Recognition: no theorem link
Replacing Gaussian Processes with Neural Networks in Pulsar Timing Array Inference of the Gravitational-Wave Background
Pith reviewed 2026-05-10 20:24 UTC · model grok-4.3
The pith
Probabilistic neural networks can replace Gaussian process interpolators in pulsar timing array analyses of nanohertz gravitational wave backgrounds, producing matching posteriors at lower computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Bayesian inference of nanohertz gravitational-wave background models in pulsar timing array analyses often relies on Gaussian-process interpolators to avoid repeated, computationally expensive strain-spectrum calculations. However, Gaussian-process training becomes a bottleneck for large training sets. We test whether probabilistic neural networks can replace Gaussian processes in this role for both a self-interacting dark matter model and a phenomenological environmental model. We find that neural networks recover consistent posteriors while significantly reducing both training and Markov chain Monte Carlo runtime, with the largest gains for the more computationally demanding model.
What carries the argument
probabilistic neural networks trained on strain-spectrum evaluations to serve as fast surrogates during posterior sampling
If this is right
- Posteriors for the self-interacting dark matter model remain consistent between the two interpolators.
- Posteriors for the phenomenological environmental model remain consistent between the two interpolators.
- Training time is reduced compared with Gaussian-process methods.
- Markov chain Monte Carlo runtime is reduced, with larger savings in the more computationally intensive model.
Where Pith is reading between the lines
- The same substitution could be tried in other astrophysical inference problems that currently use Gaussian processes for expensive forward-model evaluations.
- Larger training sets or more complex models might become feasible once the per-sample cost drops.
- The approach opens a path to embedding the surrogate inside nested sampling or other sampling algorithms that are even more expensive than standard Markov chain Monte Carlo.
Load-bearing premise
Once trained on a finite set of strain-spectrum points, the neural networks generalize accurately across the full prior volume of the target models without adding systematic biases to the recovered posteriors.
What would settle it
A side-by-side run in which the posterior distributions or credible intervals obtained from the neural-network interpolator differ from those of the Gaussian-process interpolator by more than sampling noise on an independent validation set.
Figures







read the original abstract
Bayesian inference of nanohertz gravitational-wave background models in pulsar timing array analyses often relies on Gaussian-process interpolators to avoid repeated, computationally expensive strain-spectrum calculations. However, Gaussian-process training becomes a bottleneck for large training sets. We test whether probabilistic neural networks can replace Gaussian processes in this role for both a self-interacting dark matter model and a phenomenological environmental model. We find that neural networks recover consistent posteriors while significantly reducing both training and Markov chain Monte Carlo runtime, with the largest gains for the more computationally demanding model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes replacing Gaussian-process interpolators with probabilistic neural networks for strain-spectrum calculations in Bayesian pulsar timing array inference of the nanohertz gravitational-wave background. It tests the substitution on a self-interacting dark matter model and a phenomenological environmental model, reporting that the networks recover consistent posteriors while reducing both training time and MCMC runtime, with larger gains for the more demanding model.
Significance. If the networks generalize without systematic bias across the prior volume, the approach could remove a key computational bottleneck in PTA analyses, enabling faster exploration of complex models or larger datasets. The work supplies an empirical head-to-head comparison rather than new theoretical machinery.
major comments (2)
- [Abstract / Results] Abstract and results: the central claim that neural networks recover 'consistent posteriors' is stated without quantitative diagnostics (e.g., posterior overlap metrics, held-out parameter recovery error, coverage probabilities, or credible-interval calibration tests). This leaves the load-bearing assertion that approximation error remains sub-dominant to statistical uncertainty unverified.
- [Methods] Methods: the manuscript supplies no details on network architecture, training-set construction, hyperparameter choices, or validation strategy against the full prior support. Without these, it is impossible to evaluate whether under-sampling near prior boundaries or high-curvature regions could induce systematic shifts in recovered parameters.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify key areas where additional quantitative support and methodological transparency will strengthen the manuscript. We address each major comment below and describe the revisions we plan to implement.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the central claim that neural networks recover 'consistent posteriors' is stated without quantitative diagnostics (e.g., posterior overlap metrics, held-out parameter recovery error, coverage probabilities, or credible-interval calibration tests). This leaves the load-bearing assertion that approximation error remains sub-dominant to statistical uncertainty unverified.
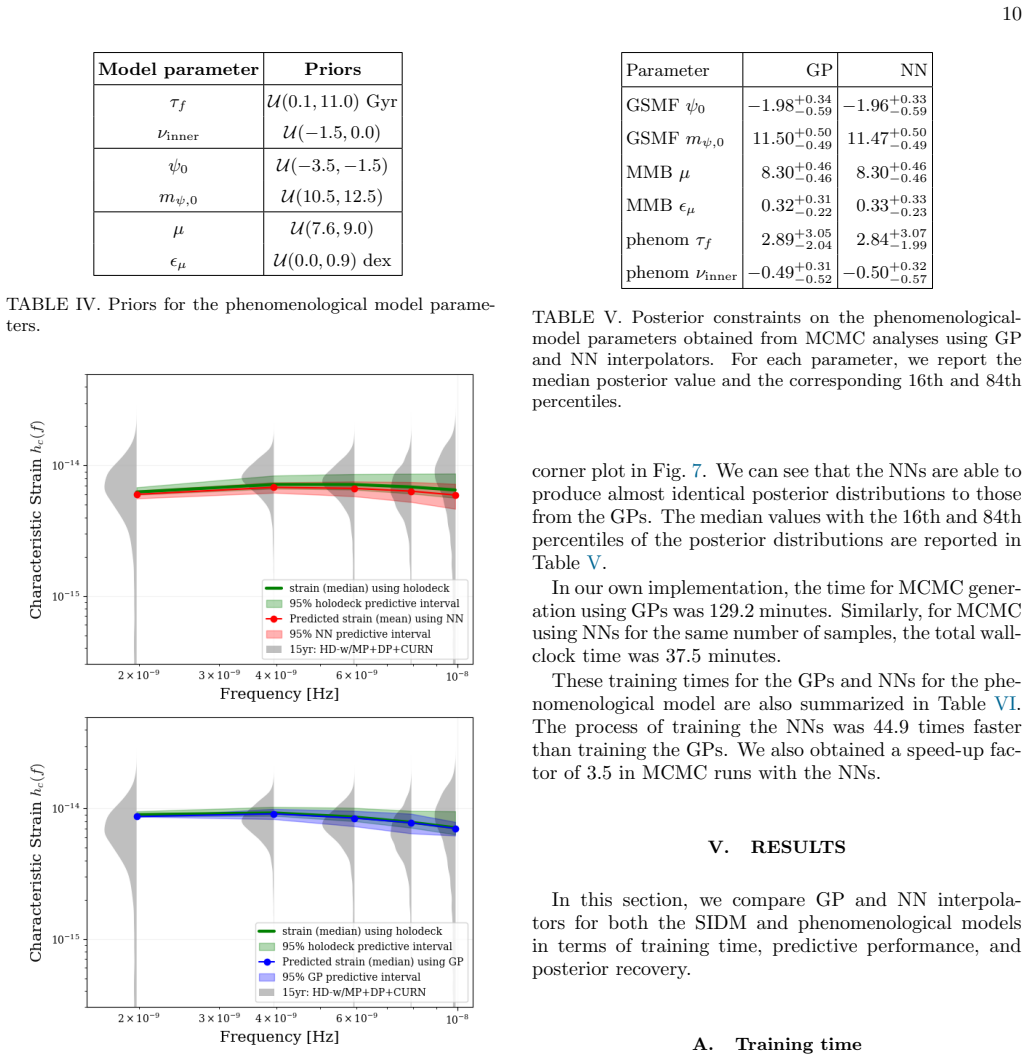
Authors: We agree that the central claim requires stronger quantitative backing. In the revised manuscript we will add explicit diagnostics in the Results section, including Jensen-Shannon divergence between the GP- and NN-derived posteriors, parameter recovery bias and variance on held-out simulations drawn from the prior, and coverage probability checks for the 68% and 95% credible intervals. These metrics will be reported for both the self-interacting dark matter and environmental models. The abstract will be updated to reference these diagnostics rather than stating consistency in purely qualitative terms. revision: yes
-
Referee: [Methods] Methods: the manuscript supplies no details on network architecture, training-set construction, hyperparameter choices, or validation strategy against the full prior support. Without these, it is impossible to evaluate whether under-sampling near prior boundaries or high-curvature regions could induce systematic shifts in recovered parameters.
Authors: We acknowledge that the current Methods section lacks the necessary detail for reproducibility and bias assessment. The revised version will expand this section to specify the neural-network architecture (number of layers, hidden units, activation functions, and probabilistic output parameterization), the training-set generation procedure (prior sampling density, total number of points, and stratification near boundaries), hyperparameter selection via cross-validation, and validation tests that explicitly probe performance in high-curvature and prior-edge regions. These additions will allow readers to judge the risk of systematic shifts. revision: yes
Circularity Check
No circularity: empirical benchmark of NN vs GP interpolators
full rationale
The paper conducts a direct numerical comparison of two interpolation methods (Gaussian processes versus probabilistic neural networks) for strain-spectrum evaluations inside PTA Bayesian inference pipelines. All reported results—posterior consistency, training time, and MCMC runtime—are obtained from independent held-out simulations and full inference runs rather than from any self-referential definition, fitted parameter renamed as a prediction, or load-bearing self-citation. No derivation chain exists that reduces an output quantity to the same fitted inputs used to define it; the work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian posterior sampling in PTA analyses requires repeated, accurate evaluations of the strain-spectrum likelihood.
Reference graph
Works this paper leans on
-
[1]
replaced theholodeckGP interpolator for the phe- nomenological SMBHB model with a normalizing-flow surrogate trained on the full strain-ensemble distribution. In this work, we pursue a more direct drop-in re- placement of the GP interpolator used in the current Bayesian PTA pipeline, focusing on Bayesian analyses of the NANOGrav 15-year dataset. We constr...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Given an input vector, the data are propagated forward through successive layers
Principle and architecture A deep NN consists of multiple layers of interconnected neurons, each of which applies a linear transformation followed by a nonlinear activation function to its input. Given an input vector, the data are propagated forward through successive layers. In each layer, the input is transformed using trainable weight matrices and bia...
-
[3]
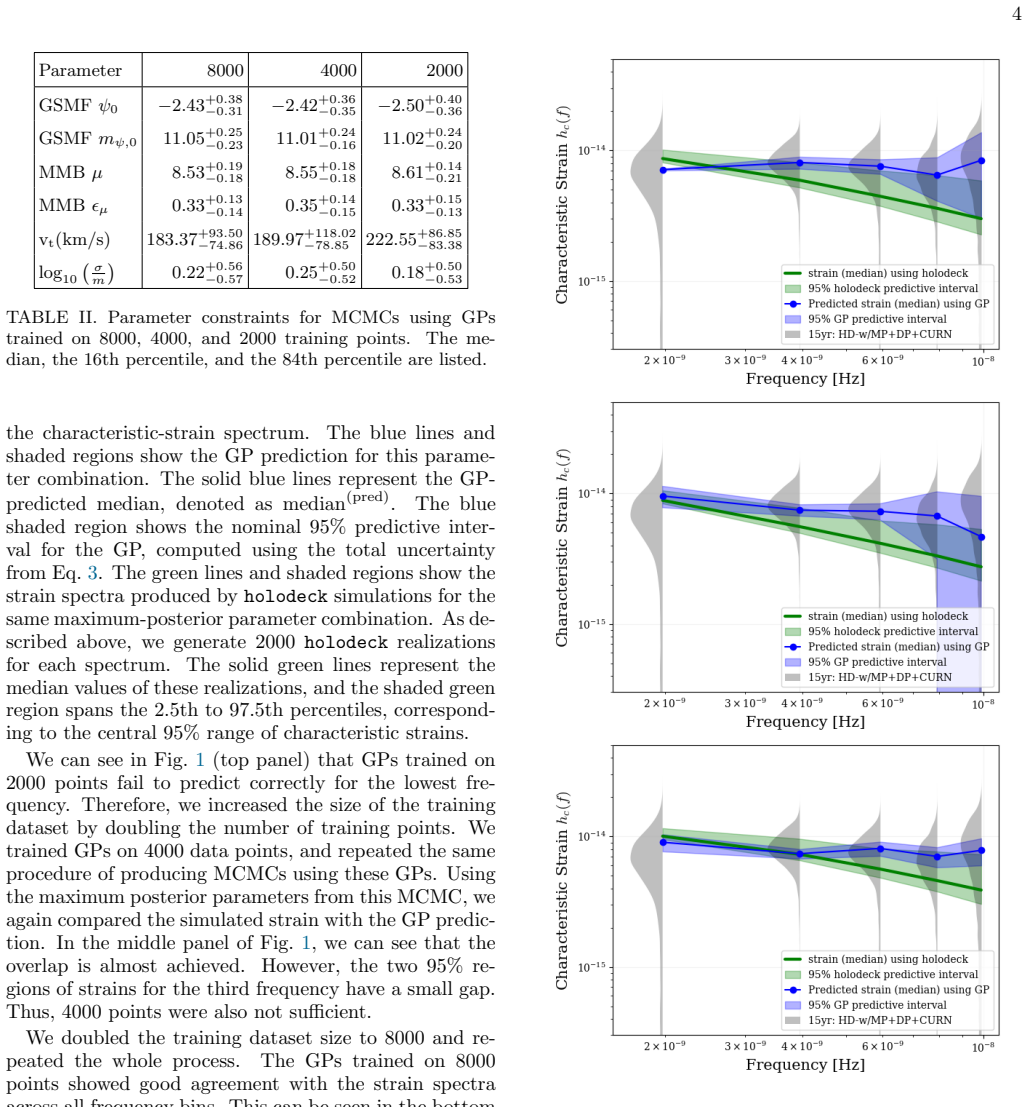
Training As mentioned before, the training dataset is simulated usingholodeck. In our training set, we chose 8000 pa- rameter combinations using the Latin hypercube sam- pling as explained in Ref. [24] and by Agazie2023. This procedure yields parameter combinations that uniformly span our six-dimensional parameter space. For each such combination, we simu...
-
[4]
Agazie, A
G. Agazie, A. Anumarlapudi,et al., The NANOGrav 15 yr data set: Evidence for a gravitational-wave back- ground, Astrophys. J. Lett.951, L8 (2023)
2023
-
[5]
D. J. Reardon, A. Zic,et al., Search for an isotropic gravitational-wave background with the Parkes pulsar timing array, Astrophys. J. Lett.951, L6 (2023)
2023
-
[6]
Antoniadis, P
J. Antoniadis, P. Arumugam,et al., The second data re- lease from the European pulsar timing array: III. Search for gravitational wave signals, Astron. Astrophys.678, A50 (2023)
2023
-
[7]
H. Xu, S. Chen,et al., Searching for the nano-hertz stochastic gravitational wave background with the Chi- nese pulsar timing array data release I, Res. Astron. As- trophys.23, 075024 (2023)
2023
-
[8]
M. C. Begelman, R. D. Blandford, and M. J. Rees, Mas- sive black hole binaries in active galactic nuclei, Nature 287, 307 (1980)
1980
-
[9]
Agazieet al., The NANOGrav 15 yr data set: Con- straints on supermassive black hole binaries from the gravitational-wave background, Astrophys
G. Agazieet al., The NANOGrav 15 yr data set: Con- straints on supermassive black hole binaries from the gravitational-wave background, Astrophys. J. Lett.952, L37 (2023)
2023
-
[10]
S. R. Taylor, J. Simon, and L. Sampson, Constraints on the dynamical environments of supermassive black-hole binaries using pulsar-timing arrays, Physical Review Let- ters118, 10.1103/physrevlett.118.181102 (2017)
-
[11]
A. Spurio Mancini, D. Piras, J. Alsing, B. Joachimi, and M. P. Hobson, CosmoPower: emulating cosmologi- cal power spectra for accelerated Bayesian inference from next-generation surveys, Mon. Not. Roy. Astron. Soc. 511, 1771 (2022), arXiv:2106.03846 [astro-ph.CO]
-
[12]
Giarda, A
G. Giarda, A. I. Renzini, C. Pacilio, and D. Gerosa, Ac- celerated inference of binary black-hole populations from the stochastic gravitational-wave background, Classical and Quantum Gravity42, 195015 (2025)
2025
-
[13]
D. Shih, M. Freytsis, S. R. Taylor, J. A. Dror, and N. Smyth, Fast parameter inference on pulsar timing ar- rays with normalizing flows, Phys. Rev. Lett.133, 011402 (2024)
2024
-
[14]
Vallisneri, M
M. Vallisneri, M. Crisostomi, A. D. Johnson, and P. M. Meyers, Rapid parameter estimation for pulsar-timing- array datasets with variational inference and normalizing flows, Phys. Rev. Lett.135, 071401 (2025)
2025
-
[15]
M. Bonetti, A. Franchini, B. G. Galuzzi, and A. Sesana, Neural networks unveiling the properties of gravitational wave background from supermassive black hole binaries, Astron. Astrophys.687, A42 (2024), arXiv:2311.04276 [astro-ph.HE]
-
[16]
N. Laal, S. R. Taylor, L. Z. Kelley, J. Simon, K. G¨ ultekin, D. Wright, B. B´ ecsy, J. A. Casey-Clyde, S. Chen, A. Cin- goranelli, D. J. D’Orazio, E. C. Gardiner, W. G. Lamb, C. Matt, M. S. Siwek, and J. M. Wachter, Deep Neural Emulation of the Supermassive Black Hole Binary Pop- ulation, Astrophys. J.982, 55 (2025), arXiv:2411.10519 [astro-ph.IM]
-
[17]
Tiruvaskar and C
S. Tiruvaskar and C. Gordon, Self-interacting dark- matter spikes and the final-parsec problem: Bayesian constraints from the NANOGrav 15-year gravitational- wave background, Phys. Rev. D113, 043501 (2026)
2026
-
[18]
Alonso- ´Alvarez, J
G. Alonso- ´Alvarez, J. M. Cline, and C. Dewar, Self- interacting dark matter solves the final parsec problem of supermassive black hole mergers, Phys. Rev. Lett.133, 021401 (2024)
2024
-
[19]
Cressie and G
N. Cressie and G. Johannesson, Fixed rank kriging for very large spatial data sets, Journal of the Royal Statis- tical Society Series B: Statistical Methodology70, 209 (2008)
2008
-
[20]
C. E. Rasmussen, Evaluation of Gaussian processes and other methods for non-linear regression (1997)
1997
-
[21]
C. K. I. Williams and C. E. Rasmussen, Gaussian pro- cesses for regression, inAdvances in Neural Information Processing Systems 8, edited by D. S. Touretzky, M. C. Mozer, and M. E. Hasselmo (MIT Press, 1996) pp. 514– 520
1996
-
[22]
S. Ambikasaran, D. Foreman-Mackey, L. Greengard, D. W. Hogg, and M. O’Neil, Fast Direct Methods for Gaussian Processes, IEEE Transactions on Pat- tern Analysis and Machine Intelligence38, 252 (2015), arXiv:1403.6015 [math.NA]
- [23]
-
[24]
Goodfellow, Y
I. Goodfellow, Y. Bengio, and A. Courville,Deep Learn- ing(MIT Press, 2016)
2016
-
[25]
Nair and G
V. Nair and G. E. Hinton, Rectified linear units improve restricted Boltzmann machines, inProceedings of the 27th International Conference on Machine Learning (ICML) (2010)
2010
-
[26]
D. P. Kingma and J. Ba, Adam: A method for stochas- tic optimization, International Conference on Learning Representations (ICLR) (2015)
2015
- [27]
-
[28]
Cholletet al., Keras (2015)
F. Cholletet al., Keras (2015)
2015
-
[29]
Abadiet al., TensorFlow: Large-scale machine learn- ing on heterogeneous systems (2015), software available from tensorflow.org
M. Abadiet al., TensorFlow: Large-scale machine learn- ing on heterogeneous systems (2015), software available from tensorflow.org
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.