Recognition: unknown
Profile-Then-Reason: Bounded Semantic Complexity for Tool-Augmented Language Agents
Pith reviewed 2026-05-13 16:58 UTC · model grok-4.3
The pith
Profile-Then-Reason bounds tool-augmented agent pipelines to two or three language-model calls by synthesizing an explicit workflow first.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
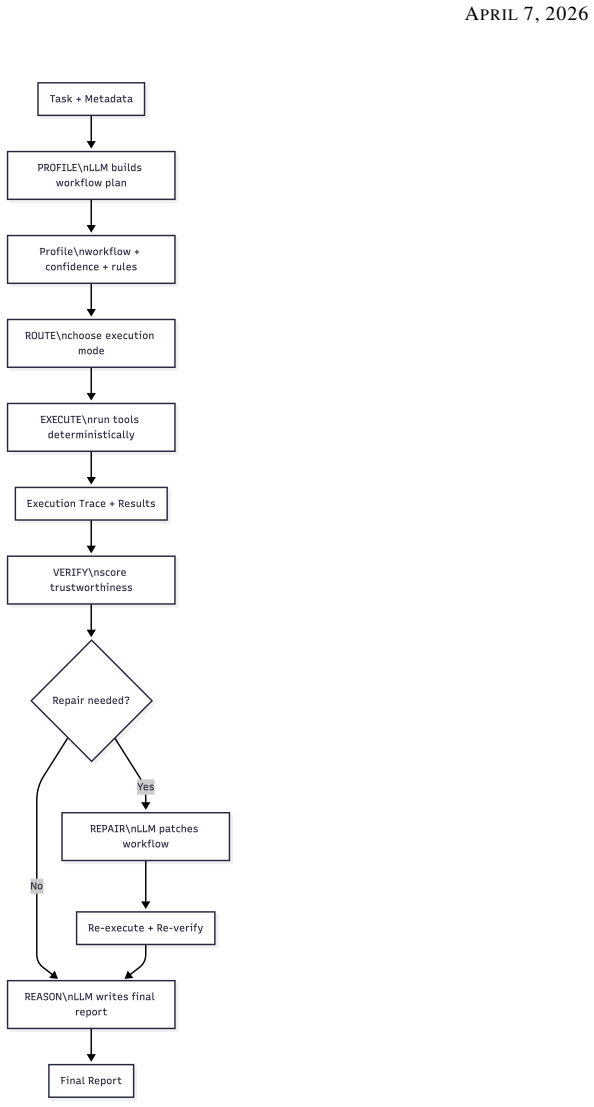
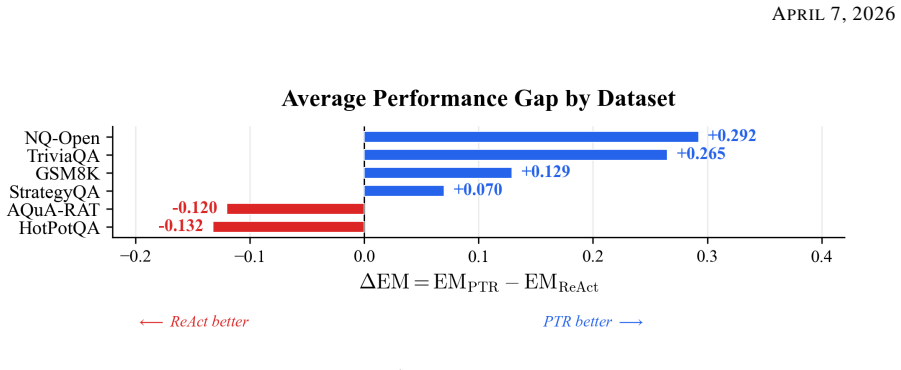
The full pipeline is expressed as a composition of profile, routing, execution, verification, repair, and reasoning operators; under bounded repair the number of language-model calls is restricted to two in the nominal case and three in the worst case. Experiments against a ReAct baseline on six benchmarks and four language models show that PTR achieves the pairwise exact-match advantage in 16 of 24 configurations. The results indicate that PTR is particularly effective on retrieval-centered and decomposition-heavy tasks, whereas reactive execution remains preferable when success depends on substantial online adaptation.
What carries the argument
The composition of profile, routing, execution, verification, repair, and reasoning operators that first produces an explicit workflow and then limits repair invocations.
If this is right
- The number of language-model calls stays at two in the nominal case and three in the worst case.
- PTR records the pairwise exact-match advantage in sixteen of twenty-four tested configurations.
- Performance gains are largest on retrieval-centered and decomposition-heavy tasks.
- Reactive execution stays preferable only when tasks require substantial online adaptation.
Where Pith is reading between the lines
- The separation of one-time planning from deterministic execution could be applied to other agent loops to reduce repeated model queries.
- Tasks that evolve rapidly after the initial profile step may still favor reactive methods even if the paper's benchmarks do not show this.
- Adding a mechanism to accept partial repairs instead of full re-profiling could lower average call counts further.
Load-bearing premise
The language model can reliably synthesize an explicit workflow in the profile step such that deterministic operators need repair only rarely across the tested tasks.
What would settle it
A new benchmark where PTR requires repair steps on more than one-third of runs or posts lower exact-match scores than ReAct would show the bounded-call claim does not hold.
Figures
read the original abstract
Large language model agents that use external tools are often implemented through reactive execution, in which reasoning is repeatedly recomputed after each observation, increasing latency and sensitivity to error propagation. This work introduces Profile--Then--Reason (PTR), a bounded execution framework for structured tool-augmented reasoning, in which a language model first synthesizes an explicit workflow, deterministic or guarded operators execute that workflow, a verifier evaluates the resulting trace, and repair is invoked only when the original workflow is no longer reliable. A mathematical formulation is developed in which the full pipeline is expressed as a composition of profile, routing, execution, verification, repair, and reasoning operators; under bounded repair, the number of language-model calls is restricted to two in the nominal case and three in the worst case. Experiments against a ReAct baseline on six benchmarks and four language models show that PTR achieves the pairwise exact-match advantage in 16 of 24 configurations. The results indicate that PTR is particularly effective on retrieval-centered and decomposition-heavy tasks, whereas reactive execution remains preferable when success depends on substantial online adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Profile-Then-Reason (PTR), a bounded execution framework for tool-augmented LM agents. An LM first synthesizes an explicit workflow via a profile operator; deterministic or guarded operators then execute it, a verifier evaluates the trace, and a repair operator is invoked only when the workflow is unreliable. The pipeline is formalized as a composition of profile, routing, execution, verification, repair, and reasoning operators, yielding a bound of two LM calls in the nominal case and three in the worst case under bounded repair. Experiments on six benchmarks against a ReAct baseline with four language models report that PTR achieves pairwise exact-match advantage in 16 of 24 configurations, with particular gains on retrieval-centered and decomposition-heavy tasks.
Significance. If the bounded-repair assumption holds empirically, the work supplies a concrete reduction in semantic complexity and latency for agent pipelines by replacing repeated reactive reasoning with a single profiled workflow plus limited repair. The operator-composition formulation is a clear strength, as it directly derives the call bound from the stated repair limit without additional free parameters. The reported advantage on 16/24 configurations suggests practical utility on structured tasks, though the significance depends on whether the latency guarantee is demonstrated rather than assumed.
major comments (1)
- [Abstract and Experiments] The central bounded-LM-call claim (abstract) rests on repair being invoked at most once per trace, yet the manuscript supplies neither a theorem establishing this limit from the operator definitions nor an empirical distribution of repair invocations across the six benchmarks. Without such measurement, the two/three-call guarantee remains conditional on an unverified assumption rather than demonstrated.
minor comments (2)
- The abstract and experimental description report advantages but omit benchmark definitions, statistical tests, error bars, and implementation details for the profile, verification, and repair operators, preventing full evaluation of the data support.
- Notation for the operator composition (profile, routing, execution, verification, repair, reasoning) is introduced without an explicit equation or diagram showing how the composition yields the exact call bound; adding this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The central concern regarding the bounded LM-call claim is well-taken; we address it directly by committing to strengthen the formal and empirical support for the repair bound in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central bounded-LM-call claim (abstract) rests on repair being invoked at most once per trace, yet the manuscript supplies neither a theorem establishing this limit from the operator definitions nor an empirical distribution of repair invocations across the six benchmarks. Without such measurement, the two/three-call guarantee remains conditional on an unverified assumption rather than demonstrated.
Authors: We acknowledge that the current manuscript does not include an explicit theorem deriving the call bound from the operator definitions or report the empirical frequency of repair invocations. The bound is stated as holding under the assumption of bounded repair (at most one invocation) as part of the pipeline composition in Section 3, where the profile operator is invoked once, execution and verification are deterministic, and repair is triggered at most once before any fallback reasoning. This structure is intended to enforce the limit by design. However, to address the referee's point rigorously, the revised manuscript will (1) add a formal theorem in Section 3 that derives the two/three-call bound directly from the operator composition and the single-repair limit, and (2) include a new table in the Experiments section reporting the observed frequency of repair invocations (as a percentage of traces) for each benchmark and model. These additions will make the guarantee both formally grounded and empirically verified rather than assumed. revision: yes
Circularity Check
No significant circularity in operator composition or call-bound claim
full rationale
The paper explicitly defines the PTR framework as a composition of profile, routing, execution, verification, repair, and reasoning operators, then states that under the bounded-repair condition the LM-call count is limited to two nominal or three worst-case. This limit follows directly from the definitional structure of the pipeline rather than from any data fitting, self-referential equation, or hidden ansatz. No load-bearing self-citations, uniqueness theorems, or renamed empirical patterns appear in the abstract or described formulation. The experimental results comparing exact-match performance against ReAct on six benchmarks supply independent empirical content. The bounded-repair premise is presented transparently as an assumption of the framework, not as a derived theorem that collapses back onto itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models can reliably synthesize explicit workflows in the profile step
Reference graph
Works this paper leans on
-
[1]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models.arXiv preprint arXiv:2201.11903, 2022. https://arxiv. org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022. https: //arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
S. Dhuliawala, M. Komeili, J. Xu, R. Raileanu, X. Li, A. Celikyilmaz, and J. Weston. Chain-of-verification reduces hallucination in large language models.arXiv preprint arXiv:2309.11495, 2023. https://arxiv.org/abs/ 2309.11495
-
[4]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need.arXiv preprint arXiv:1706.03762, 2017.https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023.https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
- [7]
- [8]
-
[9]
T. Bogavelli, R. Sharma, and H. Subramani. AgentArch: A comprehensive benchmark to evaluate agent architectures in enterprise.arXiv preprint arXiv:2509.10769, 2026.https://arxiv.org/abs/2509.10769
- [10]
-
[11]
S. Kim, S. Moon, R. Tabrizi, N. Lee, M. W. Mahoney, K. Keutzer, and A. Gholami. An LLM compiler for parallel function calling. InProceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 2024. https://doi.org/10.5555/3692070.3693047
-
[12]
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, M. Podstawski, L. Gianinazzi, J. Gajda, T. Lehmann, H. Niewiadomski, P. Nyczyk, and T. Hoefler. Graph of thoughts: Solving elaborate problems with large language models.Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):17682–17690, 2024. https: //doi.org/10.1609/aaai.v38i16.29720
- [13]
-
[14]
M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada, 2017. Association for Computational Linguistics.https://doi.org/10.1...
-
[15]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M.-W. Chang, A. M. Dai, J. Uszkoreit, Q. Le, and S. Petrov. Natural questions: A benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:452–466, 20...
-
[16]
M. Geva, D. Khashabi, E. Segal, T. Khot, D. Roth, and J. Berant. Did Aristotle use a laptop? A question answering benchmark with implicit reasoning strategies.Transactions of the Association for Computational Linguistics, 9:346–361, 2021.https://doi.org/10.1162/tacl_a_00370
-
[17]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021.https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
A. Amini, S. Gabriel, S. Lin, R. Koncel-Kedziorski, Y . Choi, and H. Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2...
-
[19]
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium, 2018. Association for Computational Linguistics.https://doi.org/10.1865...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.