Recognition: 2 theorem links
· Lean TheoremMultirate Stein Variational Gradient Descent for Efficient Bayesian Sampling
Pith reviewed 2026-05-13 17:09 UTC · model grok-4.3
The pith
Separating attraction and repulsion in SVGD onto independent time scales improves sampling stability and efficiency on complex posteriors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deriving a multirate version of SVGD that updates the attraction and repulsion components of the kernel update on different time scales, the method yields practical algorithms including a symmetric split integrator, a fixed multirate variant (MR-SVGD), and an adaptive variant (Adapt-MR-SVGD) with local error control; these preserve the original Stein variational objective while improving robustness and quality-cost tradeoffs across six benchmark families, with strongest gains on stiff hierarchical, strongly anisotropic, and multimodal targets.
What carries the argument
The multirate SVGD framework that decouples the attraction and repulsion forces for independent integration at different time scales.
If this is right
- Adaptive multirate SVGD usually outperforms vanilla SVGD in mixing speed and calibration on stiff hierarchical and multimodal problems.
- Fixed multirate SVGD supplies a simpler, lower-cost alternative that remains robust across the same problem families.
- The quality-cost tradeoff improves measurably on all six benchmark families when repulsion and attraction evolve at separate rates.
- Local error control in the adaptive variant further reduces wasted computation on regions that converge quickly.
Where Pith is reading between the lines
- The same separation principle could be tested on other particle methods such as Langevin dynamics or interacting particle systems where forces have mismatched natural time scales.
- The adaptive controller might extend naturally to sequential Bayesian updating where the posterior changes over time.
- In very high dimensions the computational saving from coarser repulsion steps could grow with the degree of anisotropy.
Load-bearing premise
The attraction and repulsion components of the SVGD kernel update can be separated and integrated on independent time scales while preserving the original Stein discrepancy minimization and convergence guarantees.
What would settle it
A concrete multimodal or hierarchical target where the decoupled multirate updates produce a particle distribution whose Stein discrepancy fails to decrease or whose empirical moments diverge from the true posterior.
Figures

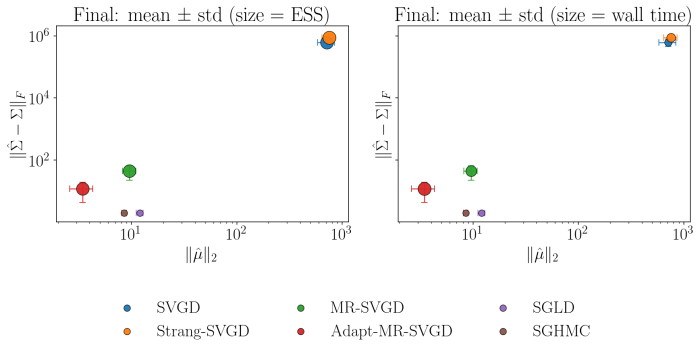


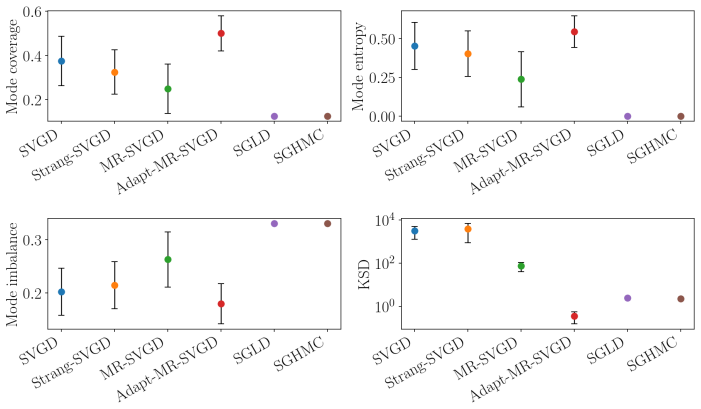
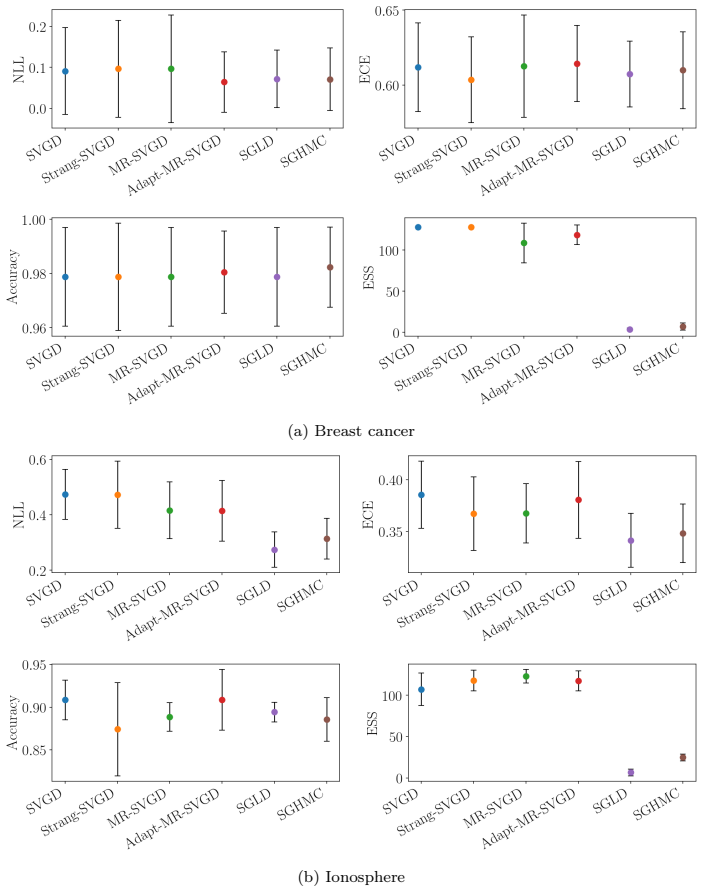


read the original abstract
Many particle-based Bayesian inference methods use a single global step size for all parts of the update. In Stein variational gradient descent (SVGD), however, each update combines two qualitatively different effects: attraction toward high-posterior regions and repulsion that preserves particle diversity. These effects can evolve at different rates, especially in high-dimensional, anisotropic, or hierarchical posteriors, so one step size can be unstable in some regions and inefficient in others. We derive a multirate version of SVGD that updates these components on different time scales. The framework yields practical algorithms, including a symmetric split method, a fixed multirate method (MR-SVGD), and an adaptive multirate method (Adapt-MR-SVGD) with local error control. We evaluate the methods in a broad and rigorous benchmark suite covering six problem families: a 50D Gaussian target, multiple 2D synthetic targets, UCI Bayesian logistic regression, multimodal Gaussian mixtures, Bayesian neural networks, and large-scale hierarchical logistic regression. Evaluation includes posterior-matching metrics, predictive performance, calibration quality, mixing, and explicit computational cost accounting. Across these six benchmark families, multirate SVGD variants improve robustness and quality-cost tradeoffs relative to vanilla SVGD. The strongest gains appear on stiff hierarchical, strongly anisotropic, and multimodal targets, where adaptive multirate SVGD is usually the strongest variant and fixed multirate SVGD provides a simpler robust alternative at lower cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a multirate extension of Stein Variational Gradient Descent (SVGD) by splitting the attraction (score-weighted) and repulsion (kernel-gradient) terms of the update into components that can be integrated on independent timescales. It introduces three algorithms—a symmetric split integrator, fixed multirate SVGD (MR-SVGD), and adaptive multirate SVGD (Adapt-MR-SVGD) with local error control—and evaluates them on six benchmark families (50D Gaussian, 2D synthetic targets, UCI logistic regression, Gaussian mixtures, Bayesian neural nets, and large-scale hierarchical logistic regression) using posterior-matching, predictive, calibration, mixing, and cost metrics. The central empirical claim is that the multirate variants improve robustness and quality-cost trade-offs over vanilla SVGD, with largest gains on stiff, anisotropic, and multimodal targets.
Significance. If the splitting preserves the original SVGD stationary distribution and Stein-discrepancy descent property, the framework offers a practical route to more stable particle-based sampling on challenging posteriors without introducing new fitted parameters. The breadth of the benchmark suite (six distinct problem families with explicit cost accounting) and the distinction between fixed and adaptive variants provide concrete evidence of improved robustness on the very targets where single-step-size SVGD is known to struggle.
major comments (2)
- [Abstract and derivation] Abstract and derivation (no numbered section provided): the claim that the multirate splitting preserves the Stein discrepancy minimization and convergence guarantees of SVGD is not supported by any derivation or error bound. The Stein operator is defined on the sum of the two vector fields; separating them onto independent timescales (symmetric, fixed, or adaptive) requires showing that the composite flow still decreases the discrepancy or converges to the target measure, yet no such analysis appears.
- [Benchmark section] Benchmark section (no numbered section provided): the reported gains on stiff hierarchical and multimodal targets rest on the assumption that the split integrator remains a valid Stein variational gradient. Because this assumption is least secure precisely where the largest improvements are claimed, the empirical results cannot be interpreted as confirming the method’s correctness without the missing theoretical control.
minor comments (2)
- [Algorithm descriptions] Clarify the precise definition and initialization of the two distinct time-step parameters in the algorithm pseudocode so that readers can reproduce the fixed and adaptive variants exactly.
- [Experimental tables] Add explicit step-size tuning protocols and wall-clock cost breakdowns for all baselines in the experimental tables to strengthen the quality-cost tradeoff claims.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the concerns about missing theoretical analysis below, clarifying the scope of our claims and outlining revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and derivation] Abstract and derivation (no numbered section provided): the claim that the multirate splitting preserves the Stein discrepancy minimization and convergence guarantees of SVGD is not supported by any derivation or error bound. The Stein operator is defined on the sum of the two vector fields; separating them onto independent timescales (symmetric, fixed, or adaptive) requires showing that the composite flow still decreases the discrepancy or converges to the target measure, yet no such analysis appears.
Authors: We acknowledge that the current manuscript does not contain a formal derivation or error bounds establishing that the multirate splitting exactly preserves the Stein discrepancy descent property or global convergence guarantees of standard SVGD. The derivation focuses on the additive decomposition of the SVGD update into attraction and repulsion terms and their integration on separate timescales, which is consistent with the original flow when the timescales coincide (as in the symmetric split case). For unequal timescales we make no such claim. We will revise the abstract, introduction, and method sections to remove any implication of preserved theoretical guarantees, explicitly state the empirical nature of the contribution, and add a dedicated paragraph on theoretical limitations together with directions for future analysis. revision: partial
-
Referee: [Benchmark section] Benchmark section (no numbered section provided): the reported gains on stiff hierarchical and multimodal targets rest on the assumption that the split integrator remains a valid Stein variational gradient. Because this assumption is least secure precisely where the largest improvements are claimed, the empirical results cannot be interpreted as confirming the method’s correctness without the missing theoretical control.
Authors: We agree that the largest observed gains occur on the targets where the validity of the splitting is most in question. We will expand the benchmark discussion to include additional diagnostics (e.g., comparison of final particle distributions and Stein discrepancy values against vanilla SVGD on simpler targets) and will add explicit caveats stating that the reported improvements are empirical demonstrations of robustness and efficiency rather than confirmation of theoretical equivalence. These changes will allow readers to interpret the results in light of the acknowledged theoretical gap. revision: yes
- A rigorous proof or error bound showing that the composite multirate flow preserves the Stein discrepancy minimization property for arbitrary timescale ratios.
Circularity Check
No significant circularity; derivation is a direct algebraic split of the standard SVGD update
full rationale
The multirate framework is obtained by explicit decomposition of the existing SVGD particle update into attraction (score-weighted) and repulsion (kernel-gradient) components, which are then integrated on separate timescales. This split is presented as a modeling choice rather than a fitted parameter or self-referential prediction. No load-bearing step reduces to a self-citation chain, an ansatz smuggled from prior work by the same authors, or a uniqueness theorem imported from the authors themselves. The reported gains are evaluated on independent benchmark families using standard posterior-matching, predictive, and calibration metrics, with explicit cost accounting. The central claim therefore remains empirically falsifiable and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The SVGD particle update can be decomposed into independent attraction and repulsion terms that may be integrated on separate time scales.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive a multirate version of SVGD that updates these components on different time scales... ˙x = f_rep(x) + f_drift(x)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Welling, Y. W. Teh, Bayesian learning via stochastic gradient langevin dynamics, in: International Conference on Machine Learning, 2011
work page 2011
-
[2]
T. Chen, E. Fox, C. Guestrin, Stochastic gradient hamiltonian monte carlo, in: International Conference on Machine Learning, 2014
work page 2014
-
[3]
C. Liu, J. Zhuo, P. Cheng, R. Zhang, J. Zhu, Understanding and accelerating particle-based variational inference, in: K. Chaudhuri, 2https://github.com/csml-beach/multirate-sampling 20 R. Salakhutdinov (Eds.), Proceedings of the 36th International Confer- ence on Machine Learning, Vol. 97 of Proceedings of Machine Learning Research, PMLR, 2019, pp. 4082–4...
work page 2019
-
[4]
J. Zhuo, C. Liu, J. Shi, J. Zhu, N. Chen, B. Zhang, Message passing stein variational gradient descent, in: J. Dy, A. Krause (Eds.), Proceedings of the 35th International Conference on Machine Learning, Vol. 80 of Proceedings of Machine Learning Research, PMLR, 2018, pp. 6018– 6027. URLhttps://proceedings.mlr.press/v80/zhuo18a.html
work page 2018
-
[5]
D. Wang, Z. Tang, C. Bajaj, Q. Liu, Stein variational gradient descent with matrix-valued kernels, in: Advances in Neural Information Pro- cessing Systems, 2019
work page 2019
-
[6]
A. N. Subrahmanya, A. A. Popov, A. Sandu, Ensem- ble variational fokker-planck methods for data assimila- tion, Journal of Computational Physics 523 (2025) 113681. doi:https://doi.org/10.1016/j.jcp.2024.113681
-
[7]
Q. Liu, D. Wang, Stein variational gradient descent: A general pur- pose bayesian inference algorithm, in: Advances in Neural Information Processing Systems, 2016
work page 2016
-
[8]
J. Zhang, R. Zhang, L. Carin, C. Chen, Stochastic particle-optimization sampling and the non-asymptotic convergence theory, in: S. Chiappa, R. Calandra (Eds.), Proceedings of the Twenty Third International Con- ference on Artificial Intelligence and Statistics, Vol. 108 of Proceedings of Machine Learning Research, PMLR, 2020, pp. 1877–1887. URLhttps://pro...
work page 2020
-
[9]
L. Pareschi, G. Russo, Implicit-explicit Runge-Kutta schemes for stiff systemsofdifferentialequations, in: Recenttrendsinnumericalanalysis, Nova Science Publishers, Inc., 2000, pp. 269–288
work page 2000
-
[10]
A. Sarshar, S. Roberts, A. Sandu, Parallel implicit-explicit general linear methods, Communications on Applied Mathematics and Computation 3 (2021) 649–669. doi:10.1007/s42967-020-00083-5. 21
-
[11]
M. Günther, A. Sandu, Multirate generalized additive Runge- Kutta methods, Numerische Mathematik 133 (3) (2016) 497–524. doi:10.1007/s00211-015-0756-z
-
[12]
A. Sarshar, S. Roberts, A. Sandu, Design of high-order decoupled multi- rate gark schemes, SIAM Journal on Scientific Computing 41 (2) (2019) A816–A847. doi:10.1137/18M1182875
-
[13]
A. Sandu, M. Günther, S. Roberts, A. Sarshar, Implicit multi- rate gark methods, Journal of Scientific Computing 87 (2021) 1–32. doi:10.1007/s10915-020-01400-z
-
[14]
A. Sarshar, S. Roberts, A. Sandu, Alternating directions im- plicit integration in a general linear method framework, Journal of Computational and Applied Mathematics 387 (2021) 112496. doi:10.1016/j.cam.2019.112496
-
[15]
A. Sarshar, S. Roberts, A. Sandu, A fast time-stepping strat- egy for dynamical systems equipped with a surrogate model, SIAM Journal on Scientific Computing 44 (3) (2022) A1405–A1430. doi:10.1137/20M1386281
-
[16]
G. Strang, On the construction and comparison of difference schemes, SIAM Journal on Numerical Analysis 5 (3) (1968) 506–517
work page 1968
-
[17]
E. Hairer, S. Norsett, G. Wanner, Solving ordinary differential equations I: Nonstiff problems, no. 8 in Springer Series in Computational Mathe- matics, Springer-Verlag Berlin Heidelberg, 1993. doi:10.1007/978-3-540- 78862-1
-
[18]
Q. Liu, J. Lee, M. Jordan, A kernelized stein discrepancy for goodness- of-fit tests, in: International Conference on Machine Learning, 2016
work page 2016
-
[19]
J. Gorham, L. Mackey, Measuring sample quality with kernels, in: D. Precup, Y. W. Teh (Eds.), Proceedings of the 34th International Conference on Machine Learning, Vol. 70 of Proceedings of Machine Learning Research, PMLR, 2017, pp. 1292–1301. URLhttps://proceedings.mlr.press/v70/gorham17a.html
work page 2017
-
[20]
C. J. Geyer, Practical markov chain monte carlo, Statistical Science 7 (4) (1992) 473–483. doi:10.1214/ss/1177011137. 22
-
[21]
A. S. Stordal, R. J. Moraes, P. N. Raanes, G. Evensen, p-kernel stein variational gradient descent for data assimilation and history matching, Mathematical Geosciences 53 (2021) 375–393. doi:10.1007/s11004-021- 09937-x
-
[22]
D. Dua, C. Graff, Uci machine learning repository,https://archive. ics.uci.edu/ml, accessed 2025-01-01 (2019). 23 (a) Banana. (b) Squiggly. (c) Two moons. (d) Ring. Figure 3: 2D target visualization panels produced with Adapt-MR-SVGD under visualization-only settings. Each subfigure shows target-density contours with initial par- ticles (left) and short-r...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.