Recognition: 2 theorem links
· Lean TheoremExplainability-Guided Adversarial Attacks on Transformer-Based Malware Detectors Using Control Flow Graphs
Pith reviewed 2026-05-13 17:06 UTC · model grok-4.3
The pith
A white-box attack uses integrated gradients to swap influential function calls in linearized control flow graphs and force misclassification by transformer malware detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
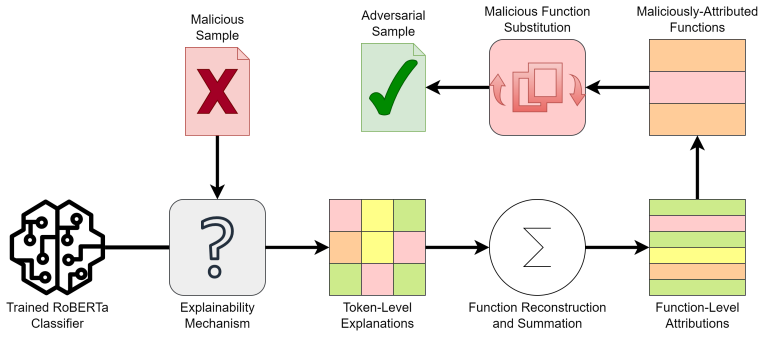
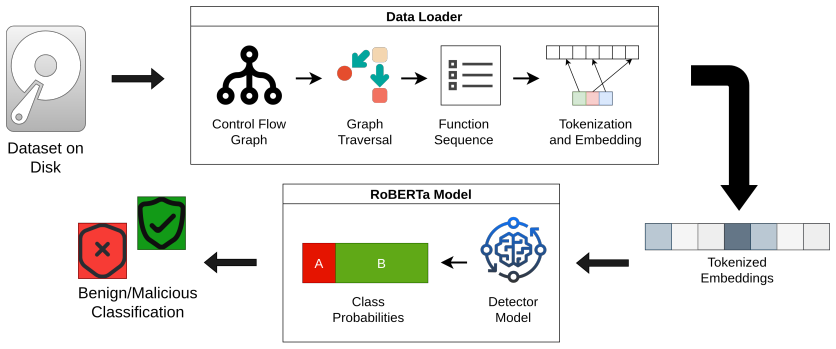
The central claim is that token- and word-level attributions from integrated gradients on a RoBERTa model processing linearized control flow graph sequences can identify positively attributed function calls; iteratively replacing those calls with synthetic external imports produces adversarial examples that induce misclassification while preserving overall program structure, as shown by reliable evasion on small- and large-scale PE datasets.
What carries the argument
Explainability-guided perturbation using integrated gradients attributions to select and replace influential function-call tokens in sequences obtained by linearizing control flow graphs.
Load-bearing premise
Linearizing control flow graphs into sequences of function calls creates token-level sensitivities that targeted replacements can exploit without changing the program's overall behavior.
What would settle it
A retrained model that incorporates adversarial examples generated by the same integrated-gradients replacement procedure and still resists misclassification would falsify the claim that the attack reliably succeeds.
Figures

read the original abstract
Transformer-based malware detection systems operating on graph modalities such as control flow graphs (CFGs) achieve strong performance by modeling structural relationships in program behavior. However, their robustness to adversarial evasion attacks remains underexplored. This paper examines the vulnerability of a RoBERTa-based malware detector that linearizes CFGs into sequences of function calls, a design choice that enables transformer modeling but may introduce token-level sensitivities and ordering artifacts exploitable by adversaries. By evaluating evasion strategies within this graph-to-sequence framework, we provide insight into the practical robustness of transformer-based malware detectors beyond aggregate detection accuracy. This paper proposes a white-box adversarial evasion attack that leverages explainability mechanisms to identify and perturb most influential graph components. Using token- and word-level attributions derived from integrated gradients, the attack iteratively replaces positively attributed function calls with synthetic external imports, producing adversarial CFG representations without altering overall program structure. Experimental evaluation on small- and large-scale Windows Portable Executable (PE) datasets demonstrates that the proposed method can reliably induce misclassification, even against models trained to high accuracy. Our results highlight that explainability tools, while valuable for interpretability, can also expose critical attack surfaces in transformer-based malware detectors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a white-box adversarial evasion attack against a RoBERTa-based malware detector that linearizes control-flow graphs (CFGs) from Windows PE binaries into sequences of function calls. The attack uses integrated-gradients attributions to identify positively influential tokens and iteratively replaces them with synthetic external imports, producing perturbed sequences that preserve overall program structure. Experiments on small- and large-scale PE datasets are reported to show reliable misclassification even against high-accuracy models, highlighting that explainability tools can expose attack surfaces in graph-to-sequence transformer detectors.
Significance. If the quantitative results hold, the work is significant because it supplies a concrete, explainability-guided attack that exploits the linearization step common to many transformer-based malware detectors. It thereby supplies a falsifiable test of robustness for an increasingly popular modeling choice and supplies a practical method that future defense papers can use as a baseline.
major comments (2)
- [Abstract and §4] Abstract and §4 (results): the central claim that the method 'reliably induce[s] misclassification' is load-bearing yet unsupported by any reported success rates, number of attacked samples, dataset statistics, or comparison to non-explainability baselines; without these numbers the experimental evaluation cannot be assessed.
- [§3.2] §3.2 (attack construction): the claim that replacements with synthetic imports preserve overall program structure is asserted but not demonstrated; the paper must show that the resulting binaries remain executable and functionally equivalent, otherwise the attack is not realizable and the practical significance is overstated.
minor comments (2)
- [Figure 2 and §4.1] Figure 2 and §4.1: axis labels and legend entries are too small to read; enlarge fonts and add a caption that states the exact perturbation budget used.
- [§2] Notation: the symbols for token attribution (e.g., IG(v)) and replacement function are introduced without a consolidated table; add a short notation table in §2.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which will help improve the clarity and rigor of our paper. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): the central claim that the method 'reliably induce[s] misclassification' is load-bearing yet unsupported by any reported success rates, number of attacked samples, dataset statistics, or comparison to non-explainability baselines; without these numbers the experimental evaluation cannot be assessed.
Authors: We agree with this observation. Upon review, the manuscript does include some experimental details in §4, but they lack the specific quantitative metrics mentioned. In the revised version, we will explicitly report success rates (such as the fraction of adversarial examples that cause misclassification), the exact number of samples attacked, full dataset statistics, and comparisons against non-explainability baselines like random perturbation. These will be added to both the abstract and the results section to support the central claim. revision: yes
-
Referee: [§3.2] §3.2 (attack construction): the claim that replacements with synthetic imports preserve overall program structure is asserted but not demonstrated; the paper must show that the resulting binaries remain executable and functionally equivalent, otherwise the attack is not realizable and the practical significance is overstated.
Authors: This is a valid point. The current manuscript asserts preservation of program structure based on the nature of the perturbations (replacing function calls with synthetic imports without changing control flow edges), but does not provide empirical validation. We will revise §3.2 to include demonstrations, such as verification that the modified CFGs correspond to executable binaries on a sample of cases, and discuss any limitations in achieving functional equivalence. If full equivalence cannot be guaranteed for all cases, we will qualify the claims accordingly. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical proposal for an explainability-guided adversarial attack on a RoBERTa-based malware detector operating on linearized CFGs. No mathematical derivations, equations, fitted parameters, or first-principles results are described that could reduce to the inputs by construction. The central claims rest on experimental evaluations of misclassification rates on PE datasets, which are independent of the attack construction. The linearization step is presented as an explicit design choice creating exploitable artifacts rather than a self-referential definition. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using token- and word-level attributions derived from integrated gradients, the attack iteratively replaces positively attributed function calls with synthetic external imports
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RoBERTa-based malware detector that linearizes CFGs into sequences of function calls
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Android malware detection using control flow graphs and text analysis,
A. Muzaffar, A. H. Riaz, and H. Ragab Hassen, “Android malware detection using control flow graphs and text analysis,” inProceedings of the International Conference on Applied Cybersecurity (ACS) 2023, H. Zantout and H. Ragab Hassen, Eds., 2023
work page 2023
-
[2]
Technique for IoT malware detection based on control flow graph analysis,
K. Bobrovnikova, S. Lysenko, B. Savenko, P. Gaj, and O. Savenko, “Technique for IoT malware detection based on control flow graph analysis,”RADIOELECTRONIC AND COMPUTER SYSTEMS, no. 1, pp. 141–153, Feb. 2022. [Online]. Available: http://nti.khai.edu/ojs/ index.php/reks/article/view/reks.2022.1.11
work page 2022
-
[3]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All You Need,” Aug. 2023, arXiv:1706.03762 [cs]. [Online]. Available: http://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Z. Ma, H. Ge, Y . Liu, M. Zhao, and J. Ma, “A Combination Method for Android Malware Detection Based on Control Flow Graphs and Machine Learning Algorithms,”IEEE Access, vol. 7, pp. 21 235–21 245, 2019. [Online]. Available: https://ieeexplore.ieee.org/document/8629067/
-
[5]
Adversarial malware binaries: Evading deep learning for malware detection in executables,
B. Kolosnjaji, A. Demontis, B. Biggio, D. Maiorca, G. Giacinto, C. Eckert, and F. Roli, “Adversarial malware binaries: Evading deep learning for malware detection in executables,” in2018 26th European signal processing conference (EUSIPCO). IEEE, 2018, pp. 533–537
work page 2018
-
[6]
A survey on adversarial attacks for malware analysis,
K. Aryal, M. Gupta, M. Abdelsalam, P. Kunwar, and B. Thuraisingham, “A survey on adversarial attacks for malware analysis,”IEEE Access, vol. 13, pp. 428–459, 2024
work page 2024
-
[7]
Explainability guided adversarial evasion attacks on malware detectors,
K. Aryal, M. Gupta, M. Abdelsalam, and M. Saleh, “Explainability guided adversarial evasion attacks on malware detectors,” in2024 33rd International Conference on Computer Communications and Networks (ICCCN). IEEE, 2024, pp. 1–9
work page 2024
-
[8]
Intra-section code cave injection for adversarial evasion attacks on windows pe malware file,
——, “Intra-section code cave injection for adversarial evasion attacks on windows pe malware file,”Computers & Security, p. 104690, 2025
work page 2025
-
[9]
Malware Detection by Eating a Whole EXE,
E. Raff, J. Barker, J. Sylvester, R. Brandon, B. Catanzaro, and C. Nicholas, “Malware Detection by Eating a Whole EXE,” Oct. 2017, arXiv:1710.09435 [stat]. [Online]. Available: http://arxiv.org/abs/1710. 09435
-
[10]
A Generative Adversarial Network Based Approach to Malware Generation Based on Behavioural Graphs,
R. A. J. McLaren, K. O. Babaagba, and Z. Tan, “A Generative Adversarial Network Based Approach to Malware Generation Based on Behavioural Graphs,” inMachine Learning, Optimization, and Data Science, G. Nicosia, V . Ojha, E. La Malfa, G. La Malfa, P. Pardalos, G. Di Fatta, G. Giuffrida, and R. Umeton, Eds. Cham: Springer Nature Switzerland, 2023, vol. 1381...
-
[11]
K. K. W. Yan, J. Suaboot, M. Puongmanee, and W. Werapun, “LiteXGNN: A Lightweight Explainable Graph Neural Network for Malware Detection with Control Flow Graph Explainability,” in2025 9th International Conference on Information Technology (InCIT). Phuket, Thailand: IEEE, Nov. 2025, pp. 658–664. [Online]. Available: https://ieeexplore.ieee.org/document/11276013/
-
[12]
On the consistency of GNN explanations for malware detection,
H. Shokouhinejad, G. Higgins, R. Razavi-Far, H. Mohammadian, and A. A. Ghorbani, “On the consistency of GNN explanations for malware detection,”Information Sciences, vol. 721, p. 122603, Dec
-
[13]
Available: https://linkinghub.elsevier.com/retrieve/pii/ S0020025525007364
[Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/ S0020025525007364
-
[14]
Enhancing android malware detection explainability through function call graph APIs,
D. Soi, A. Sanna, D. Maiorca, and G. Giacinto, “Enhancing android malware detection explainability through function call graph APIs,” Journal of Information Security and Applications, vol. 80, p. 103691, Feb. 2024. [Online]. Available: https://linkinghub.elsevier.com/retrieve/ pii/S2214212623002752
work page 2024
-
[15]
J. Govea, R. Gutierrez, W. Villegas-Ch, and A. Maldonado Navarro, “Hybrid AI for Predictive Cyber Risk Assessment: Federated Graph-Transformer Architecture With Explainability,”IEEE Access, vol. 13, pp. 122 187–122 206, 2025. [Online]. Available: https: //ieeexplore.ieee.org/document/11077151/
-
[16]
Graphene: Leveraging Transform- ers with Control Flow Modalities for Malware Detection,
A. Wheeler, K. Aryal, and M. Gupta, “Graphene: Leveraging Transform- ers with Control Flow Modalities for Malware Detection,” in5th IEEE International Conference on AI in Cybersecurity (ICAIC). Houston, TX, United States: IEEE, 2026
work page 2026
-
[17]
Subgraph-Based Adversarial Examples Against Graph-Based IoT Malware Detection Systems,
A. Abusnaina, H. Alasmary, M. Abuhamad, S. Salem, D. Nyang, and A. Mohaisen, “Subgraph-Based Adversarial Examples Against Graph-Based IoT Malware Detection Systems,” inComputational Data and Social Networks, A. Tagarelli and H. Tong, Eds. Cham: Springer International Publishing, 2019, vol. 11917, pp. 268–281, series Title: Lecture Notes in Computer Scienc...
-
[18]
Shield Broken: Black-Box Adversarial Attacks on LLM-Based Vulnerability Detectors,
Y . Jiang, S. Huang, C. Treude, X. Su, and T. Wang, “Shield Broken: Black-Box Adversarial Attacks on LLM-Based Vulnerability Detectors,”IEEE Transactions on Software Engineering, vol. 52, no. 1, pp. 246–265, Jan. 2026. [Online]. Available: https://ieeexplore.ieee.org/ document/11271845/
-
[19]
Sok: Leveraging transformers for malware analysis,
P. Kunwar, K. Aryal, M. Gupta, M. Abdelsalam, and E. Bertino, “Sok: Leveraging transformers for malware analysis,”IEEE Transactions on Dependable and Secure Computing, 2025
work page 2025
-
[20]
Explainability-informed targeted malware misclassification,
Q. Card, K. Aryal, and M. Gupta, “Explainability-informed targeted malware misclassification,” in2024 33rd International Conference on Computer Communications and Networks (ICCCN). IEEE, 2024, pp. 1–8
work page 2024
-
[21]
Meta Open Source, “Captum.” [Online]. Available: https://captum.ai/
-
[22]
PE malware machine learning dataset
M. Lester, “PE malware machine learning dataset.” [Online]. Available: https://practicalsecurityanalytics.com/ pe-malware-machine-learning-dataset/
- [23]
- [24]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.