Recognition: no theorem link
A Systematic Study of Cross-Modal Typographic Attacks on Audio-Visual Reasoning
Pith reviewed 2026-05-13 17:30 UTC · model grok-4.3
The pith
Coordinated typographic attacks across audio, visual and text modalities raise attack success rates on audio-visual MLLMs from 35% to 83%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that coordinated multi-modal typography attacks—simultaneous typographic perturbations in audio, visual, and text—produce an 83.43% attack success rate on frontier audio-visual MLLMs, more than double the 34.93% rate of single-modality attacks, across common-sense reasoning and content-moderation tasks.
What carries the argument
Multi-Modal Typography: the systematic combination of typographic perturbations applied jointly across audio, visual, and text inputs to exploit cross-modal interactions inside MLLMs.
If this is right
- Single-modality robustness evaluations systematically underestimate risk to audio-visual MLLMs.
- Coordinated attacks remain effective across multiple frontier models and both reasoning and moderation benchmarks.
- Multi-modal typography constitutes a distinct and underexplored attack vector for audio-visual reasoning systems.
- Safety assessments of deployed MLLMs must include joint perturbations rather than isolated ones.
Where Pith is reading between the lines
- Defense design for MLLMs should target cross-modal consistency checks instead of per-modality filters.
- The same coordination principle may apply to other multi-modal architectures that fuse audio and visual streams.
- Real-world red-teaming protocols would benefit from including synchronized typographic overlays in audio-visual inputs.
- Model scaling alone is unlikely to close this gap without explicit multi-modal robustness training.
Load-bearing premise
The specific typographic perturbations tested are representative of realistic attacks and the chosen benchmarks accurately reflect vulnerabilities in safety-critical applications.
What would settle it
A controlled test in which the same coordinated multi-modal perturbations yield no higher success rate than the best single-modality perturbation on identical benchmarks would falsify the claim.
Figures


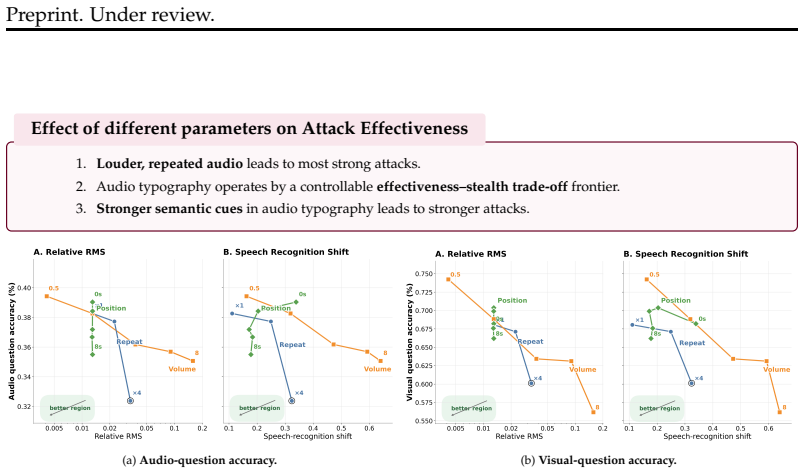










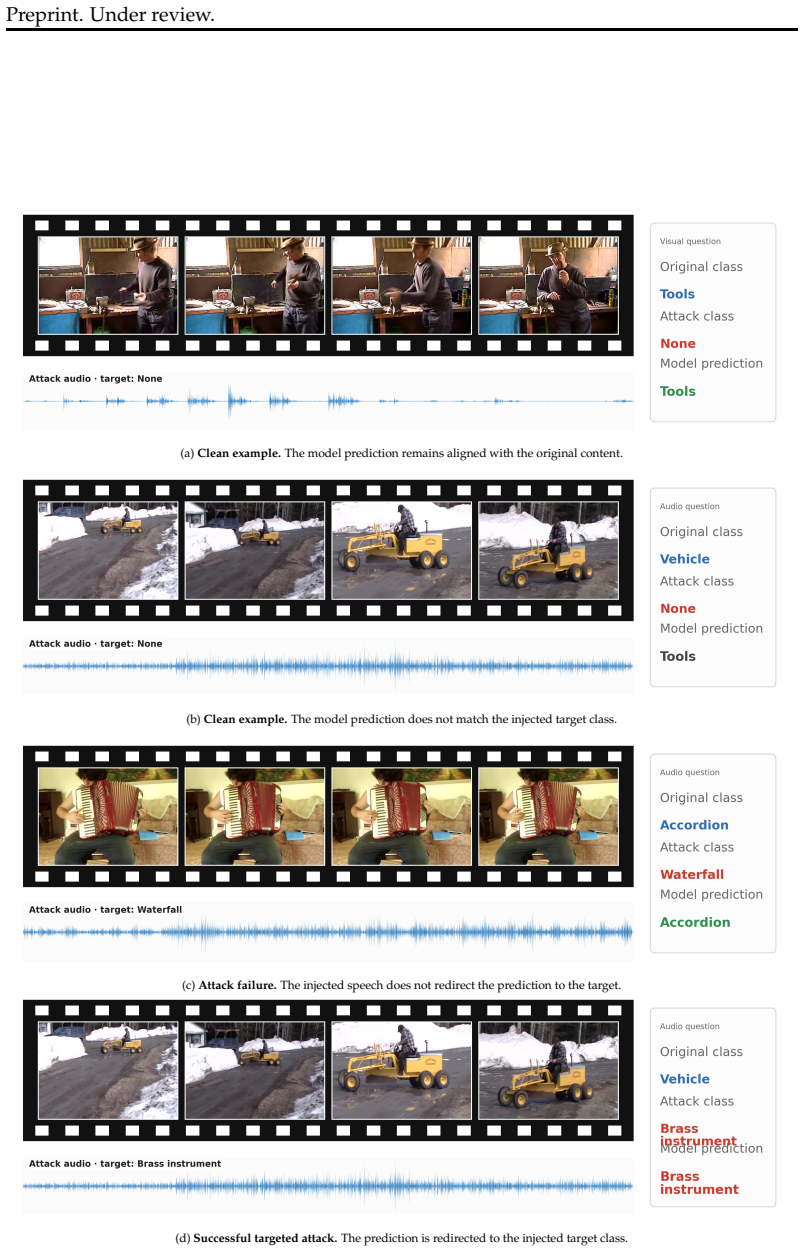

read the original abstract
As audio-visual multi-modal large language models (MLLMs) are increasingly deployed in safety-critical applications, understanding their vulnerabilities is crucial. To this end, we introduce Multi-Modal Typography, a systematic study examining how typographic attacks across multiple modalities adversely influence MLLMs. While prior work focuses narrowly on unimodal attacks, we expose the cross-modal fragility of MLLMs. We analyze the interactions between audio, visual, and text perturbations and reveal that coordinated multi-modal attack creates a significantly more potent threat than single-modality attacks (attack success rate = $83.43\%$ vs $34.93\%$).Our findings across multiple frontier MLLMs, tasks, and common-sense reasoning and content moderation benchmarks establishes multi-modal typography as a critical and underexplored attack strategy in multi-modal reasoning. Code and data will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Multi-Modal Typography, a systematic empirical study of typographic attacks applied across audio, visual, and text modalities to audio-visual MLLMs. It reports that coordinated multi-modal attacks achieve an 83.43% attack success rate, substantially higher than the 34.93% rate for single-modality attacks, and concludes that this establishes multi-modal typography as a critical and underexplored threat to multi-modal reasoning on common-sense and content-moderation benchmarks.
Significance. If the central empirical comparison holds under proper controls for attack budget, the work would identify a practically relevant vulnerability in frontier MLLMs deployed for safety-critical tasks. The planned public release of code and data would constitute a concrete strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that coordinated multi-modal attacks create a 'significantly more potent threat' (83.43% vs 34.93%) is load-bearing for the paper's central conclusion, yet the reported comparison does not demonstrate that the multi-modal attack exceeds the union of the strongest independently optimized unimodal attacks under matched total perturbation strength or search effort. Without this control the gap may be additive rather than interactive.
- [Results] Results (and abstract): concrete success rates are stated without accompanying details on experimental controls, statistical tests, error bars, or data-exclusion criteria, which directly limits verification of the headline ASR numbers.
minor comments (1)
- [Abstract] Abstract: the final sentence contains a subject-verb agreement error ('establishes' should be 'establish').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and revise the manuscript to strengthen the empirical claims and reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that coordinated multi-modal attacks create a 'significantly more potent threat' (83.43% vs 34.93%) is load-bearing for the paper's central conclusion, yet the reported comparison does not demonstrate that the multi-modal attack exceeds the union of the strongest independently optimized unimodal attacks under matched total perturbation strength or search effort. Without this control the gap may be additive rather than interactive.
Authors: We appreciate this point. The single-modality baselines in the current experiments were optimized independently per modality before coordination in the multi-modal setting. To demonstrate that the improvement is interactive rather than merely additive, we will add new experiments that enforce a matched total perturbation budget (e.g., equal total number of perturbed tokens and search iterations) and explicitly compare the coordinated multi-modal attack against the union of the strongest unimodal attacks. These controlled results will be reported in the revised Results section and abstract. revision: yes
-
Referee: [Results] Results (and abstract): concrete success rates are stated without accompanying details on experimental controls, statistical tests, error bars, or data-exclusion criteria, which directly limits verification of the headline ASR numbers.
Authors: We agree that additional methodological detail is required. In the revised manuscript we will expand the experimental setup and Results sections to include: full specification of controls and hyperparameters, error bars computed over multiple independent runs, statistical significance tests (e.g., paired t-tests with p-values), and explicit data-exclusion criteria. These additions will enable direct verification of the reported attack success rates. revision: yes
Circularity Check
Empirical attack success rates reported without derivation or self-referential reduction
full rationale
The paper is an empirical study measuring attack success rates (ASR) on audio-visual MLLMs under typographic perturbations. The headline result (83.43% coordinated multi-modal ASR vs 34.93% single-modality) is obtained by running attacks on chosen benchmarks and directly reporting observed percentages. No equations, fitted parameters, or self-citations are used to derive this from prior results by construction. The comparison may raise validity questions about attack budgets, but the reported numbers do not reduce to inputs via self-definition, renaming, or load-bearing self-citation. This is standard experimental reporting with no circular chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in adversarial machine learning hold, including that input perturbations can be applied without detection and that success is measured by output change on benchmark tasks.
Reference graph
Works this paper leans on
-
[1]
Tianle Chen, Chaitanya Chakka, Arjun Reddy Akula, Xavier Thomas, and Deepti Ghadi- yaram. Some modalities are more equal than others: Decoding and architecting multi- modal integration in mllms.arXiv preprint arXiv:2511.22826,
-
[2]
Hao Cheng, Erjia Xiao, Jindong Gu, Le Yang, Jinhao Duan, Jize Zhang, Jiahang Cao, Kaidi Xu, and Renjing Xu. Unveiling typographic deceptions: Insights of the typographic vulnerability in large vision-language models. InEuropean Conference on Computer Vision, pp. 179–196. Springer, 2024a. Hao Cheng, Erjia Xiao, Jiayan Yang, Jiahang Cao, Qiang Zhang, Le Yan...
-
[3]
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326,
-
[4]
10 Preprint. Under review. Guanyu Hou, Jiaming He, Yinhang Zhou, Ji Guo, Yitong Qiao, Rui Zhang, and Wenbo Jiang. Evaluating robustness of large audio language models to audio injection: An empirical study. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 25671–25687,
work page 2025
-
[5]
Towards mechanistic defenses against typographic attacks in clip.arXiv preprint arXiv:2508.20570,
Lorenz Hufe, Constantin Venhoff, Maximilian Dreyer, Sebastian Lapuschkin, and Wojciech Samek. Towards mechanistic defenses against typographic attacks in clip.arXiv preprint arXiv:2508.20570,
-
[6]
Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji-Rong Wen, and Di Hu
arXiv preprint arXiv:2408.03554. Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji-Rong Wen, and Di Hu. Learning to answer questions in dynamic audio-visual scenarios. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 19108–19118,
-
[7]
Physical prompt injection attacks on large vision-language models.arXiv preprint arXiv:2601.17383,
Chen Ling, Kai Hu, Hangcheng Liu, Xingshuo Han, Tianwei Zhang, and Changhai Ou. Physical prompt injection attacks on large vision-language models.arXiv preprint arXiv:2601.17383,
-
[8]
Voxtral.arXiv preprint arXiv:2507.13264,
Alexander H Liu, Andy Ehrenberg, Andy Lo, Cl´ement Denoix, Corentin Barreau, Guillaume Lample, Jean-Malo Delignon, Khyathi Raghavi Chandu, Patrick von Platen, Pavanku- mar Reddy Muddireddy, et al. Voxtral.arXiv preprint arXiv:2507.13264,
-
[9]
Maan Qraitem, Nazia Tasnim, Piotr Teterwak, Kate Saenko, and Bryan A Plummer. Vision-llms can fool themselves with self-generated typographic attacks.arXiv preprint arXiv:2402.00626, 2024a. Maan Qraitem, Piotr Teterwak, Kate Saenko, and Bryan A Plummer. Slant: Spurious logo analysis toolkit.arXiv preprint arXiv:2406.01449, 2024b. Maan Qraitem, Piotr Teter...
-
[10]
Multilingual and multi-accent jailbreaking of audio llms.arXiv preprint arXiv:2504.01094,
Jaechul Roh, Virat Shejwalkar, and Amir Houmansadr. Multilingual and multi-accent jailbreaking of audio llms.arXiv preprint arXiv:2504.01094,
-
[11]
11 Preprint. Under review. Lea Sch ¨onherr, Katharina Kohls, Steffen Zeiler, Thorsten Holz, and Dorothea Kolossa. Adversarial attacks against automatic speech recognition systems via psychoacoustic hiding.arXiv preprint arXiv:1808.05665,
-
[12]
Pandagpt: One model to instruction-follow them all.arXiv preprint arXiv:2305.16355, 2023
Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all.arXiv preprint arXiv:2305.16355,
-
[13]
Jiachen Sun, Changsheng Wang, Jiongxiao Wang, Yiwei Zhang, and Chaowei Xiao. Safe- guarding vision-language models against patched visual prompt injectors.arXiv preprint arXiv:2405.10529,
-
[14]
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. Avhbench: A cross-modal hallucination benchmark for audio-visual large language models.arXiv preprint arXiv:2410.18325,
-
[15]
Air-bench: Benchmarking large audio- language models via generative comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, et al. Air-bench: Benchmarking large audio- language models via generative comprehension. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1979–1998,
work page 1979
-
[16]
Ye Yu, Haibo Jin, Yaoning Yu, Jun Zhuang, and Haohan Wang. Now you hear me: Audio narrative attacks against large audio-language models.arXiv preprint arXiv:2601.23255,
-
[17]
Mllms are deeply affected by modality bias.arXiv preprint arXiv:2505.18657,
Xu Zheng, Chenfei Liao, Yuqian Fu, Kaiyu Lei, Yuanhuiyi Lyu, Lutao Jiang, Bin Ren, Jialei Chen, Jiawen Wang, Chengxin Li, et al. Mllms are deeply affected by modality bias.arXiv preprint arXiv:2505.18657,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.