Recognition: no theorem link
Learning Robust Visual Features in Computed Tomography Enables Efficient Transfer Learning for Clinical Tasks
Pith reviewed 2026-05-13 16:56 UTC · model grok-4.3
The pith
A self-distilled CT foundation model learns visual features that transfer efficiently to clinical tasks and outperform language-supervised models without any text supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VoxelFM is a 3D CT foundation model trained with self-distillation using the DINO framework to learn semantically rich features without language supervision. Evaluated using frozen backbone representations with lightweight probes on seven categories of clinically relevant downstream tasks—classification, regression, survival analysis, instance retrieval, localisation, segmentation, and report generation—VoxelFM matched or outperformed four existing CT foundation models. Notably, it surpassed models trained with language-alignment objectives, including on report generation.
What carries the argument
VoxelFM, the 3D vision model trained via DINO self-distillation on CT volumes to extract robust visual features for lightweight downstream probes.
Load-bearing premise
The seven task categories, chosen datasets, and lightweight probe evaluations are representative of clinical performance and allow fair model comparisons without backbone fine-tuning.
What would settle it
Observing a dataset or task where a language-supervised CT model with lightweight probes significantly outperforms VoxelFM would falsify the superiority claim.
Figures



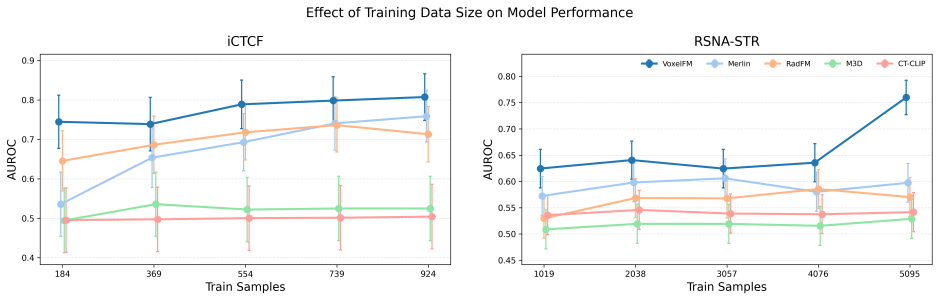
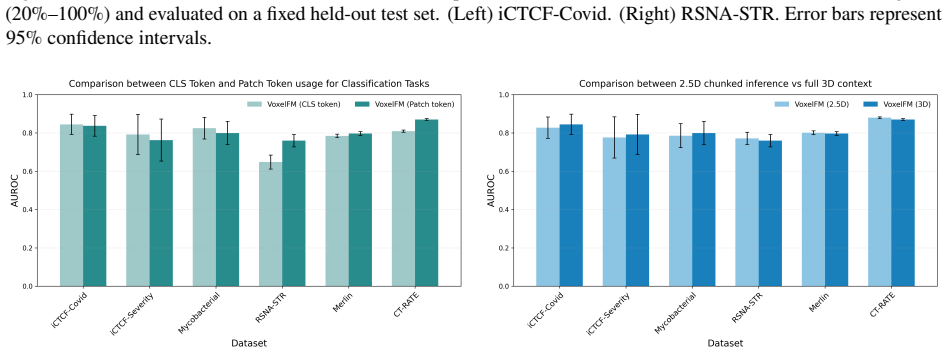
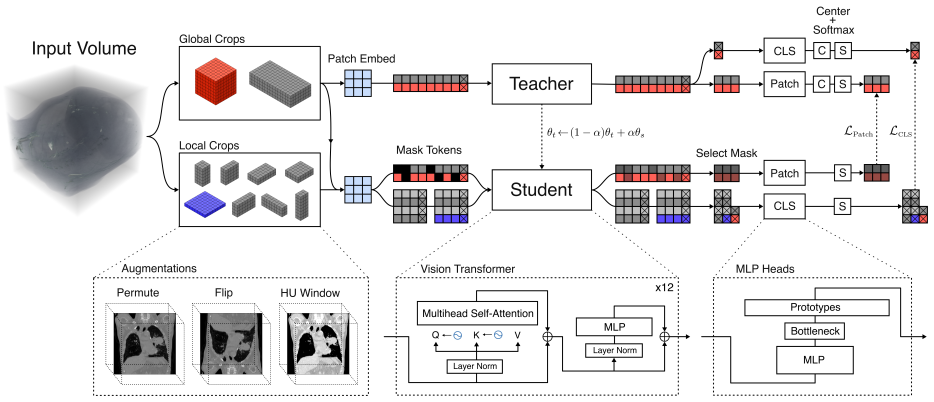
read the original abstract
There is substantial interest in developing artificial intelligence systems to support radiologists across tasks ranging from segmentation to report generation. Existing computed tomography (CT) foundation models have largely focused on building generalist vision-language systems capable of tasks such as question answering and report generation. However, training reliable vision-language systems requires paired image-text data at a scale that remains unavailable in CT. Moreover, adapting the underlying visual representations to downstream tasks typically requires partial or full backbone fine-tuning, a computationally demanding process inaccessible to many research groups. Instead, foundation models should prioritise learning robust visual representations that enable efficient transfer to new tasks with minimal labelled data and without backbone fine-tuning. We present VoxelFM, a 3D CT foundation model trained with self-distillation using the DINO framework, which learns semantically rich features without language supervision. We evaluated VoxelFM across seven categories of clinically relevant downstream tasks using frozen backbone representations with lightweight probes: classification, regression, survival analysis, instance retrieval, localisation, segmentation, and report generation. VoxelFM matched or outperformed four existing CT foundation models across all task categories. Despite receiving no language supervision during pre-training, VoxelFM surpassed models explicitly trained with language-alignment objectives, including on report generation. Our results indicate that current CT foundation models perform significantly better as feature extractors for lightweight probes rather than as vision encoders for vision-language models. Model weights and training code are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VoxelFM, a 3D CT foundation model pretrained via DINO self-distillation without language supervision. It claims that frozen VoxelFM features plus lightweight probes match or outperform four existing CT foundation models across seven clinical task categories (classification, regression, survival analysis, instance retrieval, localisation, segmentation, and report generation), including surpassing language-aligned models on report generation. The authors conclude that current CT foundation models function better as feature extractors than as vision encoders for vision-language systems and release model weights and training code publicly.
Significance. If the performance claims are substantiated with statistical controls, the work would be significant for medical imaging AI. It provides evidence that purely visual self-supervised pretraining can yield robust, transferable features competitive with vision-language models across diverse tasks while enabling efficient adaptation without backbone fine-tuning. The public code and weight release supports reproducibility and is a clear strength.
major comments (1)
- [Experimental results / evaluation across task categories] The central claim that VoxelFM 'matched or outperformed' the four baselines across all seven task categories rests on single-run point estimates (AUC, Dice, BLEU, etc.) without standard deviations across random seeds, confidence intervals, or hypothesis testing. This is load-bearing for the assertion that VoxelFM surpasses language-supervised models on report generation, as probe training variance and dataset shifts can produce differences of the observed magnitude.
minor comments (2)
- [Abstract and Methods] The abstract and methods sections provide insufficient detail on the exact datasets, patient cohorts, preprocessing, and metric definitions used for each of the seven task categories, making it difficult to assess representativeness and potential confounds.
- [Evaluation protocol] Clarify the hyperparameter settings and training protocol for the lightweight probes (e.g., whether grid search or fixed defaults were used) and report any ablation on probe architecture choices.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment on the statistical evaluation of our results below.
read point-by-point responses
-
Referee: [Experimental results / evaluation across task categories] The central claim that VoxelFM 'matched or outperformed' the four baselines across all seven task categories rests on single-run point estimates (AUC, Dice, BLEU, etc.) without standard deviations across random seeds, confidence intervals, or hypothesis testing. This is load-bearing for the assertion that VoxelFM surpasses language-supervised models on report generation, as probe training variance and dataset shifts can produce differences of the observed magnitude.
Authors: We acknowledge the validity of this concern. Our initial experiments reported single-run results due to the substantial computational resources required for 3D CT pretraining and downstream evaluations. To strengthen the manuscript, we will perform additional runs using different random seeds for the probe training across the task categories, particularly emphasizing the report generation task. We will report mean values along with standard deviations, include confidence intervals, and apply statistical hypothesis testing to confirm the significance of performance differences. These updates will be reflected in the revised version of the paper. revision: yes
Circularity Check
No significant circularity; claims rest on empirical comparisons
full rationale
The manuscript describes an empirical pipeline: VoxelFM is pretrained via the standard DINO self-distillation objective on unlabeled CT volumes, after which frozen backbone features are fed to lightweight task-specific probes and compared against four external CT foundation models on seven clinical task categories. No derivation chain, equations, or first-principles results are presented that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing premises. Performance claims are grounded in direct metric comparisons (AUC, Dice, BLEU, etc.) to independently trained baselines rather than any renaming of known results or smuggling of ansatzes via prior self-work. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- DINO training hyperparameters
axioms (1)
- domain assumption Self-distillation with DINO produces semantically rich features suitable for downstream clinical tasks in 3D CT
Reference graph
Works this paper leans on
-
[1]
Computed Tomography: Revolutionizing the Practice of Medicine for 40 Years
Geoffrey D. Rubin. “Computed Tomography: Revolutionizing the Practice of Medicine for 40 Years”. In: Radiology273.2S (Nov. 2014), S45–S74.issn: 0033-8419.doi:10.1148/radiol.14141356
-
[2]
Workload for radiologists during on-call hours: dramatic increase in the past 15 years
R. J. M. Bruls and R. M. Kwee. “Workload for radiologists during on-call hours: dramatic increase in the past 15 years”. en. In:Insights into Imaging11.1 (Nov. 2020), p. 121.issn: 1869-4101.doi: 10.1186/s13244-020- 00925-z
-
[3]
Tarek N. Hanna, Christine Lamoureux, Elizabeth A. Krupinski, Scott Weber, and Jamlik-Omari Johnson. “Effect of Shift, Schedule, and Volume on Interpretive Accuracy: A Retrospective Analysis of 2.9 Million Radiologic Examinations”. In:Radiology287.1 (Apr. 2018), pp. 205–212.issn: 0033-8419.doi: 10 . 1148 / radiol . 2017170555
work page 2018
-
[4]
Mandating Limits on Workload, Duty, and Speed in Radiology
Robert Alexander, Stephen Waite, Michael A. Bruno, Elizabeth A. Krupinski, Leonard Berlin, Stephen Macknik, and Susana Martinez-Conde. “Mandating Limits on Workload, Duty, and Speed in Radiology”. In:Radiology 304.2 (Aug. 2022), pp. 274–282.issn: 0033-8419.doi:10.1148/radiol.212631
-
[5]
TotalSegmentator: Robust Segmentation of 104 Anatomic Structures in CT Images
Jakob Wasserthal et al. “TotalSegmentator: Robust Segmentation of 104 Anatomic Structures in CT Images”. In: Radiology: Artificial Intelligence5.5 (Sept. 2023), e230024.doi:10.1148/ryai.230024
-
[6]
Vision-language foundation models for medical imaging: a review of current practices and innovations
Ji Seung Ryu, Hyunyoung Kang, Yuseong Chu, and Sejung Yang. “Vision-language foundation models for medical imaging: a review of current practices and innovations”. en. In:Biomedical Engineering Letters15.5 (Sept. 2025), pp. 809–830.issn: 2093-985X.doi:10.1007/s13534-025-00484-6
-
[7]
The role of artificial intelligence-based foundation models and “copilots
Cillian H. Cheng and Chi Chun Wong. “The role of artificial intelligence-based foundation models and “copilots” in cancer pathology: potential and challenges”. In:Journal of Experimental & Clinical Cancer Research : CR45 (Nov. 2025), p. 2.issn: 0392-9078.doi:10.1186/s13046-025-03592-4
-
[8]
arXiv preprint arXiv:2501.09001 (2025)
Suraj Pai, Ibrahim Hadzic, Dennis Bontempi, Keno Bressem, Benjamin H. Kann, Andriy Fedorov, Raymond H. Mak, and Hugo J. W. L. Aerts.Vision Foundation Models for Computed Tomography. Feb. 2025.doi: 10.48550/arXiv.2501.09001
-
[9]
Merlin: a computed tomography vision–language foundation model and dataset
Louis Blankemeier et al. “Merlin: a computed tomography vision–language foundation model and dataset”. en. In:Nature(Mar. 2026), pp. 1–11.issn: 1476-4687.doi:10.1038/s41586-026-10181-8
-
[10]
M3d:Ad- vancing 3d medical image analysis with multi-modal large language models
Fan Bai, Yuxin Du, Tiejun Huang, Max Q.-H. Meng, and Bo Zhao.M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models. Mar. 2024.doi:10.48550/arXiv.2404.00578
-
[11]
Towards generalist foundation model for radiology by leveraging web-scale 2D&3D medical data
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Hui Hui, Yanfeng Wang, and Weidi Xie. “Towards generalist foundation model for radiology by leveraging web-scale 2D&3D medical data”. en. In:Nature Communications16.1 (Aug. 2025), p. 7866.issn: 2041-1723.doi:10.1038/s41467-025-62385-7
-
[12]
Ibrahim Ethem Hamamci et al.Developing Generalist Foundation Models from a Multimodal Dataset for 3D Computed Tomography. Oct. 2024.doi:10.48550/arXiv.2403.17834
-
[13]
MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis
Jiaxin Zhuang, Linshan Wu, Qiong Wang, Peng Fei, Varut Vardhanabhuti, Lin Luo, and Hao Chen. “MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis”. In:IEEE Transactions on Medical Imaging44.9 (Sept. 2025), pp. 3727–3740.issn: 1558-254X.doi:10.1109/TMI.2025.3564382
-
[14]
Weiyun Wang et al.InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency. Aug. 2025.doi:10.48550/arXiv.2508.18265
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.18265 2025
-
[15]
Shuai Bai et al.Qwen3-VL Technical Report. Nov. 2025.doi:10.48550/arXiv.2511.21631. [16][2103.00020] Learning Transferable Visual Models From Natural Language Supervision
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[16]
Michael Tschannen et al.SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Under- standing, Localization, and Dense Features. Feb. 2025.doi:10.48550/arXiv.2502.14786. 17
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.14786 2025
-
[17]
Daniel Bolya et al.Perception Encoder: The best visual embeddings are not at the output of the network. Apr. 2025.doi:10.48550/arXiv.2504.13181
work page internal anchor Pith review doi:10.48550/arxiv.2504.13181 2025
-
[18]
David Fan et al.Scaling Language-Free Visual Representation Learning. Apr. 2025.doi: 10.48550/arXiv. 2504.01017
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[19]
Emerging properties in self-supervised vision transformers.arXiv preprint arXiv:2104.14294,
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformers. May 2021.doi: 10.48550/arXiv.2104.14294
-
[20]
Maxime Oquab et al.DINOv2: Learning Robust Visual Features without Supervision. Feb. 2024.doi: 10.48550/ arXiv.2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Oriane Sim ´eoni et al.DINOv3. Aug. 2025.doi:10.48550/arXiv.2508.10104
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10104 2025
-
[22]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. “Visual Instruction Tuning”. en. In: ()
-
[23]
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. “Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models”. en. In: ()
-
[24]
Retrieval-Augmented Embodied Agents
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. “Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs”. In:2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE, June 2024, pp. 9568–9578.isbn: 979-8-3503-5300-6. doi:10.1109/CVPR52733.2024.00914
-
[25]
Data or Language Supervision: What Makes CLIP Better than DINO?
Yiming Liu, Yuhui Zhang, Dhruba Ghosh, Ludwig Schmidt, and Serena Yeung-Levy. “Data or Language Supervision: What Makes CLIP Better than DINO?” en. In: ()
-
[26]
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Cijo Jose et al. “DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment”. en. In: ()
-
[27]
Aerts, H.J.W.L. et al.NSCLC-Radiomics. 2014.doi:10.7937/K9/TCIA.2015.PF0M9REI
-
[28]
Timoth´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski.Vision Transformers Need Registers. Apr. 2024.doi:10.48550/arXiv.2309.16588
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.16588 2024
-
[29]
Shih-Cheng Huang, Zepeng Huo, Ethan Steinberg, Chia-Chun Chiang, Matthew P. Lungren, Curtis P. Langlotz, Serena Yeung, Nigam H. Shah, and Jason A. Fries.INSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis. Nov. 2023.doi:10.48550/arXiv.2311.10798
-
[30]
2013.doi: 10.7937/TCIA.HMQ8-J677
National Lung Screening Trial Research Team.Data from the National Lung Screening Trial (NLST). 2013.doi: 10.7937/TCIA.HMQ8-J677
-
[32]
2020.doi:10.7937/TCIA.2020.NNC2-0461
Ping Li, Shuo Wang, Tang Li, Jingfeng Lu, Yunxin HuangFu, and Dongxue Wang.A Large-Scale CT and PET/CT Dataset for Lung Cancer Diagnosis. 2020.doi:10.7937/TCIA.2020.NNC2-0461
-
[34]
2021.doi:10.7937/TCIA.BBAG-2923
Joel Saltz, Mary Saltz, Prateek Prasanna, Richard Moffitt, Janos Hajagos, Erich Bremer, Joseph Balsamo, and Tahsin Kurc.Stony Brook University COVID-19 Positive Cases. 2021.doi:10.7937/TCIA.BBAG-2923
-
[35]
The RSNA Abdominal Traumatic Injury CT (RATIC) Dataset
Jeffrey D. Rudie et al. “The RSNA Abdominal Traumatic Injury CT (RATIC) Dataset”. In:Radiology: Artificial Intelligence6.6 (Nov. 2024), e240101.doi:10.1148/ryai.240101
-
[36]
K. Smith, K. Clark, W. Bennett, T. Nolan, J. Kirby, M. Wolfsberger, J. Moulton, B. Vendt, and J. Freymann.Data From CT COLONOGRAPHY. 2015.doi:10.7937/K9/TCIA.2015.NWTESAY1
-
[37]
AbdomenCT-1K: Is Abdominal Organ Segmentation a Solved Problem?
Jun Ma et al. “AbdomenCT-1K: Is Abdominal Organ Segmentation a Solved Problem?” In:IEEE Transactions on Pattern Analysis and Machine Intelligence44.10 (Oct. 2022), pp. 6695–6714.issn: 1939-3539.doi: 10.1109/TPAMI.2021.3100536
-
[38]
Phase recognition in contrast-enhanced CT scans based on deep learning and random sampling
Binh T. Dao, Thang V. Nguyen, Hieu H. Pham, and Ha Q. Nguyen. “Phase recognition in contrast-enhanced CT scans based on deep learning and random sampling”. en. In:Medical Physics49.7 (2022), pp. 4518–4528.issn: 2473-4209.doi:10.1002/mp.15551
-
[39]
Moawad et al.Multimodality annotated HCC cases with and without advanced imaging segmentation
Ahmed W. Moawad et al.Multimodality annotated HCC cases with and without advanced imaging segmentation. 2021.doi:10.7937/TCIA.5FNA-0924
-
[40]
Oguz Akin et al.The Cancer Genome Atlas Kidney Renal Clear Cell Carcinoma Collection (TCGA-KIRC). 2016. doi:10.7937/K9/TCIA.2016.V6PBVTDR
-
[41]
T. Tong and M. Li.Abdominal or pelvic enhanced CT images within 10 days before surgery of 230 patients with stage II colorectal cancer (StageII-Colorectal-CT). 2022.doi:10.7937/p5k5-tg43
-
[42]
Shanah Kirk et al.The Cancer Genome Atlas Urothelial Bladder Carcinoma Collection (TCGA-BLCA). 2016. doi:10.7937/K9/TCIA.2016.8LNG8XDR. 18
-
[43]
Bradley J. Erickson, Shanah Kirk, Yueh Lee, Oliver Bathe, Melissa Kearns, Cindy Gerdes, Kimberly Rieger-Christ, and John Lemmerman.The Cancer Genome Atlas Liver Hepatocellular Carcinoma Collection (TCGA-LIHC). 2016.doi:10.7937/K9/TCIA.2016.IMMQW8UQ
-
[44]
Nicholas Heller et al.C4KC KiTS Challenge Kidney Tumor Segmentation Dataset. 2019.doi: 10.7937/TCIA. 2019.IX49E8NX
-
[45]
Fabiano R. Lucchesi and Nat´alia D. Aredes.The Cancer Genome Atlas Stomach Adenocarcinoma Collection (TCGA-STAD). 2016.doi:10.7937/K9/TCIA.2016.GDHL9KIM
-
[46]
Bradley J. Erickson, David Mutch, Lynne Lippmann, and Rose Jarosz.The Cancer Genome Atlas Uterine Corpus Endometrial Carcinoma Collection (TCGA-UCEC). 2016.doi:10.7937/K9/TCIA.2016.GKJ0ZWAC
-
[47]
National Cancer Institute Clinical Proteomic Tumor Analysis Consortium (CPTAC).The Clinical Proteomic Tumor Analysis Consortium Clear Cell Renal Cell Carcinoma Collection (CPTAC-CCRCC). 2018.doi: 10. 7937/K9/TCIA.2018.OBLAMN27
work page 2018
-
[48]
RADCURE: An open-source head and neck cancer CT dataset for clinical radiation therapy insights
Mattea L. Welch et al. “RADCURE: An open-source head and neck cancer CT dataset for clinical radiation therapy insights”. eng. In:Medical Physics51.4 (Apr. 2024), pp. 3101–3109.issn: 2473-4209.doi: 10.1002/mp.16972
-
[49]
2020.doi:10.7937/k9/tcia.2020.a8sh-7363
A Grossberg et al.HNSCC Version 4. 2020.doi:10.7937/k9/tcia.2020.a8sh-7363
-
[50]
Zuley et al.The Cancer Genome Atlas Head-Neck Squamous Cell Carcinoma Collection (TCGA- HNSC)
Margarita L. Zuley et al.The Cancer Genome Atlas Head-Neck Squamous Cell Carcinoma Collection (TCGA- HNSC). 2016.doi:10.7937/K9/TCIA.2016.LXKQ47MS
-
[51]
2018.doi:10.7937/k9/tcia.2018.uw45nh81
The Clinical Proteomic Tumor Analysis Consortium Head and Neck Squamous Cell Carcinoma Collection (CPTAC-HNSCC) (Version 19). 2018.doi:10.7937/k9/tcia.2018.uw45nh81
-
[52]
P. Kinahan, M. Muzi, B. Bialecki, and L. Coombs.Data from the ACRIN 6685 Trial HNSCC-FDG-PET/CT.doi: 10.7937/K9/TCIA.2016.JQEJZZNG
-
[53]
2015.doi:10.7937/K9/TCIA.2015.K0F5CGLI
Reinhard R Beichel et al.Data From QIN-HEADNECK. 2015.doi:10.7937/K9/TCIA.2015.K0F5CGLI
-
[54]
2017.doi: 10.7937/K9/ TCIA.2017.8OJE5Q00
Martin Valli`eres, Emily Kay-Rivest, L ´eo Perrin, Xavier Liem, Christophe Furstoss, Nader Khaouam, Phuc Nguyen-Tan, Chang-Shu Wang, and Khalil Sultanem.Data from Head-Neck-PET-CT. 2017.doi: 10.7937/K9/ TCIA.2017.8OJE5Q00
work page doi:10.7937/k9/ 2017
-
[55]
2021.doi:10.7937/TCIA.T905-ZQ20
Nadya Shusharina and Thomas Bortfeld.Glioma Image Segmentation for Radiotherapy: RT targets, barriers to cancer spread, and organs at risk (GLIS-RT). 2021.doi:10.7937/TCIA.T905-ZQ20
-
[56]
Jacob Buatti, Christopher Kabat, Ruiqi Li, Sruthi Sivabhaskar, Michelle de Oliveira, Nikos Papanikolaou, Sotirios Stathakis, Nikos Paragios, and Neil Kirby.CT-RTSTRUCT-RTDOSE-RTPLAN Sets of Head and Neck Cancers Treated with Identical Prescriptions using IMRT: An Open Dataset for Deep Learning in Treatment Planning. 2024.doi:10.7937/AHQH-XC79
-
[57]
Walter R. Bosch, William L. Straube, John W. Matthews, and James A. Purdy.Head-Neck Cetuximab. 2015.doi: 10.7937/K9/TCIA.2015.7AKGJUPZ
-
[58]
Zolotova et al.Burdenko’s Glioblastoma Progression Dataset (Burdenko-GBM-Progression)
Svetlana V. Zolotova et al.Burdenko’s Glioblastoma Progression Dataset (Burdenko-GBM-Progression). 2023. doi:10.7937/E1QP-D183
- [59]
-
[60]
The RSNA Pulmonary Embolism CT Dataset
Errol Colak et al. “The RSNA Pulmonary Embolism CT Dataset”. In:Radiology: Artificial Intelligence3.2 (Mar. 2021), e200254.doi:10.1148/ryai.2021200254
-
[61]
Wanshan Ning et al. “Open resource of clinical data from patients with pneumonia for the prediction of COVID-19 outcomes via deep learning”. en. In:Nature Biomedical Engineering4.12 (Nov. 2020), pp. 1197–1207.issn: 2157-846X.doi:10.1038/s41551-020-00633-5
-
[62]
2025.doi: 10.34740/KAGGLE/DS/6248246
Zhilin Han, Yuyang Zhang, Wenlong Ding, and Zhiheng Xing.Mycobacterial CT Imaging Dataset. 2025.doi: 10.34740/KAGGLE/DS/6248246
-
[63]
Armato III et al.Data From LIDC-IDRI
Samuel G. Armato III et al.Data From LIDC-IDRI. 2015.doi:10.7937/K9/TCIA.2015.LO9QL9SX
-
[64]
Arnaud Arindra Adiyoso Setio et al. “Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: The LUNA16 challenge”. In:Medical Image Analysis42 (Dec. 2017), pp. 1–13.issn: 1361-8415.doi:10.1016/j.media.2017.06.015
-
[65]
Ahmed Shahin, Carmela Wegworth, David, Elizabeth Estes, Julia Elliott, Justin Zita, Simon Walsh, Slepetys, and Will Cukierski.OSIC Pulmonary Fibrosis Progression. 2020
work page 2020
-
[66]
et al.Mediastinal Lymph Node Quantification (LNQ)
Idris, T. et al.Mediastinal Lymph Node Quantification (LNQ). 2024.doi:10.7937/QVAZ-JA09
-
[67]
A Custom Annotated Dataset for Segmentation of Pulmonary Veins, Arteries, and Airways
Jian Liu, Zheng Zhang, Bing Niu, Shuai Kang, Juan Ren, Lei Wang, and Kai Xu. “A Custom Annotated Dataset for Segmentation of Pulmonary Veins, Arteries, and Airways”. en. In:Scientific Data12.1 (Nov. 2025), p. 1806. issn: 2052-4463.doi:10.1038/s41597-025-06074-6. 19
-
[68]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen.LoRA: Low-Rank Adaptation of Large Language Models. Oct. 2021.doi: 10.48550/arXiv.2106.09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2021
-
[69]
An Yang et al.Qwen3 Technical Report. May 2025.doi:10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[70]
OpenAI et al.gpt-oss-120b & gpt-oss-20b Model Card. Aug. 2025.doi:10.48550/arXiv.2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[71]
The meaning and use of the area under a receiver operating characteristic (ROC) curve
J A Hanley and B J McNeil. “The meaning and use of the area under a receiver operating characteristic (ROC) curve.” en. In:Radiology143.1 (Apr. 1982), pp. 29–36.issn: 0033-8419, 1527-1315.doi: 10.1148/radiology. 143.1.7063747. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.