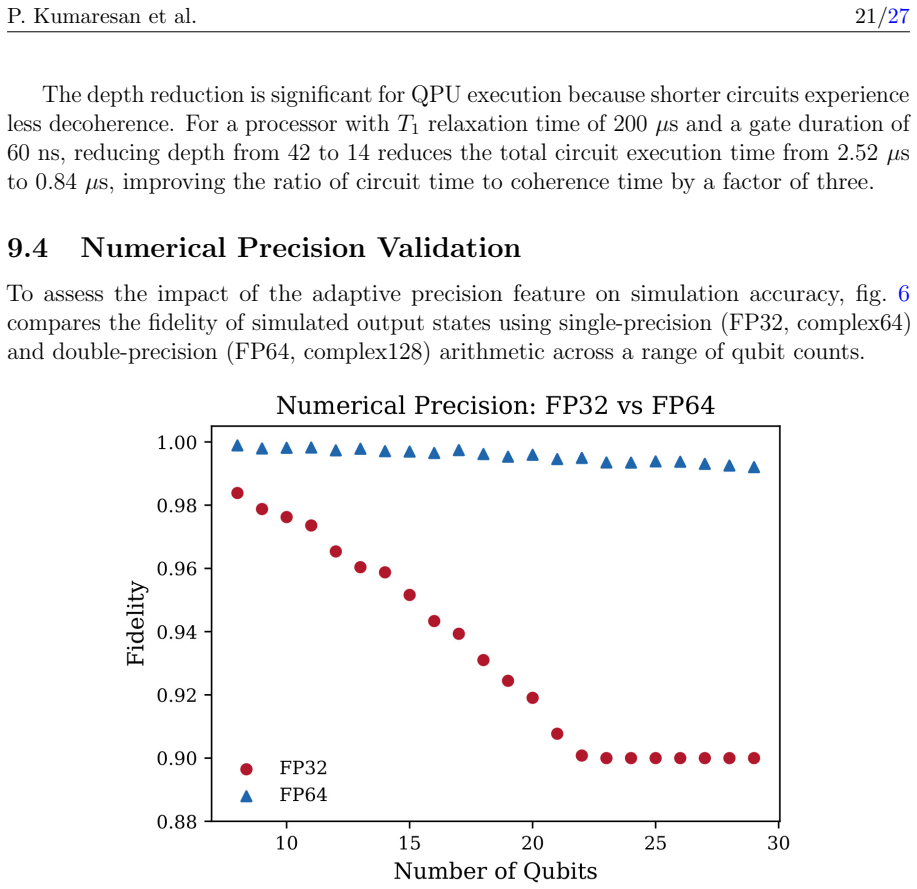
The speedups and depth reductions observed in the tested circuits and hardware will appear reliably for other circuit structures and GPU models without hidden selection overheads.
What would settle it
Benchmarking the framework on a new family of circuits with limited fusible sequences or on a different GPU architecture and finding speedups below 5x for all circuits above 16 qubits would show the gains do not generalize.
Figures


read the original abstract
Classical simulation of quantum circuits remains indispensable for algorithm development, hardware validation, and error analysis in the noisy intermediate-scale quantum (NISQ) era. However, state-vector simulation faces exponential memory scaling, with an n-qubit system requiring O(2^n) complex amplitudes, and existing simulators often lack the flexibility to exploit heterogeneous computing resources at runtime. This paper presents a GPU-accelerated quantum circuit simulation framework that introduces three contributions: (1) an empirical backend selection algorithm that benchmarks CuPy, PyTorch-CUDA, and NumPy-CPU backends at runtime and selects the optimal execution path based on measured throughput; (2) a directed acyclic graph (DAG) based gate fusion engine that reduces circuit depth through automated identification of fusible gate sequences, coupled with adaptive precision switching between complex64 and complex128 representations; and (3) a memory-aware fallback mechanism that monitors GPU memory consumption and gracefully degrades to CPU execution when resources are exhausted. The framework integrates with Qiskit, Cirq, PennyLane, and Amazon Braket through a unified adapter layer. Benchmarks on an NVIDIA A100-SXM4 (40 GiB) GPU demonstrate speedups of 64x to 146x over NumPy CPU execution for state-vector simulation of circuits with 20 to 28 qubits, with speedups exceeding 5x from 16 qubits onward. Hardware validation on an IBM quantum processing unit (QPU) confirms Bell state fidelity of 0.939, a five-qubit Greenberger-Horne-Zeilinger (GHZ) state fidelity of 0.853, and circuit depth reduction from 42 to 14 gates through the fusion pipeline. The system is designed for portability across NVIDIA consumer and data-center GPUs, requiring no vendor-specific compilation steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a GPU-accelerated quantum circuit simulation framework with three main contributions: (1) an empirical runtime backend selection algorithm that benchmarks and chooses among CuPy, PyTorch-CUDA, and NumPy-CPU based on measured throughput; (2) a DAG-based gate fusion engine that identifies fusible sequences to reduce depth, combined with adaptive switching between complex64 and complex128 precision; and (3) a memory-aware fallback to CPU execution when GPU resources are exhausted. The framework provides a unified adapter layer for Qiskit, Cirq, PennyLane, and Amazon Braket. Benchmarks on an NVIDIA A100-SXM4 (40 GiB) GPU report speedups of 64x–146x versus direct NumPy CPU execution for 20–28 qubit state-vector simulations (exceeding 5x from 16 qubits onward), while hardware validation on an IBM QPU shows Bell-state fidelity of 0.939, five-qubit GHZ fidelity of 0.853, and depth reduction from 42 to 14 gates via fusion. The system emphasizes portability across NVIDIA GPUs without vendor-specific compilation.
Significance. If the reported speedups and fidelity values are substantiated with complete benchmark data, error bars, and isolated timing breakdowns, the framework could provide a practical, portable tool for NISQ-era circuit simulation that leverages heterogeneous resources at runtime. The multi-library integration and automated fusion-plus-precision adaptation represent usable engineering contributions that could accelerate algorithm prototyping and hardware validation workflows. The absence of parameter fitting or circular derivations is a positive feature of the empirical approach.
major comments (2)
- [Benchmarks / Results] Benchmarks section (as described in the abstract and results): the headline speedups of 64x–146x (and >5x from 16 qubits) are stated relative to NumPy CPU but provide no breakdown isolating the runtime overhead of the empirical backend selection algorithm itself. For circuits near the 16-qubit threshold or with shallow depth, selection time could erode net gains; without per-component timing tables or ablation data, the central performance claim cannot be fully evaluated.
- [Hardware Validation] Hardware validation paragraph (abstract and §5): the reported Bell (0.939) and GHZ (0.853) fidelities and the depth reduction (42 to 14 gates) are given without error bars, baseline comparisons against unfused circuits on the same QPU, or details on how the fused circuit was transpiled and executed. This information is load-bearing for the validation claim and must be supplied with methodology and raw data.
minor comments (2)
- [Implementation / Setup] The abstract states that the system requires 'no vendor-specific compilation steps'; this portability claim should be supported with explicit installation and runtime instructions in the implementation section for reproducibility across consumer and data-center GPUs.
- Figure captions and tables (if present) should include the exact circuit depths, qubit counts, and number of repeated runs used to generate the speedup and fidelity numbers so readers can assess statistical reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmarks / Results] Benchmarks section (as described in the abstract and results): the headline speedups of 64x–146x (and >5x from 16 qubits) are stated relative to NumPy CPU but provide no breakdown isolating the runtime overhead of the empirical backend selection algorithm itself. For circuits near the 16-qubit threshold or with shallow depth, selection time could erode net gains; without per-component timing tables or ablation data, the central performance claim cannot be fully evaluated.
Authors: We agree that a component-wise timing breakdown is necessary to fully substantiate the performance claims. The revised manuscript will include per-component timing tables and ablation studies that isolate the overhead of the empirical backend selection algorithm across circuit sizes (including near the 16-qubit threshold) and depths. These additions will quantify the selection cost relative to the overall execution time and confirm that net speedups remain substantial in the reported regimes. revision: yes
-
Referee: [Hardware Validation] Hardware validation paragraph (abstract and §5): the reported Bell (0.939) and GHZ (0.853) fidelities and the depth reduction (42 to 14 gates) are given without error bars, baseline comparisons against unfused circuits on the same QPU, or details on how the fused circuit was transpiled and executed. This information is load-bearing for the validation claim and must be supplied with methodology and raw data.
Authors: We concur that the hardware validation section requires additional rigor. In the revision we will add error bars derived from repeated executions, direct baseline comparisons of fused versus unfused circuits on the same IBM QPU, and an expanded methodology subsection that details the transpilation workflow, execution parameters, and fusion application. Raw measurement data will be provided in supplementary materials to allow independent verification. revision: yes
Circularity Check
No circularity: empirical benchmarks and runtime algorithms are self-contained
full rationale
The paper presents an engineering framework whose central claims are direct runtime measurements (speedups of 64x–146x on A100 for 20–28 qubits, >5x from 16 qubits) and hardware fidelity checks (Bell 0.939, GHZ 0.853). No derivation chain, equations, or first-principles results exist that could reduce to fitted parameters or self-referential definitions. Backend selection benchmarks throughput at runtime before execution; this is an algorithmic step, not a prediction fitted to the reported speedups. Gate fusion and adaptive precision are implemented mechanisms whose performance is measured, not derived from prior self-citations. The work is self-contained against external benchmarks (NumPy CPU, IBM QPU) with no load-bearing self-citation or ansatz smuggling. Minor self-citations, if present, do not support the headline results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Richard P. Feynman. Simulating physics with computers.International Journal of Theoretical Physics, 21(6-7):467–488, 1982
work page 1982
-
[2]
Quantum supremacy using a programmable superconducting processor.Nature, 574(7779):505–510, 2019
Frank Arute, Kunal Arya, Ryan Babbush, et al. Quantum supremacy using a programmable superconducting processor.Nature, 574(7779):505–510, 2019
work page 2019
-
[3]
Peter W. Shor. Algorithms for quantum computation: Discrete logarithms and factoring. InProceedings of the 35th Annual Symposium on Foundations of Computer Science, pages 124–134, 1994
work page 1994
-
[4]
Lov K. Grover. A fast quantum mechanical algorithm for database search. In Proceedings of the 28th Annual ACM Symposium on Theory of Computing, pages 212–219, 1996
work page 1996
-
[5]
Love, Al´ an Aspuru-Guzik, and Jeremy L
Alberto Peruzzo, Jarrod McClean, Peter Shadbolt, Man-Hong Yung, Xiao-Qi Zhou, Peter J. Love, Al´ an Aspuru-Guzik, and Jeremy L. O’Brien. A variational eigenvalue solver on a photonic quantum processor.Nature Communications, 5:4213, 2014
work page 2014
-
[6]
Abhinav Kandala, Antonio Mezzacapo, Kristan Temme, Maika Takita, Markus Brink, Jerry M. Chow, and Jay M. Gambetta. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets.Nature, 549(7671):242–246, 2017
work page 2017
-
[7]
Kishor Bharti, Alba Cervera-Lierta, Thi Ha Kyaw, Tobias Haug, Sumner Alperin-Lea, Abhinav Anand, Matthias Degroote, Hermanni Heimonen, Jakob S. Kottmann, Tim Menke, et al. Noisy intermediate-scale quantum algorithms.Reviews of Modern Physics, 94(1):015004, 2022
work page 2022
-
[8]
Quantum computing in the NISQ era and beyond.Quantum, 2:79, 2018
John Preskill. Quantum computing in the NISQ era and beyond.Quantum, 2:79, 2018
work page 2018
-
[9]
Scalable parallel programming with CUDA.ACM Queue, 6(2):40–53, 2008
John Nickolls, Ian Buck, Michael Garland, and Kevin Skadron. Scalable parallel programming with CUDA.ACM Queue, 6(2):40–53, 2008
work page 2008
-
[10]
NVIDIA A100 Tensor Core GPU: Performance and innovation.IEEE Micro, 41(2): 29–35, 2021
Jack Choquette, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. NVIDIA A100 Tensor Core GPU: Performance and innovation.IEEE Micro, 41(2): 29–35, 2021
work page 2021
-
[11]
Fang, Yunchao Gao, Jim Guan, John Gunnels, et al
Hasan Bayraktar, Ali Charara, David Clark, Shawn Cohen, Timothy Costa, Yao- Lung L. Fang, Yunchao Gao, Jim Guan, John Gunnels, et al. cuQuantum SDK: A high- performance library for accelerating quantum science. In2023 IEEE International Conference on Quantum Computing and Engineering (QCE), pages 1050–1061. IEEE,
-
[12]
doi: 10.1109/qce57702.2023.00119
-
[13]
Sergio Boixo, Sergei V. Isakov, Vadim N. Smelyanskiy, et al. Simulation of low- depth quantum circuits as complex undirected graphical models.arXiv preprint arXiv:2001.00862, 2020
-
[14]
Qiskit: An open-source framework for quantum computing
H´ ector Abraham et al. Qiskit: An open-source framework for quantum computing
-
[15]
Zenodo.https://doi.org/10.5281/zenodo.2562110. P. Kumaresan et al. 26/27
-
[16]
Cirq Developers. Cirq: A Python framework for creating, editing, and invoking noisy intermediate scale quantum circuits. 2018. https://github.com/quantumlib/Cirq
work page 2018
-
[17]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin, Shahnawaz Ahmed, Vishnu Ajber, M. Sohaib Alam, Guillermo Alonso-Linaje, et al. PennyLane: Au- tomatic differentiation of hybrid quantum-classical computations.arXiv preprint arXiv:1811.04968, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Amazon Braket: Quantum computing service
Amazon Web Services. Amazon Braket: Quantum computing service. 2020. https: //aws.amazon.com/braket/
work page 2020
-
[19]
Igor L. Markov and Yaoyun Shi. Simulating quantum computation by contracting tensor networks.SIAM Journal on Computing, 38(3):963–981, 2008
work page 2008
-
[20]
Improved simulation of stabilizer circuits
Scott Aaronson and Daniel Gottesman. Improved simulation of stabilizer circuits. Physical Review A, 70(5):052328, 2004
work page 2004
-
[21]
Benjamin Villalonga, Sergio Boixo, Bron Nelson, Christopher Henze, Eleanor Rieffel, Rupak Biswas, and Salvatore Mandra. A flexible high-performance simulator for verifying and benchmarking quantum circuits implemented on real hardware.npj Quantum Information, 5(1):86, 2019
work page 2019
- [22]
-
[23]
64-qubit quantum circuit simulation.Science Bulletin, 63(15):964–971, 2018
Zhao-Yun Chen, Qi Zhou, Cheng Xue, Xia Yang, Guang-Can Guo, and Guo-Ping Guo. 64-qubit quantum circuit simulation.Science Bulletin, 63(15):964–971, 2018
work page 2018
-
[24]
Thomas H¨ aner and Damian S. Steiger. 0.5 petabyte simulation of a 45-qubit quantum circuit. InProceedings of the International Conference for High Performance Com- puting, Networking, Storage and Analysis (SC), 2017. doi: 10.1145/3126908.3126947
-
[25]
TensorCircuit: a quantum software framework for the NISQ era.Quantum, 7:912, 2023
Shi-Xin Zhang, Jonathan Allcock, Zhou-Quan Wan, Shuo Liu, Jiace Sun, Hao Yu, Xing-Han Yang, Jiezhong Qiu, Zhaofeng Ye, Yu-Qin Chen, et al. TensorCircuit: a quantum software framework for the NISQ era.Quantum, 7:912, 2023
work page 2023
-
[26]
Gunnels, Giacomo Nannicini, Lior Horesh, and Robert Wisnieff
Edwin Pednault, John A. Gunnels, Giacomo Nannicini, Lior Horesh, and Robert Wisnieff. Breaking the 49-qubit barrier in the simulation of quantum circuits.arXiv preprint arXiv:1710.05867, 2017
-
[27]
Nakanishi, Kosuke Mitarai, Ryosuke Imai, Shiro Tamiya, et al
Yasunari Suzuki, Yoshiaki Kawase, Yuya Masumura, Yuria Hiraga, Masahiro Nakadai, Jiabao Chen, Ken M. Nakanishi, Kosuke Mitarai, Ryosuke Imai, Shiro Tamiya, et al. Qulacs: a fast and versatile quantum circuit simulator for research purpose.Quantum, 5:559, 2021
work page 2021
-
[28]
Advanced simulation of quantum computations
Alwin Zulehner and Robert Wille. Advanced simulation of quantum computations. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 38(5):848–859, 2019
work page 2019
-
[29]
Hans De Raedt, Fengping Jin, Dennis Willsch, et al. Massively parallel quantum computer simulator, eleven years later.Computer Physics Communications, 237: 47–61, 2019. P. Kumaresan et al. 27/27
work page 2019
-
[30]
CuPy: A NumPy-compatible library for NVIDIA GPU calculations
Ryosuke Okuta, Yuya Unno, Daisuke Nishino, Shohei Hido, and Crissman Loomis. CuPy: A NumPy-compatible library for NVIDIA GPU calculations. InProceedings of Workshop on Machine Learning Systems (LearningSys) in NeurIPS, 2017
work page 2017
-
[31]
Adam Paszke, Sam Gross, Francisco Massa, et al. PyTorch: An imperative style, high-performance deep learning library.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
- [32]
-
[33]
IBM Heron architecture: 156-qubit processors
IBM Quantum. IBM Heron architecture: 156-qubit processors. IBM Research Blog,
-
[34]
Accessed: 2026-03-15
work page 2026
-
[35]
Alexander J. McCaskey, Eugene F. Dumitrescu, Mengsu Chen, Dmitry Lyakh, and Travis S. Humble. Validating quantum-classical programming models with tensor network simulations.PLoS ONE, 13(12):e0206704, 2018
work page 2018
-
[36]
Yunseong Nam, Neil J. Ross, Yuan Su, Andrew M. Childs, and Dmitri Maslov. Automated optimization of large quantum circuits with continuous parameters.npj Quantum Information, 4(1):23, 2018
work page 2018
-
[37]
Open Quantum Assembly Language
Andrew W. Cross, Lev S. Bishop, John A. Smolin, and Jay M. Gambetta. Open quantum assembly language.arXiv preprint arXiv:1707.03429, 2017
work page Pith review arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.